排序算法
1、选择排序
2、冒泡排序
3、插入排序
4、异或运算
5、归并排序
5.1、小和问题
5.2、逆序对问题
6、快速排序
6.1、荷兰国旗问题
问题1、
给定一个数组arr,和一个数num,请把小于等于num的数放在数 组的左边,大于num的
数放在数组的右边。要求额外空间复杂度O(1),时间复杂度O(N) 无序
解决方法
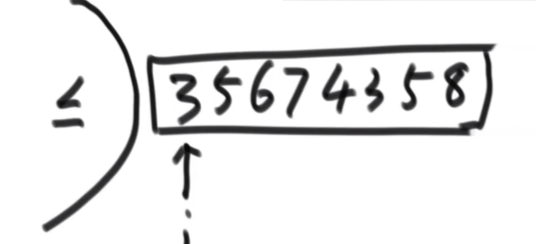
用一个标记记录小于等于区,开始时小于等于区的位置为-1,i从左到右走,根据以下两个步骤操作:
1)如果[i] <= num ,则[i]和小于等于区的下一个数交换,小于等于区往右扩,i++;
2)如果[i] > num , i++;
直到 i 越界停止。
问题2、(荷兰国旗问题)
给定一个数组arr,和一个数num,请把小于num的数放在数组的 左边,等于num的数放
在数组的中间,大于num的数放在数组的 右边。要求额外空间复杂度O(1),时间复杂度
O(N)
解决方法
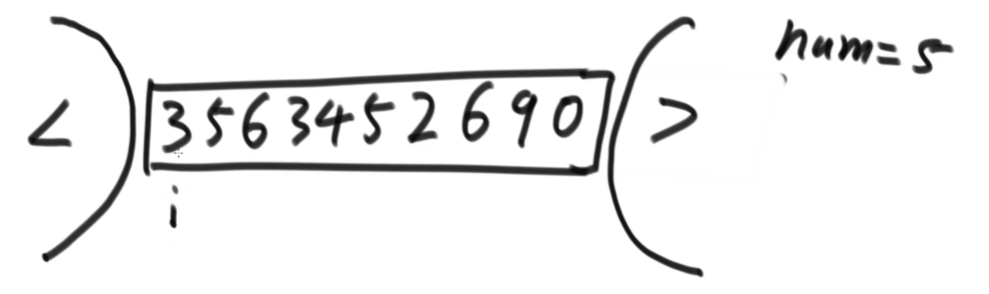
用一个变量代表左边区域(小于区,起始为-1)的右边界,另一个变量代表右边区域(大于区,起始位数组长度)的左边界,i从左向右开始走
,根据以下三个步骤操作:
1)如果当前数 [i] < num ,当前数[i] 和小于区的下一个数做交换,小于区右扩,i++;
2)如果当前数 [i] = num ,i++;
3)如果当前数 [i] > num,[i] 和大于区前一个数交换,大于区左扩,i原地不动。
直到 i 和 大于区左边界重合停止。
6.2快速排序
1、最初的快速排序(1,0版本)
1)把数组范围中的最后一个数作为划分值,然后把数组分成两个部分:
左侧:小于等于区域(保证最后一个值为等于划分值,通过交换)、右侧:大于区域
2)对左侧范围和右侧范围,递归执行。
2、不改进的快速排序(2.0版本):
1)把数组范围中的最后一个数作为划分值,然后把数组通过荷兰国旗问题分成三个部分:
左侧<划分值、中间==划分值、右侧>划分值
2)对左侧范围和右侧范围,递归执行。
最后将最后一个索引的划分值与右侧范围最左端的值交换
分析:
1)划分值越靠近两侧,复杂度越高;划分值越靠近中间,复杂度越低
2)可以轻而易举的举出最差的例子,所以不改进的快速排序时间复杂度为O(N^2)
3、随机快速排序(改进的快速排序 , 3.0版本)
1)在数组范围中,等概率随机选一个数作为划分值,然后把数组通过荷兰国旗问题分成三个部分:
左侧<划分值、中间==划分值、右侧>划分值
2)对左侧范围和右侧范围,递归执行
最后将最后一个索引的划分值与右侧范围最左端的值交换
时间复杂度为O(N*logN)
7、堆排序
7.1、堆结构
满二叉树:树中每个分支结点(非叶结点)都有两棵非空子树
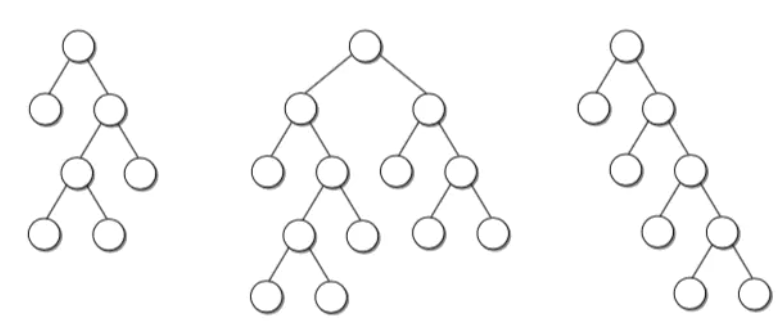
完全二叉树:对于一个树高为h的二叉树,如果其第0层至第h-1层的节点都满。如果最下面一层节点不满,则所有的节点在左边的连续排列,空位都在右边。这样的二叉树就是一棵完全二叉树。
- i 位置的左孩子为:2 * i + 1;
- i 位置的有孩子为:2 * i + 2;
- i 位置的父孩子为:(i - 1) / 2;
堆在逻辑概念上是一个完全二叉树结构,又分为小根堆和大根堆:
- 完全二叉树中如果每棵子树的最大值都在顶部就是大根堆。
- 完全二叉树中如果每棵子树的最小值都在顶部就是小根堆
堆结构的heapInsert与heapify操作:
1、heapInsert操作:(O(logN) 级别)
用户依次给一些数字,然后把这些数字放在干净的数组上,让这些数组组成一个大根堆。
方法:
每一个进来的数字都与自己的父节点进行比较,如果比自己的父节点大,就与父节点交换,直到不再比父节点大(heapsize 标记堆的大小)(这个操作为heapinsert)。
public static void heapInsert(int[] arr,int index){
while (arr[index] > arr[(index - 1) / 2]){
swap(arr,index,(index - 1) / 2);
index = (index - 1) / 2;
}
}
2、heapify操作(O(logN) 级别):
如果在一个已经调整好顺序的大根堆上 执行如下的操作:
告诉这个大根堆最大值是多少,然后拿掉这个最大值数字,使其仍然保持为大根堆。
操作:
1、先把 0 位置上的最大值用一个临时变量保存起来,
2、 把最后一个数字放到 0 位置上 ,再把heapsize减小(代表最后一个数字从堆中移除掉了。)
3、此时这个完全二叉树不是大根堆,因此需要调整:从头节点开始,先在它的左孩子和右孩子中选一个最大值,然后孩子和头位置的数字pk,如果pk失败了(头位置比孩子中的最大值小),则头位置的数字与孩子节点位置的数字交换位置;然后再把该孩子节点作为头节点,重复操作,直到没有左孩子和右孩子或者左孩子和右孩子都比头节点小。(这个过程为heapify)。(也可以从任何一个位置向下左heapify)。
public static void heapify(int[] arr,int index,int heapSize){
int left = index * 2 + 1; //左孩子的下标
while (left < heapSize){ //下方还有孩子的时候
//两个孩子中,谁的值大,把下标给largers
int largest = left + 1 < heapSize && arr[left + 1] > arr[left]
? left + 1 : left;
//父和较大孩子之间,谁的值大,就把下标给largest
largest = arr[largest] > arr[index] ? largest : index;
if(largest == index){
break;
}
swap(arr,largest,index);
index = largest;
left = index * 2 + 1;
}
}
7.2、堆排序:
堆排序过程为:
1、将数组整体变成大根堆(heapinsert操作 ,没进入堆一个数字, heapsize 就自增1)
2、 把0位置上的数字和最后一个位置的数字做交换,heapsize -- (即把最大值和堆断开联系)
3、对剩下的数字,从0位置开始做heapify操作,使其变成一个大根堆,然后执行第2 步
4、直到堆的大小变成0(heapsize = 0),整个数字就拍好序了。
public static void heapSort(int[] arr){
if(arr == null || arr.length < 2){
return;
}
//调整为大根堆
for (int i = 0;i < arr.length;i++){
heapInsert(arr,i);
}
int heapSize = arr.length;
//0位置与最后一个位置交换
swap(arr,0,--heapSize);
while (heapSize > 0){
//调整为大根堆
heapify(arr,0,heapSize);
//0位置与最后一个位置交换
swap(arr,0,--heapSize);
}
}
时间复杂度O(N * logN) , 空间复杂度:O(1)。
一开始生成大根堆还可以使用另外一种方式:
将数组中的数字排成一个完全二叉树,然后从最下面的节点开始往下做heapify , 做完后上一层节点在做heapify,直到 0 节点做heapify结束。
//第二种调整为大根堆的方法 for(int i = arr.length - 1;i >= 0;i--){ heapify(arr,i,arr.length); }
7.3、堆排序扩展问题:
已知一个几乎有序的数组,几乎有序是指,如果把数组排好顺序的话,每个元素移动的距离可以不超过k,并且k相对于数组来说比较小。请选择一个合适的排序算法针对这个数据进行排序。
解决方案 O(N * logk):
1、准备一个小根堆,然后遍历数组, i = 1
2、将数组前k + 1个数放在小根堆中,
3、然后将小根堆0位置上的数弹出依次放进数组中((此时这个值与其后面所有数相比最小)),并将第k +1 + i个数放入小根堆,i++,
4、循环执行第三步,直到将数组中所有的数全都放到小根堆。最后将小根堆中的数依次弹出。
小根堆在java中为优先级队列,默认情况下不给它传递任何参数时为小根堆(使用比较器可以变为大根堆),通过PriorityQueue类创建对象。
add():往堆中放入一个数。
poll(): 弹出堆中0位置的数。
PriorityQueue<Integer> heap = new PriorityQueue<>();
一些简单的工作中可以使用,一些复杂的工作需要手写堆结构。
在本问题中使用java中的PriorityQueue创建就好了,上面问题的实现如下:
public void sortArrayDistanceLessK(int[] arr,int k){
//堆结构,默认小根堆
PriorityQueue<Integer> heap = new PriorityQueue<>();
int index = 0;
for(;index <= Math.min(arr.length,k);index++){
heap.add(arr[index]);
}
int i = 0;
for(;index < arr.length;i++,index++){
heap.add(arr[index]);
arr[i] = heap.poll();
}
while (!heap.isEmpty()){
arr[i++] = heap.poll();
}
}
7.4、比较器使用:
1)比较器的实质就是重载比较运算符。
2)比较器可以很好的应用在特殊标准的排序上。
3)比较器可以很好的应用在根据特殊标准排序的结构上。
比较器在C++中时重载比较运算符;在Java中,比较器就是告诉他们两个数怎么比较大小。
例如在给一个数组排序的时候,使用Arrays.sort()方法进行排序的时候,默认是从小到大进行排序,这时就可以使用比较器 进行从大到小的排序。
java中创建比较器的时候,需要实现Comparator接口,并且需要实现compare方法 ,根据方法的返回值:
- 返回负数的时候,第一个参数排在前面。
- 返回正数的时候,第二个参数排在前面。
- 返回0的时候,谁在前面都无所谓。
举例:当我们自定义一个类,然后创建对象,现在需要根据这个对象的指定属性进行排序时就需要使用比较器进行排序,例如创建一个学生类,按照学生的id进行排序:
public static class Student{
public String name;
public int id;
public int age;
public Student(String name,int id,int age){
this.name = name;
this.id = id;
this.age = age;
}
}
构建正序 和 逆序的比较器
//正序 Id由小到大排序
public static class IdAscendingComparator implements Comparator<Student>{
//返回负数的时候,第一个参数排在前面
//返回正数的时候,第二个参数排在前面
//返回0的时候,谁在前面都无所谓。
@Override
public int compare(Student o1, Student o2) {
return o1.id - o2.id;
}
}
//逆序 Id由大到小排序
public static class IdDescendingComparator implements Comparator<Student> {
@Override
public int compare(Student o1, Student o2) {
return o2.id - o1.id;
}
}
测试:
public static void printStudents(Student[] students) {
for (Student student : students) {
System.out.println("Name : " + student.name + ", Id : " + student.id + ", Age : " + student.age);
}
}
public static void main(String[] args) {
Integer[] arr = {5,4,3,2,7,9,1,0};
Arrays.sort(arr);
Student student1 = new Student("A", 2, 23);
Student student2 = new Student("B", 3, 21);
Student student3 = new Student("C", 1, 22);
Student[] students1 = new Student[] { student1, student2, student3 };
Arrays.sort(students1,new IdAscendingComparator());
printStudents(students1);
/**
Name : C, Id : 1, Age : 22
Name : A, Id : 2, Age : 23
Name : B, Id : 3, Age : 21
**/
Student[] students2 = new Student[] { student1, student2, student3 };
Arrays.sort(students2,new IdDescendingComparator());
printStudents(students2);
/**
Name : B, Id : 3, Age : 21
Name : A, Id : 2, Age : 23
Name : C, Id : 1, Age : 22
**/
}
同理也可以根据年龄进行排序。
在堆中使用
除了用在数组中,还可以用在有序的结构中,如小根堆(PriorityQueue),默认情况下是小根堆,可以通过比较器使其变成大根堆。
public static class AComp implements Comparator<Integer>{
//返回负数的时候,第一个参数排在上面
//返回正数的时候,第二个参数排在上面
//返回0的时候,谁在上面都无所谓。
@Override
public int compare(Integer o1, Integer o2) {
return o2 - o1;
}
}
public static void main(String[] args) {
//不使用比较器
PriorityQueue<Integer> heap = new PriorityQueue<>();
heap.add(3);
heap.add(5);
heap.add(1);
heap.add(4);
while (!heap.isEmpty()){
System.out.println(heap.poll());
}
/**
1
3
4
5
**/
//使用比较器
PriorityQueue<Integer> heap1 = new PriorityQueue<>(new AComp());
heap1.add(3);
heap1.add(5);
heap1.add(1);
heap1.add(4);
while (!heap1.isEmpty()){
System.out.println(heap1.poll());
}
/**
5
4
3
1
**/
}
比较器也可以用于比较复杂的比较策略。
8、桶排序
不基于比较的排序。应用范围没有基于比较的排序的应用范围广,不基于比较的排序是根据数据状况进行定制的。
8.1、计数排序
加入一个数组中存的是员工的年龄,那么这个数组中的数都是 0-200大小的。
1、可以申请一个201大小的额外数组,0位置代表 数字0的个数,1位置代表 数字1的个数,依次类推,200位置代表 数字200的个数,将原数组遍历一遍,就可以得到年龄的词频统计表。
2、然后将这个词频数组还原回原数组,假如词频数组中 0 位置为3,1位置为2,2位置为3,则排好序的原数组为:0 0 0 1 1 2 2 2。
整个过程的复杂度为 O(N)。
但是这种排序只适用于数组中数组比较小的情况(如上例中的0-200),如果对所有的整数排序就不适用。
8.2、基数排序
举例:
一个数组中有如下数字:
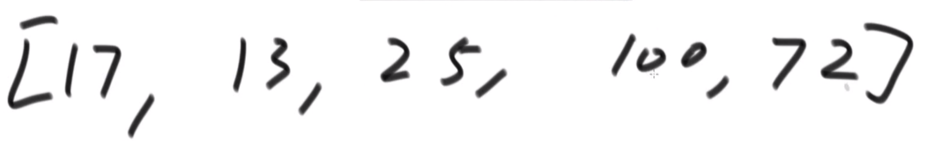
1、看最大的数字有几位(这里按照十进制看,有三位),所以把长度不到三位的数字左边要补齐0,得到如下数组:
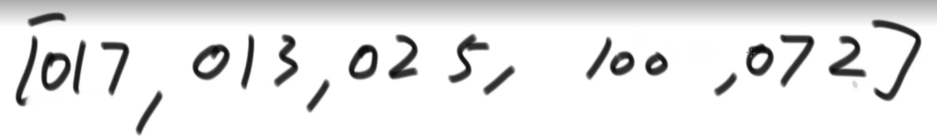
2、然后准备十个容器,可以认为是数组也可以是队列也可以是栈,在术语里面叫做桶,在这里以队列(先进先出)为例:
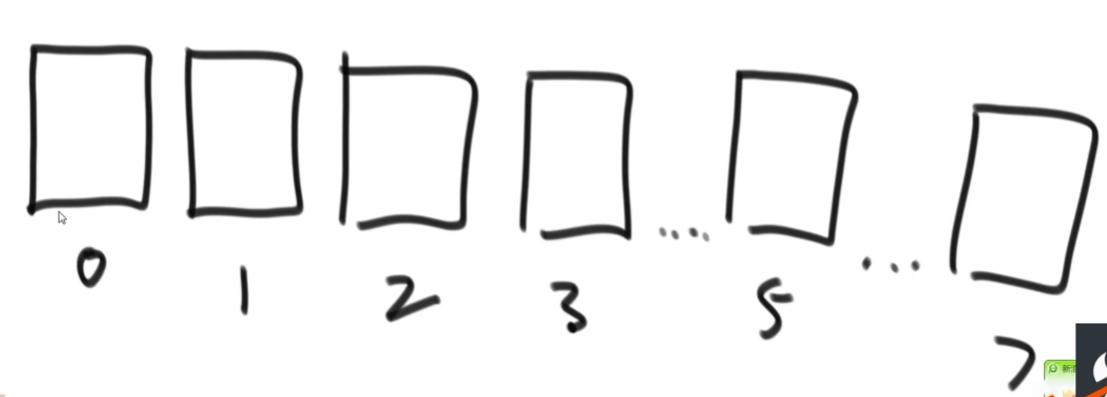
3、先根据个位数字哪个数字进入哪号桶里,例如017进入7号桶里,013进入3号桶里,依次类推。。。
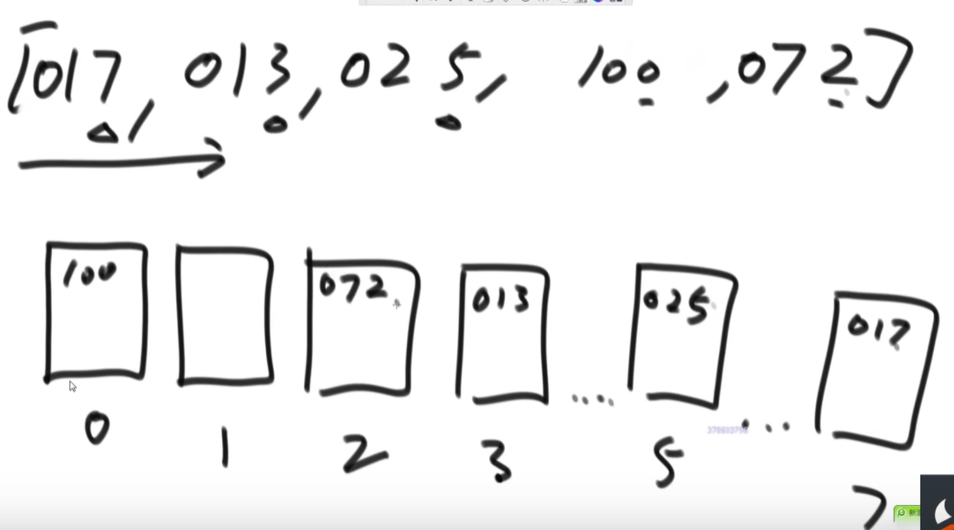
4、然后从左往右将桶中的数字倒出来,如果一个桶有多个数字则遵循先进先出的原则出桶。
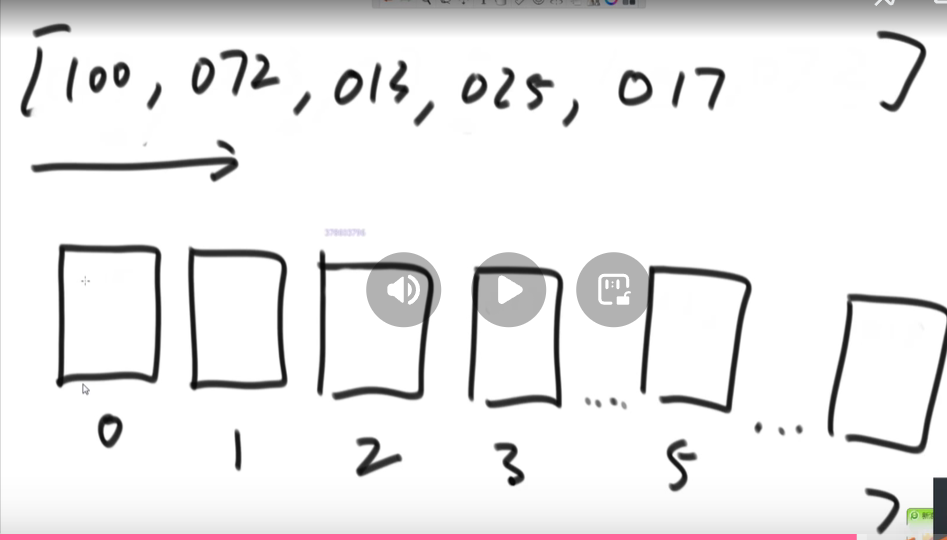
5、然后根据十位数字 进桶出桶,根据百位数字进桶出桶,。。。,直到根据最高位数字完成进桶出桶停止。即得到最终有序的序列。
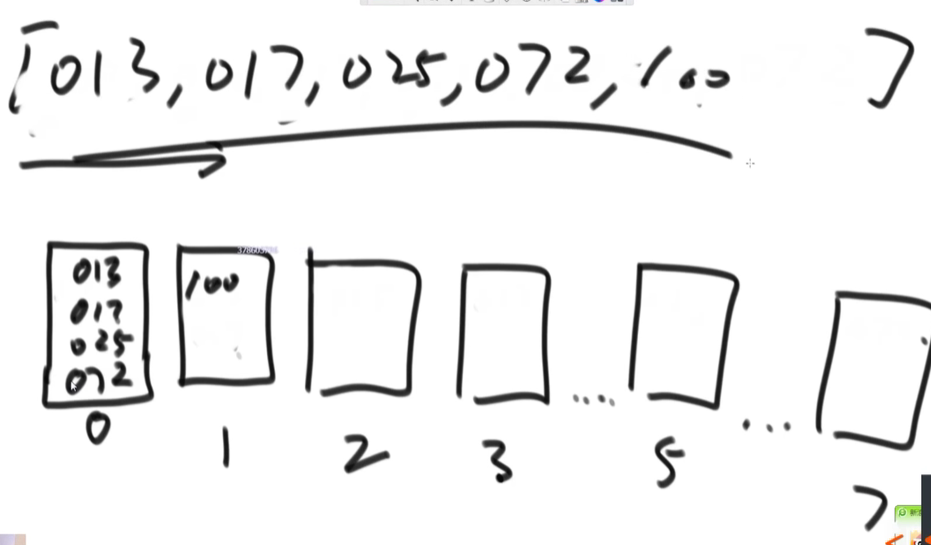
这种方法 排的对象必须有进制才可以。
而在代码实现过程中与上述过程略有不同:
1、使用一个长度位10的数组a保存 当前位(个,百,十)数字有几个,例如个位数字位 1 的有两个,那么数组下标为1的位置的值就为2;并开辟一个新数组b与原数组长度相同。
2、然后从下标为0开始遍历数组 将前一个下标上的数加到后一个数中,这样数组a中每一个下标中所对应的数 为 小于等于下标的数(这个数代表个,十,百位上的数对应的数)有多少个,例如:如果数组a中下标为2的数为4,则个为(或十,或百。。。)上小于等于2的数字有4个。

3、然后从右向左遍历原数组,找每个数x指定位(个位,十,或百。。。位)上的数c ,然后在数组a中找到这个数c所对应下标所对应的数组中的值d,并将原数组这个数x放入数组b中,这个数在数组中b中的下标为d-1,然后d--。最后将数组b中的数按顺序再放回原数组中。

4、遍历完个位后,遍历十位,百位,直到最高位遍历完成。
这里使用数组进行词频统计来代替桶。
排序总结:

在不考虑稳定性和空间限制的时候使用快排,有空间限制的时候使用堆排,考虑稳定性就是用归并排序。
常见的坑:
- 归并排序的额外空间复杂度可以变成O(1),但是非常难,不需要掌握,有兴趣可以搜“归并排序 内部缓存法”。
- “原地归并排序”的帖子都是垃圾,会让归并排序的时间复杂度变成O(N^2)。
- 快速排序可以做到稳定性问题,但是非常难,不需要掌握, 可以搜“01 stable sort”。
- 所有的改进都不重要,因为目前没有找到时间复杂度O(N*logN),额外空间复杂度O(1),又稳定的排序。
- 有一道题目,是奇数放在数组左边,偶数放在数组右边,还要求原始的相对次序不变,碰到这个问题,可以怼面试官。(快排的思想(01标准)快排做不到稳定性在 01 stable sort可以做到,但是很难。)
工程上对排序的改进:
- 充分利用O(N*logN)和O(N^2)排序各自的优势
- 稳定性的考虑
链表
1、哈希表和有序表(无重复数据)
1.1、哈希表的简单介绍:
- 哈希表在使用层面上可以理解为一种集合结构
- 如果只有key,没有伴随数据value,可以使用HashSet结构(C++中叫UnOrderedSet)
- 如果既有key,又有伴随数据value,可以使用HashMap结构(C++中叫UnOrderedMap)
- 有无伴随数据,是HashMap和HashSet唯一的区别,底层的实际结构是一回事
- 使用哈希表增(put)、删(remove)、改(put)和查(get)的操作,可以认为时间复杂度为O(1),但是常数时间比较大。
- 放入哈希表的东西,如果是基础类型,内部按值传递,内存占用就是这个东西的大小
- 放入哈希表的东西,如果不是基础类型,内部按引用传递,内存占用是这个东西内存地址的大小。
1.2、有序表的简单介绍:
-
有序表在使用层面上可以理解为一种集合结构。
-
如果只有key,没有伴随数据value,可以使用TreeSet结构(C++中叫OrderedSet)
-
如果既有key,又有伴随数据value,可以使用TreeMap结构(C++中叫OrderedMap)
-
有无伴随数据,是TreeSet和TreeMap唯一的区别,底层的实际结构是一回事
-
有序表和哈希表的区别是,有序表把key按照顺序组织起来,而哈希表完全不组织
-
红黑树、AVL树、size-balance-tree和跳表等都属于有序表结构,只是底层具体实现不同
-
放入有序表的东西,如果是基础类型,内部按值传递,内存占用就是这个东西的大小
-
放入有序表的东西,如果不是基础类型,必须提供比较器,内部按引用传递,内存占用是这个东西内存地址的大小
-
不管是什么底层具体实现,只要是有序表,都有以下固定的基本功能和固定的时间复杂度:
-
void put(K key, V value):将一个(key,value)记录加入到表中,或者将key的记录
更新成value。 -
V get(K key):根据给定的key,查询value并返回。
-
void remove(K key):移除key的记录。
-
boolean containsKey(K key):询问是否有关于key的记录。
-
K firstKey():返回所有键值的排序结果中,最左(最小)的那个。
-
K lastKey():返回所有键值的排序结果中,最右(最大)的那个。
-
K floorKey(K key):如果表中存入过key,返回key;否则返回所有键值的排序结果中,key的前一个。
-
K ceilingKey(K key):如果表中存入过key,返回key;否则返回所有键值的排序结果中,key的后一个。
以上所有操作时间复杂度都是O(logN),N为有序表含有的记录数
-
2、单链表和双链表
单链表和双链表结构只需要给定一个头部节点head,就可以找到剩下的所有的节点。
2.1、单链表
只有一个指向下一个节点的指针
Class Node<V>{
V value;
Node next;
}

2.2、双链表
有两个指针,一个指向前一个节点,一个后一个节点。
Class Node<V>{
V value;
Node next;
Node last;
}

3、相关题目
3.1、反转单向和双向链表
题目描述:分别实现反转单向链表和反转双向链表的函数
要求:如果链表长度为N,时间复杂度要求为O(N),额外空间复杂度要求为O(1)
单向链表:
//单向链表
public static class Node{
public int value;
public Node next;
public Node(int data){
this.value = data;
}
}
//反转单向链表
public static Node reverseList(Node head){
//反转节点的前驱节点
Node pre = null;
//反转节点的后继节点
Node next = null;
//当head不为空时
while (head != null){
//用next保存head下一个节点的信息
next = head.next;
//当前节点向前指,
head.next = pre;
//下一个节点的前驱节点变为当前节点
pre = head;
//将下一个节点变成当前节点
head = next;
}
return pre;
}
双向链表
//双向链表
public static class DoubleNode{
public int value;
public DoubleNode last;
public DoubleNode next;
public DoubleNode(int data){
this.value = data;
}
}
public static DoubleNode reverseList(DoubleNode head){
//反转节点的前驱节点
DoubleNode pre = null;
//反转节点的后继节点
DoubleNode next = null;
//当head不为空时
while (head != null){
//用next保存head下一个节点的信息
next = head.next;
//将当前节点的下一个值向前指,
head.next = pre;
//将当前节点的前一个值向后指,
head.last = next;
////下一个节点的前驱节点变为当前节点
pre = head;
//将下一个节点变成当前节点
head = next;
}
return pre;
}
3.2、打印两个有序链表的公共部分
题目:给定两个有序链表的头指针head1和head2,打印两个链表的公共部分。
要求:如果两个链表的长度之和为N,时间复杂度要求为O(N),额外空间复杂度要求为O(1)
1、一开始两个指针分别指向两个链表的头部,
2、谁的值小,谁指向下一个;
3、相等的时候打印数字,两个都指向下一个;
4、当两个链表有一个为空的时候停止。
3.3、面试时链表解题的方法论
- 对于笔试,不用太在乎空间复杂度,一切为了时间复杂度
- 对于面试,时间复杂度依然放在第一位,但是一定要找到空间最省的方法
重要技巧:
- 额外数据结构记录(哈希表等)。
- 快慢指针。
3.4、判断一个链表是否为回文结构
题目:给定一个单链表的头节点head,请判断该链表是否为回文结构。
例子:1->2->1,返回true; 1->2->2->1,返回true;15->6->15,返回true;1->2->3,返回false。
如果链表长度为N,时间复杂度达到O(N),额外空间复杂度达到O(1)。
方法1(笔试解法):
创建一个栈,然后遍历链表,依次将每个节点放入栈中,这样栈中弹出的顺序就是链表逆序的顺序。然后再从头遍历链表,每遍历一个就从栈中弹出一个,比对两个节点一不一样就好了。在比对的过程中有一个不一样就不是回文了。
方法2(方法1简化版):
只需要把链表右边部分放入栈中,然后链表从头与栈中弹出的节点对比,有不同的就不是回文,直到栈中节点全部弹出。
但是怎么只把右边部分放入栈中?使用快慢指针:慢指针每次走一步,快指针每次走两步,快指针走完的时候,慢指针走到中间,然后把慢指针后的内容放入栈中(这里需要自己琢磨,需要根据不同的情况编写合适的快慢指针)。
方法3(面试版,不使用额外空间):
快指针每次走两步,慢指针每次走一步,在快指针走完的时候,慢指针来到中点的位置。接下来,中点往下遍历的时候,将遍历的节点逆序(中位置指向空,后面内容指向前一个节点)
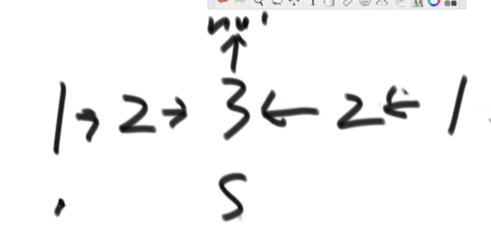
链表开始和结束的节点分别用一个引用(A和B)记住,然后A和B同时向中间走,对比A和B所在位置内容是否一样,直到有一个空。在返回的时候将链表调整会原来的样子。

3.5、将单向链表按某值划分成左边小、中间相等、右边大的形式
题目:给定一个单链表的头节点head,节点的值类型是整型,再给定一个整数pivot。实现一个调整链表的函数,将链表调整为左部分都是值小于pivot的节点,中间部分都是值等于pivot的节点,右部分都是值大于pivot的节点。
进阶:在实现原问题功能的基础上增加如下的要求:
- 调整后所有小于pivot的节点之间的相对顺序和调整前一样
- 调整后所有等于pivot的节点之间的相对顺序和调整前一样
- 调整后所有大于pivot的节点之间的相对顺序和调整前一样
- 时间复杂度请达到O(N),额外空间复杂度请达到O(1)。
方法一(笔试版):创建一个Node类型的数组,将链表上的所有的节点放入数组中,然后在数组上做partition(荷兰国旗问题,快排)。然后再把数组中的节点一个一个串起来就好了。
方法二(面试版):
准备六个节点变量,小于部分的头SH,小于部分的尾ST,等于部分的头EH,等于部分的尾,大于部分的头BH,大于部分的尾BT,一开始让着六个变量都指向空。

从左到右看链表中的节点,第一个为4,其小于5,则让小于部分的头SH和尾ST都指向这个节点;再看第二个节点,其值为6,则让大于部分的头BH和尾BT都指向该节点;再看第三个节点,值为3 ,让之前发现的小于5的节点的next指针指向该节点,小于部分的尾也指向该节点;下一个节点为5,则让等于部分的头EH和尾ET都指向该节点;下一个节点尾8,则让之前发现的大于5的节点指向该节点,大于部分的尾也指向该节点。其余节点依次类推...
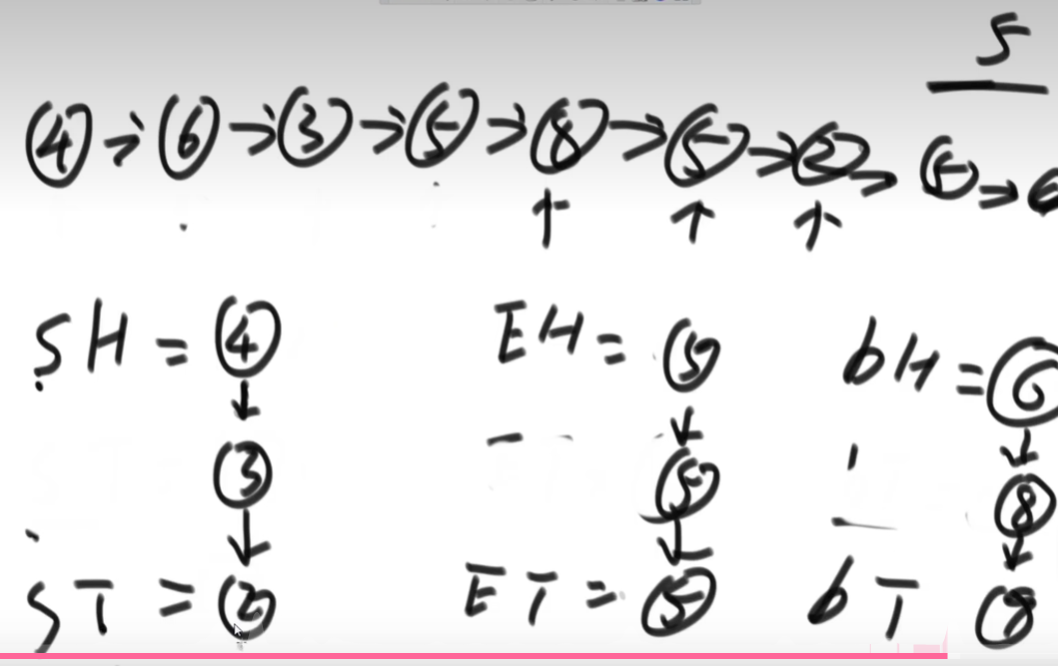
最后,小于部分的尾ST连等于部分的头EH,等于部分的尾ET连大于部分的头BH。
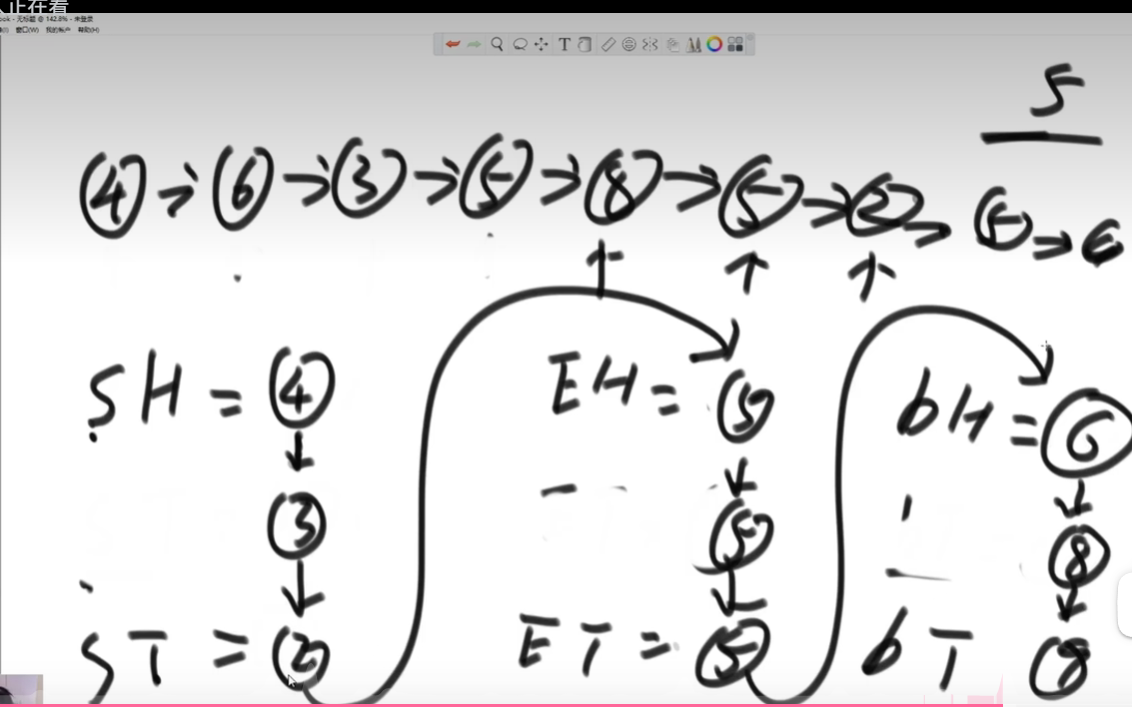
3.6、复制含有随机指针节点的链表
题目:一种特殊的单链表节点类描述如下
class Node {
int value;
Node next;
Node rand;
Node(int val) {
value = val;
}
}
rand指针是单链表节点结构中新增的指针,rand可能指向链表中的任意一个节点,也可能指向null。给定一个由Node节点类型组成的无环单链表的头节点head,请实现一个函数完成这个链表的复制,并返回复制的新链表的头节点。
方法一(需要额外空间)
1、准备一个哈希表(HashMap),哈希表的key为Node类型,存放老节点,value也为Node类型,存放克隆出来的新节点。
2、设置新链表next方向和random方向的指针,可以遍历老链表或者哈希表,根据老链表中节点在哈希表的value值将新链表的next和random节点找出来。
例如老链表中1节点的下一个节点为2,则从哈希表中找出2对应的克隆节点2‘ ,并将其作为1’的next节点,random节点也是同样的方式。最后把新链表第一个节点返回即可。
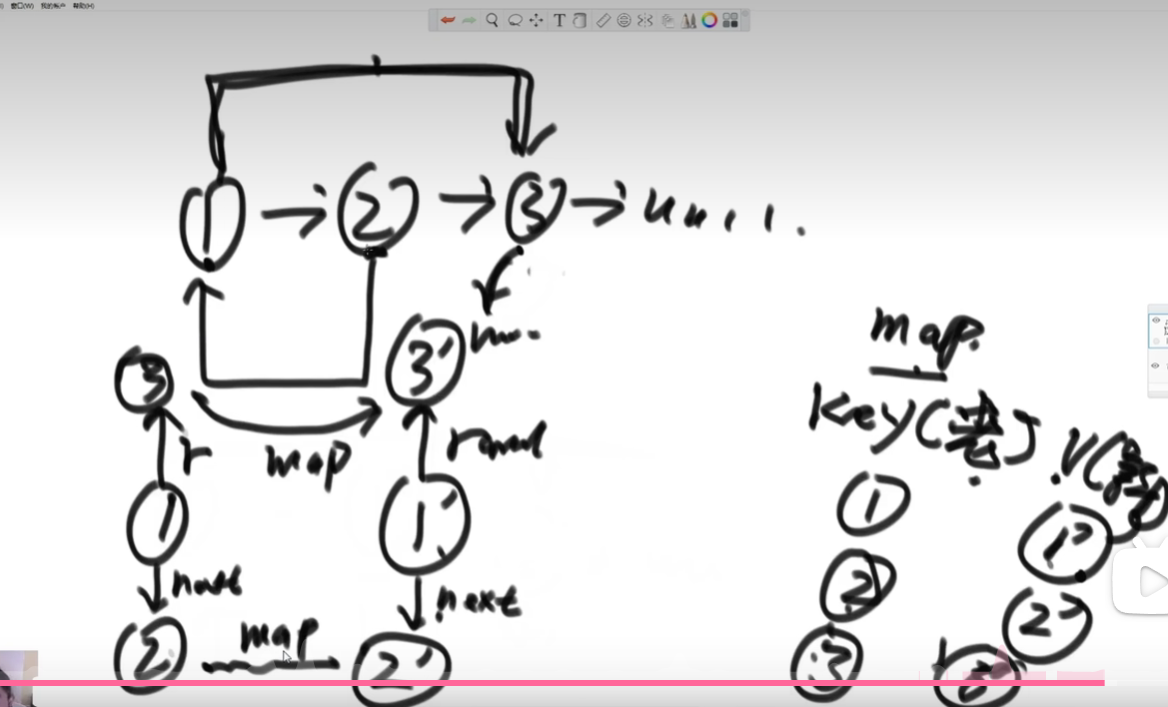
方法二(不用哈希表)
1、生成克隆节点,把克隆节点就放在老链表的下一个,然后克隆节点去串上老链表的下一个。新节点的random指针都没有设置。
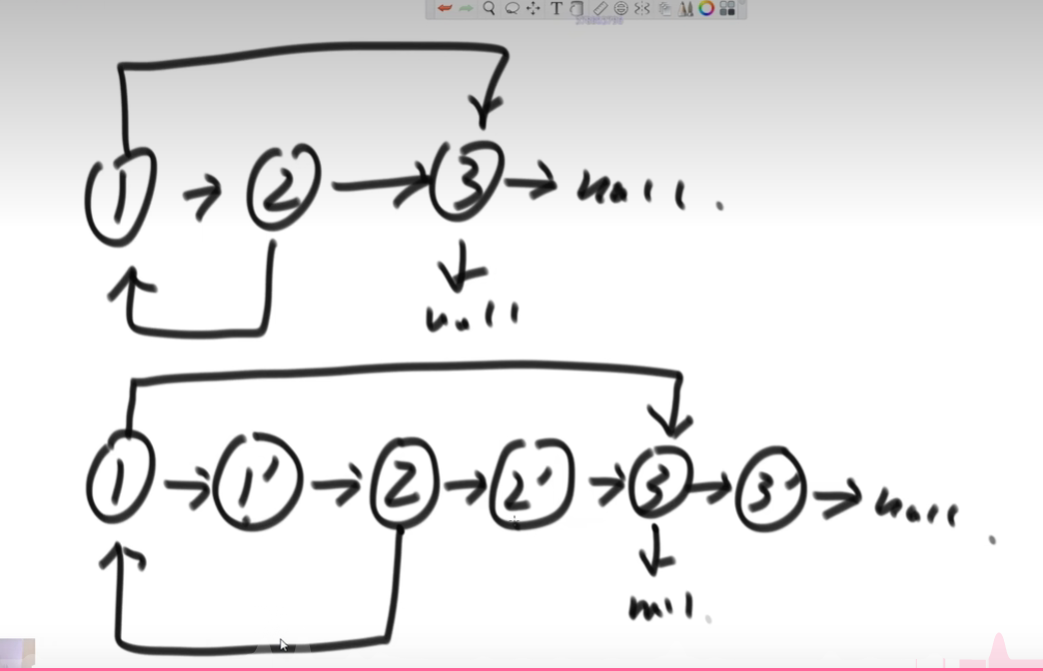
2、然后一对一对的拿,设置每一个克隆节点的random指针。
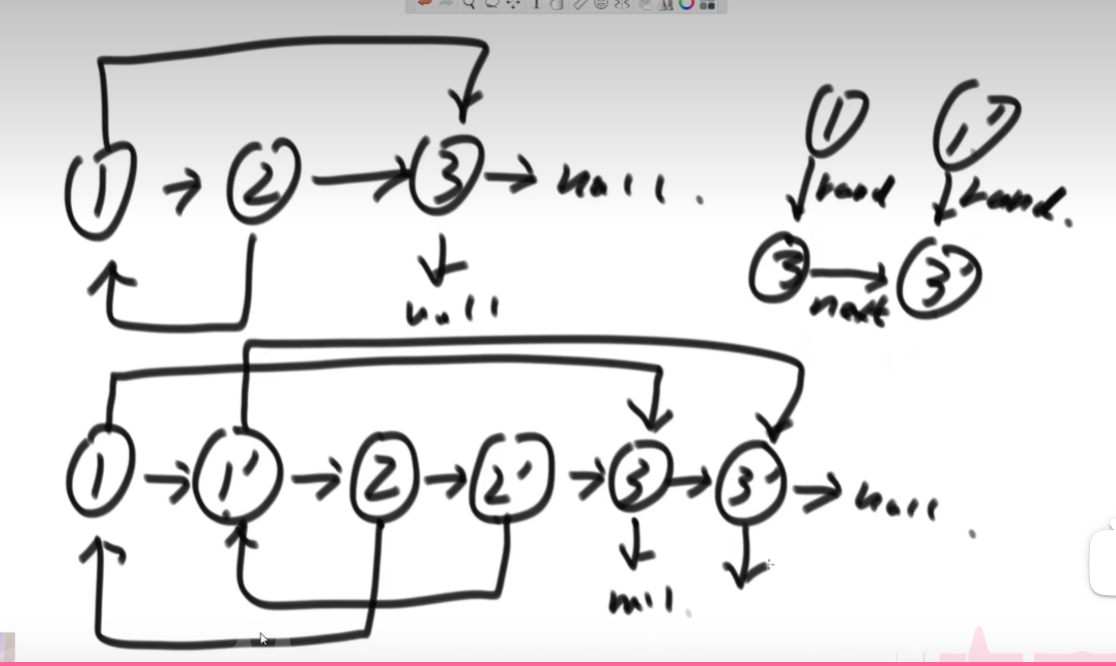
3、最后在next的方向上将新老链表分开。
3.7、两个单链表相交的一系列问题
题目:给定两个可能有环也可能无环的单链表,头节点head1和head2。请实现一个函数,如果两个链表相交,请返回相交的 第一个节点。如果不相交,返回null。
要求:如果两个链表长度之和为N,时间复杂度请达到O(N),额外空间复杂度请达到O(1)。
子问题1:判断一个链表是否有环,如果有环,返回第一个入环的节点,无环则返回false。
方法1(使用哈希表):
从头节点,依次将节点放入哈希表中,同时检查该节点是否在哈希表中,当第一次查到某个节点在哈希表中,那么这个节点为第一个入环节点。
方法2(不使用哈希表,使用快慢指针):
1、快慢指针一开始在头节点(或者慢指针往前走一步,快指针往前走两步),快指针一次走两步,慢指针一次走一步,如果快指针指向了空,那么该链表没有环。
2、如果快慢指针相遇了,那么一定是在环上相遇的(即该链表存在环),且在环上转的圈数不会大于两圈以上。
3、相遇之后,快指针回到开头,慢指针还在原来的位置,接下来,两个指针都每次走一步,他俩一定会在第一个入环节点处再次相遇(比较魔幻,不想证明)
回到主问题:
讨论主问题,
有两个链表,第一个链表(头为head1)的入环节点为 loop1 ,第二个链表(头为head2)的入环节点为 loop2 。
-
当loop1 为空,loop2也为空,两个单链表都没有环,也有相交和不相交两种情况:
-
不相交:就没有相交部分的第一个节点

-
相交:
两个无环单链表,如果相交的话,从相交的地方一直往下走到空都共有。
方法:第一个链表从头节点head1开始遍历,一直遍历到最后一个节点,最后一个节点记为end1,长度记为len1;第二个链表也从头节点head2开始遍历,一直遍历到最后一个节点,最后一个节点记为end2,长度记为len2。假设len1长度为100,len2长度为80。
先判断end1和end2的内存地址是不是一个,如果不是一个,head1和和head2所在的链表不可能相交。
如果地址是同一个,那么两个链表相交,找相交的第一个节点的方法为:从头节点开始,长度较长的链表先走两个链表的差值步(如len1 为100,len2为80,则链表1先走100-80=20步),然后较短的链表和较长链表一起走,他俩一定会在相交的第一个节点相遇。
-
-
loop有一个为空,另一个不为空,即一个为有环链表,另一个为无环链表。这种情况下两个链表不可能相交。
-
两个链表都有环:
-
两个链表不相交

-
共用环,入环节点是一个

是下面这个样子:

-
共用环,入环节点不是一个
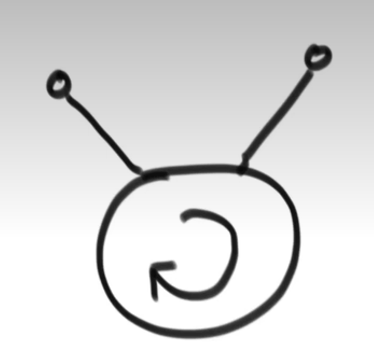
是下面这个样子:

第一个链表的入环节点为 loop1,第二个链表的入环节点为loop2,如何区分上述三种情况:
- 第二种情况最好区分,loop1的内存地址和loop2的内存地址是同一个,此时就可以把他看成无环链表的相交问题。l此时把loop1和loop2看成终止节点。
- 第一和第三种情况的区分:流程是:让loop1继续往下走,在转回到自己之前,如果能遇到loop2就是情况三,没有遇到loop2就是情况一。
- 如果是情况一,第一个相交的节点就是空
- 如果是情况三,返回loop1或返回loop2都对。
-
二叉树
二叉树节点结构:
class Node<V>{
V value;
Node left;
Node right;
}
二叉树是一种每个结点至多只有两个子树(即二叉树的每个结点的度不大于2),并且二叉树的子树有左右之分,其次序不能任意颠倒。
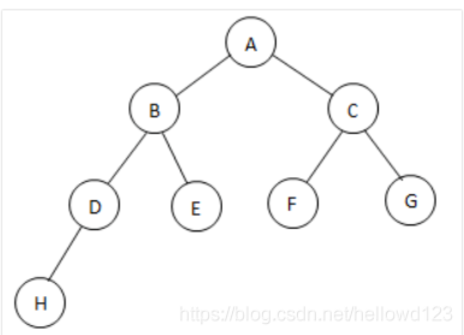
1、先序、中序、后序遍历
用递归和非递归两种方式实现二叉树的先序、中序、后序遍历
1.1、递归方式:
递归方式较为简单,每个节点都会被查看三次,如下面一个二叉树的递归序如下:

在递归序的基础上可以加工出三种序的遍历 :先序、中序和后序。
1、先序遍历:对所有的子树来说,先打印头节点,再打印左子树上的所有节点,再打印右子树上的所有节点。其实现为:递归序中,第一次到某个节点的时候就打印,再第二三次到达的时候不打印

2、中序遍历:对每一个子树,先打印左树,再打印头节点,最后打印右树上的节点。其实现为:再递归序中,第二次来到某个节点的时候才打印,第一次和第三次什么也不干。
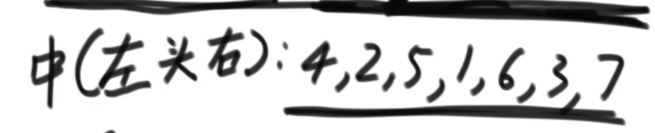
3、后序遍历:对于每一个子树,先打印左数,再打印右树,最后再打印中间节点。其实现为:再递归序中,第三次来到某个节点的时候才打印,第一次和第二次什么也不干。
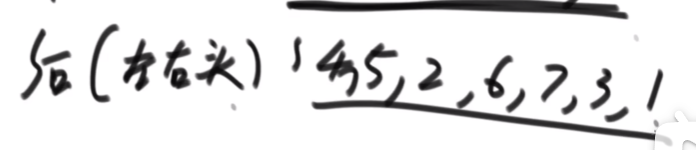
1.2、不使用递归方式:
1、先序遍历:准备一个栈,先把头节点放进栈中,执行以下的固定流程:
①、 每次从栈中弹出一个节点记为 cur 。
②、 打印(处理) cur。
③、 先右后左(左右两个节点)压入栈 (如果有)。
④、 重复① - ③。
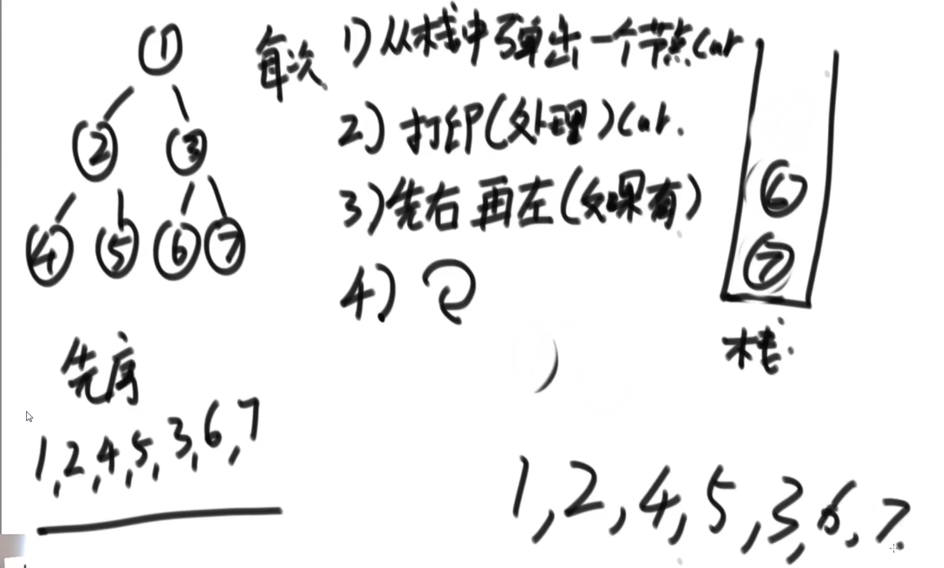
2、后序遍历:准备两个栈,一个栈1,一个栈2(记为收集栈)。先把头节点放入栈1中。进行如下的操作:
①、从栈1中弹出一个节点 cur。
②、将节点cur放入收集栈中。
③、先左后右(左右两个节点)放入栈中。
④、重复上述操作。
⑤、收集完成后,依次弹出收集栈中的数据。
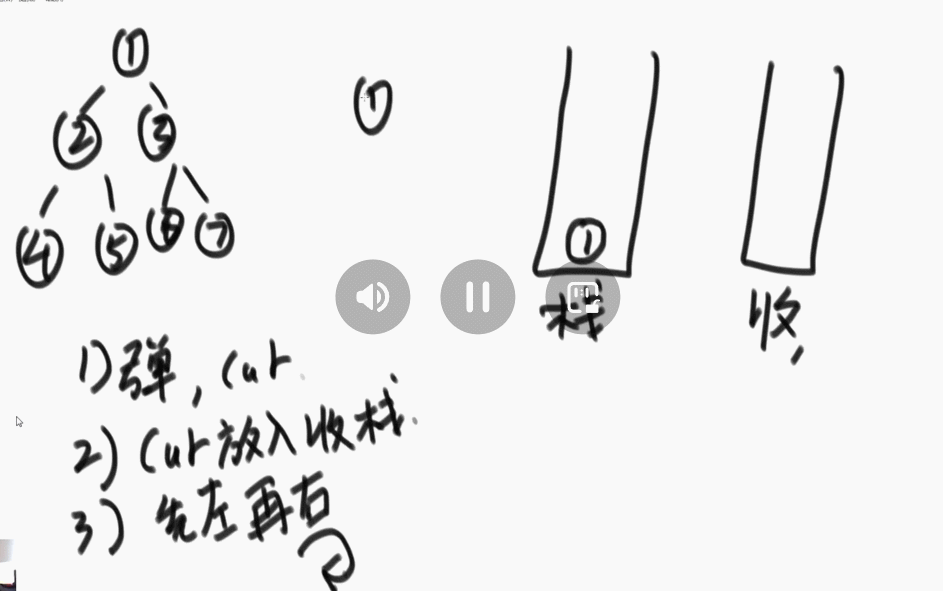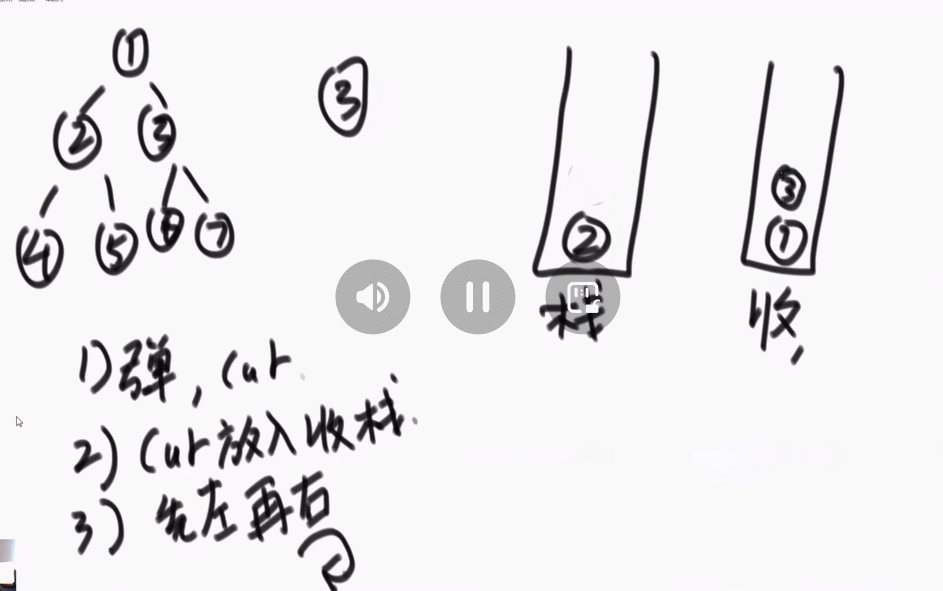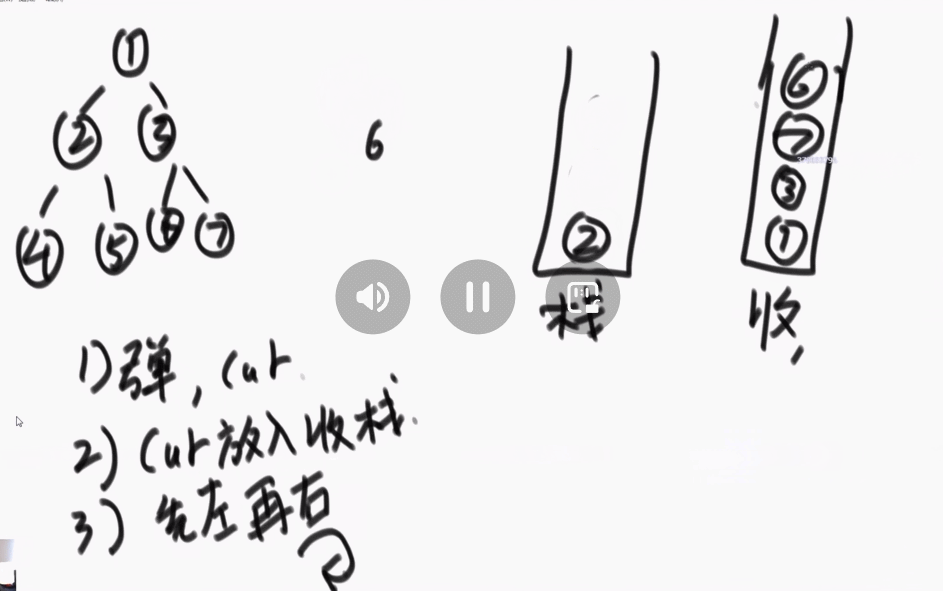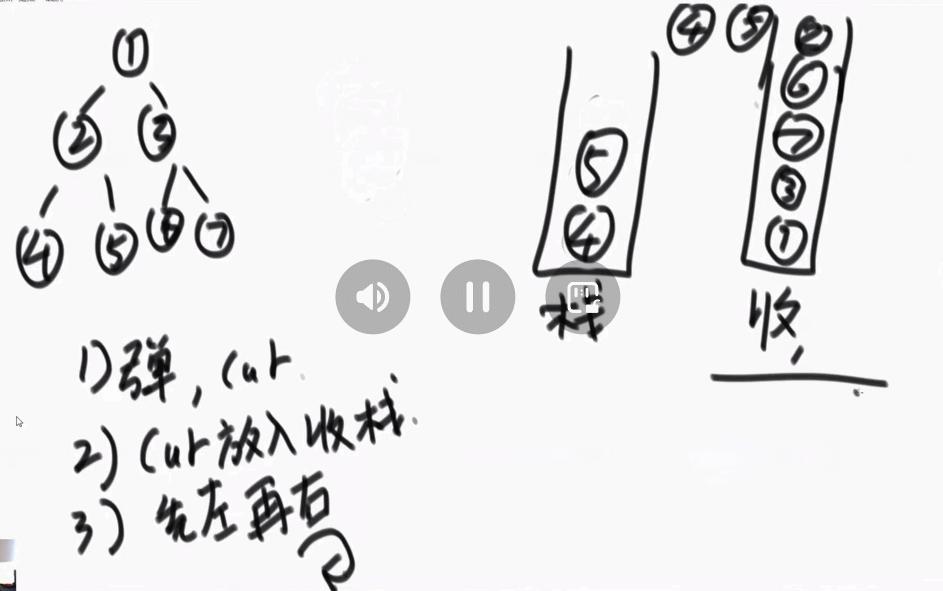
得到最终的序列:4、5、2、6、7、3、1
3、中序遍历:准备一个栈
每棵子树,整个树左边界进栈,依次弹出节点的过程中打印节点,对弹出节点的右树重复(将左边界进栈,依次弹出节点的过程中打印节点,对弹出节点的右树重复)。
得到最终的序列:4、2、5、1、6、3、7
如何直观的打印一颗二叉树
一个福利函数,打印二叉树的形状。
2、如何完成二叉树的宽度优先遍历
二叉树的深度优先遍历就是二叉树的先序遍历。
宽度优先遍历:准备一个队列,先把头节点放入队列中,每一次弹出就打印,放入弹出节点的左右节点(先放左再放右),周而复始。
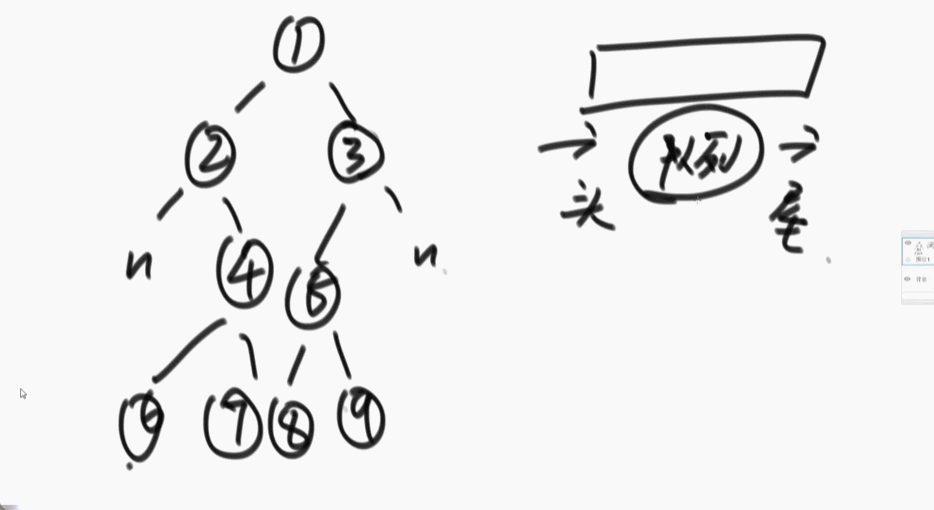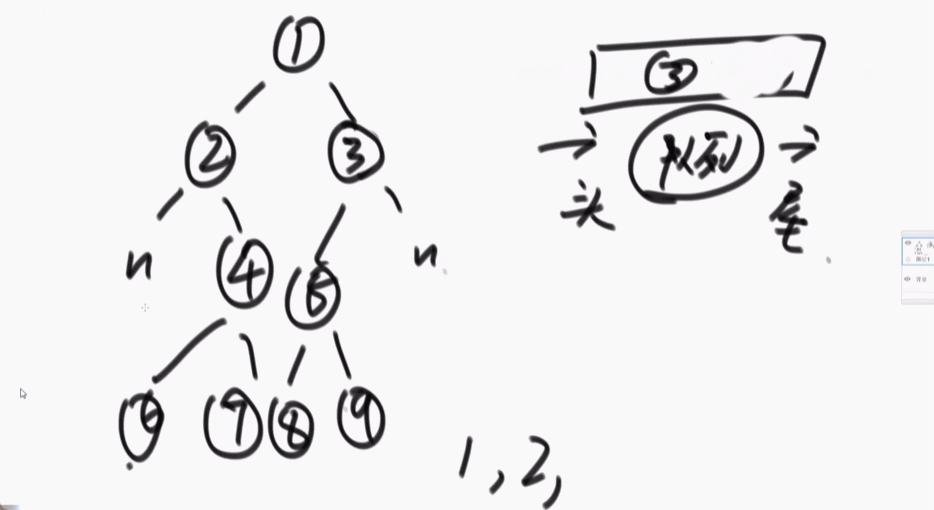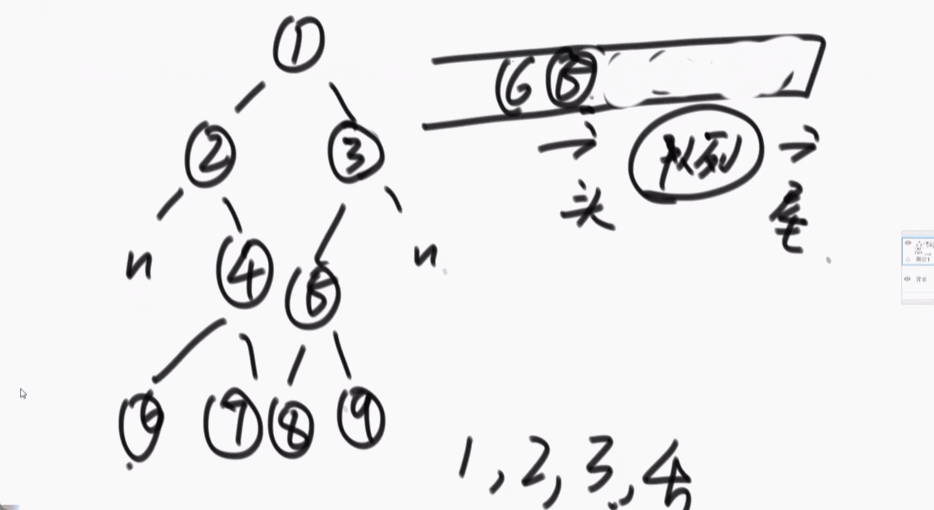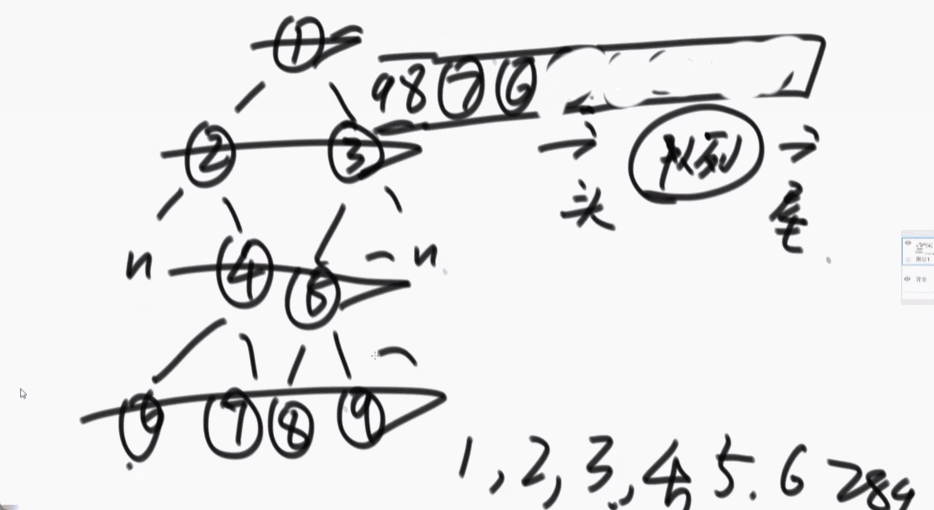
代码:
public static void w(Node head){
if(head == null){
return;
}
//队列
LinkedList<Node> queue = new LinkedList<>();
queue.add(head);
while (!queue.isEmpty()){
//弹出队首节点
Node cur = queue.poll();
System.out.println(cur.value);
//先放左边节点再放右边节点
if (cur.left != null){
queue.add(cur.left);
}
if (cur.right != null){
queue.add(cur.right);
}
}
}
2.1、常见题目:求一棵二叉树的宽度
使用哈希表:
设置一个map,初始头节点在第一层,从第一层开始,记当前层curLevel = 1 ; 当前层发现了0个节点,记Nodes = 0,全局宽度最大值为max = -inf,头节点放入队列。
1、弹出一个节点cur,并从map中拿到该节点cur属于第几层,记为curNodeLevel。
2、如果该节点的层curNodeLevel 与 当前层curLevel相同,则当前层的节点数Nodes ++。
3、如果该节点的层curNodeLevel 与 当前层curLevel不同,则比较当前层的节点数与之前层节点数谁大(即宽度谁大),保存节点数大的数量,将当前层curLevel ++ ,当前层的节点数Nodes=1。
4、如果节点cur 有左节点,在map中记录左节点的层号(为cur的层号curNodeLevel + 1),并将左节点放入队列中
5、如果节点cur 有右节点,在map中记录右节点的层号(为cur的层号curNodeLevel + 1),并将右节点放入队列中
6、周而复始上述操作,直到队列为空。
不使用哈希表:
不使用哈希表,需要使用队列,设置当前层最后一个节点(Node curend = ①),下一层最后一个节点(Node nextend = null),当前层发现的节点数(curlevel = 0)。后面看视频实现一下。
3、二叉树的相关概念及其实现判断
3.1、如何判断一棵二叉树是否是搜索二叉树
搜索二叉树:对于每一个子树来说,左树的节点都比它小,右树的节点都比它大。
解决方法1:使用中序遍历,如果依次遍历的每个节点都是升序的话就是搜索二叉树,否则就不是搜索二叉树。
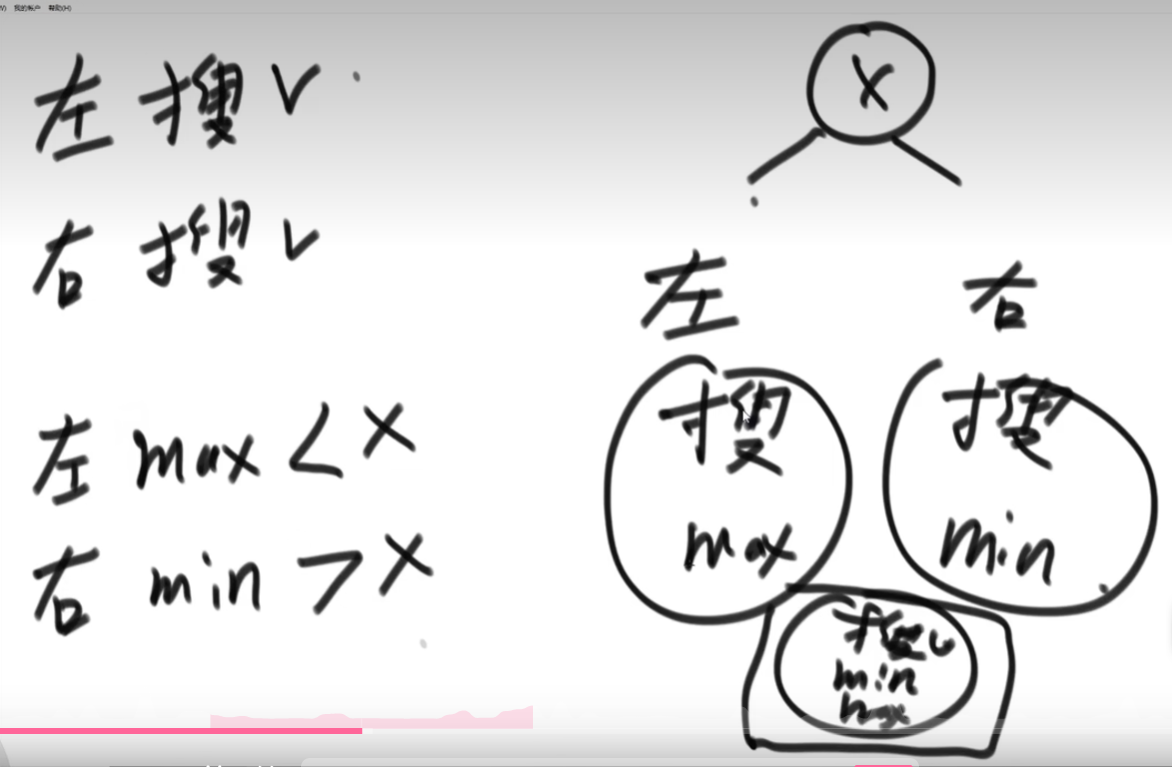
解决方法2:使用递归套路求解(树形DP),判断X为头的树是否为搜索二叉树,向左树和右树要信息:
1、左树需要是搜索二叉树
2、右树需要是搜索二叉树
3、左树上的最大值 应该小于X,右树上的最小值应该大于X。
以上三个条件都成立,整棵二叉树才是搜索二叉树。需要向左树要的信息为(是否为搜索二叉树和最大值),向右树要的信息为(是否为搜索二叉树和最小值),这样一来,左树和右树要求变得不一样了,递归套路要求对每一个节点都是一样的,因此不管是左树还是右树,需要返回三个信息(是否为搜索二叉树、最大值,最小值)。
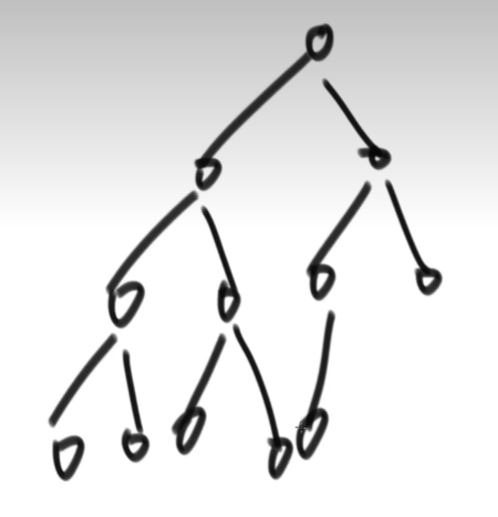
3.2、如何判断一棵二叉树是完全二叉树
完全二叉树,要么每一层是满的(满二叉树),如果不满也是最后一层不满,即便最后一层不满,也是从左到右依次是满的。
判断方法:
按照宽度遍历二叉树:
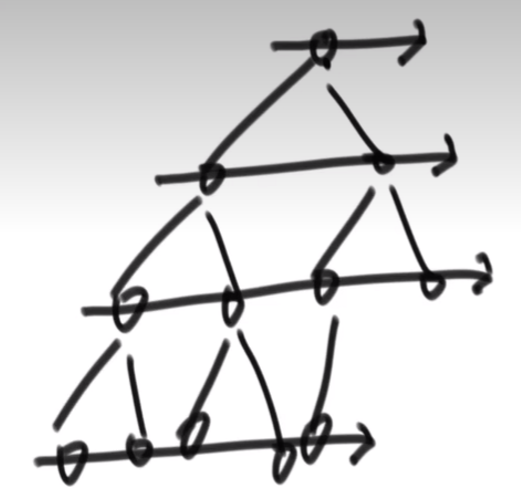
在依次遇到每一个节点的过程中,出现以下情况:
(1)、任一节点,有右无左,则为false(不是完全二叉树)。
(2)、在 (1) 不违规的条件下,如果遇到了第一个左右孩子不全的情况,则后续节点必须全为叶节点,否则不是完全二叉树。
3.3、如何判断一棵二叉树是否是满二叉树
满二叉树,每一层的节点都是满的。
解决方法:(代码在后面讲)
统计整个树的最大深度 l,再统计这课树的节点个数 N,如果满足 N = \(2^l\)-1,则这棵树一定是满二叉树。
使用递归套路求解:
public class IsFBT {
//二叉树的类
public static class Node{
public int value;
public Node left;
public Node right;
public Node(int data){
this.value = data;
}
}
//调用该函数判断是否为满二叉树
public static boolean isF(Node head){
if(head == null){
return true;
}
Info data = process(head);
return data.nodes == (1 << data.height - 1);
}
//每个子树向上返回的信息,包括节点数和树的深度
public static class Info{
public int height;
public int nodes;
public Info(int h,int n){
height = h;
nodes = n;
}
}
//递归方法
public static Info process(Node n){
if(n == null){
return new Info(0,0);
}
//收集左右子树的信息
Info leftInfo = process(n.left);
Info rightInfo = process(n.right);
//加工左右子树的信息并向上返回。
int height = Math.max(leftInfo.height,rightInfo.height) + 1;
int nodes = leftInfo.nodes + rightInfo.nodes + 1;
return new Info(height,nodes);
}
}
3.4、如何判断一棵二叉树是否是平衡二叉树
平衡二叉树:对于任何一个子树来说,它的左树和右树的高度差都不超过1。
解决方法(二叉树题目套路):
以X为头的 子树, 判断它是不是平衡二叉树,如果这棵树是平衡二叉树的话,需要满足下面三个条件:
1、 X的左子树是平衡二叉树。
2、X的右子树是平衡二叉树。
3、左子树和右子树的高度差小于等于1.
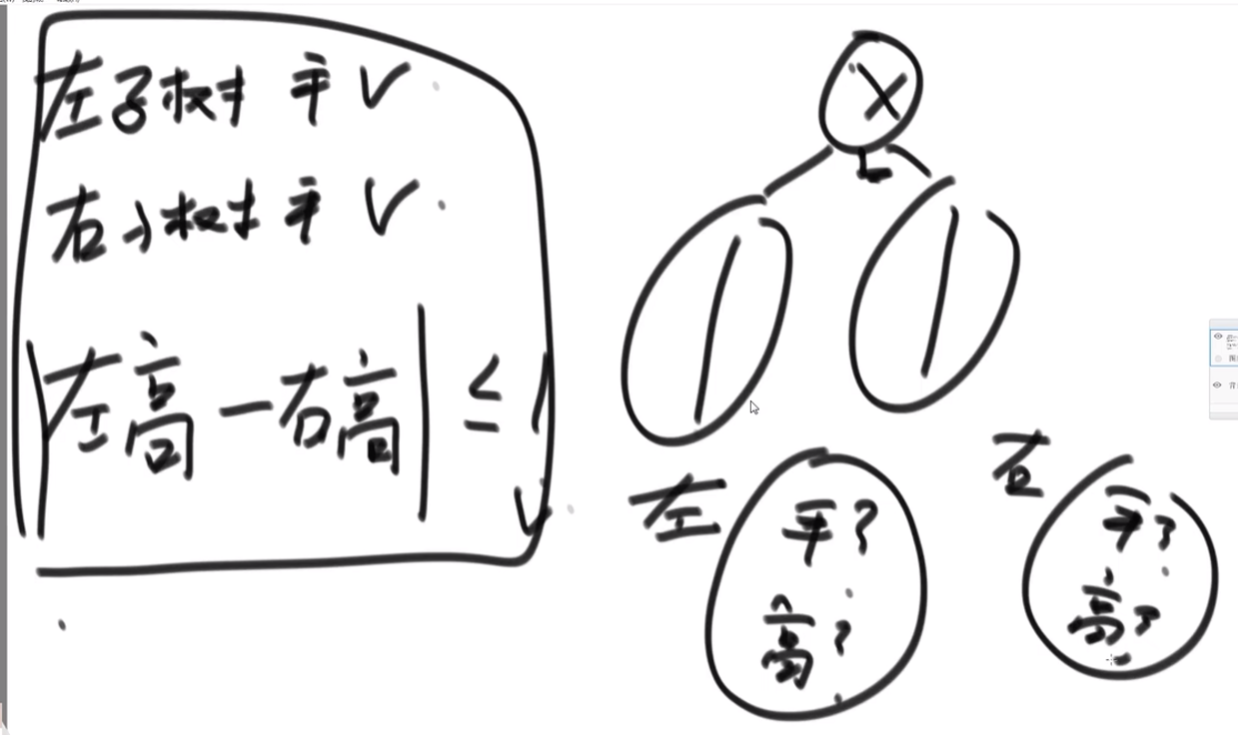
二叉树题目套路(递归套路):
递归套路可以解决面试中所有的树形DP问题,
树形DP就是在树上做动态规划,左树给的信息和右树给的信息就是他们动态规划所出来的结果,怎么通过他们的信息加工出自己的动态规划然后往上给。
4、给定两个二叉树的节点node1和node2,找到他们的最低公共祖先节点
最低公共祖先节点:两个点最先汇聚的点就是最先公共祖先节点。例如D节点和F节点的最低公共祖先节点是B节点,E节点和F节点最低公共祖先节点是E节点。
解决方法1:生成每个节点向上的节点是什么,就可以找到最低公共祖先节点了。
1、首先将每个节点及其对应的父节点放入一个map中。
2、将其中一个节点D的父节点,父节点的父节点,。。。直到根节点全都放在一个set集合中。
3、然后查看另一个节点F的的父节点,父节点的父节点,查看哪一个节点已经被放在了set集合中,最先发现的在set集合的节点就是最低公共祖先节点了。
解决方法2:
从两种情况考虑:
1、O1是O2的最低公共祖先,或O2是O1的最低公共祖先,
2、O1与O2不互为最低公共祖先。‘
解决方法2的代码如下:
public static Node lowestAncestor(Node head,Node o1,Node o2){
if(head == null || head == o1 || head == o2){
return head;
}
Node left = lowestAncestor(head.left,o1,o2);
Node right = lowestAncestor(head.right,o1,o2);
//左右两棵树,都有返回值
if(left != null && right != null){
return head;
}
//左右两棵树,并不都有返回值
return left != null ? left : right;
}
5、在二叉树中找到一个节点的后继节点
题目:现在有一种新的二叉树节点类型如下:
public class Node {
public int value;
public Node left;
public Node right;
public Node parent;
public Node(int val) {
value = val;
}
}
该结构比普通二叉树节点结构多了一个指向父节点的parent指针。
在二叉树的中序遍历的序列中, node的下一个节点叫作node的后继节点。例如下图中,D的后继节点为B,B的后继节点为E,。。。,G后继节点为null。

假设有一棵Node类型的节点组成的二叉树,树中每个节点的parent指针都正确地指向自己的父节点,头节点的parent指向null。
只给一个在二叉树中的某个节点node,请实现返回node的后继节点的函数。(以一种简单的方式,而不需要使用中序遍历遍历整棵二叉树)
方法:(找X的后继节点为例)
1)如果X有右树,则为右树的最左节点。
2)如果X没有右树,一路往上找节点,当发现某一个节点为他父节点左孩子的时候。这个父节点就是X的后继节点。
3)总有一个节点没有后继节点。
6、二叉树的序列化和反序列化
就是内存里的一棵树如何变成字符串形式,又如何从字符串形式变成内存里的树。
由内存变成字符串为序列化, 由字符串还原出原来的内存结构为反序列化。
解决方法:
序列化:
遍历二叉树(可以使用先序,中序,后序,按层遍历)这里以先序遍历为例:
用节点的值代表该节点,用下划线代表该节点结束,用特殊字符#代表null。下面两个二叉树变为字符串为:
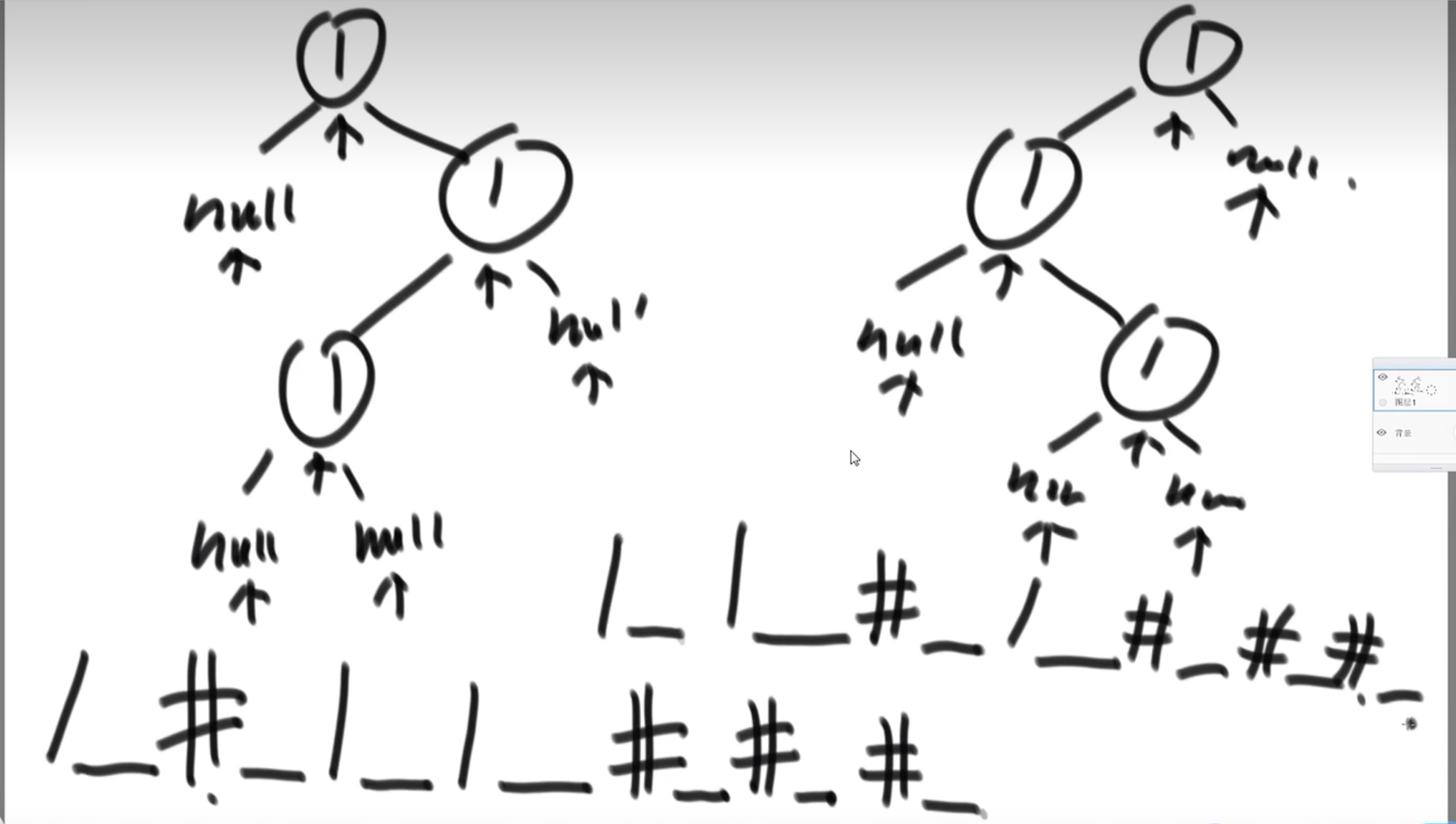
反序列化:
将序列化后的字符串中用 _ 分开存放在数组中。

按个遍历这些分割后的字符串。根据先序遍历的方式,先建立头节点,再建立左子树,再建立右子树。
如何判断一颗二叉树是不是另一棵二叉树的子树?
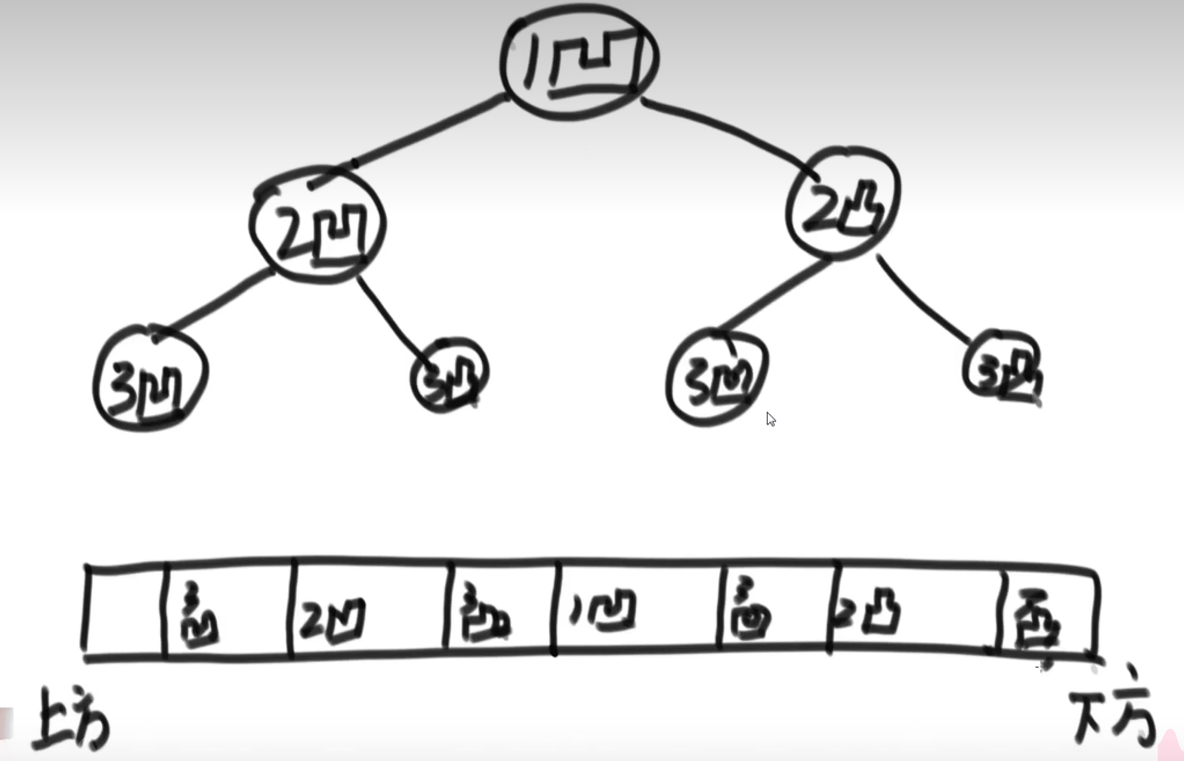
7、折纸问题
请把一段纸条竖着放在桌子上,然后从纸条的下边向上方对折1次,压出折痕后展开。
此时折痕是凹下去的,即折痕突起的方向指向纸条的背面。
如果从纸条的下边向上方连续对折2次,压出折痕后展开,此时有三条折痕,从上到下依次是下折痕、下折痕和上折痕。
给定一个输入参数N,代表纸条都从下边向上方连续对折N次。
请从上到下打印所有折痕的方向。
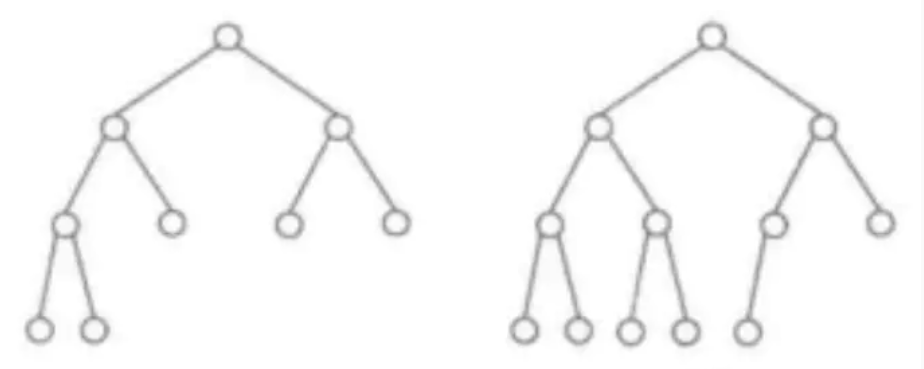
例如:N=1时,打印: down N=2时,打印: down down up
解决方法:可以用一颗树来展示折痕,如下图所示,因此展示所有折痕的方式,相当于这棵二叉树的中序遍历。这个二叉树的每个左孩子都是凹的,右孩子都是凸的。