NumPy 是 Python 科学计算的基础包,几乎所有用 Python 工作的科学家都利用了的强大功能。此外,它也广泛应用在开源的项目中,如:Pandas、Seaborn、Matplotlib、scikit-learn等。

Numpy全称Numerical Python。它提供了2种基本的对象:ndarray与ufunc。
ndarray是存储单一数据的多维数组,它相对于list列表可以快速的节省空间,提供数组化的算数运算和高级的广播功能。
ufunc是能够对数组进行处理的函数,这些标准的数学函数对整个数组的数据进行快速运算,且不需要编写循环。
Numpy其他优点:
- 它是读取/写入磁盘上的阵列数据和操作存储器映像文件的工具
- 它具有线性代数、随机数生成以及傅里叶变换的能力
- 它集成了C、C++、Fortran代码的工具
虽然Numpy库具有很多的优点,但是其默认不在标准库中,如果你直接安装anaconda,它会自带Numpy库。
但是,如果你是直接安装的Python工具,那么需要通过如下命令安装之后才能使用,具体命令如下所示:
pip install numpy
下面,我们详细介绍Numpy库的使用方式。
生成Numpy数组
从已有数据中创建数组
一般来说,对于一些基础的数据,我们在Python中都是直接使用list。
而如果这个时候,需要进行大量的运算,我们不妨将list列表转换为numpy数组进行计算。转换的方式如下所示(我们使用numpy时一般将其重命名np使用):
import numpy as np
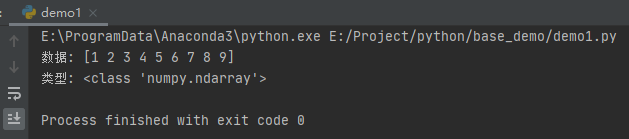
list1 = [1, 2, 3, 4, 5, 6, 7, 8, 9]
nd = np.array(list1)
print("数据:", nd)
print("类型:", type(nd))
运行之后,效果如下:
通过random生成数组
在深度学习中,我们经常会通过随机数创建一些数组进行测试,比如创建符合正态分布的随机数,又或者打乱数据等等。
而这些都可以通过numpy.random模块进行操作。下面,博主列出了一个常用随机函数表格:
| 函数 | 意义 |
|---|---|
| numpy.random.random | 生成0到1之间的随机数 |
| numpy.random.uniform | 生成均匀分布的随机数 |
| numpy.random.randn | 生成标准正态分布的随机数 |
| numpy.random.randint | 生成随机整数 |
| numpy.random.normal | 生成正态分布 |
| numpy.random.shuffle | 随机打乱顺序 |
| numpy.random.seed 设置随机数种子 | |
| numpy.random.random_sample | 生成随机的浮点数 |
下面,我们举一个简单的使用例子:
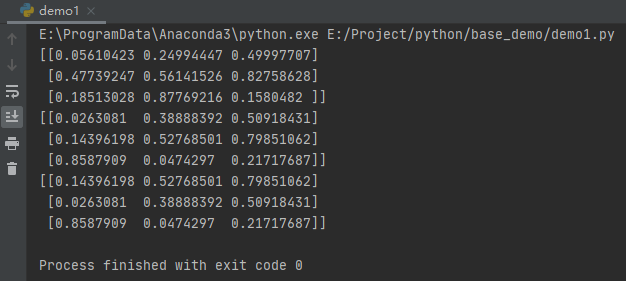
import numpy as np
#生成3行3列0到1的随机数
nd1 = np.random.random([3, 3])
print(nd1)
#生成3行3列0到1的浮点数
nd2 = np.random.random_sample([3, 3])
print(nd2)
#打乱nd2的数据
np.random.shuffle(nd2)
print(nd2)
运行之后,效果如下:
创建多维数组
在上面随机数的数组创建中,我们看到了其实numpy可以创建多维数组,而如果不使用随机数的话,我们还可以通过下面表格的函数创建numpy数组。
| 函数 | 意义 |
|---|---|
| np.zeros((3,4)) | 创建3行4列全部为0的数组 |
| np.ones((3,4)) | 创建3行4列全部为1的数组 |
| np.empty((2,4)) | 创建2行4列的空数组,空数组中的值并不为0,而是为初始化的垃圾值 |
| np.zeros_like(nd) | 以nd相同的维度创建一个全为0的数组 |
| np.ones_like(nd) | 以nd相同的维度创建一个全为1的数组 |
| np.empty_like(nd) | 以nd相同的维度创建空数组 |
| np.eye(5) | 创建一个5*5的矩阵,对角线为1,其余为0 |
| np.full((2,2),111) | 创建一个2行2列全是111的数组,第2个参数为指定值 |
下面,我们随机举些列子:
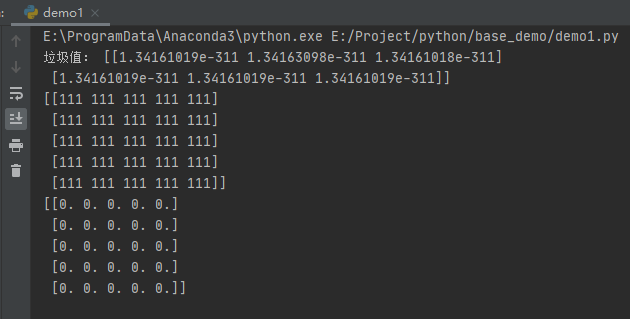
import numpy as np
#创建2*3的空数组
nd1 = np.empty((2, 3))
print("垃圾值:", nd1)
#创建5*5,值全为111的数组
nd2 = np.full((5, 5), 111)
print(nd2)
#创建5*5值全为0的数组
nd3 = np.zeros((5, 5))
print(nd3)
运行之后,效果如下:
arange与linspace生成数组
首先,我们来看看arange函数的定义:
arange([start,]stop[,step,],dtype=None)
其中,start与stop用来指定范围,step指定步长。比如说我们生成一个倒叙的数组[9,8,7,6,5],可以发现它们的步长就是-1。示例如下:
nd = np.arange(9, 4, -1)
print(nd)
这里就不运行了,输入就是[9,8,7,6,5]。
接着,我们再来看看linspace函数的定义:
linspace(start,stop,num=50,endpoint=True,retstep=False,dtype=None)
linspace函数可以根据输入的指定数据范围以及等份数量,自动生成一个线性的等分向量。
简单的理解就是,我们设置一个区间(start,stop),然后再次设定生成num个数据。
那么通过(stop-start+1)/num,就算出了这些数据的步长,而每个数据依次加减这个步长就是2边的数据。
而不需要像arange取指定步长,linspace函数会自己计算出来。示例如下:
nd = np.linspace(9, 4, 6)
print(nd)
这里代表就是9到4输出6个数据,且每个数间隔一样,那么肯定会输出[9,8,7,6,5,4]。
元素的截取
既然创建了Numpy数组,那么我们就需要获取数组中的元素进行操作。那么如果获取Numpy数组中指定的元素呢?这里,博主列出了一个表格:
nd为一维数组时:输出[0 1 2 3 4 5 6 7 8 9](索引0开始)
nd为二维数组时:(索引0开始)
[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]
[15 16 17 18 19]
[20 21 22 23 24]]
| 公式 | 意义 |
|---|---|
| nd[3] | 获取数组的第4个元素,如果为多维数组,获取第4行([3]) |
| nd[3:5] | 获取数组的第4个元素到第5个元素([3,4],不包括右边元素5) |
| nd[1:5:2] | 获取数组索引1到索引5步长间隔为2的元素([1,3]),不包括右边元素5 |
| nd[::-2] | 获取倒叙,间隔2的元素([9 7 5 3 1]) |
| nd[1:3, 1:3] | 获取1,2行,1,2列的数据([[ 6 7][11 12]]),不包括3行,3列 |
| nd[(nd > 3) & (nd < 10)] | 获取大于3小于10的数据([4 5 6 7 8 9]) |
| nd[[1,2]] | 获取1,2行的所有列数据([[ 5 6 7 8 9][10 11 12 13 14]]) |
| nd[:,1:3] | 获取所有行的1到3列([[ 1 2][ 6 7][11 12][16 17][21 22]]),不包括3列 |
算术运算
对应元素相乘
简单的理解就是2个维度相同的Numpy数组,各个对应位置互相相乘得到的一个新的Numpy数组。图解如下:
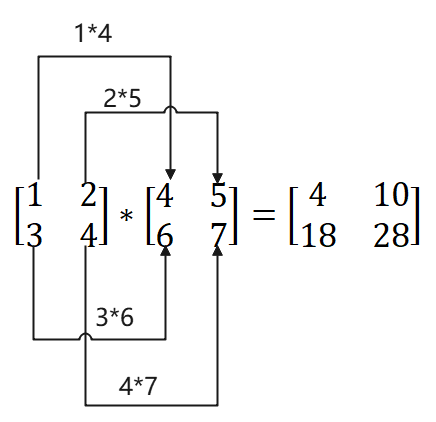
将上面的图转换为代码如下所示:
import numpy as np
A = np.array([[1, 2], [3, 4]])
B = np.array([[4, 5], [6, 7]])
print(A * B)
print(np.multiply(A, B))
运行结果与上图一致,当然Numpy数组对应元素相乘有2种方式:一种直接通过“*”号进行运算,一种是通过multiply()函数进行运算,结果一样。
有时候我们在进行图像处理时,会对对应的像素进行乘积运算,但每个像素的变更运算是一样的,难道我们创建一个同样维度的数组进行运算吗?显然不划算。
假如,每个像素只是+2,或者*2,我们可以直接将Numpy数组加乘这个值即可。如下面代码所示:
A = np.array([[1, 2], [3, 4]])
print(A + 2)
print(A * 2)
运算之后,效果如下:
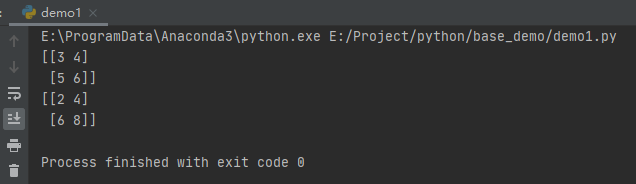
点积运算
点积就是Dot Product,又称之为内积,也就是我们线性代数中常常用到的矩阵运算,在Numpy中的函数为:np.dot(),其具体定义如下所示:
np.dot(a,b,out=None)
运算的过程如下所示:
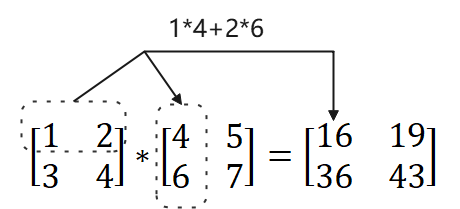
简单的理解点积就是第1行第1列,对应元素乘完相加就是矩阵的第1个值。第1行第2列,对应元素相乘得到第2个值,之后的以此类推。代码如下:
A = np.array([[1, 2], [3, 4]])
B = np.array([[4, 5], [6, 7]])
print(np.dot(A, B))
点积运算的2个数组必须行列数相等才能运算,不然无法进行点积运算。
数组变形
改变向量的维度
有过OpenGL开发经验的读者,应该都使用过改变向量的维度,这也是深度学习中常常需要的基础处理步骤。而Numpy改变维度的函数如下表所示:
| 函数 | 意义 |
|---|---|
| nd.reshape | 将向量nd维度进行改变,不修改向量本身 |
| nd.resize | 将向量nd维度进行改变,修改向量本身 |
| nd.T | 将向量nd进行转置 |
| nd.ravel | 将向量nd进行展平,即多维变一维,不会产生原向量的副本 |
| nd.flatten | 将向量nd进行展平,即多维变一维,返回原数组的副本 |
| nd.squeeze | 只能对一维数组进行降维,多维不会报错,但没有任何影响 |
| nd.transpose | 对高维矩阵进行轴对换 |
示例代码如下所示:
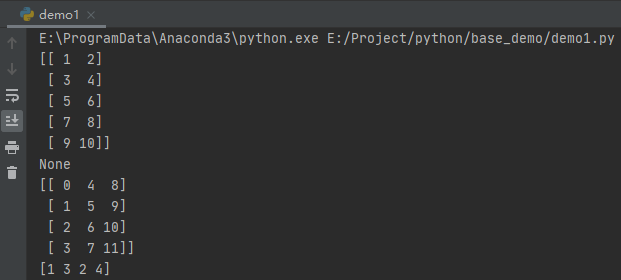
# 改变向量维度
nd = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
print(nd.reshape(5, 2))
nd = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
print(nd.resize(5, 2))
# 行列对换
nd = np.arange(12).reshape(3, 4)
print(nd.T)
# 按照列优先展平,没有参数按照行优先展平
nd = np.array([[1, 2], [3, 4]])
print(nd.ravel('F'))
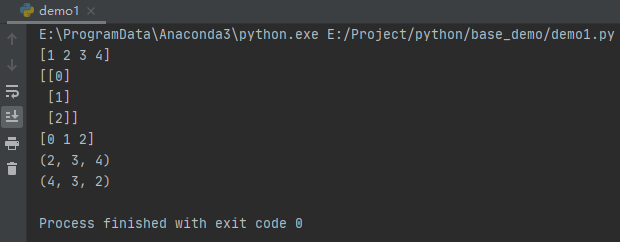
# 展平为一维
nd = np.array([[1, 2], [3, 4]])
print(nd.flatten())
# 将矩阵中含1的维度去掉
nd = np.arange(3).reshape(3, 1)
print(nd)
print(nd.squeeze())
# 矩阵轴对换
nd = np.arange(24).reshape(2, 3, 4)
print(nd.shape)
print(nd.transpose().shape)
比如transpose()函数,在RGB转GBR时就可以用到
合并数组
除了改变数组维度之外,我们还需要合并数组。比如在对股票进行处理的时候,需要将多个表格进行合并等。下面,也有一张合并函数的表格:
| 函数 | 意义 |
|---|---|
| np.append | 内存占用大 |
| np.concatenate | 没有内存问题 |
| np.stack | 沿新轴加入一系列数组 |
| np.hstack | 堆栈数组垂直顺序(行) |
| np.vstack | 堆栈数组垂直顺序(列) |
| np.dstack | 堆栈数组按顺序深入,作用于第3维 |
| np.vsplit | 将数组分解成垂直的多个子数组的列表 |
其中,stack、hstack、dstack要求合并的数组具有相同的shape,也就是维度必须一模一样。
而append与concatenate操作的数组必须有相同的行数或者列数(满足一个即可)。
append、concatenate以及stack都有一个axis参数,控制数组的合并是按行还是列进行。
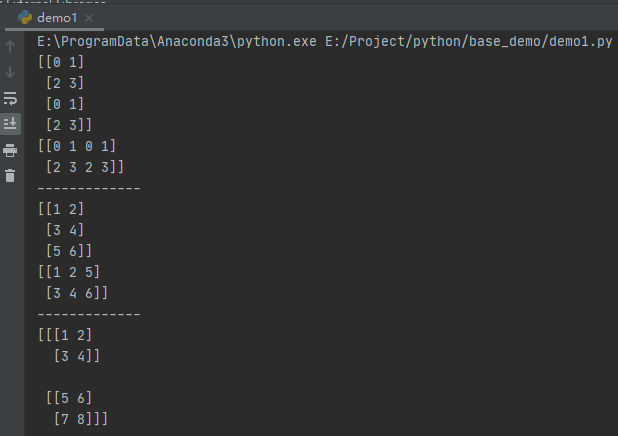
举例如下:
# append
a = np.arange(4).reshape(2, 2)
b = np.arange(4).reshape(2, 2)
print(np.append(a, b, axis=0))
print(np.append(a, b, axis=1))
print("-------------")
# concatenate
a = np.array([[1, 2], [3, 4]])
b = np.array([[5, 6]])
print(np.concatenate((a, b), axis=0))
print(np.concatenate((a, b.T), axis=1))
print("-------------")
# stack
a = np.array([[1, 2], [3, 4]])
b = np.array([[5, 6], [7, 8]])
print(np.stack((a, b), axis=0))
运行之后,效果如下:
速度优势
在前面我们介绍time库时,就详细讲解了time也可以进行算法时间复杂度的测试。今天,我们就来测试一下,Numpy与普通运算哪个更快。
首先,我们计算100万以内每个数的sin值。常规的代码如下所示:
import numpy as np
import time
a = [i for i in range(1, 1000001)]
start_time = time.perf_counter()
for i, num in enumerate(a):
a[i]=np.sin(num)
print("执行的时长为:", time.perf_counter() - start_time)
然后我们进行Numpy计算的测试:
a = [i for i in range(1, 1000001)]
start_time = time.perf_counter()
a = np.sin(num)
print("执行的时长为:", time.perf_counter() - start_time)
运行之后两者时间的对比如下:
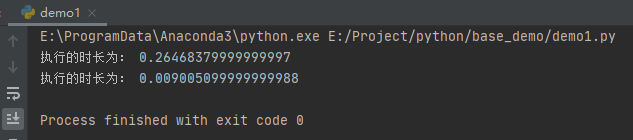
标签:Python,科学计算,nd,print,数组,numpy,np,NumPy,Numpy From: https://www.cnblogs.com/arena/p/17728546.html可以看到numpy的速度比math快多了。而且如果是大量的点积运算,Numpy与普通的方式对比几乎能快400倍的速度。所以,在深度学习,科学计算等领域,Numpy具有绝对的优势。