今日内容概要
-
字典相关操作
-
元祖相关操作
-
集合相关操作
-
字符编码(理论)
今日内容详细
字典相关操作
类型转换
# 格式
dict(其他数据类型)
字典的转换一般不使用关键字 而是自己动手转
# 使用关键字转非常的麻烦 不推荐使用
d1 = dict((['name', 'jack'], ['age', 18]))
print(d1) # {'name': 'jack', 'age': 18}
字典的取值
user_dict = {
'username': 'jason',
'password': 123,
'hobby': ['read', 'music', 'run']
}
# 第一种方法 直接按k取值
print(user_dict['username']) # jason
print(user_dict['age']) # k不存在会直接报错,所以不推荐使用
# 第二种方法 用内置方法get取值
print(user_dict.get('username')) # jason
print(user_dict.get('age')) # 当k不存在时 会返回一个None
print(user_dict.get('age', '嘿嘿嘿'))
# 可以自定义返回值 如果键存在获取对应的值 不存在返回自定义的内容
修改值数据以及新增键值对
print(id(user_dict))
user_dict['username'] = 'tony' # 键存在则修改对应的值
user_dict['age'] = 18 # 键如果不存在则新增键值对
删除数据
方法一
del user_dict['username']
print user_dict # {'password': 123, 'hobby': ['read', 'music', 'run']}
方法二
user_dict.pop('password') # {'hobby': ['read', 'music', 'run']}
res = user_dict.pop('password') # 用pop方法删除会返回删除的值 123
统计字典中键值对的个数
print(len(user_dict)) # 3
字典三剑客
print(user_dict.keys()) # 一次性获取字典所有的键 dict_keys(['username', 'password', 'hobby'])
print(user_dict.values()) # 一次性获取字典所有的值 dict_values(['jason', 123, ['read', 'music', 'run']])
print(user_dict.items()) # 一次性获取字典的键值对数据 dict_items([('username', 'jason'), ('password', 123), ('hobby', ['read', 'music', 'run'])])
快速生成值相同的字典
print(dict.fromkeys(['name', 'pwd', 'hobby'], 123))
# {'name': 123, 'pwd': 123, 'hobby': 123}
'''注意!!! 当生成的值是可变类型的时候,一定要注意通过任何一个键修改都会影响所有'''
res = dict.fromkeys(['name', 'pwd', 'hobby'], [])
print(res) # {'name': [], 'pwd': [], 'hobby': []}
res['name'].append('jason')
res['pwd'].append(123)
res['hobby'].append('study')
print(res)
# {'name': ['jason', 123, 'study'], 'pwd': ['jason', 123, 'study'], 'hobby': ['jason', 123, 'study']}
setdefault方法
setdefault()和get()方法类似, 如果键不存在于字典中,将会添加键并将值设为默认值。
res = user_dict.setdefault('username','tony')
print(user_dict, res) # 键存在则返回 结果是键对应的值
res = user_dict.setdefault('age',123) # 可以自定义
print(user_dict, res) # 不存在则新增键值对 结果是新增的值
popitem()方法
print(user_dict) # {'username': 'jason', 'password': 123, 'hobby': ['read', 'music', 'run']}
user_dict.popitem() # 弹出键值对 后进先出 可以理解为从右往左删
print(user_dict) # {'username': 'jason', 'password': 123}
元祖相关操作
类型转换
tuple()
支持for循环的数据类型都可以转成元祖
索引取值
t1 = (11, 22, 33, 44, 55, 66)
print(t1[0]) # 11
切片
# 和其他类型数据切片的使用方法一样 也可以设置间隔以及取值方向
print(t1[1:3]) # (22, 33)
print(t1[::-1]) # 也可以倒着取值(66, 55, 44, 33, 22, 11)
统计元祖内数据值的个数
print(len(t1)) # 6
统计元祖内某个数据值出现的次数
t2 = (11, 11, 33, 11, 44, 33)
print(t2.count(11)) # 3
print(t2.count(33)) # 2
获取元祖内指定数据值的索引值
print(t2.index(33)) # 2 当有多个一样的值是只会返回第一次出现的索引值
元祖的一些注意事项
- 元祖内如果只有一个数据值那么逗号不能少
- 元祖内索引绑定的内存地址不能被修改
- 元祖不能新增或删除数据
集合相关操作
类型转换
set()
集合内数据必须是不可变类型(整型 浮点型 字符串 元祖),并且是无序的,没有索引的概念
集合需要掌握的方法
'''集合最常用于去重以及运算,只有遇到上述两种需求的时候才应该考虑使用集合'''
去重
s1 = {11, 22, 11, 22, 22, 11, 222, 11, 22, 33, 22}
l1 = [11, 22, 33, 22, 11, 22, 33, 22, 11, 22, 33, 22]
s1 = set(l1)
l1 = list(s1)
print(l1) # [33, 11, 22]
'''集合去重后无法保留原先数据的排列顺序'''
关系运算
用于做群体之间做差异化校验
f1 = {'jason', 'tony', 'jerry', 'oscar'} # 用户1的好友列表
f2 = {'jack', 'jason', 'tom', 'tony'} # 用户2的好友列表
# 两人的共同好友
print(f1 & f2) # {'jason', 'tony'}
# 用户1独有的好友
print(f1 - f2) # {'jerry', 'oscar'}
# 两人所有的好友
print(f1 | f2) # {'jason', 'jack', 'tom', 'tony', 'oscar', 'jerry'}
# 两个人各组独有的好友
print(f1 ^ f2) # {'oscar', 'tom', 'jack', 'jerry'}
# 父集 子集
print(f1 > f2) # 判断f1是不是f2的父集 False
print(f1 < f2) # 判断f2是不是f1的父集 False
字符编码理论
字符是计算机与人交互的媒介,人虽然可以看懂二进制串,但文字是更加直观的。所以需要用数字来表示字符,字符与数字的对应关系就叫编码。
由于计算机发源于美国,一开始不需要显示其他语言的文字,所以就挑选了常用的128个字符,形成了ASCII码表。其中有一些特殊的字符是不能显示的,例如换行、空、水平制表符等。如下图所示:
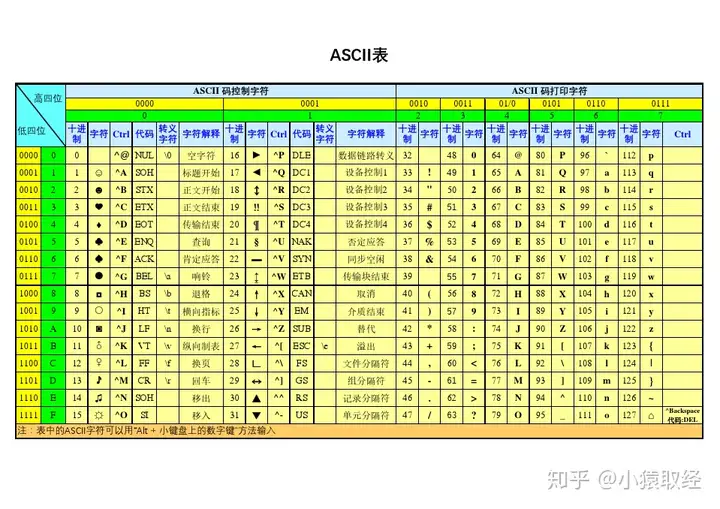
字符编码发展史
-
一家独大
计算机是由美国人发明的 为了能够让计算机识别英文需要发明一个数字跟英文字母的对应关系
ASCII码:记录了英文字母跟数字的对应关系
用8bit(1字节)来表示一个英文字符 -
群雄割据
中国人
GBK码:记录了英文、中文与数字的对应关系
用至少16bit(2字节)来表示一个中文字符
很多生僻字还需要使用更多的字节
英文还是用8bit(1字节)来表示
日本人
shift_JIS码:记录了英文、日文与数字的对应关系
韩国人
Euc_kr码:记录了英文、韩文与数字的对应关系每个国家的计算机使用的都是自己定制的编码本不同国家的文本数据无法直接交互 会出现"乱码"
-
天下一统
unicode万国码
兼容所有国家语言字符
起步就是两个字节来表示字符
utf系列:utf8 utf16 ...
专门用于优化unocide存储问题
英文还是采用一个字节 中文三个字节
字符编码实操
-
针对乱码不要慌 切换编码慢慢试即可
-
编码与解码
-
编码: 将人类的字符按照指定的编码编码成计算机能够读懂的数据
字符串.encode() -
解码: 将计算机能够读懂的数据按照指定的编码解码成人能够读懂
bytes类型数据.decode()
-
-
Python2与Python3中的差异
Python2默认的编码是ASCII 需要文件头 # encoding:utf8 字符串前面得加u u'你好啊' Python3默认的编码是utf系列(unicode)
'''去重下列列表并保留数据值原来的顺序
eg: [1,2,3,2,1] 去重之后 [1,2,3]
l1 = [2,3,2,1,2,3,2,3,4,3,4,3,2,3,5,6,5]'''
l1 = [2, 3, 2, 1, 2, 3, 2, 3, 4, 3, 4, 3, 2, 3, 5, 6, 5]
l2 = []
for i in l1:
if i not in l2:
l2.append(i)
print(l2)
'''有如下两个集合,pythons是报名python课程的学员名字集合,linuxs是报名linux课程的学员名字集合
pythons={'jason','oscar','kevin','ricky','gangdan','biubiu'}
linuxs={'kermit','tony','gangdan'}
1. 求出即报名python又报名linux课程的学员名字集合
2. 求出所有报名的学生名字集合
3. 求出只报名python课程的学员名字
4. 求出没有同时这两门课程的学员名字集合'''
pythons = {'jason', 'oscar', 'kevin', 'ricky', 'gangdan', 'biubiu'}
linuxs = {'kermit', 'tony', 'gangdan'}
s1 = pythons & linuxs
print(s1)
s2 = pythons | linuxs
print(s2)
s3 = pythons - linuxs
print(s3)
s4 = pythons ^ linuxs
print(s4)
'''统计列表中每个数据值出现的次数并组织成字典战士
eg: l1 = ['jason','jason','kevin','oscar']
结果:{'jason':2,'kevin':1,'oscar':1}
真实数据
l1 = ['jason','jason','kevin','oscar','kevin','tony','kevin']
'''
l1 = ['jason', 'jason', 'kevin', 'oscar', 'kevin', 'tony', 'kevin']
t1 = tuple(l1)
dic = {}
for i in t1:
dic[f'{i}'] = t1.count(f'{i}')
print(dic)