前缀树
前缀树是N叉树的一种特殊形式,也叫Trie、字典树、查找树。通常来说,一个前缀树是用来存储字符串的。前缀树的每一个节点代表一个 字符串 ( 前缀 )。每一个节点会有多个子节点,通往不同子节点的路径上有着不同的字符。子节点代表的字符串是由节点本身的原始字符串,以及 通往该子节点路径上所有的字符组成的。
前缀树常用于实现字符串检索、词频统计、字符串排序等操作,它的特点有:查找效率高,消耗内存大
前缀树的数据结构比较简单,关键字段为关键字结束标识和子节点,主要方法为关键字段的get和set方法。
//前缀树
private class TrieNode{
// 关键字结束标识
private boolean isKeywordEnd = false;
//子节点 key:下级字符 value: 下级节点
private Map<Character,TrieNode> subNodes =new HashMap<>();
//get关键字结束标识
public boolean isKeywordEnd() {
return isKeywordEnd;
}
//set关键字结束标识
public void setKeywordEnd(boolean keywordEnd) {
isKeywordEnd = keywordEnd;
}
//添加子节点
public void addSubNode(Character c, TrieNode node) {
subNodes.put(c, node);
}
//获取子节点
public TrieNode getSubNode(Character c) {
return subNodes.get(c);
}
}
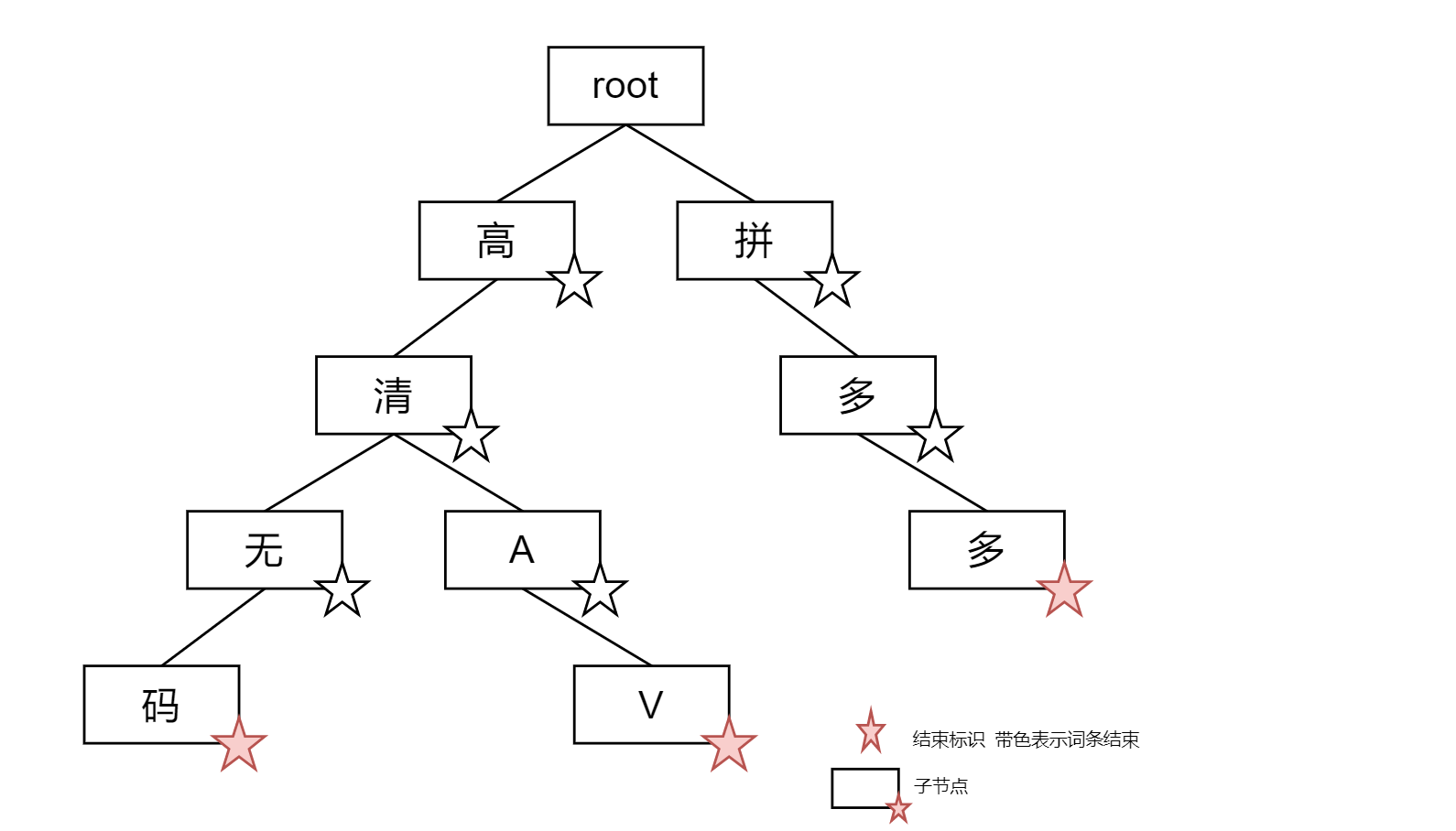
初始化前缀树
我们的敏感词是不断发生变化增长,所以我们把敏感词持久化到一份txt文件中,当然也可以保存到数据库,实现敏感词的动态更新。同时为了提高程序运行效率我们会在项目启动时初始化加载前缀树,这里用到了 @PostConstruct注解,代码如下:
@PostConstruct
public void init() {
try (
InputStream is = this.getClass().getClassLoader().getResourceAsStream("sensitive-words.txt");
BufferedReader reader = new BufferedReader(new InputStreamReader(is));
) {
String keyword;
//逐行读取敏感词
while ((keyword = reader.readLine()) != null) {
// 添加到前缀树
this.addKeyword(keyword);
}
} catch (IOException e) {
log.error("加载敏感词文件失败: " + e.getMessage());
}
}
添加敏感词
由于我们设置txt中每行一个敏感词,我们可以直接将读取到的keyword传入addKeyword方法。
// 将一个敏感词添加到前缀树中
private void addKeyword(String keyword) {
//初始节点、根节点
TrieNode tempNode = rootNode;
for (int i = 0; i < keyword.length(); i++) {
char c = keyword.charAt(i);
TrieNode subNode = tempNode.getSubNode(c);
if (subNode == null) {
// 初始化子节点
subNode = new TrieNode();
tempNode.addSubNode(c, subNode);
}
// 指向子节点,进入下一轮循环
tempNode = subNode;
// 设置结束标识
if (i == keyword.length() - 1) {
tempNode.setKeywordEnd(true);
}
}
}
public String sensitiveWordFilter(String text) {
//若是空字符串 返回空
if (StringUtils.isBlank(text)) {
return null;
}
// 根节点
// 每次在目标字符串中找到一个敏感词,完成替换之后,都要再次从根节点遍历树开始一次新的过滤
TrieNode tempNode = rootNode;
// begin指针作用是目标字符串每次过滤的开头
int begin = 0;
// position指针的作用是指向待过滤的字符
// 若position指向的字符是敏感词的结尾,那么text.subString(begin,position+1)就是一个敏感词
int position = 0;
//过滤后的结果
StringBuilder result = new StringBuilder();
//开始遍历 position移动到目标字符串尾部是 循环结束
while (position < text.length()) {
// 最开始时begin指向0 是第一次过滤的开始
// position也是0
char c = text.charAt(position);
//忽略用户故意输入的符号 例如嫖※娼 忽略※后 前后字符其实也是敏感词
if (isSymbol(c)) {
//判断当前节点是否为根节点
//若是根节点 则代表目标字符串第一次过滤或者目标字符串中已经被遍历了一部分
//因为每次过滤掉一个敏感词时,都要将tempNode重新置为根节点,以重新去前缀树中继续过滤目标字符串剩下的部分
//因此若是根节点,代表依次新的过滤刚开始,可以直接将该特殊符号字符放入到结果字符串中
if (tempNode == rootNode) {
//将用户输入的符号添加到result中
result.append(c);
//此时将单词begin指针向后移动一位,以开始新的一个单词过滤
begin++;
}
//若当前节点不是根节点,那说明符号字符后的字符还需要继续过滤
//所以单词开头位begin不变化,position向后移动一位继续过滤
position++;
continue;
}
//判断当前节点的子节点是否有目标字符c
tempNode = tempNode.getSubNode(c);
//如果没有 代表当前beigin-position之间的字符串不是敏感词
// 但begin+1-position却不一定不是敏感词
if (tempNode == null) {
//所以只将begin指向的字符放入过滤结果
result.append(text.charAt(begin));
//position和begin都指向begin+1
position = ++begin;
//再次过滤
tempNode = rootNode;
} else if (tempNode.isWordEnd()) {
//如果找到了子节点且子节点是敏感词的结尾
//则当前begin-position间的字符串是敏感词 将敏感词替换掉
result.append(REPLACE_WORD);
//begin移动到敏感词的下一位
begin = ++position;
//再次过滤
tempNode = rootNode;
//&& begin < position - 1
} else if (position + 1 == text.length()) {
//特殊情况
//虽然position指向的字符在树中存在,但不是敏感词结尾,并且position到了目标字符串末尾(这个重要)
//因此begin-position之间的字符串不是敏感词 但begin+1-position之间的不一定不是敏感词
//所以只将begin指向的字符放入过滤结果
result.append(text.charAt(begin));
//position和begin都指向begin+1
position = ++begin;
//再次过滤
tempNode = rootNode;
} else {
//position指向的字符在树中存在,但不是敏感词结尾,并且position没有到目标字符串末尾
position++;
}
}
return begin < text.length() ? result.append(text.substring(begin)).toString() : result.toString();
}