前言
webpack 作为目前主流的前端构建工具,我们几乎每天都需要与它打交道。个人认为一个好的开源产品壮大的原因应该包括核心开发者的稳定输出以及对应生态的繁荣。对于生态来说, webpack 是一个足够开放的类库,提供了可插拔的方式去自定义一些配置,包括配置 loader 和 plugin ,本篇我们主要讨论loader。
loader 本质上是一个函数,webpack在打包过程中会按照规则顺序调用处理某种文件的 loader ,然后将上一个 loader 产生的结果或者资源文件传入进去,当前 loader 处理完成后再交给下一个 loader 。
loader的类型
开始之前,还是要先大概提一下 loader 的类型以及一些常用的 api ,不感兴趣的同学可以直接跳过这一小节,更详细的指引请参阅官方文档。
loader 主要有以下几种类型:
- 同步
loader:return或调用this.callback都是同步返回值 - 异步
loader:是用this.async()获取异步函数,是用this.callback()返回值 raw loader:默认情况下接受utf-8类型的字符串作为入参,若标记raw属性为true,则入参的类型为二进制数据pitch loader:loader总是从右到左被调用。有些情况下,loader只关心 request 后面的 元数据(metadata),并且忽略前一个loader的结果。在实际(从右到左)执行loader之前,会先从左到右调用loader上的pitch方法。
开发 loader 时常用的 API 如下:
this.async:获取一个callback函数,处理异步this.callback:同步loader中,返回的方法this.emitFile:产生一个文件this.getOptions:根据传入的schema获取对应参数this.importModule:用于子编译器在构建时编译和执行请求this.resourcePath:当前资源文件的路径
Hello Loader
现在假设我们有这么一个需求:在每个文件的头部打上开发者的相关信息。比如打包之前的文件内容是这样的:
const name = 'jay'
打包之后文件内容可能是这样的:
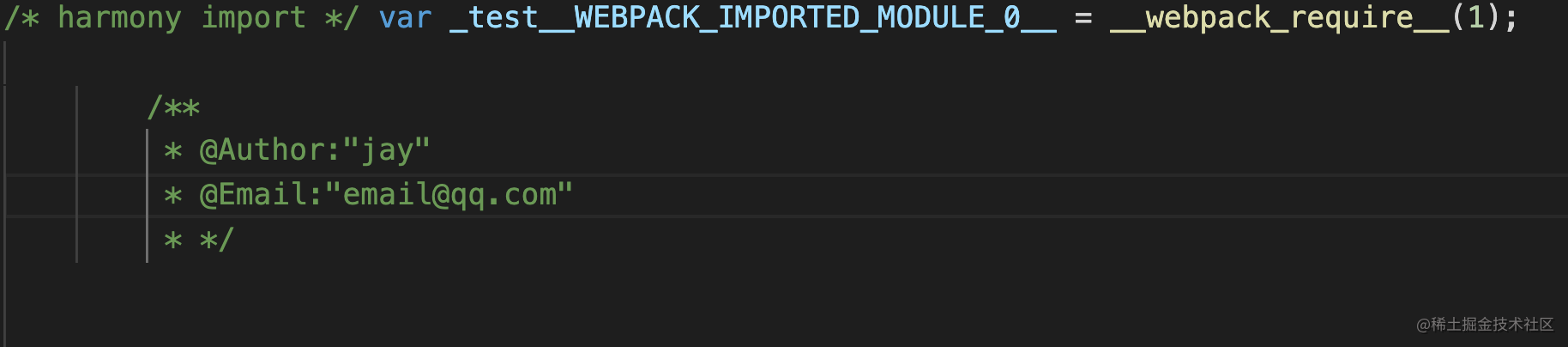
/** * @Author:jay * @Email:email@qq.com * /const name = 'jay'
那废话不多说,直接开整。首先把相关依赖安装一下:
//package.json
"webpack": "^5.0.0",
"webpack-cli": "^4.10.0",
"webpack-dev-server": "^4.10.0"
再简单的配置一下webpack:
const HtmlWebpackPlugin = require('html-webpack-plugin')
const { resolve } = require('path')
module.exports = {
mode: 'none',
entry: './src/main.js',
output: {
path: resolve(__dirname, './dist'),
filename: 'js/[name].js',
clean: true
},
module: {
rules: [
{
test: /\.js$/,
loader: './loaders/hello-loader',
},
]
},
plugins: [
new HtmlWebpackPlugin({
template: './public/index.html'
})
]
}
接下来就可以开始实现这个 loader 了,首先每一个 loader 都是一个函数,这个函数的返回结果要么是二进制数据要么是字符串,字符串就是文件的具体内容,二进制数据就是资源文件比如图片的内容。在上面这个需求中,显然我们只需要拿到文件的内容,做一些修改替换即可。所以可以比较容易的写出下面的代码:
module.exports = function (content) {
const newContent = ` /** * @Author:jay * @Email:email@qq.com * */ ${content}
`
return newContent;
}
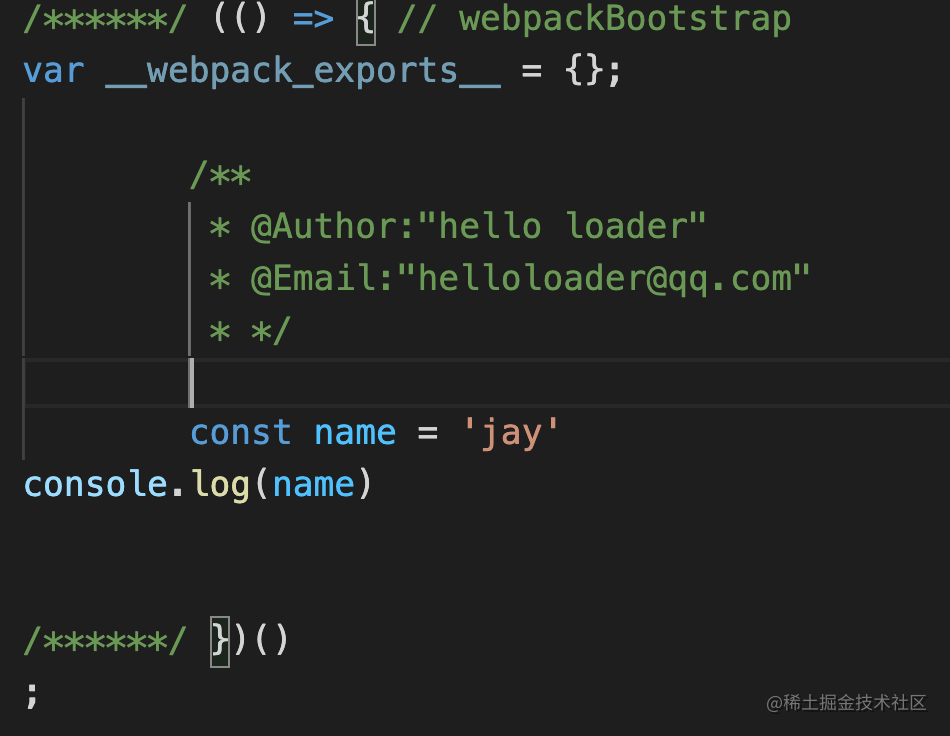
这样就会将对应的内容添加到打包结果中,如下图所示:
获取参数
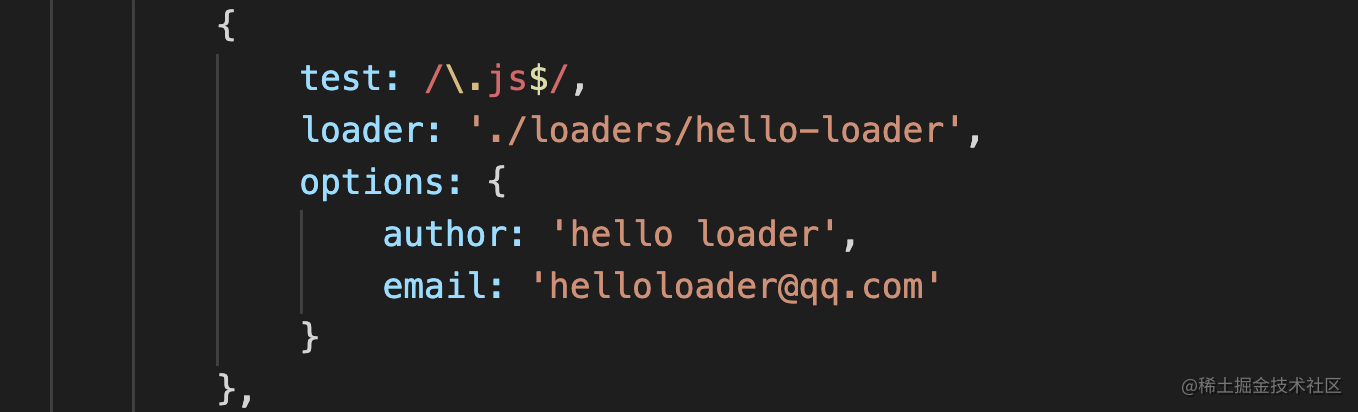
上面对于文件的一些描述我们是已经写死了,但这样不太灵活,大多数时候是希望能通过 loader 对应的配置去获取对应的参数,我们可以在引入 loader 的时候这样改造一下:
{
test: /\.js$/,
loader: './loaders/hello-loader',
options: {
author: 'hello loader',
email: 'helloloader@qq.com'
}
}
那么在具体的loader中,可以使用 this.getOptions(schema) 去获取传入的配置。这个 schema 是对 option 的格式校验,代码改造如下:
参考webpack视频讲解:进入学习
const schema = {
type: 'object', //options是一个对象
properties: {
//author是一个字符串
author: {
type: 'string'
},
//email是一个字符串
email: {
type: 'string'
}
}
}
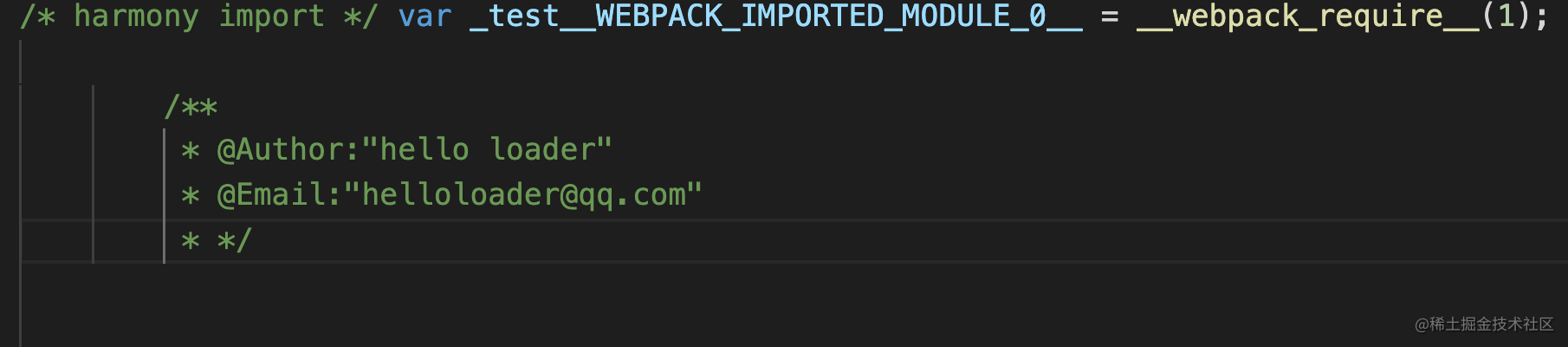
const options = this.getOptions(schema) || {}
const { author = 'null', email = 'null' } = options
const newContent = ` /** * @Author:"${author}" * @Email:"${email}" * */ ${content}
`
这样就可以将用户自定义的参数传给处理的 loader ,对于一些需要提供可拓展能力的 loader 来说,获取参数这一步是必不可少的。webpack配置如下,即可使用loader获取参数的能力。
异步回调
这时候有了一个新需求,希望我们把当前处理的文件内容信息与文件名通过网络传输,以便后续做一些分析。那为了方便我们还是在上面的 loader 进行拓展,实际开发中最好不要这样做,要保证 loader 的单一职责。这时候就不能直接返回结果,而是要获取一个异步 callback 函数,使用这个函数把结果输出。代码实现如下:
const callback = this.async()
// 模拟网络请求
setTimeout(() => {
callback(null, JSON.stringify(newContent), null, {})
console.log('net done');
}, 1000)
这里留意一下 callback 函数的用法:callback(error,content,map,meta) ,其中有四个参数,分别的作用是:
error:错误信息,如果存在的话则会抛出异常,构建终止content:处理后的内容map:sourceMap相关信息meta:要传给下一个loader的额外信息参数
JS处理
上面大致举例说明了同步l loader 、异步 loader 以及如何获取 loader 的参数。在这一小结,主要实现开发过程中经常用到的三个 JS 处理相关的 loader :
eslint-loader:使用eslint做代码检测babel-loader:将ES6+语法转换为ES5语法uglify-loader:对代码进行压缩混淆
eslint-loader
首先先来实现 eslint-loader ,实现思路是对当前处理的文件调用 eslint 去扫描,如果无错误则继续正常调用下一个 loader 去处理。具体代码实现如下:
const childProcess = require('child_process')
const exec = (command, cb) => {
childProcess.exec(command, (error, stdout) => {
cb && cb(error, stdout)
})
}
const schema = {
type: 'object',
properties: {
fix: 'boolean'
}
}
module.exports = function (content) {
const resourcePath = this.resourcePath
const callback = this.async()
const command = `npx eslint ${resourcePath}`
exec(command, (error, stdout) => {
if (error) {
console.log(stdout)
}
callback(null, content)
})
}
这里需要理清的是, loader 只是调用了具体工程中的 eslint ,也就是说用到的 eslint 相关的插件以及配置文件都是具体工程提供的,与这个 loader 无关。简单在项目内的 .eslintrc.js 文件下配置了一下引号类型为单引号

打包过程如下:

配置fix
由上图可以看出, eslint 其实还支持一键修复的能力,由 fix 参数控制。实现 fix 的思路如下:
- 将文件内容写入到新文件中,对新文件进行
eslint检测并fix - 读取新文件的内容,返回
代码实现如下:
let id = 0
const schema = {
type: 'object',
properties: {
fix: {
type: 'boolean'
}
}
}
const fs = require('fs')
const path = require('path')
module.exports = function (content) {
const resourcePath = this.resourcePath
const callback = this.async()
const { fix } = this.getOptions(schema) || { fix: false }
if (fix) {
const tempName = `./${id++}.js`
const fullPath = path.resolve(__dirname, tempName)
// 写入新文件
fs.writeFileSync(fullPath, content, { encoding: 'utf8' })
// 带fix检测新文件
const command = `npx eslint ${fullPath} --fix`
exec(command, (error, stdout) => {
if (error) {
console.log(stdout)
}
// 读取新文件
const newContent = fs.readFileSync(fullPath, { encoding: 'utf8' })
fs.unlinkSync(fullPath)
callback(null, newContent)
})
} else {
// 没有选择fix则还是走旧逻辑,没必要读写文件
const command = `npx eslint ${resourcePath}`
exec(command, (error, stdout) => {
if (error) {
console.log(stdout)
}
callback(null, content)
})
}
}
这是打包前的文件,可以看到eslint也对它错误标红提示了
这是打包后的文件,可以看到配置的检测规则 eslint 已经帮我们修复
babel-loader
babel-loader 应该是绝大部份前端项目都会用到的 loader 之一了吧, ES6+ 语法转 ES5 在打包这一步是必不可少的。这里也是依赖 babel 的提供的能力, loader 充当的角色只是一个 API 调用工程师罢了~。稍微灵活一点的是,调用 babel 相关的参数可以从 loader 配置中传进来:
{
test: /\.js$/,
loader: './loaders/babel-loader',
options: {
presets: ['@babel/preset-env']
}
}
loader的具体代码实现如下:
const schema = {
"type": "object",
"properties": {
"presets": {
"type": "array"
}
}
}
const babel = require('@babel/core')
module.exports = function (content) {
const options = this.getOptions(schema);
const callback = this.async();
babel.transform(content, options, function (err, result) {
if (err) {
callback(err)
} else {
callback(null, result.code)
}
})
}
可以分别看一下打包前后的效果:
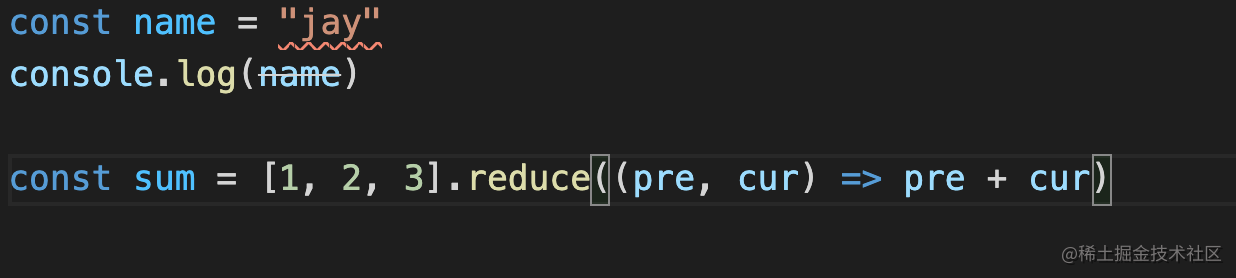
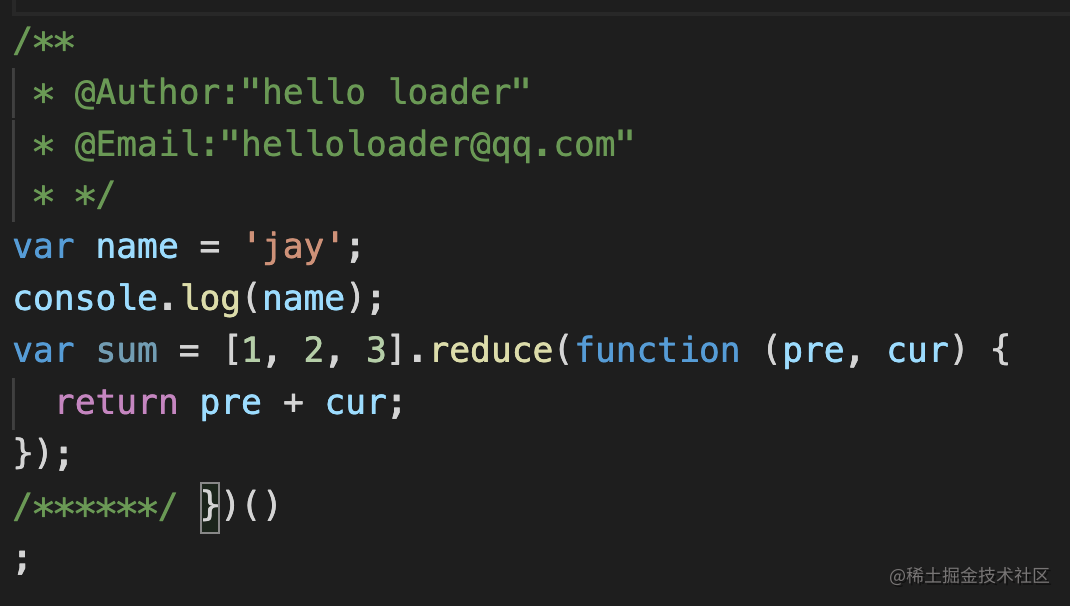
uglify-loader
最后要实现的一个是对代码进行压缩混淆的 loader ,主要是用到的是uglify-js这个十分强大的库,感兴趣的同学可以自行去了解下。我们这里的实现十分简单,只是调用了一下这个库而已。
const uglifyJS = require('uglify-js');
module.exports = function (content) {
const result = uglifyJS.minify(content)
const { error, code } = result
if (error) {
this.callback(error)
} else {
this.callback(null, code)
}
}
可以稍微看一下打包后的代码:

小结
上面我们大概了解与实现了 JS 相关的三个 loader ,这三个 loader 配合起来使用的顺序如下,默认情况下, loader 的执行顺序都是从下往上,从右往左的,注意实际情况下,一般会加一个 exclude 属性,让 loader 不去检测一些文件(比如 node_modules 目录下的文件)。
{
test: /\.js$/,
exclude:/node_modules/,
loader: './loaders/uglify-loader',
},
{
test: /\.js$/,
loader: './loaders/babel-loader',
exclude:/node_modules/,
options: {
presets: ['@babel/preset-env']
}
},
{
test: /\.js$/,
loader: './loaders/eslint-loader',
exclude:/node_modules/,
options: {
fix: true
}
}
CSS处理
处理完 JS 文件之后,我们开始处理 CSS 文件。这里会实现两个常用的 loader :css-loader 和 style-loader 。先分别介绍一下它们的作用:
- css-loader:处理
CSS文件的依赖以及资源的加载(因为webpack默认只支持JS的导入以及一些资源文件的导入,所以我们需要实现对CSS文件的导入) - style-loader:将
css-loader处理后的结果输出到文档中
在源码的实现中,使用了 postcss 去分析 CSS 文件,对 CSS 文件中的资源进行了分类处理加载。我们实现没有源码实现那么全,这里实现主要实现两个功能:
@import的实现- 图片资源的导入
其中图片资源的导入会放到下小节图片处理中介绍,所以本小结主要实现 @import、 CSS 文件的输出以及 style-loader
@import与CSS代码输出
先写下一些测试的导入代码:
//main.js
import './style/index.css'
//index.css
@import './color.css';
.container {
width: 100px;
height: 100px;
}
//color.css
@import './bg.css';
.container {
color: red;
}
//bg.css
.container {
background: url('../assets/img-168kb.jpeg');
border: 1px solid red;
}
在这里主要需要处理的应该是 @import 这个关键字,其他的内容就当字符串正常输出即可。由上图可以看出, @import 可以无限嵌套使用,实际上我们要做的就是一棵树的深度优先遍历,递归是比较浅显易懂的处理方式,可以配合注释大概看下下面的代码:
//css-loader.js
module.exports = async function (content) {
const callback = this.async()
let newContent = content
try {
newContent = await getImport(this, this.resourcePath, content)
//这里注意需要这样导出,后续webpack的打包处理会默认当成一个JS文件来处理
callback(null, `module.exports = ${JSON.stringify(newContent)}`)
} catch (error) {
callback(error, '')
}
}
// 匹配图片
const urlReg = /url\(['|"](.*)['|"]\)/g
// 匹配@import关键字
const importReg = /(@import ['"](.*)['"];?)/
const fs = require('fs')
const path = require('path')
async function getImport(context, originPath, content) {
let newContent = content
let regRes, imgRes
// 获取当前处理文件的父目录
let absolutePath = originPath.slice(0, originPath.lastIndexOf('/'))
// 如果当前文件中存在@import关键字,不断匹配处理
while (regRes = importReg.exec(newContent)) {
const importExp = regRes[1]
const url = regRes[2]
// 获取@import导入的css文件的绝对路径
const fileAbsoluteUrl = url.startsWith('.') ? path.resolve(absolutePath, url) : url
// 读取目标文件的内容
const transformResult = fs.readFileSync(fileAbsoluteUrl, { encoding: 'utf8' })
// 将@import关键字替换成读取的文件内容
newContent = newContent.replaceAll(importExp, transformResult)
// 继续递归处理
newContent = await getImport(context, fileAbsoluteUrl, newContent)
// 处理图片
while (imgRes = urlReg.exec(newContent)) {
const url = imgRes[1]
// 获取url方式引入图片的父目录
let absolutePath = fileAbsoluteUrl.slice(0, fileAbsoluteUrl.lastIndexOf('/'))
// 获取引入图片的绝对路径
const imgAbsoluteUrl = url.startsWith('.') ? path.resolve(absolutePath, url) : url
if (fs.existsSync(imgAbsoluteUrl)) {
// 调用图片相关loader处理(下一小节实现)
const transformResult = await context.importModule(imgAbsoluteUrl, {})
// 将图片loader处理完成的内容替换url
newContent = newContent.replaceAll(url, transformResult)
}
}
}
return newContent
}
总结来说,上面代码干了如下几点:
- 匹配
@import,获取绝对路径 - 读取目标文件,将读取到的文件内容替换
@import - 如果有图片,则调用相关
loader处理 - 当前文件循环处理,引用的文件递归处理,直至
CSS依赖树构建完成
可以大致看一下打包后的结果:
/***/ ((module) => {
module.exports = '.container {\n border: 1px solid red;\n background: url(\'../assets/img-168kb.jpeg\'); \n}\n.container {\n color: red;\n}\n.container {\n width: 100px;\n height: 100px;\n}\n\n'
/***/ })
style-loader
有了上面的打包结果之后,我们只需要把打包结果插入到 DOM 中,就可以实现引入样式文件的功能。大致实现如下:
let id = 0
const fs = require('fs')
const path = require('path')
module.exports = function (content) {
const temp = path.resolve(__dirname,`./${id++}.js`)
// 将css-loader生成的字符串写入文件
fs.writeFileSync(temp,content)
// 读出module.exports
const res = require(temp)
fs.unlinkSync(temp)
// 插入样式
const insertStyle = ` const style = document.createElement('style'); style.innerHTML = ${JSON.stringify(res)}; document.head.appendChild(style); `
return insertStyle
}
这里 style-loader 的实现相对简单,做了如下几件事情:
- 提取
css-loader的处理结果(这里取巧使用了读写文件的方式) - 插入样式
一起来看看样式生效了没有吧~
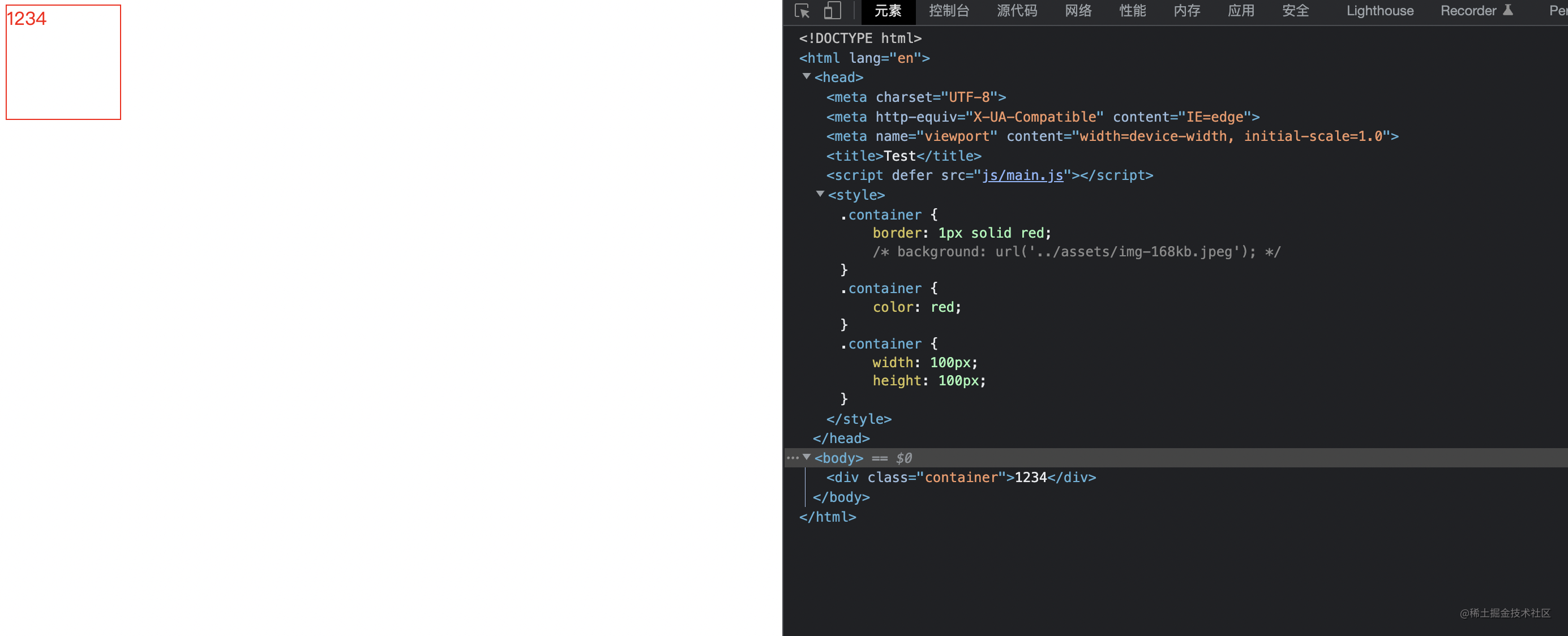
图片处理
上面我们还没有实现图片的相关 loader
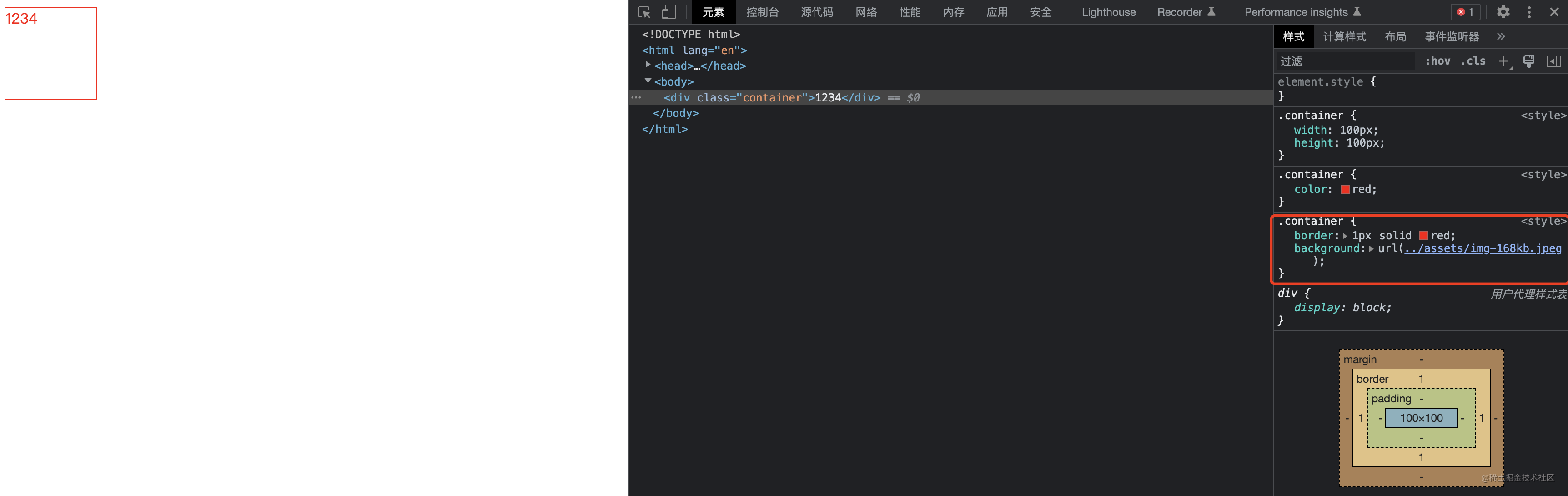
毫无疑问的这篇图片引入失败了,因为图片的路径不对。我们接下来会实现三个 loader 去处理图片,分别是:
file-loader处理图片的路径url-loader将图片转成base64image-loader压缩图片
file-loader
file-loader 是一个 raw loader ,也就是它接受的内容应该是二进制的图片数据,它要做的有两件事:
- 将图片输出到打包结果中
- 将打包结果的图片路径替换代码的路径
代码实现如下:
const loaderUtils = require('loader-utils')
module.exports = function (content, map = null, meta = {}) {
// 是否被url-loader处理过,处理过的话返回base74,url-loader在下面小结具体实现
const { url,base64 } = meta
if (url) {
return `module.exports = "${base64}"`
} else {
// 根据当前的上下文,生成一个文件路径,基于dist打包目录,这里生成的文件地址就是:dist/assets/img.jpg
const interpolateName = loaderUtils.interpolateName(
this,
'assets/[name].[contenthash].[ext][query]',
{ content }
}
// webpack特有方法,生成一个文件
this.emitFile(interpolateName, content);
return `module.exports = "${interpolateName}"`
}
}
// 添加标记,表示这是一个raw loader
module.exports.raw = true
有了 file-loader 之后,我们来看看打包结果是怎样的:


可以看到文件已经输出到 dist 目录,打包后的文件中引入文件也是正确的,可以正常显示文件了。到这里我们才算把上面说的 CSS 文件导入致实现完毕:
- 处理
@import - 处理图片
image-loader
接下来就是一些锦上添花的内容了,这里做的事情是压缩图片,用到的是images这个开源的图片处理库。可以大概看一下代码,这里没有什么特别的处理,都是上面已经提到过的内容,就不过多赘述。
const images = require('images')
const fs = require('fs')
// 根据全路径取文件后缀
const { getExtByPath } = require('../utils')
const schema = {
type: 'object',
properties: {
quality: {
type: 'number'
}
}
}
module.exports = function (content) {
const options = this.getOptions(schema) || { quality: 50 }
const { quality } = options
const ext = getExtByPath(this)
const tempname = `./temp.${ext}`
// 根据传入的压缩程度,生成一张新图片
images(content).save(tempname, { quality })
// 读取新图片的内容
const newContent = fs.readFileSync(tempname)
fs.unlinkSync(tempname)
// 返回新图片的内容
return newContent
}
module.exports.raw = true
url-loader
对于一些小图片,我们可以将它转成 base64 嵌入代码中,这样可以省去一些网络请求的时间,但是转成 base64 之后文件的大小会增大,所以要根据自身的实际情况把控好这里的阈值。
const { getExtByPath } = require('../utils')
const schema = {
type: 'object',
properties: {
limit: {
type: 'number'
}
}
}
module.exports = function (content) {
// 默认值500K
const options = this.getOptions(schema) || { limit: 1000 * 500 }
const { limit } = options
// 超过阈值则返回原内容
const size = Buffer.byteLength(content)
if (size > limit) {
return content
}
// 读取buffer
const buffer = Buffer.from(content)
const ext = getExtByPath(this)
// 将buffer转为base64字符串
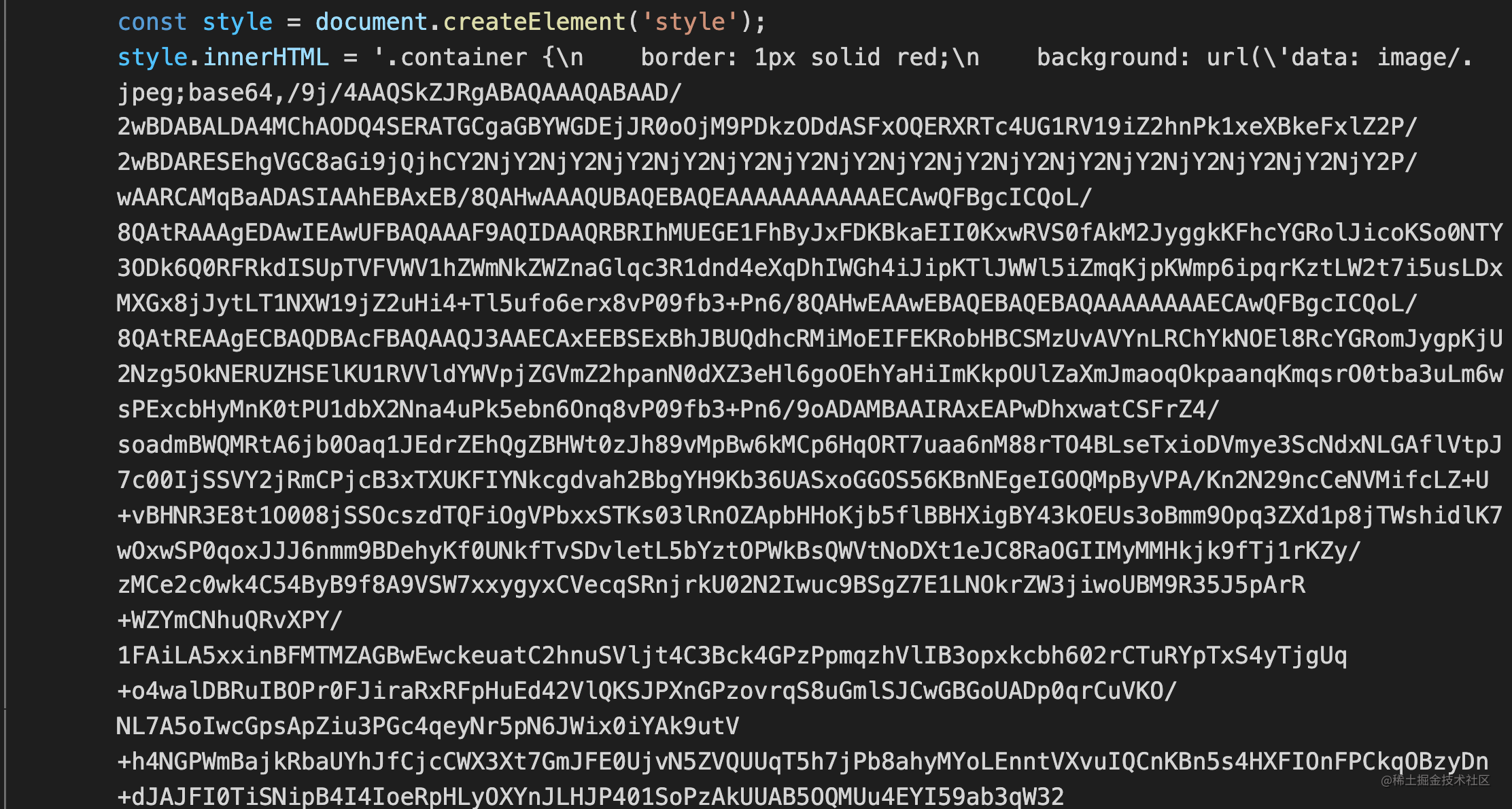
const base64 = 'data: image/' + ext + ';base64,' + buffer.toString('base64');
// 这里返回了第四个参数——meta,表示这张图片已经被url-loader处理过,上层的file-loader应该使用base64变量
this.callback(null, content, null, { url: true, base64 })
}
module.exports.raw = true
来看看打包后的结果:
小结
这三个 loader 的使用顺序一般如下:
- 先压缩图片
- 再判断是否可以转成
base64 - 最后使用
file-loader输出
{
test: /\.(png|jpe?g|gif)$/,
loader: './loaders/file-loader',
type: 'javascript/auto' //让webpack把这些资源当成js处理,不要使用内部的资源处理程序去处理
},
{
test: /\.(png|jpe?g|gif)$/,
loader: './loaders/url-loader',
type: 'javascript/auto',
options: {
limit: 1000 * 500
}
},
{
test: /\.(png|jpe?g|gif)$/,
loader: './loaders/image-loader',
type: 'javascript/auto',
options: {
quality: 50
}
}
最后
在本文中主要实现了8个平时会经常接触到的 loader ,包括 JS 的处理、 CSS 的处理、图片的处理。希望能够加深你我对 loader 的理解,在脑海中大概知道它可以做什么,或许有一天遇到问题的时候,你我可以通过这种开发 loader 的方式去解决。
最近在工作中多多少少接触到了一点开发工具的需求——类似于 babel 分析文件、 eslint 插件、 stylelint 插件编写,觉得还是挺有意思的。还有 postcss ,他可以生成 CSS 的 AST ,之后也想去了解一下。当然, loader 都写了, plugin 肯定也得整一篇。接下来应该会对这些相关的工具写一些分享的文章,感兴趣的同学可以留意一下下~