本篇文章的内容都是基于以下作者“等我复活再拆塔”的博客来写的,记录自己学完之后的总结以及学习过程中遇到的困惑。
利用朴素贝叶斯原理过滤垃圾邮件(TF-IDF算法)_等我复活再拆塔的博客-CSDN博客
数据集我也是下载的trec06c,06表示是2006年发布的,c表示是(Chinese)中文,同时还有trec06p,这个版本的数据集是英文的邮件,我当时下载的时候没看清楚,下了两次都是下的英文版本的数据集。
下载完成后解压并打开trec06c文件夹,可以看到有三个文件夹,分别是data,delay和full,下面来介绍一下这三个文件夹里的东西是什么
![]() 编辑
编辑
第一个文件夹data文件夹打开后可以看到有000-215子文件夹,这里的图片我只截取了一部分,再打开000这个子文件夹就可以看到邮件了,一个子文件夹下有0-299共300封邮件。整个data文件夹下的邮件大概有216*300=64800封邮件,将近6万封。

![]() 编辑
编辑

![]() 编辑
编辑
由于邮件太多,我只选取了000,001这两个文件夹下的邮件,共600封邮件。
trec06c下的第二个文件夹delay在此算法中并没有用到,所以此处并不介绍,略过。
下面来介绍trec06c下的第三个文件夹full,打开full文件夹可以看到一个名为index的文件,此文件也并没有具体的文件格式,但是我们双击之后可以选择用记事本打开,可以看到一下内容:

![]() 编辑
编辑
可以看到内容是一行一行的,我们先来看第一行内容:spam ../data/000/000,这一行的内容分为两部分,第一部分是“spam”,第二部分是一个路径“../data/000/000”。
“../data/000/000”,下面来介绍一下这个的含义,当前的index文件处于full文件夹下,而"."这个就代表当前这个文件所处的文件夹,这里是full文件夹,而“..”代表当前文件夹的父目录,当前文件夹是full,full的父目录便是trec06c文件夹,..便回到了trec06c文件夹,通过/data/000/000便可找到一封邮件,“spam”则表示这封邮件为垃圾邮件。
这个文件的用处
介绍完数据集后,下面来介绍如何对数据集进行处理,分为三部分,提取正文,中文分词去除停用词,特征提取,这一部分的内容就不写了,在作者“等我复活再拆塔”的博客中写的很清楚。利用朴素贝叶斯原理过滤垃圾邮件(TF-IDF算法)_等我复活再拆塔的博客-CSDN博客
在博客中有这样一句话 通过在CSV文件中VLOOKUP一下,可以得到这样的一个文件,即把邮件正文和标注对应了,因为是生成了两个csv文件,但是作者的两个csv文件合到了一起,当初还以为是通过代码实现的,百度了半天也没找到方法,后来才发现是excel表格的vlookup方法实现的,下面介绍怎么使用vlookup函数将两个表格合到一起。
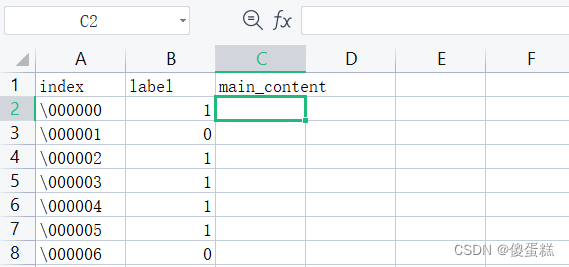
第一步,打开index_dic.csv文件,在文件的第三列,即字母C的下面,label的右边格子处写上main_content,然后再绿色框框中填入一下内容:=vlookup(A2,main_content_dic.csv!$A$2:$B$601.2.0),然后回车一下就完成一个正文的填写
![]() 编辑
编辑
再往下拖拽就可完成全部正文的填充。
标签:垃圾邮件,full,trec06c,000,贝叶斯,算法,文件夹,data,邮件 From: https://www.cnblogs.com/liuyujie-zhang/p/16597830.html