我们应该都遇见过敏感词过滤,比如当我们输入一些包含暴力或者色情的文本,系统会阻止信息提交。敏感词过滤就是检查用户输入的内容有没有敏感词,检查之后有两个策略。
- 直接阻止信息保存,接口返回错误信息
- 允许信息保存,但是会把敏感词替换为***
不管是哪种策略,首先都得找到是否包含敏感词,这个判断一般是在服务端完成的。
要判断用户输入有无敏感词,首先要知道哪些词语是敏感词,也就是得有个敏感词库。比如现在敏感词库里记录了两个敏感词:“abc”和“cde”,如何判断用户输入的内容里是否包含这两个敏感词呢?最容易想到的方法是遍历敏感词库,依次判断输入内容是否有“abc”和“cde”。这种方法是可靠的,但是真实的敏感词库里存放的敏感词是非常多的,这时候遍历敏感词库的性能比较低,而且大部分情况下用户输入的内容都是不包含敏感词的,这时需要完全遍历敏感词库,也就是说大部分情况下遇到的都是这个算法复杂度最高的情形。
有没有一种比较高效的方法来查找敏感词呢?DFA算法可以做到。
DFA全称为:Deterministic Finite Automaton,即确定有穷自动机。其特征为:有一个有限状态集合和一些从一个状态通向另一个状态的边,每条边上标记有一个符号,其中一个状态是初态,某些状态是终态。但不同于不确定的有限自动机,DFA中不会有从同一状态出发的两条边标志有相同的符号。
敏感词过滤很适合用DFA算法,用户每次输入都是状态的切换,如果出现敏感词,既是终态,就可以结束判断。
我们把数组形式的敏感词整理为一个树状结构,准确的说是一个森林。
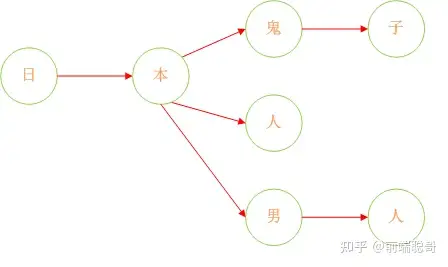
这样查找敏感词就变成了一个查找路径的问题,如果用户输入的内容中包含一个从根节点到叶子节点的完整路径,就说明包含敏感词。
算法实现逻辑是循环用户输入的字符串,依次查找每个字符是否出现在树的节点上,比如用户输入“打倒日本人”,从第一个字开始判断,“打”不在树的根节点上,进入下一步,“倒”也不在根节点上,进入下一步,“日”出现在了根节点上,这时状态切换,下一步的查找范围变为“日”的子节点;“本”出现在子节点中,状态再次切换为“本”的子节点;“人”出现在子节点中,并且为叶子节点,所以包含敏感词。
上述过程只是基本的思路,具体实现还要考虑中途退出时的状态重置,完整代码放在下面。(html代码)
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<style>
#text{
width: 100%;
}
.output{
margin: 30px 0;
font-size: 16px;
line-height: 28px;
}
</style>
</head>
<body>
<textarea id="text"></textarea>
<div>
<button id="button">提交</button>
</div>
<div class="output"></div>
</body>
</html>
<script>
const dirtyTextArr = ['日本人', '日本鬼子', '日本男人']
console.log('敏感词个数 -> ', dirtyTextArr.length)
const dirtyRoot = new Map()
const buildMap = function (text) {
let dirtyMap = dirtyRoot
let origin = true
if (!text) { // 敏感词不能为空
return
}
for (let a = 0; a < text.length; a++) {
if (origin && dirtyMap.get(text[a])) {
// 当前字符已存在
if (dirtyMap.get(text[a]) === true) {
// 已经存在更短的敏感词
return;
}
let oldDirtyMap = dirtyMap
dirtyMap = dirtyMap.get(text[a])
// 当前字符是最后一个字, 将dirtyMap置为true
if (a === text.length - 1) {
oldDirtyMap.set(text[a], true)
// oldDirtyMap.
}
} else {
origin = false
if (a === text.length - 1) {
// 最后一个字
dirtyMap.set(text[a], true)
} else {
// console.log(text[a])
dirtyMap.set(text[a], new Map())
dirtyMap = dirtyMap.get(text[a])
}
}
}
}
for (let b = 0; b < dirtyTextArr.length; b++) {
buildMap(dirtyTextArr[b])
}
console.log('整理为map结构 -> ', dirtyRoot)
const dirtyCheckDFA = function (word){
if (!word || !dirtyRoot) {
return {dirty: false}
}
let dirty = false
let dirtyMap = dirtyRoot
let start = null
let end = 0
let origin = true
for (let i = 0; i < word.length; i++) {
// console.log(word[i])
const aMap = dirtyMap.get(word[i])
if (aMap) {
// 在敏感词中匹配到该字符,且该字符为最后一个字
if (aMap === true) {
// 敏感词长度为1
if (start === null) {
start = i
}
end = i
dirty = true
break
} else {
// 在敏感词中匹配到该字符,但不是结尾
if (origin) {
start = i
}
// console.log(aMap)
dirtyMap = aMap
origin = false
if (i === word.length - 1) {
i = start
origin = true
dirtyMap = dirtyRoot
}
}
} else {
if (!origin) {
// 在树结构中途退出,重新从进入字符的下一个字符检查
i = start
}
origin = true
start = null
dirtyMap = dirtyRoot
}
}
if (dirty) {
return { dirty: true, start, end}
}
return {dirty: false}
}
const dirtyCheckLoop = function (word) {
if (!word) {
return {dirty: false}
}
for (let a = 0; a < dirtyTextArr.length; a++) {
const startIndex = word.indexOf(dirtyTextArr[a])
if (startIndex !== -1) {
return {dirty: true, start: startIndex, end: startIndex + dirtyTextArr[a].length - 1}
}
}
return {dirty: false}
}
function submit() {
console.log('**********************')
const text = document.querySelector('#text').value
const textLength = text.length
// console.log('待检测字符串长度',)
console.time('dirtyCheckDFA')
const checkResult = JSON.stringify(dirtyCheckDFA(text))
console.timeEnd('dirtyCheckDFA')
console.time('dirtyCheckLoop')
const checkResult2 = JSON.stringify(dirtyCheckLoop(text))
console.timeEnd('dirtyCheckLoop')
const str = `输入字符串长度:${textLength}<br>dirtyCheckDFA运行结果:${checkResult}<br>dirtyCheckLoop运行结果:${checkResult2}`
document.querySelector('.output').innerHTML = str
}
document.querySelector('#button').addEventListener('click', submit)
</script>
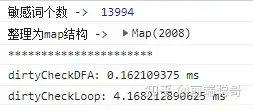
上述例子中还比较了DFA算法和遍历词库算法的运行速度,由于敏感词库只有三个敏感词,所以DFA性能并不占优势,但是当敏感词库很大时,DFA优势会很明显,截图如下。
从catchadmin框架下找到以下代码:
<?php
declare(strict_types=1);
use think\facade\Cache;
class Trie
{
protected $tree = [];
protected $end = 'end';
protected $sensitiveWord = '';
protected $sensitiveWords = [];
/**
* add
*
* @time 2020年06月17日
* @param string $word
* @return $this
*/
public function add(string $word)
{
$words = mb_str_split($word);
$array = [];
$len = count($words);
$end = true;
while ($len > 0) {
if ($end) {
$array[] = [
$words[$len - 1] => ['end' => true],
];
} else {
$latest = array_pop($array);
$array[] = [
$words[$len-1] => $latest,
];
}
$end = false;
$len--;
}
$this->tree = array_merge_recursive($this->tree, array_pop($array));
return $this;
}
/**
* 获取
*
* @time 2020年06月17日
* @throws \Psr\SimpleCache\InvalidArgumentException
* @return array|bool
*/
public function getTries()
{
if (!empty($this->tree)) {
return $this->tree;
}
return Cache::store('redis')->get("trie_tree");
}
/**
* 获取敏感词
*
* @time 2020年06月17日
* @param array $trieTree
* @param string $content
* @param bool $all
* @return array|string
*/
public function getSensitiveWords(array $trieTree, string $content, $all = true)
{
$words = mb_str_split($content);
$len = count($words);
for ($start = 0; $start < $len; $start++) {
// 未搜索到
if (!isset($trieTree[$words[$start]])) {
continue;
}
$node = $trieTree[$words[$start]];
$this->sensitiveWord = $words[$start];
// 从敏感词开始查找内容中是否又符合的
for ($i = $start+1; $i< $len; $i++) {
$node = $node[$words[$i]] ?? null;
$this->sensitiveWord .= $words[$i];
if (isset($node['end'])) {
if ($all) {
$this->sensitiveWords[] = $this->sensitiveWord;
$this->sensitiveWord = '';
} else {
break 2;
}
}
if (!$node) {
$this->sensitiveWord = '';
$start = $i-1;
break;
}
}
// 防止内容比敏感词短 导致验证过去
// 使用敏感词【傻子】校验【傻】这个词
// 会提取【傻】
// 再次判断是否是尾部
if (!isset($node['end'])) {
$this->sensitiveWord = '';
}
}
return $all ? $this->sensitiveWords : $this->sensitiveWord;
}
/**
* replace
*
* @time 2020年06月17日
* @param $tree
* @param string $content
* @return string|string[]
*/
public function replace($tree, string $content)
{
$sensitiveWords = $this->getSensitiveWords($tree, $content);
$replace = [];
foreach ($sensitiveWords as $word) {
$replace[] = str_repeat('*', mb_strlen($word));
}
return str_replace($sensitiveWords, $replace, $content);
}
/**
* cache
*
* @time 2020年06月17日
*/
public function cached()
{
return Cache::store('redis')->set("trie_tree", $this->tree);
}
}
用法:
$trie = new Trie();
$trie->add("敏感词");
// 获取 trie tree
$trieTree = $trie->getTries();
//getSensitiveWords 方法可以获取到内容里面存在的敏感词汇
//$content为用户提交的内容
$trie->getSensitiveWords($trieTree, $content);
//replace 方法可以替换到内容里面存在的敏感词。
$trie->replace(['敏感词111','敏感词2222'], $content);
标签:return,--,text,敏感,start,算法,dirtyMap,DFA,true From: https://www.cnblogs.com/dreamboycx/p/17516268.html