Elasticsearch 是目前大数据领域最热门的技术栈之一,腾讯云 Elasticsearch Service(ES)是基于开源搜索引擎 Elasticsearch 打造的高可用、可伸缩的云端全托管 Elasticsearch 服务,完善的高可用解决方案,让业务可以放心的把重要数据存储到腾讯云 ES 中。
了解 ES 的索引管理方法有助于扬长避短,更好的利用 ES 的强大功能,特别是当遇到性能问题时,原因通常都可回溯至数据的索引方式以及集群中的分片数量。如果未能在一开始做出最佳选择,随着数据量越来越大,便有可能会引发性能问题。集群中的数据越多,要纠正这一问题就越难,本文旨在帮助大家了解 ES 容量管理的方法,在一开始就管理好索引的容量,避免给后面留坑。
1. 为什么要做索引容量管理
- 在生产环境使用 ES 要面对的第一个问题通常是索引容量的规划,不合理的分片数,副本数和分片大小会对索引的性能产生直接的影响;
- Elasticsearch 中的每个索引都由一个或多个分片组成的,每个分片都是一个 Lucene 索引实例,您可以将其视作一个独立的搜索引擎,它能够对 Elasticsearch 集群中的数据子集进行索引并处理相关查询;
- 查询和写入的性能与索引的大小是正相关的,所以要保证高性能,一定要限制索引的大小,具体来说是限制分片数量和单个分片的大小;
- 关于分片数量,索引大小的问题这里不再赘述,可以参考 ES 官方 blog 《我在 Elasticsearch 集群内应该设置多少个分片?》;
- 直接说结论:ES 官方推荐分片的大小是 20G - 40G,最大不能超过 50G。
本文介绍 3 种管理索引容量的方法,从这 3 种方法可以了解到 ES 管理索引容量的演进过程:
2. 方法 1: 使用在索引名称上带上时间的方法管理索引
2.1 创建索引
索引名上带日期的写法:
<static_name{date_math_expr{date_format|time_zone}}>日期格式就是 java 的日期格式:
yyyy:年
MM:月
dd:日
hh:1~12小时制(1-12)
HH:24小时制(0-23)
mm:分
ss:秒
S:毫秒
E:星期几
D:一年中的第几天
F:一月中的第几个星期(会把这个月总共过的天数除以7)
w:一年中的第几个星期
W:一月中的第几星期(会根据实际情况来算)
a:上下午标识
k:和HH差不多,表示一天24小时制(1-24)。
K:和hh差不多,表示一天12小时制(0-11)。
z:表示时区
参考官方文档:Date math support in index names。
例如:
<logs-{now{yyyyMMddHH|+08:00}}-000001>在使用的时候,索引名要 urlencode 后再使用:
PUT /%3Cmylogs-%7Bnow%7ByyyyMMddHH%7C%2B08%3A00%7D%7D-000001%3E
{
"aliases": {
"mylogs-read-alias": {}
}
}执行结果:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "mylogs-2020061518-000001"
}
2.2 写入数据
写入数据的时候也要带上日期:
POST /%3Cmylogs-%7Bnow%7ByyyyMMddHH%7C%2B08%3A00%7D%7D-000001%3E/_doc
{"name":"xxx"}
执行结果:
{
"_index" : "mylogs-2020061518-000001",
"_type" : "_doc",
"_id" : "VNZut3IBgpLCCHbxDzDB",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
2.3 查询数据
由于数据分布在多个索引里,查询的时候要在符合条件的所有索引查询,可以使用下面的方法查询。
2.3.1 使用逗号分割指定多个索引
GET /mylogs-2020061518-000001,mylogs-2020061519-000001/_search
{"query":{"match_all":{}}}
2.3.2 使用通配符查询
GET /mylogs-*/_search
{
"query": {
"match_all": {}
}
}
执行结果:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "mylogs-2020061518-000001",
"_type" : "_doc",
"_id" : "VNZut3IBgpLCCHbxDzDB",
"_score" : 1.0,
"_source" : {
"name" : "xxx"
}
}
]
}
}
2.3.3 使用别名查询
GET /mylogs-read-alias/_search
{
"query": {
"match_all": {}
}
}
执行结果同上。
2.4 使用带日期的索引名称的缺陷
这个方法的优点是比较直观能够通过索引名称直接分辨出数据的新旧,缺点是:
- 不是所有数据都适合使用时间分割,对于写入之后还有修改的数据不适合;
- 直接使用时间分割也可能存在某段时间数据量集中,导致索引分片超过设计容量的问题,从而影响性能;
- 为了解决上述问题还需要配合 rollover 策略使用,索引的维护比较复杂。
3. 方法 2: 使用 Rollover 管理索引
Rollover 的原理是使用一个别名指向真正的索引,当指向的索引满足一定条件(文档数或时间或索引大小)更新实际指向的索引。
3.1 创建索引并且设置别名
注意: 索引名称的格式为 {.*}-d 这种格式的,数字默认是 6 位:
PUT myro-000001
{
"aliases": {
"myro_write_alias":{}
}
}
3.2 通过别名写数据
使用 bulk 一次写入了 3 条记录:
POST /myro_write_alias/_bulk?refresh=true
{"create":{}}
{"name":"xxx"}
{"create":{}}
{"name":"xxx"}
{"create":{}}
{"name":"xxx"}
执行结果:
{
"took" : 37,
"errors" : false,
"items" : [
{
"create" : {
"_index" : "myro-000001",
"_type" : "_doc",
"_id" : "wVvFtnIBUTVfQxRWwXyM",
"_version" : 1,
"result" : "created",
"forced_refresh" : true,
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1,
"status" : 201
}
},
{
"create" : {
"_index" : "myro-000001",
"_type" : "_doc",
"_id" : "wlvFtnIBUTVfQxRWwXyM",
"_version" : 1,
"result" : "created",
"forced_refresh" : true,
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1,
"status" : 201
}
},
{
"create" : {
"_index" : "myro-000001",
"_type" : "_doc",
"_id" : "w1vFtnIBUTVfQxRWwXyM",
"_version" : 1,
"result" : "created",
"forced_refresh" : true,
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1,
"status" : 201
}
}
]
}
记录都写到了 myro-000001 索引下。
3.3 执行 rollover 操作
rollover 的 3 个条件是并列关系,任意一个条件满足就会发生 rollover:
POST /myro_write_alias/_rollover
{
"conditions": {
"max_age": "7d",
"max_docs": 3,
"max_size": "5gb"
}
}
执行结果:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"old_index" : "myro-000001",
"new_index" : "myro-000002",
"rolled_over" : true,
"dry_run" : false,
"conditions" : {
"[max_docs: 3]" : true,
"[max_size: 5gb]" : false,
"[max_age: 7d]" : false
}
}
分析一下执行结果:
"new_index" : "myro-000002"
"[max_docs: 3]" : true,
从结果看出满足了条件("[max_docs: 3]" : true)发生了 rollover,新的索引指向了 myro-000002。
再写入一条记录:
POST /myro_write_alias/_doc
{"name":"xxx"}
已经写入了新的索引,结果符合预期:
{
"_index" : "myro-000002",
"_type" : "_doc",
"_id" : "BdbMtnIBgpLCCHbxhihi",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
3.4 使用 Rollover 的缺点
- 必须明确执行了 rollover 指令才会更新 rollover 的别名对应的索引;
- 通常可以在写入数据之后 再执行一下 rollover 命令,或者采用配置系统 cron 脚本的方式;
- 增加了使用的 rollover 的成本,对于开发者来说不够自动化。
4. 方法 3: 使用 ILM(Index Lifecycle Management ) 管理索引
ES 一直在索引管理这块进行优化迭代,从 6.7 版本推出了索引生命周期管理(Index Lifecycle Management ,简称 ILM)机制,是目前官方提供的比较完善的索引管理方法。所谓 Lifecycle(生命周期)是把索引定义了四个阶段:

- Hot:索引可写入,也可查询,也就是我们通常说的热数据,为保证性能数据通常都是在内存中的;
- Warm:索引不可写入,但可查询,介于热和冷之间,数据可以是全内存的,也可以是在 SSD 的硬盘上的;
- Cold:索引不可写入,但很少被查询,查询的慢点也可接受,基本不再使用的数据,数据通常在大容量的磁盘上;
- Delete:索引可被安全的删除。
这 4 个阶段是 ES 定义的一个索引从生到死的过程, Hot -> Warm -> Cold -> Delete 4 个阶段只有 Hot 阶段是必须的,其他 3 个阶段根据业务的需求可选。
使用方法通常是下面几个步骤:
4.1 建立 Lifecycle 策略
这一步通常在 Kibana 上操作,需要的时候再导出 ES 语句,例如下面这个策略:
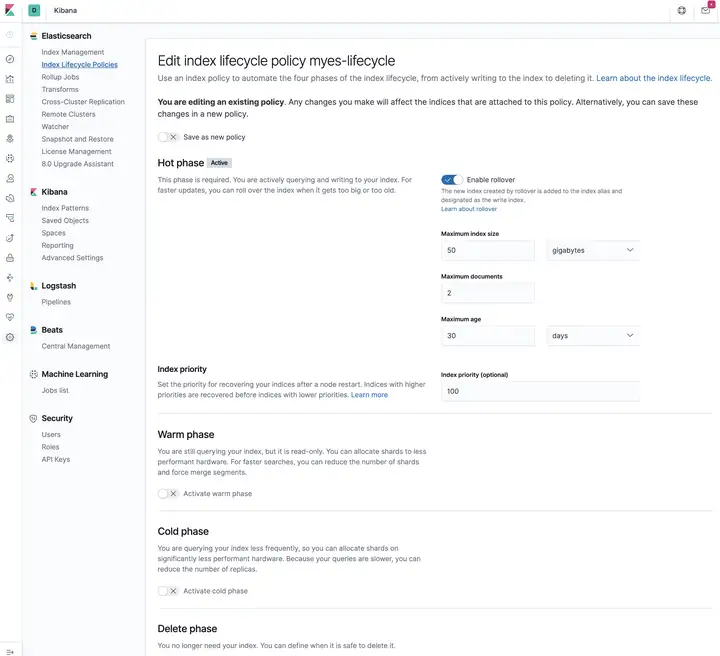
- 暂时只配置了 Hot 阶段;
- 为了方便验证,最大文档数(max_docs) 超过 2 个时就 rollover。
导出的语句如下:
PUT _ilm/policy/myes-lifecycle
{
"policy": {
"phases": {
"hot": {
"min_age": "0ms",
"actions": {
"rollover": {
"max_age": "30d",
"max_size": "50gb",
"max_docs": 2
},
"set_priority": {
"priority": 100
}
}
}
}
}
}
4.2 建立索引模版
ES 语句如下:
PUT /_template/myes_template
{
"index_patterns": [
"myes-*"
],
"aliases": {
"myes_reade_alias": {}
},
"settings": {
"index": {
"lifecycle": {
"name": "myes-lifecycle",
"rollover_alias": "myes_write_alias"
},
"refresh_interval": "30s",
"number_of_shards": "12",
"number_of_replicas": "1"
}
},
"mappings": {
"properties": {
"name": {
"type": "keyword"
}
}
}
}
:warning:注意:
- 模版匹配以索引名称 myes- 开头的索引;
- 所有使用此模版创建的索引都有一个别名 myes_reade_alias 用于方便查询数据;
- 模版绑定了上面创建的 Lifecycle 策略,并且用于 rollover 的别名是 myes_write_alias。
4.3 创建索引
ES 语句:
PUT /myes-testindex-000001
{
"aliases": {
"myes_write_alias":{}
}
}
:warning:注意:
- 索引的名称是 .*-d 的形式;
- 索引的别名用于 lifecycle 做 rollover。
4.4 查看索引配置
GET /myes-testindex-000001
{}
执行结果:
{
"myes-testindex-000001" : {
"aliases" : {
"myes_reade_alias" : { },
"myes_write_alias" : { }
},
"mappings" : {
"dynamic_templates" : [
{
"message_full" : {
"match" : "message_full",
"mapping" : {
"fields" : {
"keyword" : {
"ignore_above" : 2048,
"type" : "keyword"
}
},
"type" : "text"
}
}
},
{
"message" : {
"match" : "message",
"mapping" : {
"type" : "text"
}
}
},
{
"strings" : {
"match_mapping_type" : "string",
"mapping" : {
"type" : "keyword"
}
}
}
],
"properties" : {
"name" : {
"type" : "keyword"
}
}
},
"settings" : {
"index" : {
"lifecycle" : {
"name" : "myes-lifecycle",
"rollover_alias" : "myes_write_alias"
},
"refresh_interval" : "30s",
"number_of_shards" : "12",
"translog" : {
"sync_interval" : "5s",
"durability" : "async"
},
"provided_name" : "myes-testindex-000001",
"max_result_window" : "65536",
"creation_date" : "1592222799955",
"unassigned" : {
"node_left" : {
"delayed_timeout" : "5m"
}
},
"priority" : "100",
"number_of_replicas" : "1",
"uuid" : "tPwDbkuvRjKtRHiL4fKcPA",
"version" : {
"created" : "7050199"
}
}
}
}
}
:warning:注意:
- 索引使用了之前建立的索引模版;
- 索引绑定了 lifecycle 策略并且写入别名是 myes_write_alias。
4.5 写入数据
POST /myes_write_alias/_bulk?refresh=true
{"create":{}}
{"name":"xxx"}
{"create":{}}
{"name":"xxx"}
{"create":{}}
{"name":"xxx"}
执行结果:
{
"took" : 18,
"errors" : false,
"items" : [
{
"create" : {
"_index" : "myes-testindex-000001",
"_type" : "_doc",
"_id" : "jF3it3IBUTVfQxRW1Xys",
"_version" : 1,
"result" : "created",
"forced_refresh" : true,
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1,
"status" : 201
}
},
{
"create" : {
"_index" : "myes-testindex-000001",
"_type" : "_doc",
"_id" : "jV3it3IBUTVfQxRW1Xys",
"_version" : 1,
"result" : "created",
"forced_refresh" : true,
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1,
"status" : 201
}
},
{
"create" : {
"_index" : "myes-testindex-000001",
"_type" : "_doc",
"_id" : "jl3it3IBUTVfQxRW1Xys",
"_version" : 1,
"result" : "created",
"forced_refresh" : true,
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1,
"status" : 201
}
}
]
}
:warning:注意:
- 3 条记录都写到了 myes-testindex-000001 中, Lifecycle 策略明明设置的是 2 条记录就 rollover 为什么会三条都写到同一个索引了呢?
再次执行上面的语句,写入 3 条记录发现新的数据都写到了 myes-testindex-000002 中, 结果符合预期。
{
"took" : 17,
"errors" : false,
"items" : [
{
"create" : {
"_index" : "myes-testindex-000002",
"_type" : "_doc",
"_id" : "yl0JuHIBUTVfQxRWvsv5",
"_version" : 1,
"result" : "created",
"forced_refresh" : true,
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1,
"status" : 201
}
},
{
"create" : {
"_index" : "myes-testindex-000002",
"_type" : "_doc",
"_id" : "y10JuHIBUTVfQxRWvsv5",
"_version" : 1,
"result" : "created",
"forced_refresh" : true,
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1,
"status" : 201
}
},
{
"create" : {
"_index" : "myes-testindex-000002",
"_type" : "_doc",
"_id" : "zF0JuHIBUTVfQxRWvsv5",
"_version" : 1,
"result" : "created",
"forced_refresh" : true,
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1,
"status" : 201
}
}
]
}
:warning:注意: 如果按照这个步骤没有发生自动 rollover 数据仍然写到了 myes-testindex-000001 中,需要 配置 Lifecycle 自动 Rollover 的时间间隔, 参考下文。
4.6 配置 Lifecycle 自动 Rollover 的时间间隔
- 由于 ES 是一个准实时系统,很多操作都不能实时生效;
- Lifecycle 的 rollover 之所以不用每次手动执行 rollover 操作是因为 ES 会隔一段时间判断一次索引是否满足 rollover 的条件;
- ES 检测 ILM 策略的时间默认为 10min。
修改 Lifecycle 配置:
PUT _cluster/settings
{
"transient": {
"indices.lifecycle.poll_interval": "3s"
}
}
5. ES 在 QQ 家校群作业统计功能上的实践
疫情期间线上教学需求爆发,QQ 的家校群功能也迎来了一批发展红利,家校群的作业功能可以轻松在 QQ 群里实现作业布置,提交,批改等功能,深受师生们的喜爱。
5.1 使用场景简介
近期推出的作业统计功能,可以指定时间段+指定科目动态给出排名,有效提高了学生答题的积极性。在功能的实现上如果用传统的 SQL + KV 的方式实现成本比较高,要做到高性能也需要花不少精力,借助 ES 强大的统计聚合能力大大降低了开发成本,实现了需求的快速上线。
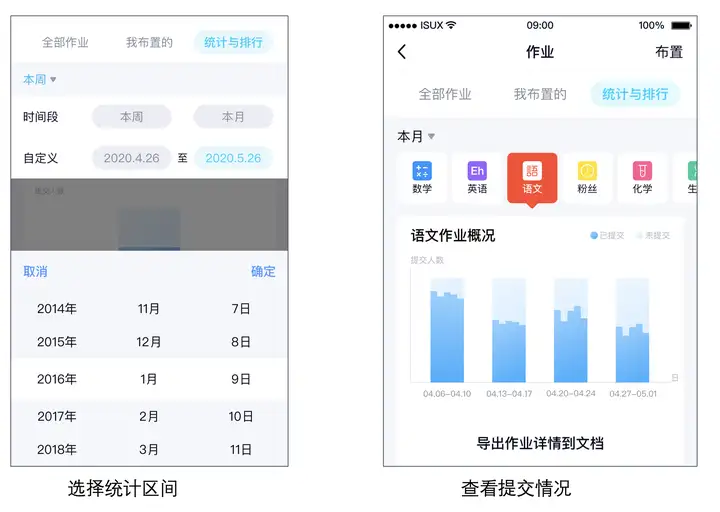
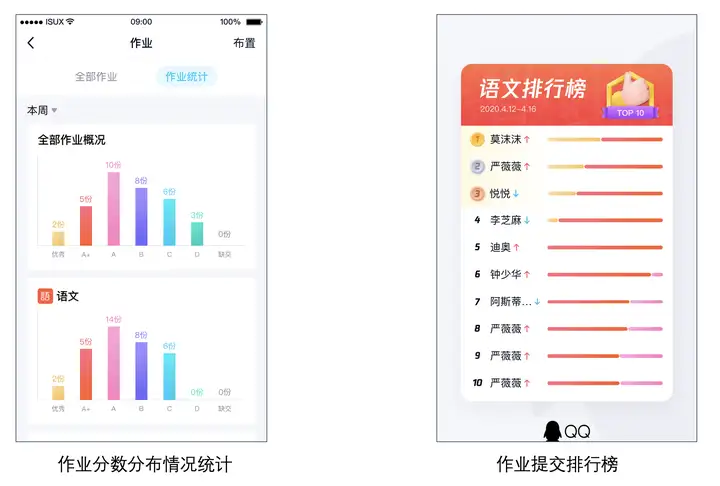
5.2 申请资源
- ES 版本: 7.5.1
- 高级特性:腾讯云 ES 白金版
- 单节点容量: 1000GB
- 节点数: 3
- 总容量:3000GB
5.3 索引使用方案
- 按群尾号 % 100 把数据分为 100 个索引
- 每个索引 12 个分片
- 每 40000W(120GB)发生一次 Rollover
- 单个分片最大大小 10GB
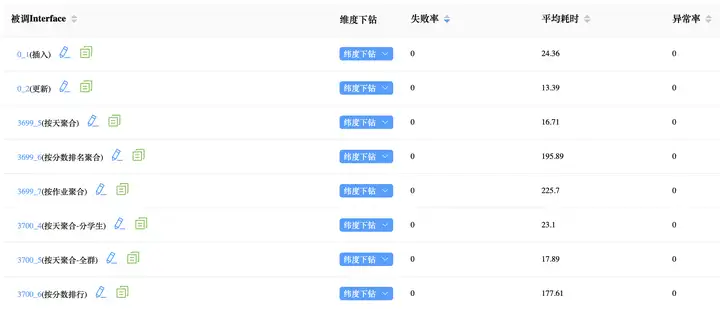
5.4 实际耗时情况
- 插入:~ 25ms
- 更新:~ 15ms
- 聚合:200ms 以内
参考链接
- 我在 Elasticsearch 集群内应该设置多少个分片?
- Elasticsearch rollover index 滚动索引
- 使用索引生命周期管理实现热温冷架构
- Index lifecycle management settings in Elasticsearchedit