首先,访问github上的LIME源码,https://github.com/marcotcr/lime
将代码克隆至本地。我用的是pycharm打开进行阅读。下载下来后使用
pip install . ,别用pip install lime,使用后面的就不会使用源码中的Lime,阅读源码使用printf大法就会失效了。
可以看一下readme文档中提到的一个最简单的tutorial,以它为切入点开始源码的阅读。
将代码克隆至本地。我用的是pycharm打开进行阅读。下载下来后使用
pip install . ,别用pip install lime,使用后面的就不会使用源码中的Lime,阅读源码使用printf大法就会失效了。
可以看一下readme文档中提到的一个最简单的tutorial,以它为切入点开始源码的阅读。
https://github.com/marcotcr/lime/blob/master/doc/notebooks/Lime%20-%20basic%20usage%2C%20two%20class%20case.ipynb
这篇tutorial notebook的前半部分是在调用sklearn中的random forest进行文本分类。是一个二分类。
接下来,就要用到LIME模型对随机森林进行解释了
首先,使用sklearn中的Pipeline,目的是为了能直接输入纯文本就能得到预测结果,相当于是对模型的封装
https://github.com/marcotcr/lime/blob/master/doc/notebooks/Lime%20-%20basic%20usage%2C%20two%20class%20case.ipynb
这篇tutorial notebook的前半部分是在调用sklearn中的random forest进行文本分类。是一个二分类。
接下来,就要用到LIME模型对随机森林进行解释了
首先,使用sklearn中的Pipeline,目的是为了能直接输入纯文本就能得到预测结果,相当于是对模型的封装


上面这几行代码就完成了对随机森林的解释 接下来,就需要对源码进行阅读了
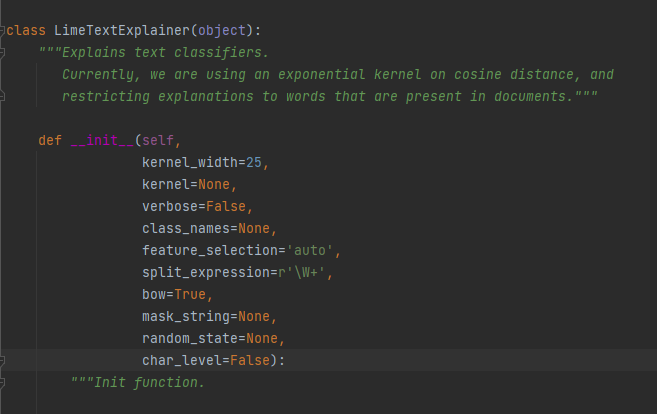
首先来到LimeTextExplainer类中,我来说明一下各个参数的意义
kernel_width,就是论文中的计算权重的公式中的
首先来到LimeTextExplainer类中,我来说明一下各个参数的意义
kernel_width,就是论文中的计算权重的公式中的
 kernel是一个函数,就是论文中的计算权重的这个Πx(z)函数,在源码中,给出了下面的公式,其中d就是一个距离向量,在LIME中,会通过随机的方式在原始样本点周围生成许多的新样本点,这个d向量的形式如下:
[原始样本点与原始样本点距离,第一个随机样本点与原始样本点的距离,第二个随机样本点与原始样本点的距离,第三个......],依次类推。
不过可以看到,源码中的公式好像比论文中多了一个开根号的操作。我没有找到这么做的原因,留着待日后探究。
kernel是一个函数,就是论文中的计算权重的这个Πx(z)函数,在源码中,给出了下面的公式,其中d就是一个距离向量,在LIME中,会通过随机的方式在原始样本点周围生成许多的新样本点,这个d向量的形式如下:
[原始样本点与原始样本点距离,第一个随机样本点与原始样本点的距离,第二个随机样本点与原始样本点的距离,第三个......],依次类推。
不过可以看到,源码中的公式好像比论文中多了一个开根号的操作。我没有找到这么做的原因,留着待日后探究。

verbose用来控制输出的详细程度,true就会输出一些相关信息,false就不会输出
class_names:类别标签的名字,用来可视化用的
feature_selection:这是用来指示使用哪种特征选择方法的变量。特征选择指的是在LIME中,对于一个纯文本,会将它变成一个全1的向量,每一个1代表句子中的一个单词,如果这个文本特别长的话,那么特征的维数可能会特别多。而我们要做的是可解释性,要计算特征的重要程度,特征数量太多人看不过来(论文中就这么说的),所以要选几个代表性的特征,将他们的重要程度算出来就行了。具体的方法在文章之后继续将。
split_expression:切分纯文本的函数,用来对文本进行处理的。这里的'rW+'是一个正则表达式
bow:设置为true,表示采用词袋模型,将不同位置上的相同的词语视为同一个,设置为false,表示将不同位置上的相同的词语设为不同的。
mask_string:如果bow为true,没有作用,如果bow为false,会用来mask掉那些应该被删除的样本中的词。
random_state:一个整数或者numpy,用来生成随机数的东西。
char_level:是否要在字符级别上对文本进行处理。
接下来,我们看这个类当中的explain_instance函数
verbose用来控制输出的详细程度,true就会输出一些相关信息,false就不会输出
class_names:类别标签的名字,用来可视化用的
feature_selection:这是用来指示使用哪种特征选择方法的变量。特征选择指的是在LIME中,对于一个纯文本,会将它变成一个全1的向量,每一个1代表句子中的一个单词,如果这个文本特别长的话,那么特征的维数可能会特别多。而我们要做的是可解释性,要计算特征的重要程度,特征数量太多人看不过来(论文中就这么说的),所以要选几个代表性的特征,将他们的重要程度算出来就行了。具体的方法在文章之后继续将。
split_expression:切分纯文本的函数,用来对文本进行处理的。这里的'rW+'是一个正则表达式
bow:设置为true,表示采用词袋模型,将不同位置上的相同的词语视为同一个,设置为false,表示将不同位置上的相同的词语设为不同的。
mask_string:如果bow为true,没有作用,如果bow为false,会用来mask掉那些应该被删除的样本中的词。
random_state:一个整数或者numpy,用来生成随机数的东西。
char_level:是否要在字符级别上对文本进行处理。
接下来,我们看这个类当中的explain_instance函数
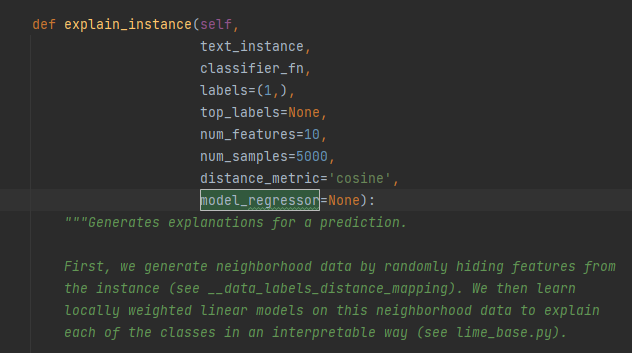
同样,先来理清这个函数的参数
text_instance就是纯文本,输入的数据
classifier_fn:就是我们要解释的模型,一个函数,输入纯文本数据,输出预测概率。
labels:在分类模型中,有多个类别,LIME的解释是针对每一类进行解释,这里就可以写要解释哪些类
top_labels:如果不是None,忽视传入的labels,去解释k个预测概率最大的标签,k就是这个top_labels
num_features:前面说过,输入的纯文本可能会由于过长导致特征数量巨大,这里指定最大的特征数量
num_samples:Lime会根据原样本随机生成新样本,这里就是指定新生成的随机样本数(包含了原样本)
distance_metric:距离评估方法,用来计算上面提到的距离向量的。
model_regressor:指定用来解释的模型,代码中默认使用岭回归
接下来,探究这个函数里面干了什么
同样,先来理清这个函数的参数
text_instance就是纯文本,输入的数据
classifier_fn:就是我们要解释的模型,一个函数,输入纯文本数据,输出预测概率。
labels:在分类模型中,有多个类别,LIME的解释是针对每一类进行解释,这里就可以写要解释哪些类
top_labels:如果不是None,忽视传入的labels,去解释k个预测概率最大的标签,k就是这个top_labels
num_features:前面说过,输入的纯文本可能会由于过长导致特征数量巨大,这里指定最大的特征数量
num_samples:Lime会根据原样本随机生成新样本,这里就是指定新生成的随机样本数(包含了原样本)
distance_metric:距离评估方法,用来计算上面提到的距离向量的。
model_regressor:指定用来解释的模型,代码中默认使用岭回归
接下来,探究这个函数里面干了什么

第一步构造了一个IndexedString类,这个类是用来处理纯文本的,可以类比nlp中常用的数据预处理。会生成word2idx,idx2word表。 第二步构造一个TextDomainMapper类,这个类用来后处理的,包括将id转换成word,或者可视化 接下来这个函数用来根据原样本生成随机扰动生成的数据,所有数据通过原模型生成的预测概率,以及距离向量。

其中,invsered_data就是将输入的文本经过处理后所得到的词汇表的大小
接下来,看一下__data_labels_distances函数
这个函数就是通过随机数的方法来确定要把原始样本中的哪些词抹掉,在inverse_removing函数里面会进行对原始样本的处理操作。 接下来回到explain_instance函数,继续阅读剩下的代码

注意两行 第一个是生成了一个Explanation类,这个类是用来输出解释结果以及可视化用的 第二个是self.base.explain_instance_with_data这个函数,这个函数就开始进行解释操作了 接下来,看一下这个explain_instance_with_data函数

feature_selection函数就是之前说过的会对特征进行选择,比如说从1000个特征中选出6个,那怎么选呢?代码中提供了5种方法 第一种:forward_selection方法

维护一个已经选出的特征列表,遍历所有特征,将未加入特征列表的特征加入,用岭回归进行训练,在所有未加入特征列表的特征中,选择一个加入了以后进行训练会使得模型正确值达到最大的特征。如此循环往复,直到收集到需要的特征数。 第二种方法:highest_weights 用岭回归训练模型,选择权重最大的K个特征

这里我将源码简化了一下,只保留简单的部分方便看到核心
第三种方法,不选择,拿全部特征训练 第四种方法,auto,指定的num_features<=6,用forward_selection,当num_features>6,用highest_weights 第五种方法:lasso_path法,没了解,直接略过 将特征选出来后,就是利用这些特征,使用岭回归,对数据进行训练,来近似原始模型,得到的系数权重就是最后的解释。 阅读源码是对读论文的补充,读论文读的云里雾里,不妨来看一下它的源码。 标签:函数,--,样本,解释性,特征,源码,文本,LIME From: https://www.cnblogs.com/lxah/p/16748811.html