文章核心思想速读:
提出了一个LIME解释技术能够对任何分类器做出的预测进行解释。
L指LOCAL,意思是模型是针对局部某个样本的解释,而不是所有样本
I指:INTERPRETABLE,可解释性,能够让人类看懂
M指:MODEL-AGNOSTIC ,与特定模型无关,也就是将要解释的模型都看作一个黑盒,无需了解原模型的运作原理
E指:EXPLANATIONS,解释
主要思想可以看下面这张图:
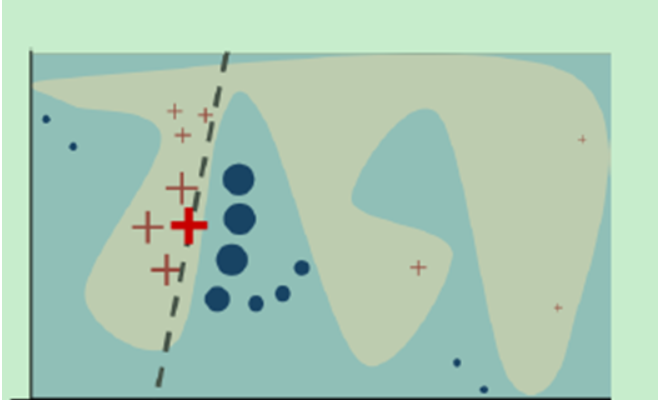
颜色最亮的那个红色十字是我们想要做出解释的样本,
其他颜色稍暗一些的红色十字和深蓝色圆点是我们根据这个最亮的红色十字,在它的周围生成的一些样本。比如说对于句子“我想有一个女朋友”,生成一些句子,
“我想女朋友”,“我有女朋友”,“我想有女朋友”,“我想有一个朋友”。
而背景中的浅蓝色和灰色是原始模型的分类边界,是 很难被我们人类所解读的,我们要做的就是用一个简单的模型,比如线性模型,决策树模型等等这些人类能够做出解读的模型去拟合原始的模型。当拟合完成后,新模型对于相同的输入应该产生和原始模型相同的输出。
然后我们只需要对新的简易模型做出解读就好了。
模型中对于句子的表示使用的是词袋模型,这个模型简单易懂,能够被人类所解读。
比如
颜色最亮的那个红色十字是我们想要做出解释的样本,
其他颜色稍暗一些的红色十字和深蓝色圆点是我们根据这个最亮的红色十字,在它的周围生成的一些样本。比如说对于句子“我想有一个女朋友”,生成一些句子,
“我想女朋友”,“我有女朋友”,“我想有女朋友”,“我想有一个朋友”。
而背景中的浅蓝色和灰色是原始模型的分类边界,是 很难被我们人类所解读的,我们要做的就是用一个简单的模型,比如线性模型,决策树模型等等这些人类能够做出解读的模型去拟合原始的模型。当拟合完成后,新模型对于相同的输入应该产生和原始模型相同的输出。
然后我们只需要对新的简易模型做出解读就好了。
模型中对于句子的表示使用的是词袋模型,这个模型简单易懂,能够被人类所解读。
比如
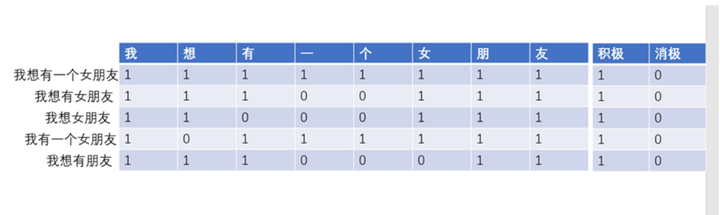 这样就构成了一个简单的训练样本,其中第一行是原始样本,其他是生成的样本。
如果样本的特征特别多,比如说训练数据的第二维有10000个,那么太多了对于我们人来来说也是不好去理解的,所以需要从中选出k个特征。选择的方法代码里提供了几种,最简单的就是不选,稍微复杂的就是用岭回归,选出对模型重要性影响最大的k个特征
选出来之后,再用岭回归去训练我们那个解释模型
这里用到了两次岭回归
涉及到模型的具体问题就需要去查看源码了。
源码中对模型的训练就是使用的
Sklearn中的岭回归
源码:https://github.com/marcotcr/lime
这个仓库中还有示例代码:可以看一遍了解lime
对源码的解读也可以看我的文章
九影:机器学习可解释性--LIME源码阅读
这样就构成了一个简单的训练样本,其中第一行是原始样本,其他是生成的样本。
如果样本的特征特别多,比如说训练数据的第二维有10000个,那么太多了对于我们人来来说也是不好去理解的,所以需要从中选出k个特征。选择的方法代码里提供了几种,最简单的就是不选,稍微复杂的就是用岭回归,选出对模型重要性影响最大的k个特征
选出来之后,再用岭回归去训练我们那个解释模型
这里用到了两次岭回归
涉及到模型的具体问题就需要去查看源码了。
源码中对模型的训练就是使用的
Sklearn中的岭回归
源码:https://github.com/marcotcr/lime
这个仓库中还有示例代码:可以看一遍了解lime
对源码的解读也可以看我的文章
九影:机器学习可解释性--LIME源码阅读