184_Python 在 Excel 和 Power BI 绘制堆积瀑布图
一、背景
在 2023 年 8 月 22 日 微软 Excel 官方宣布:在 Excel 原生内置的支持了 Python。博客原文
笔者第一时间就更新到了 Excel 的预览版,通过了漫长等待分发,现在可以体验了,先来看看效果。

- 在 Excel 公式选项卡下 Python 菜单
- 原来的 Excel 公示栏,左边多了一个
PY的绿高亮区域输入 Python 代码。 - 在单元格区域直接可以展示出 Python 输出结果。
Power BI 公共 web 效果:https://demo.jiaopengzi.com/pbi/184-full.html
二、如何体验
1、首先需要是微软365用户才可以,其他用户目前无法体验,即便是发送给别人也看不到效果如下:

2、当前时间 Python 在 Excel 还是属于预览功能,所以需要把自己的 Excel 切换到预览频道。具体方法可以参考官方:https://insider.microsoft365.com/en-us/join/windows
3、需要联网.
Python 在云中运行
Excel 中的 Python 计算使用标准版本的 Python 语言在 Microsoft 云中运行。 Excel 中的 Python 附带 Anaconda 通过标准的安全分发提供的一组核心 Python 库。
无需本地版本的 Python 就可以在 Excel 中使用 Python。 如果计算机上安装了本地版本的 Python,则对 Python 安装所做的任何自定义都不会反映在 Excel 计算中的 Python 中。
由于 Excel 中的 Python 计算在云中运行,因此需要使用 Internet 访问才能使用该功能。
4、参考文档,认真阅读
Python 简介 - 培训 |Microsoft Learn
在 Excel 中将Power Query数据与 Python 配合使用
5、Excel 内置 Python 默认使用的开源库
Excel 在云端运行的时候就导入了下图的包,可以在自己写代码的时候不用导入。但强烈建议自己还是单独写一下导入的过程。注意一些约定俗成的导包的别名。
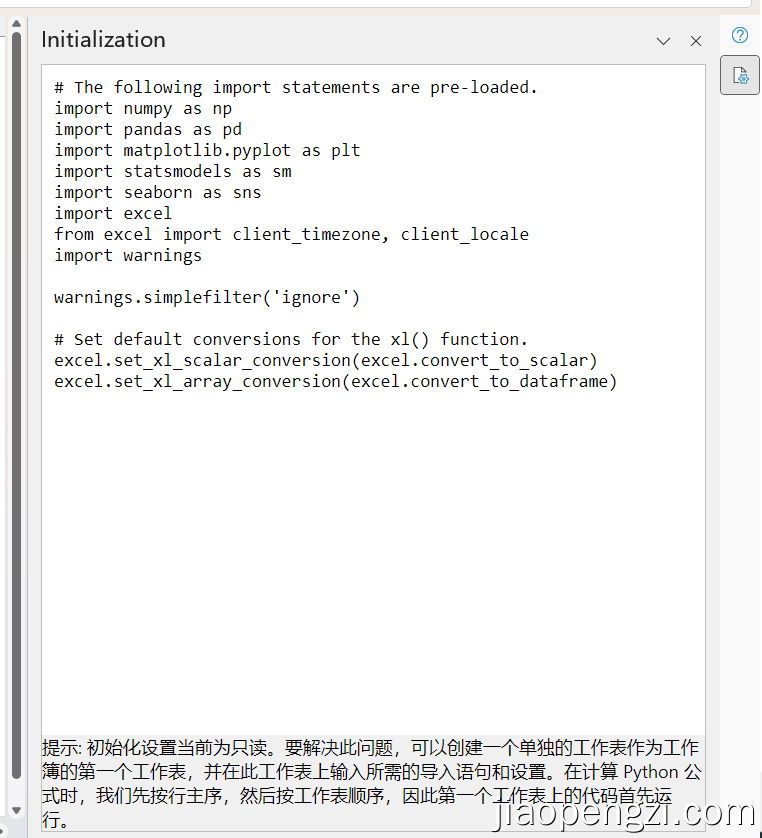
云端开源库列表requirements.txt,在本地体验和调试。
matplotlib==3.7.3
numpy==1.25.2
pandas==2.1.0
seaborn==0.12.2
statsmodels==0.14.0
astropy==5.3.3
beautifulsoup4==4.12.2
imbalanced-learn==0.11.0
ipython==8.15.0
gensim==4.3.2
networkx==3.1
Pillow==10.0.0
datasette-pytables==2.0.1
torch==2.0.1
PyWavelets==1.4.1
scikit-learn==1.3.0
scipy==1.11.2
snowballstemmer==2.2.0
statsmodels==0.14.0
sympy==1.12
tabulate==0.9.0
spyder-kernels==2.4.4
本地导入
pip install -r requirements.txt
三、体验应用
在 Excel 中我们体验自定义画图:堆积瀑布图
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
df = xl("B3:D15", headers = True) # 创建数据集
decimal_places = 0 # 小数位数 默认 0 位
color_base = ['#213058', '#8E599F', '#ADB175'] # 基础颜色可自行扩展,最少保证三个颜色。
column_names = df.columns.tolist() # 获取数据集字段名称
df_pivot = df.pivot_table(index=column_names[0], columns=column_names[1], values=column_names[2], aggfunc='sum').fillna(0) # 透视表
df_pivot['cumulative'] = df_pivot.sum(axis=1).cumsum() # 计算累计值
df_pivot.loc['Total'] = df_pivot.sum() # 添加总计行
unique_wd_values = df_pivot.columns[:-1].tolist() # 获取分类列表
# 颜色处理
if len(unique_wd_values) > len(color_base): # 如果 wd 数量大于颜色数量,需要随机添加颜色
color_base += [f'#{np.random.randint(0, 0xFFFFFF):06x}' for _ in range(len(unique_wd_values) - len(color_base))]
elif len(unique_wd_values) < len(color_base): # 如果 wd 数量小于颜色数量,需要截取颜色
color_base = color_base[:len(unique_wd_values)]
colors = {wd: color_base[i] for i, wd in enumerate(unique_wd_values)} # 分类颜色字典
bar_width = 0.5 # 柱形图宽度
opacity = 0.95 # 柱形图透明度
width = 10 # 宽度为 10 英寸 默认 6.4 英寸
height = 7.5 # 高度为 7.5 英寸 默认 4.8 英寸
fig, ax = plt.subplots(figsize=(width, height)) # 创建子图
bottom = np.zeros(len(df_pivot)) # 初始化底部值
bottom[1:-1] = df_pivot['cumulative'].iloc[:-2].tolist() # 更新底部值为累计值
# 绘图
for wd, color in colors.items(): # 遍历每个分类
values = df_pivot[wd].tolist() # 获取每个分类的值
bars = ax.bar(df_pivot.index, values, bar_width, color=color, alpha=opacity, bottom=bottom, edgecolor='black') # 绘制柱形图
for i, value in enumerate(values): # 添加标签
if value > 0: # 值大于 0 才添加标签
ax.text(i, bottom[i] + value / 2, f'{value:,.{decimal_places}f}', color='white', fontsize=12, ha='center', va='center')
bottom += values # 更新底部值
for i, value in enumerate(values): # 添加连接线
if i < len(values) - 1 and wd == unique_wd_values[-1]: # 最后一个分类不添加连接线
ax.plot([i + 0.75, i + 0.25], [bottom[i], bottom[i]], color='black', linestyle='--') # 虚线连接线
# 总计标签
totals = np.sum(df_pivot.drop('cumulative', axis=1), axis=1) # 计算每个分类的总计值
for i, total in enumerate(totals): # 添加标签
ax.text(i, bottom[i] + 100, f'{total:,.{decimal_places}f}', color=color_base[0], fontsize=12, fontweight='bold', ha='center', va='center') # 总计标签
ax.spines['top'].set_visible(False) # 上边框隐藏
ax.spines['right'].set_visible(False) # 右边框隐藏
ax.spines['bottom'].set_linewidth(1) # 下边框宽度
ax.spines['left'].set_linewidth(0.5) # 左边框宽度
# 图例
legend_elements = [plt.Rectangle((0, 0), 1, 1, fc=colors[key], ec='black', alpha=opacity) for key in colors] # 图例元素
ax.legend(legend_elements, colors.keys(), title='', fontsize=12) # 图例
# 标题
ax.set_title('Title', fontsize=16, fontweight='bold', color=color_base[0], pad=16)
plt.show() # 显示图形
在 Power BI 中画图效果
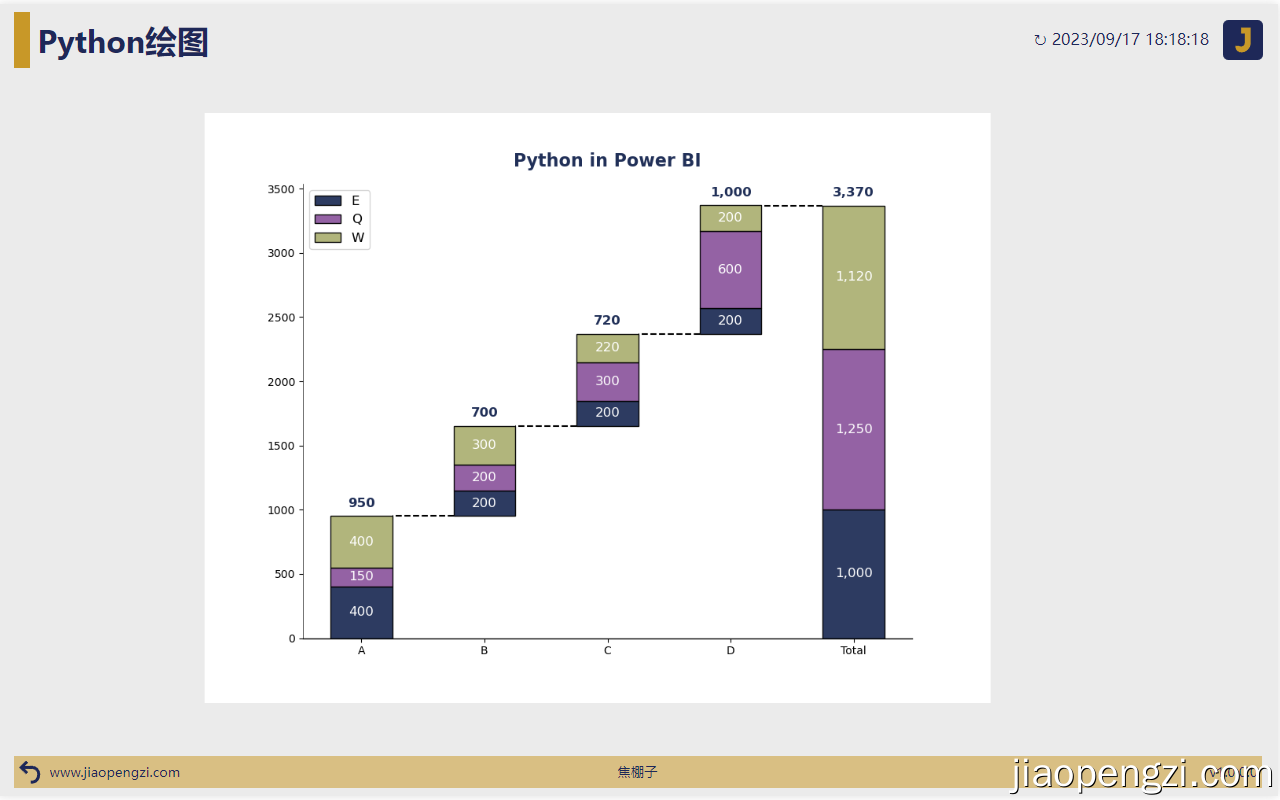
附件内容如下,可以自行下载体验:
附件下载
https://jiaopengzi.com/3044.html
请关注
全网同名搜索 焦棚子
如果对你有帮助,请 点赞、关注、三连 支持一下,这是我们更新的动力。
我们承接 Power BI 相关业务:培训、报告制作与部署、咨询服务等。

by 焦棚子
标签:wd,Power,Python,Excel,color,values,df From: https://www.cnblogs.com/jiaopengzi/p/17711533.html