用5分钟时间学习一下谷歌公司的 MLP-Mixer 「MLP-Mixer: An all-MLP Architecture for Vision」CVPR 2021
CNN以及 attention 在视觉任务上取得非常好的性能,但是我们真的需要这么复杂的网络结构吗?MLP 这种简单的结构是否也能够取得SOTA呢? MLP-Mixer给出了答案:convolutions and attention are both sufficient for good performance, neither of them are necessary.
之所以叫Mixer,是因为卷积其实就是相当于mix不同维度的特征。比如说:depth-wise conv相当于在空间位置上的 mix,而 point-wise conv 相当于是在通道上的 mix。
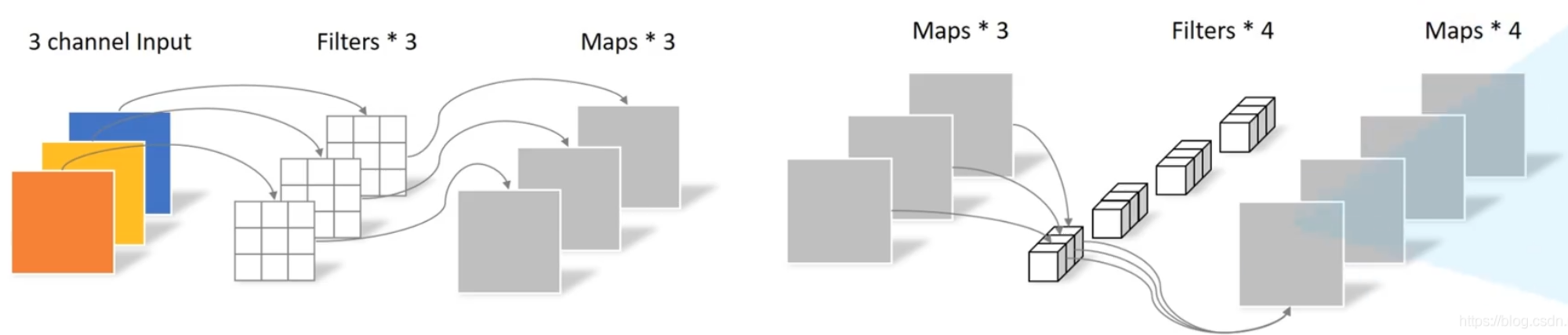
MLP-Mixer将上图所示的这两个任务切割开来,用两个MLP网络来处理,分别为(1)不同位置的mix叫做token-mixing (2)同一位置不同通道的mix叫做channel-mixing。
总体架构如下图所示,如图举例:将图片拆分为9个patch,用一个FC层将所有patch提取特征变为 token,经过 N 个Mixer层,进一步提取特征,最后用一个 FC 层预测类别。结构比较简单,需要进一步介绍的只有 Mixer Layer。

Mixer Layer 的结构如下图所示,一个图片被为成9个 patch,然后经过全连接层,每个 patch 被成了一个 4 维的向量,这样原图像就变成了一个 9X4 的矩阵,后续分为两步:
- 第一步:进行 LayerNorm,在4这个维度上归一化。接着矩阵转置变成 4X9,然后在9这个维度进行MLP处理(token-mixing),输出仍是4X9的矩阵。(中间有 skip connection)
- 第二步:矩阵转置为 9X4,再进行LayerNorm。接着在 4 这个维度进行MLP处理。(中间有skip connection)
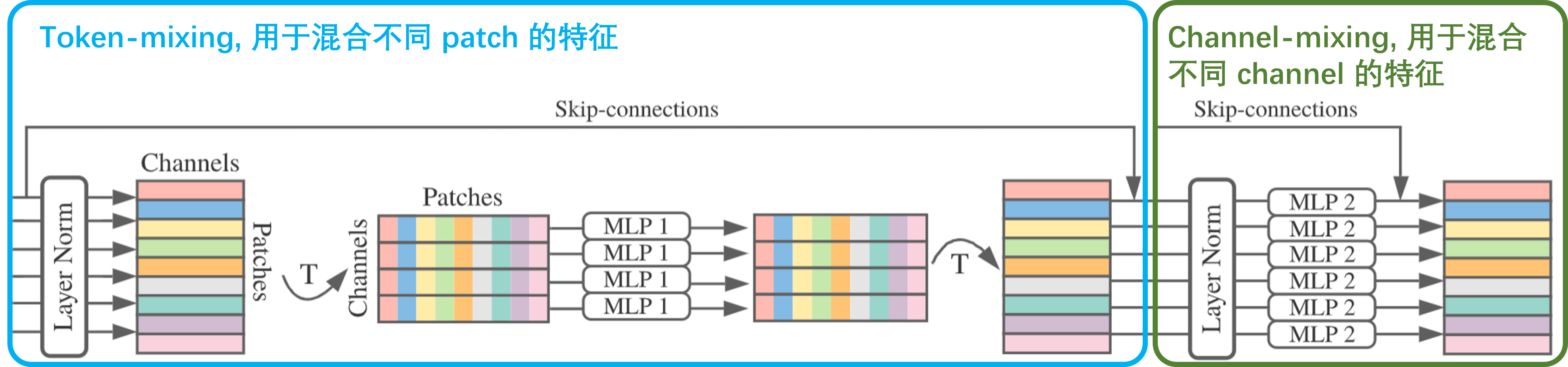
需要注意的是,MLP是两个全连接层,中间以 GELU 作为激活函数,代码如下:
def FeedForward(dim, expansion_factor = 4, dropout = 0., dense = nn.Linear):
return nn.Sequential(
dense(dim, dim * expansion_factor),
nn.GELU(),
nn.Dropout(dropout),
dense(dim * expansion_factor, dim),
nn.Dropout(dropout)
)