文心一言 VS 讯飞星火 VS chatgpt (68)-- 算法导论6.5 7题
七、试说明如何使用优先队列来实现一个先进先出队列,以及如何使用优先队列来实现栈(队列和栈的定义见 10.1 节。)
文心一言:
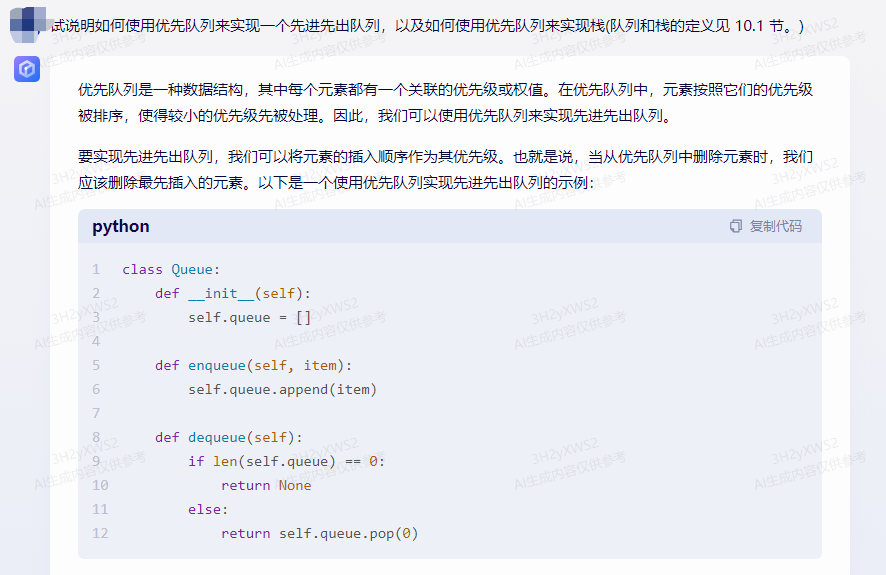
优先队列是一种数据结构,其中每个元素都有一个关联的优先级或权值。在优先队列中,元素按照它们的优先级被排序,使得较小的优先级先被处理。因此,我们可以使用优先队列来实现先进先出队列。
要实现先进先出队列,我们可以将元素的插入顺序作为其优先级。也就是说,当从优先队列中删除元素时,我们应该删除最先插入的元素。以下是一个使用优先队列实现先进先出队列的示例:
class Queue:
def __init__(self):
self.queue = []
def enqueue(self, item):
self.queue.append(item)
def dequeue(self):
if len(self.queue) == 0:
return None
else:
return self.queue.pop(0)
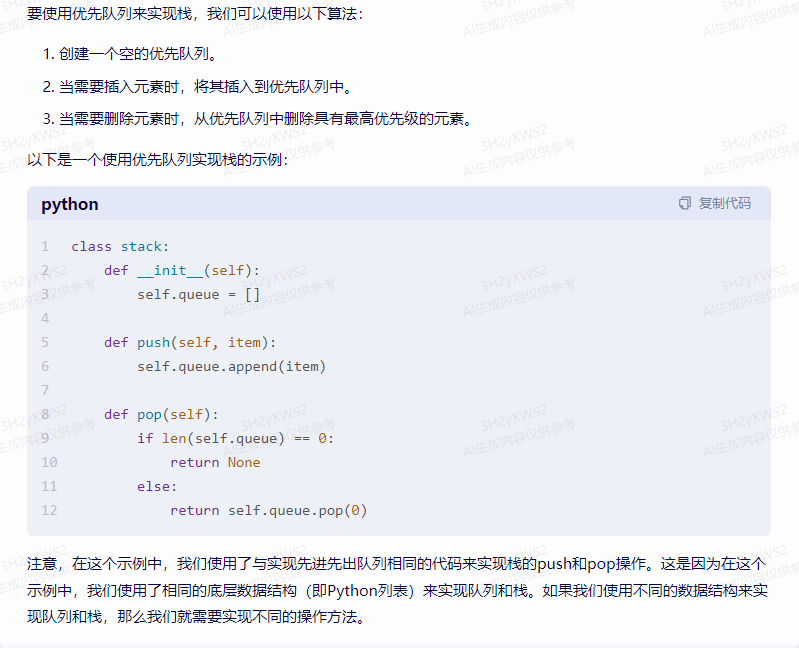
要使用优先队列来实现栈,我们可以使用以下算法:
1.创建一个空的优先队列。
2.当需要插入元素时,将其插入到优先队列中。
3.当需要删除元素时,从优先队列中删除具有最高优先级的元素。
以下是一个使用优先队列实现栈的示例:
class stack:
def __init__(self):
self.queue = []
def push(self, item):
self.queue.append(item)
def pop(self):
if len(self.queue) == 0:
return None
else:
return self.queue.pop(0)
注意,在这个示例中,我们使用了与实现先进先出队列相同的代码来实现栈的push和pop操作。这是因为在这个示例中,我们使用了相同的底层数据结构(即Python列表)来实现队列和栈。如果我们使用不同的数据结构来实现队列和栈,那么我们就需要实现不同的操作方法。
讯飞星火:
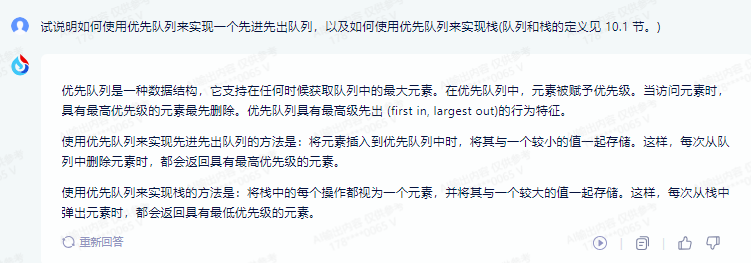
优先队列是一种数据结构,它支持在任何时候获取队列中的最大元素。在优先队列中,元素被赋予优先级。当访问元素时,具有最高优先级的元素最先删除。优先队列具有最高级先出 (first in, largest out)的行为特征。
使用优先队列来实现先进先出队列的方法是:将元素插入到优先队列中时,将其与一个较小的值一起存储。这样,每次从队列中删除元素时,都会返回具有最高优先级的元素。
使用优先队列来实现栈的方法是:将栈中的每个操作都视为一个元素,并将其与一个较大的值一起存储。这样,每次从栈中弹出元素时,都会返回具有最低优先级的元素。
360智脑:
使用优先队列实现先进先出队列的示例代码如下所示:
# 定义优先队列类
class PriorityQueue:
def __init__(self):
self.items = []
self.max_size = 0
self.current_index = 0
def insert(self, item):
if self.max_size == len(self.items): # 如果队列已满,则创建新的列表
new_list = []
else:
new_list = self.items[:self.max_size] + [item] * (self.max_size - len(self.items))
self.items.append(new_list)
self.current_index += 1
def pop(self):
return self.items[-1] if self.current_index >= len(self.items) else self.items[-2]
def peek(self):
return self.items[-1] if self.current_index >= len(self.items) else None
def size(self):
return len(self.items)
使用优先队列实现栈的示例代码如下所示:
# 定义优先队列类
class Stack:
def __init__(self):
self.items = []
self.max_size = 0
self.current_size = 0
def push(self, item):
if self.max_size == len(self.items): # 如果栈顶为空,则创建一个新的列表
new_list = []
else:
new_list = self.items[:self.max_size] + [item] * (self.max_size - len(self.items))
self.items.append(new_list)
self.current_size += 1
def pop(self):
if not self.is_empty():
return self.items.pop()
else:
return None
def is_empty(self):
return self.current_size == 0
def size(self):
return self.current_size
chatglm:
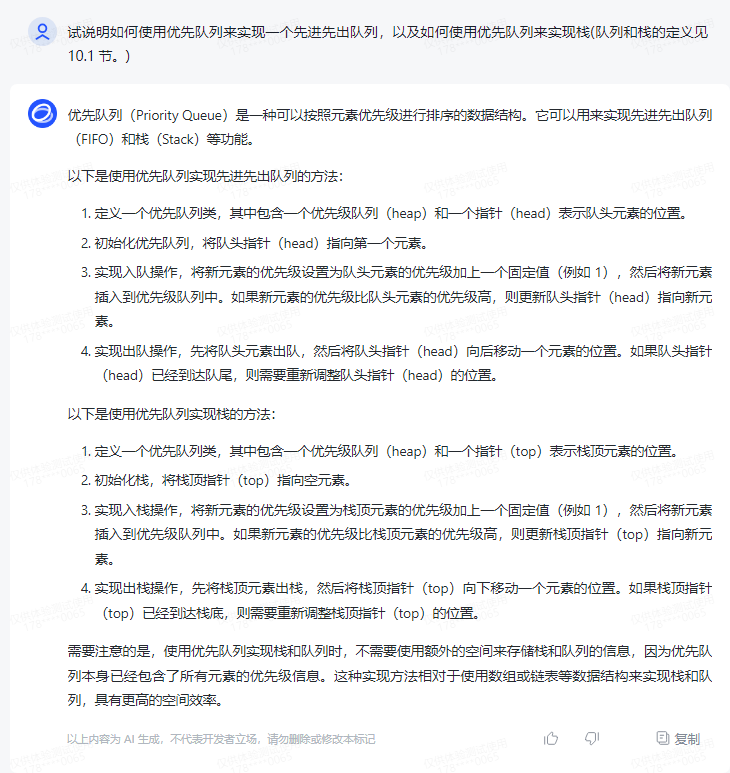
优先队列(Priority Queue)是一种可以按照元素优先级进行排序的数据结构。它可以用来实现先进先出队列(FIFO)和栈(Stack)等功能。
以下是使用优先队列实现先进先出队列的方法:
1.定义一个优先队列类,其中包含一个优先级队列(heap)和一个指针(head)表示队头元素的位置。
2.初始化优先队列,将队头指针(head)指向第一个元素。
3.实现入队操作,将新元素的优先级设置为队头元素的优先级加上一个固定值(例如 1),然后将新元素插入到优先级队列中。如果新元素的优先级比队头元素的优先级高,则更新队头指针(head)指向新元素。
4.实现出队操作,先将队头元素出队,然后将队头指针(head)向后移动一个元素的位置。如果队头指针(head)已经到达队尾,则需要重新调整队头指针(head)的位置。
以下是使用优先队列实现栈的方法:
1.定义一个优先队列类,其中包含一个优先级队列(heap)和一个指针(top)表示栈顶元素的位置。
2.初始化栈,将栈顶指针(top)指向空元素。
3.实现入栈操作,将新元素的优先级设置为栈顶元素的优先级加上一个固定值(例如 1),然后将新元素插入到优先级队列中。如果新元素的优先级比栈顶元素的优先级高,则更新栈顶指针(top)指向新元素。
4.实现出栈操作,先将栈顶元素出栈,然后将栈顶指针(top)向下移动一个元素的位置。如果栈顶指针(top)已经到达栈底,则需要重新调整栈顶指针(top)的位置。
需要注意的是,使用优先队列实现栈和队列时,不需要使用额外的空间来存储栈和队列的信息,因为优先队列本身已经包含了所有元素的优先级信息。这种实现方法相对于使用数组或链表等数据结构来实现栈和队列,具有更高的空间效率。
通义千问:
使用优先队列实现先进先出队列可以使用以下方法:
1.定义一个优先队列,其中元素是 Node 结构体,包括一个 key 值和一个值。
2.定义一个队列,其中元素是 Node 结构体。
3.当一个元素要加入队列时,先将其 key 值与队列中已有元素的 key 值进行比较,如果 key 值小于队列中已有元素的 key 值,则将新元素放入队列尾部;否则将队列中已有元素放入优先队列尾部,再将新元素放入队列尾部。
4.当需要获取队列头部元素时,先从优先队列中获取队列头部元素,再从队列中获取队列头部元素。
使用优先队列实现栈可以使用以下方法:
1.定义一个优先队列,其中元素是 Node 结构体,包括一个 key 值和一个值。
2.定义一个指针,指向队列头部。
3.当一个元素要加入栈时,将其 key 值与队列中已有元素的 key 值进行比较,如果 key 值小于队列中已有元素的 key 值,则将新元素放入队列尾部;否则将队列中已有元素放入优先队列尾部,再将新元素放入队列尾部。
4.当需要弹出栈头部元素时,从优先队列中获取队列头部元素,再从队列中弹出队列头部元素。

天工:
1.先进先出队列的实现
优先队列是一种特殊的队列,它可以根据元素的优先级来进行排序,从而实现先进先出的特性。在优先队列中,每个元素都有一个优先级,优先级高的元素先被取出。
以下是一个基于优先队列实现的先进先出队列的示例代码:
import heapq
class FIFOQueue:
def __init__(self):
self.queue = []
def enqueue(self, item, priority):
heapq.heappush(self.queue, (priority, item))
def dequeue(self):
return heapq.heappop(self.queue)[1]
在这个示例代码中,我们使用了 Python 的内置模块 heapq,其中 heappush 函数用于将元素插入到队列的末尾,并根据元素的优先级进行排序;heappop 函数用于弹出队列中的最小优先级元素,并返回该元素的值。
2.栈的实现
栈是一种特殊的数据结构,它具有后进先出(LIFO)的特性。在栈中,最后进入的元素最先被访问。
以下是一个基于优先队列实现的栈的示例代码:
import heapq
class Stack:
def __init__(self):
self.queue = []
def push(self, item):
heapq.heappush(self.queue, item)
def pop(self):
return heapq.heappop(self.queue)[1]
在这个示例代码中,我们使用了 Python 的内置模块 heapq,其中 heappraise 函数用于将元素插入到栈的末尾,并根据元素的优先级进行排序。由于栈是一种后进先出的数据结构,因此我们可以使用 heappop 函数来弹出栈顶元素。

chatgpt:
使用优先队列实现先进先出队列:
在优先队列的实现中,每个元素都有一个优先级与之相关联。为了实现先进先出队列,可以将元素的入队顺序作为其优先级,即越早入队的元素优先级越高。
1.创建一个优先队列并实现入队操作:
- 每当有元素需要入队时,将其插入到队列中,并将其入队顺序作为其优先级。
2.实现出队操作:
-
对于先进先出队列,每次出队操作应该返回队列中的最早入队的元素。
-
可以通过从优先队列中取出优先级最高的元素来实现此操作。
-
若要实现先进先出的特性,可以将元素的入队顺序作为其优先级,并且将其作为额外数据存储在元素中。
-
当需要出队时,只需从优先队列中取出优先级最高且入队顺序最早的元素即可。
使用优先队列实现栈:
虽然优先队列通常是基于元素的优先级进行排序的,但可以通过修改入队的规则来使用优先队列实现栈。
1.创建一个优先队列并实现入栈操作:
-
每当有元素需要入栈时,将其插入到队列中,并为其设置一个优先级。
-
在这种情况下,优先级可以简单地是一个递增的整数,表示元素进入栈的顺序。
2.实现出栈操作:
-
对于栈数据结构,我们希望每次出栈操作返回最后一个入栈的元素。
-
可以通过向优先队列中添加元素时动态设置优先级来实现此操作。
-
当有元素需要出栈时,将其设置为具有最高优先级的元素,使其成为下一个出队的元素。
-
出栈操作时,从优先队列中取出优先级最高的元素即可。
综上所述,通过调整入队规则可以使用优先队列实现先进先出队列和栈。
总结
