对象
设计类(class):
class Student:
name = None
创建对象
stu_1 = Student()
对象属性赋值
stu_1.name = "周杰伦"
类的定义和使用
class 类名称: class 是关键字,表示要定义类了
类的属性:定义在类中的变量
类的行为:即定义在类中的函数
创建类对象的语法:
对象 = 类名称()
成员方法:
在类中定义成员方法和定义函数基本一致,但仍然有细微区别:
def 方法名(self,形参1,...,形成N):
方法体
self关键字
self关键字是成员方法定义的时候,必须填写的。
- 它用来表示类对象自身的意思
- 当我们使用类对象调用方法的时候,self会自动被python传入
- 在方法内部,想要访问类的成员变量,必须使用self
self关键字,尽管在参数列表中,但是传参的时候可以忽略它
即,方法中只有self这一个参数时,就调用时不需要参数传入
类和对象
现实世界的实物和类
类和对象:
对象名 = 类名称()
类就是设计图纸,对象就是实体
面向对象编程
函数(方法)那样,通过传参的形式对属性赋值
构造方法:init()方法
可以实现:
-
在创建类对象(构造类)的时候,会自动执行
-
在创建类对象(构造类)的时候,将传入参数自动传递给
-
__init__方法使用 -
class Student: name = None age = None tel = None def __init__(self,name,age,tel): self.name = name self.age = age self.tel = tel print("Student类创建成功了") stu = Student("周杰伦",31,"18500033666") #构建类时传入的参数会自动提供给__init__方法 #构建类的时候__init__方法会自动执行
魔术方法
__init__ 构造方法
__str__字符串方法
__lt__小于、大于符号比较
__le__小于等于、大于等于符号比较
__eq__ ==符号比较
class Student:
name = None
age = None
tel = None
def __init__(self,name,age,tel):
self.name = name
self.age = age
self.tel = tel
print("Student类创建成功了")
def __str__(self):
return f"student类对象.name={self.name},age = {self.age},tel = {self.tel}"
stu = Student("周杰伦",31,"18500033666")
print(stu)
print(str(stu))
#构建类时传入的参数会自动提供给__init__方法
#构建类的时候__init__方法会自动执行
方法名:
__str__
返回值:字符串
内容:自行定义
方法二:
class Student:
name = None
age = None
tel = None
def __init__(self,name,age,tel):
self.name = name
self.age = age
self.tel = tel
print("Student类创建成功了")
def __str__(self):
return f"student类对象.name={self.name},age = {self.age},tel = {self.tel}"
def __lt__(self, other):
return self.age < other.age
stu = Student("周杰伦",31,"18500033666")
stu2 = Student("lide",21,"188726222")
print(stu)
print(str(stu))
print(stu < stu2)
print(stu > stu2)
#构建类时传入的参数会自动提供给__init__方法
#构建类的时候__init__方法会自动执行
__lt__方法其实就是重写了<和>符号,使得其能够对类能直接进行操作
同理__le__方法,其实就是重写了<=和>=两种运算符上
传入参数:other,另一个类对象,返回值:True或False
内容自定义
同理,__eq__方法,传入参数:other,另一个类对象,返回值:True或False
内容:自行定义
封装
现实实物有不公开的属性和行为,那么作为现实实物在程序中映射的类,也应该支持
class Student:
name = None
age = None
tel = None
def __init__(self,name,age,tel):
self.name = name
self.age = age
self.tel = tel
print("Student类创建成功了")
def __str__(self):
return f"student类对象.name={self.name},age = {self.age},tel = {self.tel}"
def __lt__(self, other):
return self.age < other.age
def __le__(self, other):
return self.age <= other.age
stu = Student("周杰伦",31,"18500033666")
stu2 = Student("lide",21,"188726222")
print(stu)
print(str(stu))
print(stu < stu2)
print(stu > stu2)
#构建类时传入的参数会自动提供给__init__方法
#构建类的时候__init__方法会自动执行
类中提供了私有成员的形式来支持:
- 私有成员变量
- 私有成员方法
定义私有成员的方法:
私有成员变量:变量名以__开头
私有成员方法:方法名以__开头
class Phone:
IMEI = None #序列号
producer = None #厂商
__current_voltage = None #当前电压
def __keep_single_core(self):
print("私有成员方法")
私有方法无法直接被类对象使用
私有变量无法赋值,也无法获取值
一般在公开的成员方法中可以访问私有的成员变量
私有成员:在类中仅供内部使用的属性而不对外开发
继承
class Phone:
IMEI = None
producer = None
def call_by_4g(self):
print("4g通话")
#继承之后的类
class Phone2023(Phone):
face_id = True
def call_by_5g(self):
print("5g通话")
#则4g等老功能都被继承了,不需要写
class 类名(父类名):
类内容体
多继承:一个类可以继承多个父类
class 类名(父类1,父类2,...,父类N):
类内容体
class MyPhone(Phone,NFCReader,RemoteControl):
pass#这个语句没有实际的意义,只是用来填补这个语法
多个父类中,如果有同名成员,那么默认以继承顺序(从左到右)为优先级。
即:先继承的保留,后继承的被覆盖
**复写:子类继承父类的成员属性和成员方法后,如果对其“不满意,那么可以进行复写。在子类中重写定义同名的属性或方法即可
class Phone:
IMEI = None
producer = None
def call_by_4g(self):
print("4g通话")
#继承之后的类
class Phone2023(Phone):
producer = "HUAWEI" #复写父类属性
def call_by_4g(self):#对父类的属性和方法不满意,重写
print("5g通话")
调用父类同名成员:
一旦复写父类同名成员,那么类对象调用成员的时候,就会调用复写后的新成员,如果需要使用被复写的父类的成员,需要特殊的调用方式
方式1:调用父类成员
使用成员变量:父类名.成员变量
使用成员方法:父类名.成员方法(self)
方式2:使用super()调用父类成员
使用成员变量:super().成员变量
使用成员方法:super().成员方法()(不需要传入self指针)
都是在子类中进行处理
class Phone:
IMEI = None
producer = None
def call_by_4g(self):
print("4g通话")
#继承之后的类
class Phone2023(Phone):
producer = "HUAWEI" #复写父类属性
def call_by_4g(self):#对父类的属性和方法不满意,重写
print("5g通话")
#方式1
print(f"父类的厂商是:{Phone.producer}")
Phone.call_by_4g(self)
#方法2
print(f"父类的厂商是:{super().producer}")
phone = Phone2023()
phone.call_by_4g()
类型注解
调用方法时,ctrl+P可以弹出提示:
主要功能:
帮助第三方IDE工具对代码进行类型推断,协助做代码提示
帮助开发者自身对变量进行类型注解
支持的类型注解
函数(方法)形参列表和返回值的类型注解
类型注解的语法:
为变量设置类型注解:
变量:类型
var_1:int = 10
var_2:float = 3.1415
#类对象类型注解
class Student:
pass
stu:Student = Student()
#基础容器类型注解
my_list:list = [1,2,3]
my_dict:dict = {"nihao":666}
#容器类型详细注解
my_list : list[int] = [1,2,3]
my_tuple:tuple[str,int,bool] = ("nihao",20,True)
my_set : set[int] = {1,2,3}
my_dict:dict[str,int] = {"itmea":12}
除了使用 变量:类型,这种语法做注解外,也可以在注释中进行类型注解
type:类型
class Student:
pass
var_1 = random.randint(1,10) #type:int
var_2 = json.loads(data) #type:dict[str,int]
var_3 = func() #type:Student
一般,无法直接看出变量类型之时会添加变量的类型注解
对方法进行类型注解-形参注解
def 函数方法名(形参名:类型,形参名:类型,...):
pass
例如:
def add(x:int,y:int):
return x+y
def func(data:list):
pass
同时,函数(方法)的返回值也是可以添加类型注解的。
def 函数方法名(形参:类型,...,形参:类型)->返回值类型:
pass
def func(data:list) -> list:
return data
Union 类型 (进行联合类型注解)
from typing import Union
my_list: list[Union[str,int]] = [1,2,"itheima"]
#使用Union[类型,...,类型]可以定义联合数据类型注解,只要是符合这个里面的数据类型的数据都可以用
多态
指多种状态,即完成某个行为时,使用不同的对象会得到不同的状态
多态常作用在继承关系上,以父类做定义声明
以子类做实际工作
用以获得同一行为,不同状态
函数(方法)形参声明接收父类对象
实际传入父类的子类对象进行工作
class Animal:
def speak(selfs):
pass
class Dog(Animal):
def speak(selfs):
print("汪汪汪")
class Cat(Animal):
def speak(self):
print("喵喵喵")
def make_noise(animal:Animal):
animal.speak()
dog = Dog()
cat = Cat()
make_noise(dog)
make_noise(cat)
父类用来确定有哪些方法
具体的方法实现,由子类自行决定
抽象类:含有抽象方法的类称为抽象
抽象方法:方法体是空实现的(pass)
抽象类:包含了抽象的方法,要求子类必须实现
class AC:
def cool_wind(self):
pass
def hot_wind(self):
pass
包含抽象方法的类,称之为抽象类。抽象方法是指:没有具体实现的方法(pass)
**抽象类:用于顶层设计(设计标准*,以便子类做具体实现
也是对子类的一种软性约束,要求子类必须复写父类的一些方法。*
sql
数据:数据的存储、数据的计算
数据库:存储数据,涉及到->增删改查->
库->表->数据
show databases:查看有哪些数据库
use 数据库名 使用某个数据库
show tables 查看数据库内有哪些表
exit 退出Mysql的命令行环境
mysql -uroot -p
#进入页面
sql:Stutured Query Language 结构化查询语言,用于访问和处理数据库的标准计算机语言
sql语言就是操作数据库的专用工具
操作数据库的SQL语言,也基于功能,可以划分为4类:
-
数据定义:DDL 库的创建删除、表的创建删除等
Data Difinition Language
-
数据操纵:DML 新增数据、删除数据、修改数据
Data Manipulation Language
- 数据控制:DCL 新增用户、删除用户、密码修改、权限管理等
Data Control Language
- 数据查询:DDL 基于需求查询和计算数据
Data Query Language
SQL语言,大小写不敏感
Sql语言单行或多行书写,最后以;结束
sql支持注释:
- 单行注释:-- 注释内容(--后面一定要有一个空格)
- 单行注释:#注释内容(#后面可以不加空格,推荐加上)
- 多行注释:/* 注释内容 */
查看数据库
SHOW DATABASES;
使用数据库
USE 数据库名称;
创建数据库
CREATE DATABASE 数据库名称 [CHARSET UTF8]
删除数据库
DROP DATABASE 数据库名称;
查看当前使用的数据库
SELECT DATABASE();
DDL-表管理
SHOW TABLES;
删除表
DROP TABLE 表名称;
DROP TABLE IF EXISTS 表名称;
创建表
CREAT TABLE 表名称(
列名称 列类型,
列名称 列类型,
......
);
-- 列表类型有
int --整数
float --浮点数
varchar(长度) -- 文本,长度为数字,做最大长度限制
date -- 日期类型
timestamp -- 时间戳类型
use world;
show tables;
create table student(
id int,
name varchar(10),
age int
);
drop table student;
DML
掌握DML:INSERT数据插入
掌握DML:DELETE数据删除
掌握DML:UPDATE数据更新
基础语法:
INSERT INTO 表[(列1,列2,...,列N)] VALUES(值1,值2,...,值N)[,(值1,值2,...,值N),(值1,值2,...,值N)]
基础语法:
DELETE FROM 表名称 [WHERE 条件判断];
UPDATE 表名 SET 列=值 [WHERE 条件判断]; 更新数据
基础数据查询:
SELECT 字段列表|* FROM 表
SELECT id,name FROM student WHERE age < 33;
SELECT * FROM student where gender = "男"
分组聚合:
基础语法
SELECT 字段|聚合函数 FROM 表 [WHERE 条件] GROUP BY 列
- SUM 求和
- AVG 求平均
- MIN 求最小值
- MAX 求最大值
- COUNT(列|*) 求数量
select gender,name,avg(age) from student group by gender;
结果排序
可以查询的结果,使用ORDER BY 关键字,指定某个列进行排序,语法:
SELECT 列|聚合函数|* FROM 表
WHERE ...
GROUP BY ...
ORDER BY ... [ASC|DESC]
PYTHON 操作MySQL:
from pymysql import Connection
# 获取到MySQL数据库的连接对象
conn = Connection(
host = 'localhost', #主机名 (或IP地址)
port = 3306, #端口,默认3306
user = 'root', #账户名
password = 'Zhanglizhi6@' #密码
)
# 打印MySQL数据库软件信息
print(conn.get_server_info())
# 获取游标对象
cursor = conn.cursor()
conn.select_db("world") #先选择数据库
# 使用游标对象,执行sql语句
# cursor.execute("CREATE TABLE test_pymysql(id INT , info VARCHAR(255))")
cursor.execute("SELECT * FROM city ")
#单独插入一行数据,但是直接执行不会生效,需要进行代码确认
#cursor.execute("insert into student values(10001,'周杰伦',31,男)")
#通过commit确认
conn.commit()
# 获取查询结果
results: tuple = cursor.fetchall()
for r in results:
print(r)
# 关闭到数据库的链接
conn.close()
from pymysql import Connection
# 获取到MySQL数据库的连接对象
conn = Connection(
host = 'localhost', #主机名 (或IP地址)
port = 3306, #端口,默认3306
user = 'root', #账户名
password = 'Zhanglizhi6@' #密码
# autocommit = True 设置自动提交
)
# 打印MySQL数据库软件信息
print(conn.get_server_info())
# 获取游标对象
cursor = conn.cursor()
conn.select_db("world") #先选择数据库
# 使用游标对象,执行sql语句
# cursor.execute("CREATE TABLE test_pymysql(id INT , info VARCHAR(255))")
cursor.execute("SELECT * FROM city ")
#单独插入一行数据,但是直接执行不会生效,需要进行代码确认
#cursor.execute("insert into student values(10001,'周杰伦',31,男)")
#通过commit确认
conn.commit()
# 获取查询结果
results: tuple = cursor.fetchall()
for r in results:
print(r)
# 关闭到数据库的链接
conn.close()
create database py_sql charset utf8; #创建一个py_sql数据库
use py_sql;
create table orders( #创建一个表
order_date date,
order_id varchar(255),
money int,
province varchar(10)
)
RDD对象:弹性分布式数据集
数据存储在RDD内
各类数据的计算方法,也都是RDD的成员方法
RDD的数据计算方法,返回值依旧是RDD对象
from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local[*]").\
setAppName("test_spark_app")
sc = SparkContext(conf=conf)
rdd = sc.parallelize(数据容器对象)
#输出RDD的内容
print(rdd.collect())
rdd_list:list = rdd.collect()#将rdd对象输出为list容器
#reduce算子,对RDD对象进行两两聚合
num = rdd.reduce(lambda a,b:a+b)
#take算子:将RDD的前N个元素,组合成list返回
sc.parallelize([3,2,1,4,5,6]).take(5)
#count算子,统计rdd内有多少条数据,返回值为数值
saveAsTextFile算子
将RDD的数据写入文本文件中,
rdd = sc.parallelize([1,2,3,4,5])
rdd.saveAsTextFile("../data/output/test.txt")
闭包
在函数嵌套的前提下,内部函数使用了外部函数的变量,并且外部函数返回了内部函数,我们把这个使用外部函数变量的内部函数称为闭包
def account_create(initial_amount = 0):
def atm(num,deposit=True):
nonlocal initial_amount
if deposit:
initial_amount += num
print(f"存款:{num},账户余额:{initial_amount}")
else:
initial_amount -= num
print(f"存款:{num},账户余额:{initial_amount}")
return atm
fn = account_create()
fn(300)
fn(200)
fn(300,False)
#简单闭包
def account_create(initial_amount = 0):
def atm(num,deposit=True):
nonlocal initial_amount
if deposit:
initial_amount += num
print(f"存款:{num},账户余额:{initial_amount}")
else:
initial_amount -= num
print(f"存款:{num},账户余额:{initial_amount}")
return atm
fn = account_create()
fn(300)
fn(200)
fn(300,False)
#简单闭包
def outer(logo):
def inner(msg):
print(f"<{logo}><{msg}><{logo}>")
return inner
fn1 = outer("德华六")
fn1("你好")
fn1("阿里嘎多")
nonlocal 关键字修饰外部函数的变量才可以内部函数中修改它
闭包:额外的内存占用
装饰器:闭包、其功能就是在不破坏目标函数原有的代码和功能的前提下,为目标函数增加新功能。
def outer(func):
def inner():
print("我睡觉了")
func()
print("起床了")
@outer
def sleep():
import random
import time
print("睡眠中...")
time.sleep(random.randint(1,5))
sleep()
装饰器就是使用创建一个闭包函数,在闭包函数内调用目标函数。
可以达到不改动目标函数的同时,增加额外的功能。
设计模式:
设计模式是一种编程套路,可以极大的方便程序的开发。
最常见、最经典的设计模式,就是我们所学习的面向对象了。
单例模式:该模式主要目的是确保某一个类只有一个实例存在。在整个系统中,某个类只能出现一个实例时,单例对象就能派上用场。
- 定义:保证一个类只有一个实例,并提供一个访问它的全局访问点
- 适用场景:当一个类只能有一个实例,而客户可以从一个总所周知的访问点访问它时。
在一个文件中写方法
class StrTools:
pass
str_tool = StrTools()
在另一个文件中导入对象
from test import str_tool
s1 = str_tool
s2 = str_tool
print(s1)
print(s2)
工厂模式:
当需要大量创建一个类的实例的时候,可以使用工厂模式
即,从原生的使用类的构造去创建对象的形式
迁移前基于工厂提供的方法去创建对象的形式
class Person:
pass
class Worker(Person):
pass
class Student(Person):
pass
class Teacher(Person):
pass
worker = Worker()
stu =Student()
teacher = Teacher()
工厂模式
class Person:
pass
class Worker(Person):
pass
class Student(Person):
pass
class Teacher(Person):
pass
class Factory:
def get_person(self,p_type):
if p_type = 'w':
return worker()
elif p_type = 's':
return Student()
else:
return Teacher()
factory =Factory()
worker = factory.get_person('w')
stu = factory.get_person('s')
teacher = factory.get_person('t')
使用工厂类的get_person()方法去创建具体的类对象
优点:
- 大批量创建对象的时候有统一的入口,易于代码维护
- 当发生修改,仅修改工厂类的创建方法即可
- 符合现实世界的模式,即由工厂来制作产品(对象)
多线程并行执行
进程:就是一个程序,运行在系统之上,那么便称之这个程序为一个运行进程,并分配进程ID方便系统管理。
线程:线程是归属于进程的,一个进程可以开启多个线程,执行不同的工作,是进程的实际工作最小单位。
不同的进程是内存隔离,不同的进程拥有各自的内存空间
线程可以并行执行
socket
socket负责进程之间的网络数据传输,好比数据的搬运工
socket:进程之间通信的一个工具
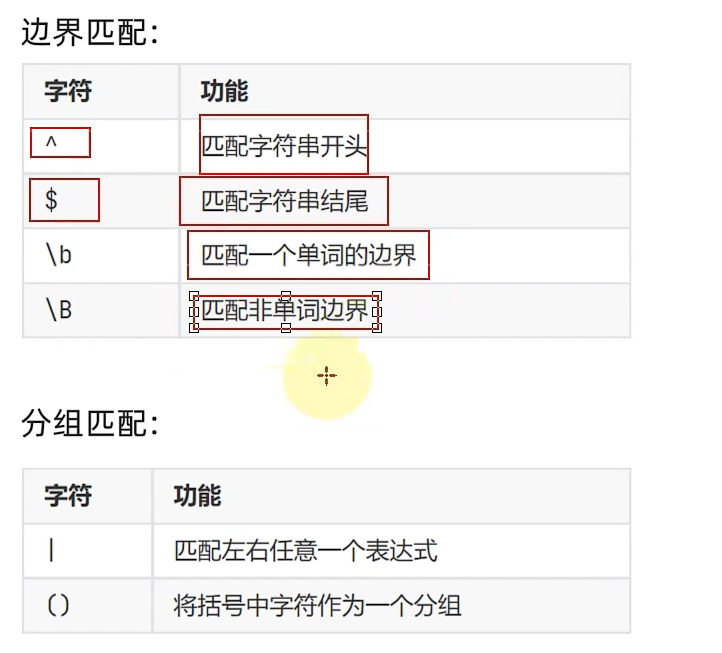
正则表达式
正则表达式:单个字符串来描述、匹配某个句法规则的字符串来检索,替换那些符合某个模式(规则)的文本
正则表达式:定义规则,并通过规则去验证字符串是否匹配
Python中正则表达式使用re模块,并基于re模块中三个基础方法来做正则匹配
分别是match、search,findall三个基础方法
re.match(规则匹配,被匹配字符串)
从被匹配字符串开头进行匹配,匹配成功返回匹配对象(包含匹配的信息),匹配不成功返回空.
s = 'python asefae python asfasdf python asf'
result = re.match('python',s)
print(result)
print(result.span())#匹配成功的下标
print(result.group)#匹配成功的值是什么
search(匹配规则,被比配字符串)
搜索整个字符串,找出匹配的。从前向后,找到第一个后,就停止了,不会继续向后
import re
s = 'python asefae python asfasdf python asf'
result = re.match('python',s)
print(result)
print(result.span())
print(result.group)
s1 = '12pythonaegfasegagaspython'
result = re.search('python',s1)
print(result)
print(result.span())
print(result.group())
findall(匹配规则,被匹配字符串)
匹配整个字符串,找到全部匹配项
import re
s = 'python asefae python asfasdf python asf'
result = re.match('python',s)
print(result)
print(result.span())
print(result.group)
s1 = '12pythonaegfasegagaspython'
result = re.search('python',s1)
print(result)
print(result.span())
print(result.group())
result = re.findall('python',s)
print(result)
import re
s ='asefasf$$@@$$%234243242asefase2342geer'
result = re.findall(r'\d',s)#字符串前面加上r,表示字符串转义字符无效,就是普通字符的意思
print(result)
import re
s ='asefasf$$@@$$%234243242asefase2342geer'
result = re.findall(r'\d',s) #找出所有数字字符
print(result)
result1 = re.findall(r'\W',s)
print(result1) #找出所有的特殊字符
result2=re.findall(r'[a-zA-Z0-9]',s)
print(result2) #找出所有的大小写字母和数字符号
result3=re.findall(r'[Adcea135@]',s)
print(result3)#找出字符串中特定的字符
import re
# r = '^[0-9a-zA-Z]{6,10}$'# 正则表达式里面不要乱带空格
# s ='12354687'
# print(re.findall(r,s))
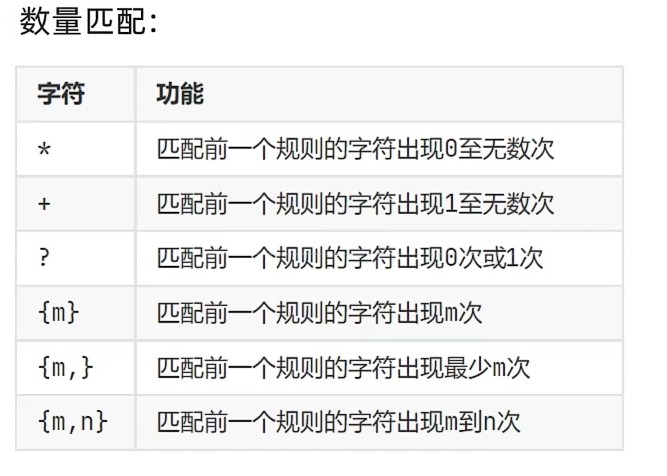
#匹配QQ号,要求纯数字,长度为5-11
r ='[1-9][0-9]{4,10}' #第一位不为0 带有^ $时,就是从开头到结尾都要匹配,不带就是取子串
s = '012345678'
print(re.findall(r,s))#取它子串
#匹配邮箱地址
r1 = '^[\w-]+(\.[\w]+)*@(qq|163|gmail)(\.[\w-]+)$'
s ='[email protected]'
print(re.findall(r1,s))

递归
递归在编程中是一种非常重要的算法
递归:即方法(函数)自己调用自己的一种特殊编程方法
def func():
if ...:
func()
return ...