目录
- metrics aggregations(度量聚合)
metrics aggregations(度量聚合)
该系列中的聚合基于以某种方式从被聚合的文档中提取的值来计算度量。 这些值通常从文档的字段中提取(使用字段数据),但也可以使用脚本生成。
数字度量聚合是一种特殊类型的度量聚合,它输出数值。 一些聚合输出单个数字度量(例如 avg),称为single-value numeric metrics aggregation(单值数字度量聚合),其他聚合生成多个度量(例如 stats),称为multi-value numeric metrics aggregation(多值数字度量聚合)。 当单值和多值数字度量聚合作为某些桶聚合的直接子聚合时,这些聚合之间的区别就很重要(某些桶聚合使你能够根据每个桶中的数字度量对返回的桶进行排序)。
avg(平均聚合)
single-value(单值)度量聚合,计算从聚合文档中提取的数值的平均值。 这些值可以从文档中指定的 numeric 字段中提取,也可以由给定的脚本生成。
假设数据由代表学生考试成绩(0 到 100 之间)的文档组成,我们可以用以下公式计算他们的平均分数:
POST /exams/_search?size=0
{
"aggs" : {
"avg_grade" : { "avg" : { "field" : "grade" } }
}
}
上面这个聚合计算所有文档的平均分数。 聚合类型为 avg,field 设置定义了计算平均值所依据的文档的 numeric 字段。 上面的查询请求将返回以下内容:
{
...
"aggregations": {
"avg_grade": {
"value": 75.0
}
}
}
聚合的名称(上例中用的是avg_grade)也用作 key,通过该 key 可以从返回的响应中检索聚合结果。
脚本(script)
基于脚本计算平均分数:
POST /exams/_search?size=0
{
"aggs" : {
"avg_grade" : {
"avg" : {
"script" : {
"source" : "doc.grade.value"
}
}
}
}
}
这将把 script 参数解释为一个inline(内联)脚本,使用painless(无痛) 脚本语言,没有脚本参数。 要使用已存储的脚本,请使用以下语法:
POST /exams/_search?size=0
{
"aggs" : {
"avg_grade" : {
"avg" : {
"script" : {
"id": "my_script",
"params": {
"field": "grade"
}
}
}
}
}
}
值脚本(value script)
事实证明,这次考试远远超出了学生的水平,需要进行分数修正。 我们可以使用值脚本来获得新的平均值:
POST /exams/_search?size=0
{
"aggs" : {
"avg_corrected_grade" : {
"avg" : {
"field" : "grade",
"script" : {
"lang": "painless",
"source": "_value * params.correction",
"params" : {
"correction" : 1.2
}
}
}
}
}
}
缺失的值(missing value)
参数 missing 定义应该如何处理有缺失的值的文档。 默认情况下,它们将被忽略,但也可以将它们视为有(一个默认)值。
POST /exams/_search?size=0
{
"aggs" : {
"grade_avg" : {
"avg" : {
"field" : "grade",
"missing": 10
}
}
}
}
grade字段中没有值的文档将与值为10的文档属于同一个桶。
weighted_avg(加权平均聚合)
single-value(单值)度量聚合,计算从聚合文档中提取的数值的加权平均值。 这些值可以从文档中指定的 numeric 字段中提取。
计算常规平均值时,每个数据点都有相同的“权重(weight)”…它对最终的值的贡献是相同的。 加权平均值就不同了,它会对每个数据点进行不同的加权。 每个数据点对最终的值的贡献量是从文档中提取的,或者由脚本提供。
加权平均值公式是 ∑(value * weight) / ∑(weight)
常规平均值也可视为加权平均值,只是每个值的隐含权重为1。
表 3. weighted_avg 参数
| 参数名称 | 描述 | 要求 | 默认值 |
|---|---|---|---|
value |
提供值的字段或脚本的配置 | 必需 | |
weight |
提供权重的字段或脚本的配置 | 必需 | |
format |
数值响应格式化程序 | 可选 | |
value_type |
关于纯脚本或未映射字段的值的提示 | 可选 | |
value 和 weight 对象每个字段可有特定的配置: |
|||
| 表 4. value 参数 |
| 参数名称 | 描述 | 要求 | 默认值 |
|---|---|---|---|
field |
要从其中提取值的字段 | 必需 | |
missing |
字段完全缺失时使用的值 | 可选 | |
| 表 5. weight 参数 |
| 参数名称 | 描述 | 要求 | 默认值 |
|---|---|---|---|
field |
要从其中提取权重的字段 | 必需 | |
missing |
字段完全缺失时使用的权重值 | 可选 |
例子
如果我们的文档有一个保存 0-100 数值分数的 "grade" 字段和一个保存任意数值权重的 "weight" 字段,我们可以使用以下公式计算加权平均值:
POST /exams/_search
{
"size": 0,
"aggs" : {
"weighted_grade": {
"weighted_avg": {
"value": {
"field": "grade"
},
"weight": {
"field": "weight"
}
}
}
}
}
这将产生如下响应:
{
...
"aggregations": {
"weighted_grade": {
"value": 70.0
}
}
}
虽然每个字段允许多个值((multiple values-per-field),但只允许一个权重。 如果聚合遇到具有多个权重的文档(例如,权重字段是多值字段(multi-value field)),将抛出异常。 如果遇到这种情况,需要为权重字段指定一个 script ,并使用该脚本将多个值组合成一个要使用的值。
这个权重将独立应用于从 value 字段中提取的每个值。
下面这个示例显示了如何使用单一权重对具有多个值的单个文档进行平均:
POST /exams/_doc?refresh
{
"grade": [1, 2, 3],
"weight": 2
}
POST /exams/_search
{
"size": 0,
"aggs" : {
"weighted_grade": {
"weighted_avg": {
"value": {
"field": "grade"
},
"weight": {
"field": "weight"
}
}
}
}
}
grade的三个值(1、2 和 3)将作为独立的值包含在内,所有值的权重为2:
{
...
"aggregations": {
"weighted_grade": {
"value": 2.0
}
}
}
聚合返回的结果是 2.0,这与我们手动计算时的预期相符: ((1*2) + (2*2) + (3*2)) / (2+2+2) == 2
脚本(script)
value和weight都可以从脚本中导出,而不是从字段中。 举个简单的例子,下面将使用脚本在文档中给grade和weight加 1:
POST /exams/_search
{
"size": 0,
"aggs" : {
"weighted_grade": {
"weighted_avg": {
"value": {
"script": "doc.grade.value + 1"
},
"weight": {
"script": "doc.weight.value + 1"
}
}
}
}
}
缺失的值(missing values)
参数 missing 定义应该如何处理有缺失值的文档。 value 和 weight的默认行为不同:
默认情况下,如果 value 字段缺失,则忽略该文档,并继续聚合下一个文档。 如果 weight 字段缺失,则假设权重为 1 (类似于常规平均值)。
这两个默认值都可以用参数 missing 覆盖:
POST /exams/_search
{
"size": 0,
"aggs" : {
"weighted_grade": {
"weighted_avg": {
"value": {
"field": "grade",
"missing": 2
},
"weight": {
"field": "weight",
"missing": 3
}
}
}
}
}
boxplot(箱线图聚合)
boxplot 度量聚合,计算从聚合文档中提取的数值的箱线图。 这些值可以由给定的脚本生成,也可以从文档中的特定 numeric 或 histogram 字段中提取。
boxplot 聚合返回制作箱线图(box plot)的基本信息:最小值、最大中值、第一个四分位数(第25个百分位数)和第三个四分位数(第75个百分位数)值。
语法
孤立的 boxplot 聚合如下所示:
{
"boxplot": {
"field": "load_time"
}
}
让我们来看一个表示加载时间(load time)的箱线图:
GET latency/_search
{
"size": 0,
"aggs" : {
"load_time_boxplot" : {
"boxplot" : {
"field" : "load_time"
}
}
}
}
- 字段
load_time必须是 numeric 类型的。
响应看起来会像下面这样:
{
...
"aggregations": {
"load_time_boxplot": {
"min": 0.0,
"max": 990.0,
"q1": 165.0,
"q2": 445.0,
"q3": 725.0
}
}
}
脚本(script)
箱线图度量支持脚本。 例如,如果加载时间(load time)是以毫秒为单位的,但我们希望以秒为单位进行计算,这时我们就可以使用一个脚本来动态转换它们:
GET latency/_search
{
"size": 0,
"aggs" : {
"load_time_boxplot" : {
"boxplot" : {
"script" : {
"lang": "painless",
"source": "doc['load_time'].value / params.timeUnit",
"params" : {
"timeUnit" : 1000
}
}
}
}
}
}
- 参数
field被替换为script,这个 script 参数使用脚本来生成计算百分点的值 - 脚本支持参数化输入,就像任何其他脚本一样
这将把参数script解释为一个内联脚本,使用painless(无痛)脚本语言,没有脚本参数。 要使用一个已存储的脚本,请使用以下语法:
GET latency/_search
{
"size": 0,
"aggs" : {
"load_time_boxplot" : {
"boxplot" : {
"script" : {
"id": "my_script",
"params": {
"field": "load_time"
}
}
}
}
}
}
箱线图的值(通常)是近似值
boxplot 度量使用的算法称为 TDigest (由 Ted Dunning 在使用T-Digests计算精确分位数中引入)。
箱线图与其他百分位数聚合一样,也是不确定的(non-deterministic)。这意味着您可以使用相同的数据得到稍微不同的结果。 这意味着使用相同的数据会得到稍微不同的结果。
压缩(compression)
近似算法必须平衡内存利用率和估计精度。 这种平衡可以使用参数 compression 来控制:
GET latency/_search
{
"size": 0,
"aggs" : {
"load_time_boxplot" : {
"boxplot" : {
"field" : "load_time",
"compression" : 200
}
}
}
}
compression控制内存使用和近似误差
TDigest 算法使用多个“节点”来近似百分位数,可用的节点越多,与数据量成比例的精度(和大内存占用)就越高。 参数compression将最大节点数限制为20 * compression。
因此,通过增加compression的值,可以以更多内存为代价来提高百分位数的准确性。 较大的compression值也会使算法变慢,因为底层树数据结构的大小会增加,从而导致更昂贵的操作。compression的默认值为100。
一个“节点”使用大约 32 字节的内存,因此在最坏的情况下(大量数据被排序并按顺序到达),默认设置将产生大约 64KB 大小的 TDigest。 实际上,数据往往更加随机,TDigest 将使用更少的内存。
缺失的值
参数 missing 定义应该如何处理有缺失值的文档。 默认情况下,它们会被忽略,但也可以将它们视为有一个(默认)值。
GET latency/_search
{
"size": 0,
"aggs" : {
"grade_boxplot" : {
"boxplot" : {
"field" : "grade",
"missing": 10
}
}
}
}
grade字段中没有值的文档将与值为10的文档落入同一个桶。
cardinality(基数聚合)
计算不同值的近似计数的single-value(单值)度量聚合。 值可以从文档的给定的字段中提取,也可以由脚本生成。
假设你正在对商店的销售数据进行索引,并希望计算符合查询条件的已售出产品的唯一数量:
POST /sales/_search?size=0
{
"aggs" : {
"type_count" : {
"cardinality" : {
"field" : "type"
}
}
}
}
请求的响应:
{
...
"aggregations" : {
"type_count" : {
"value" : 3
}
}
}
精度控制
此聚合还支持 precision_threshold 选项:
POST /sales/_search?size=0
{
"aggs" : {
"type_count" : {
"cardinality" : {
"field" : "type",
"precision_threshold": 100
}
}
}
}
precision_threshold选项允许用内存换取准确性,并定义一个唯一的计数,低于该计数时,计数将接近准确值。 超过这个值,计数可能会变得有点模糊。 支持的最大值是 40000,超过该值的阈值将与阈值 40000 具有相同的效果。默认值为3000。
计数是近似值
计算精确的计数需要将值加载到一个哈希集合中并返回其大小。 当处理高基数集合和(或)大值时,这是不可伸缩的,因为所需的内存使用量以及在节点之间传递每个分片的集合会占用太多的集群资源。
这种 cardinality 聚合基于 HyperLogLog++ 算法,该算法基于具有一些有趣属性的值的散列进行计数:
- 可配置的精度,决定如何用内存交换精度,
- 在低基数集合上有极好的准确性,
- 固定的内存使用量:无论是有数百个还是数十亿个唯一值,内存使用量仅取决于配置的精度。
对于精度阈值c,我们实现它时大约需要c * 8个字节。
下图显示了阈值前后误差的变化情况:
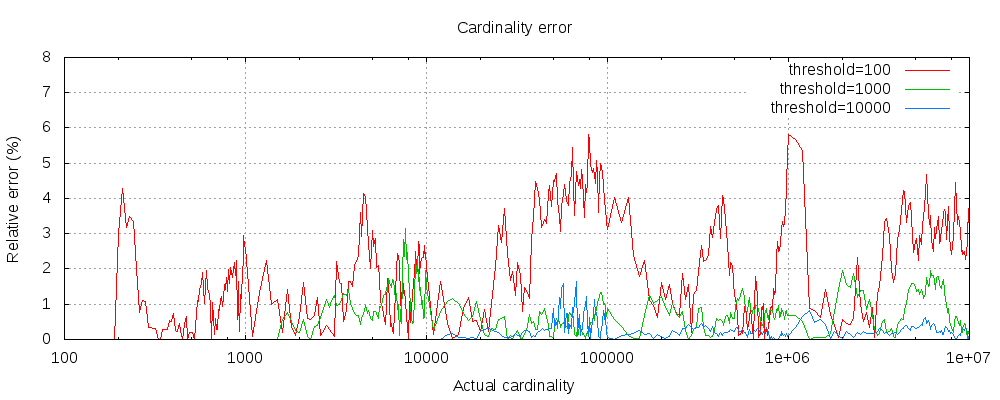
对于所有的 3 个阈值来说,计数都精确到了配置的阈值。 虽然不能保证,但很可能是这样。 实际的准确性取决于所讨论的数据集。 总的来说,大多数数据集显示出一贯良好的准确性。 还要注意,即使阈值低至 100,即使在计算数百万个项目时,误差仍然很低(如上图所示,1-6%)。
HyperLogLog++ 算法依赖于散列值的前导零,散列在数据集中的确切分布会影响基数的准确性。
还请注意,即使阈值低至 100,误差仍然很低,即使在计算数百万个项目时。
预先计算的哈希值 (pre-computed hashes)
对于具有高基数的 string 字段,将字段值的散列存储在索引中,然后对该字段运行 cardinality 聚合可能会更快。 这可以通过从客户端提供哈希值或使用 mapper-murmur3 插件让 Elasticsearch 计算哈希值来实现。
预先计算散列通常只对非常大和(或)高基数的字段有用,因为它节省了CPU和内存。 但是,在 numeric 字段上,散列非常快,存储原始值所需的内存与存储散列所需的内存差不多。 对于低基数 string 字段也是如此,特别是考虑到这些字段已经过优化,以确保每个段的每个唯一值最多计算一次散列。
脚本(script)
cardinality 度量支持脚本,但是性能会受到明显影响,因为散列需要动态计算。
POST /sales/_search?size=0
{
"aggs" : {
"type_promoted_count" : {
"cardinality" : {
"script": {
"lang": "painless",
"source": "doc['type'].value + ' ' + doc['promoted'].value"
}
}
}
}
}
这将把参数 script 解释为一个 inline(内联) 脚本,使用painless(无痛) 脚本语言,没有脚本参数。 要使用一个已存储的脚本,请使用以下语法:
POST /sales/_search?size=0
{
"aggs" : {
"type_promoted_count" : {
"cardinality" : {
"script" : {
"id": "my_script",
"params": {
"type_field": "type",
"promoted_field": "promoted"
}
}
}
}
}
}
缺失的值
参数 missing 定义应该如何处理有缺失值的文档。 默认情况下,它们会被忽略,但也可以将它们视为有一个(默认)值。
POST /sales/_search?size=0
{
"aggs" : {
"tag_cardinality" : {
"cardinality" : {
"field" : "tag",
"missing": "N/A"
}
}
}
}
tag字段没有值的文档将与具有值N/A的文档落入相同的桶中。
stats(统计聚合)
一种multi-value(多值)度量聚合,计算从聚合文档中提取的数值的统计(stats)数据。 值可以从文档的给定的 numeric 字段中提取,也可以由脚本生成。
返回的统计数据包括:min、max、sum、count 和 avg。
假设数据由代表学生考试成绩(0 到 100 之间)的文档组成:
POST /exams/_search?size=0
{
"aggs" : {
"grades_stats" : { "stats" : { "field" : "grade" } }
}
}
上述聚合计算所有文档的分数统计信息。 聚合类型是 stats ,field 设置定义了用于统计计算的文档的 numeric 字段。 上面的查询将返回以下内容:
{
...
"aggregations": {
"grades_stats": {
"count": 2,
"min": 50.0,
"max": 100.0,
"avg": 75.0,
"sum": 150.0
}
}
}
聚合的名称(上面的grades_stats)也用作键,通过它可以从返回的响应中检索聚合结果。
脚本(script)
基于脚本计算成绩统计数据:
POST /exams/_search?size=0
{
"aggs" : {
"grades_stats" : {
"stats" : {
"script" : {
"lang": "painless",
"source": "doc['grade'].value"
}
}
}
}
}
这将把参数 script 解释为一个 inline(内联) 脚本,使用painless(无痛) 脚本语言,没有脚本参数。 要使用一个已存储的脚本,请使用以下语法:
POST /exams/_search?size=0
{
"aggs" : {
"grades_stats" : {
"stats" : {
"script" : {
"id": "my_script",
"params" : {
"field" : "grade"
}
}
}
}
}
}
值脚本(value script)
事实证明,这次考试远远超出了学生的水平,需要进行分数修正。 我们可以使用一个值脚本来获取新的统计数据:
POST /exams/_search?size=0
{
"aggs" : {
"grades_stats" : {
"stats" : {
"field" : "grade",
"script" : {
"lang": "painless",
"source": "_value * params.correction",
"params" : {
"correction" : 1.2
}
}
}
}
}
}
缺失的值
参数 missing 定义应该如何处理有缺失值的文档。 默认情况下,它们会被忽略,但也可以将它们视为有一个(默认)值。
POST /exams/_search?size=0
{
"aggs" : {
"grades_stats" : {
"stats" : {
"field" : "grade",
"missing": 0
}
}
}
}
grade字段中没有值的文档将与值为0的文档落入同一个桶。
extended_stats 聚合
一种multi-value(多值)度量聚合,计算从聚合文档中提取的数值的统计(stats)数据。 值可以从文档的给定的 numeric 字段中提取,也可以由脚本生成。
extended_stats 聚合是 stats 聚合的扩展版本,其中添加了额外的度量,如sum_of_squares、variance、std_deviation 和 std_deviation_bounds。
假设数据由代表学生考试成绩(0 到 100 之间)的文档组成:
GET /exams/_search
{
"size": 0,
"aggs" : {
"grades_stats" : { "extended_stats" : { "field" : "grade" } }
}
}
上述聚合计算所有文档的分数统计信息。 聚合类型是 extended_stats ,field 设置定义了用于统计计算的文档的 numeric 字段。 上面的查询将返回以下内容:
{
...
"aggregations": {
"grades_stats": {
"count": 2,
"min": 50.0,
"max": 100.0,
"avg": 75.0,
"sum": 150.0,
"sum_of_squares": 12500.0,
"variance": 625.0,
"std_deviation": 25.0,
"std_deviation_bounds": {
"upper": 125.0,
"lower": 25.0
}
}
}
}
聚合的名称(上面的grades_stats)也用作键,通过它可以从返回的响应中检索聚合结果。
标准偏差界限 (standard deviation bounds)
默认情况下,extended_stats 度量将返回一个名为 std_deviation_bounds 的对象,该对象提供了一个距离平均值正负两个标准差的区间。 这是一种可视化数据差异的有用方法。 如果你想要使用不同的边界,例如三个标准偏差,可以在请求中设置 sigma:
GET /exams/_search
{
"size": 0,
"aggs" : {
"grades_stats" : {
"extended_stats" : {
"field" : "grade",
"sigma" : 3
}
}
}
}
sigma控制应该显示多少偏离平均值的标准偏差
sigma可以是任何非负的浮点数,这意味着你可以请求非整数值,如1.5。 值0是有效的,但是将简单地返回upper(上) 和lower(下) 限的平均值。
标准差和界限需要正态性
默认情况下会显示标准差及其界限,但它们并不总是适用于所有数据集。 数据必须是正态分布的,这样度量才有意义。 标准差背后的统计会假设数据呈正态分布,因此,如果数据严重向左或向右倾斜,返回的值将会产生误导。
脚本
基于脚本计算成绩的统计数据:
GET /exams/_search
{
"size": 0,
"aggs" : {
"grades_stats" : {
"extended_stats" : {
"script" : {
"source" : "doc['grade'].value",
"lang" : "painless"
}
}
}
}
}
这将把参数 script 解释为一个 inline(内联) 脚本,使用painless(无痛) 脚本语言,没有脚本参数。 要使用一个已存储的脚本,请使用以下语法:
GET /exams/_search
{
"size": 0,
"aggs" : {
"grades_stats" : {
"extended_stats" : {
"script" : {
"id": "my_script",
"params": {
"field": "grade"
}
}
}
}
}
}
值脚本(value script)
事实证明,这次考试远远超出了学生的水平,需要进行分数修正。 我们可以使用一个值脚本来获取新的统计数据:
GET /exams/_search
{
"size": 0,
"aggs" : {
"grades_stats" : {
"extended_stats" : {
"field" : "grade",
"script" : {
"lang" : "painless",
"source": "_value * params.correction",
"params" : {
"correction" : 1.2
}
}
}
}
}
}
缺失的值
参数 missing 定义应该如何处理有缺失值的文档。 默认情况下,它们会被忽略,但也可以将它们视为有一个(默认)值。
GET /exams/_search
{
"size": 0,
"aggs" : {
"grades_stats" : {
"extended_stats" : {
"field" : "grade",
"missing": 0
}
}
}
}
grade字段中没有值的文档将与值为0的文档落入同一个桶。
geo_bounds 聚合
一种度量聚合,用于计算包含字段的所有 geo_point 值的边界框。
例如:
# 定义索引
PUT /museums
{
"mappings": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}
# 新增并索引文档
POST /museums/_bulk?refresh
{"index":{"_id":1}}
{"location": "52.374081,4.912350", "name": "NEMO Science Museum"}
{"index":{"_id":2}}
{"location": "52.369219,4.901618", "name": "Museum Het Rembrandthuis"}
{"index":{"_id":3}}
{"location": "52.371667,4.914722", "name": "Nederlands Scheepvaartmuseum"}
{"index":{"_id":4}}
{"location": "51.222900,4.405200", "name": "Letterenhuis"}
{"index":{"_id":5}}
{"location": "48.861111,2.336389", "name": "Musée du Louvre"}
{"index":{"_id":6}}
{"location": "48.860000,2.327000", "name": "Musée d'Orsay"}
# 执行搜索
POST /museums/_search?size=0
{
"query" : {
"match" : { "name" : "musée" }
},
"aggs" : {
"viewport" : {
"geo_bounds" : {
"field" : "location",
"wrap_longitude" : true
}
}
}
}
- 指定
geo_bounds聚合用于获取边界的字段 wrap_longitude是一个可选参数,它指定是否允许边界框与国际日期变更线重叠。 默认值为true
上面的聚合演示了如何为所有博物馆(museum)的文档计算 location 字段的边界框。
上面的聚合的响应:
{
...
"aggregations": {
"viewport": {
"bounds": {
"top_left": {
"lat": 48.86111099738628,
"lon": 2.3269999679178
},
"bottom_right": {
"lat": 48.85999997612089,
"lon": 2.3363889567553997
}
}
}
}
}
geo_centroid 聚合
根据 geo-point 字段的所有坐标值计算加权 矩心(centroid) 的度量聚合。
示例:
PUT /museums
{
"mappings": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}
POST /museums/_bulk?refresh
{"index":{"_id":1}}
{"location": "52.374081,4.912350", "city": "Amsterdam", "name": "NEMO Science Museum"}
{"index":{"_id":2}}
{"location": "52.369219,4.901618", "city": "Amsterdam", "name": "Museum Het Rembrandthuis"}
{"index":{"_id":3}}
{"location": "52.371667,4.914722", "city": "Amsterdam", "name": "Nederlands Scheepvaartmuseum"}
{"index":{"_id":4}}
{"location": "51.222900,4.405200", "city": "Antwerp", "name": "Letterenhuis"}
{"index":{"_id":5}}
{"location": "48.861111,2.336389", "city": "Paris", "name": "Musée du Louvre"}
{"index":{"_id":6}}
{"location": "48.860000,2.327000", "city": "Paris", "name": "Musée d'Orsay"}
POST /museums/_search?size=0
{
"aggs" : {
"centroid" : {
"geo_centroid" : {
"field" : "location"
}
}
}
}
geo_centroid聚合指定用于计算矩心的字段。(注意:字段必须是geo-point类型)
上面的聚合演示了如何计算博物馆(museum)的所有文档的 location(位置) 字段的矩心。
上面聚合的响应为:
{
...
"aggregations": {
"centroid": {
"location": {
"lat": 51.00982965203002,
"lon": 3.9662131341174245
},
"count": 6
}
}
}
当 geo_centroid 聚合作为其他桶聚合的子聚合时,会更有意思。
例如:
POST /museums/_search?size=0
{
"aggs" : {
"cities" : {
"terms" : { "field" : "city.keyword" },
"aggs" : {
"centroid" : {
"geo_centroid" : { "field" : "location" }
}
}
}
}
}
上面的示例使用 geo_centroid 作为 terms 桶聚合的子聚合,用于查找每个城市中博物馆的中心位置。
上面聚合的响应为:
{
...
"aggregations": {
"cities": {
"sum_other_doc_count": 0,
"doc_count_error_upper_bound": 0,
"buckets": [
{
"key": "Amsterdam",
"doc_count": 3,
"centroid": {
"location": {
"lat": 52.371655656024814,
"lon": 4.909563297405839
},
"count": 3
}
},
{
"key": "Paris",
"doc_count": 2,
"centroid": {
"location": {
"lat": 48.86055548675358,
"lon": 2.3316944623366
},
"count": 2
}
},
{
"key": "Antwerp",
"doc_count": 1,
"centroid": {
"location": {
"lat": 51.22289997059852,
"lon": 4.40519998781383
},
"count": 1
}
}
]
}
}
}
使用geo_centroid作为geohash_grid的子聚合
geohash_grid 聚合将文档而不是单个 geo-point 放入桶中。 如果文档的 geo_point字段包含多值(multiple values),则该文档可以被分配给多个桶,即使一个或多个 geo-point 在桶边界之外。
如果还用了 geocentroid 子聚合,则使用桶中的所有 geo-point (包括桶边界之外的 geo-point )来计算每个矩心。这可能会导致矩心位于桶边界之外。
max 聚合
single-value(单值) 度量聚合,跟踪并返回从聚合文档中提取的数值的最大值。 这些值可以从文档中指定的 numeric 字段中提取,也可以由提供的脚本生成。
min和max聚合对数据以double(双精度) 进行操作。 因此,在绝对值大于2^53的长整型上运行时,结果可能是近似的。
计算所有文档的最高价格(max_price):
POST /sales/_search?size=0
{
"aggs" : {
"max_price" : { "max" : { "field" : "price" } }
}
}
响应:
{
...
"aggregations": {
"max_price": {
"value": 200.0
}
}
}
可以看到,聚合的名称(上面的max_price)也作为键,通过它可以从返回的响应中检索聚合结果。
脚本(script)
max 聚合还可以计算脚本的最大值。以下示例计算最高价格:
POST /sales/_search
{
"aggs" : {
"max_price" : {
"max" : {
"script" : {
"source" : "doc.price.value"
}
}
}
}
}
这将使用 painless(无痛) 脚本语言,没有脚本参数。 要使用存储的脚本,请使用以下语法:
POST /sales/_search
{
"aggs" : {
"max_price" : {
"max" : {
"script" : {
"id": "my_script",
"params": {
"field": "price"
}
}
}
}
}
}
值脚本 (Value Script)
假设索引中的文档价格以美元为单位,但是我们想以欧元计算最大值(这个例子中,假设兑换率是 1.2)。 我们可以使用值脚本,在汇总每个值之前对其应用转换率(conversion_rate):
POST /sales/_search
{
"aggs" : {
"max_price_in_euros" : {
"max" : {
"field" : "price",
"script" : {
"source" : "_value * params.conversion_rate",
"params" : {
"conversion_rate" : 1.2
}
}
}
}
}
}
缺失的值
参数 missing 定义应该如何处理有缺失值的文档。 默认情况下,它们将被忽略,但也可以将它们视为有一个值。
POST /sales/_search
{
"aggs" : {
"grade_max" : {
"max" : {
"field" : "grade",
"missing": 10
}
}
}
}
grade字段没有值的文档将与值为10的文档落入同一个桶中。
min 聚合
single-value(单值) 度量聚合,跟踪并返回从聚合文档中提取的数值的最小值。 这些值可以从文档中指定的 numeric 字段中提取,也可以由提供的脚本生成。
min和max聚合对数据以double(双精度) 进行操作。 因此,在绝对值大于2^53的长整型上运行时,结果可能是近似的。
计算所有文档的最低价格(min_price):
POST /sales/_search?size=0
{
"aggs" : {
"min_price" : { "min" : { "field" : "price" } }
}
}
响应:
{
...
"aggregations": {
"min_price": {
"value": 10.0
}
}
}
可以看到,聚合的名称(上面的min_price)也作为键,通过它可以从返回的响应中检索聚合结果。
脚本(script)
min 聚合还可以计算脚本的最小值。以下示例计算最低价格:
POST /sales/_search
{
"aggs" : {
"min_price" : {
"min" : {
"script" : {
"source" : "doc.price.value"
}
}
}
}
}
这将使用 painless(无痛) 脚本语言,没有脚本参数。 要使用存储的脚本,请使用以下语法:
POST /sales/_search
{
"aggs" : {
"min_price" : {
"min" : {
"script" : {
"id": "my_script",
"params": {
"field": "price"
}
}
}
}
}
}
值脚本 (Value Script)
假设索引中的文档价格以美元为单位,但是我们想以欧元计算最小值(这个例子中,假设兑换率是 1.2)。 我们可以使用值脚本,在汇总每个值之前对其应用转换率(conversion_rate):
POST /sales/_search
{
"aggs" : {
"min_price_in_euros" : {
"min" : {
"field" : "price",
"script" : {
"source" : "_value * params.conversion_rate",
"params" : {
"conversion_rate" : 1.2
}
}
}
}
}
}
缺失的值
参数 missing 定义应该如何处理有缺失值的文档。 默认情况下,它们将被忽略,但也可以将它们视为有一个值。
POST /sales/_search
{
"aggs" : {
"grade_min" : {
"min" : {
"field" : "grade",
"missing": 10
}
}
}
}
grade字段没有值的文档将与值为10的文档落入同一个桶中。
median_absolute_deviation(绝对中位差聚合)
这个single-value(单值) 聚合近似于其搜索结果的绝对中位差(median absolute deviation)。
绝对中位差是一个可变性的衡量标准。 它是一个可靠的统计数据,这意味着它对于描述可能有异常值或可能不是正态分布的数据很有用。 对于这样的数据,它可能比标准差(standard deviation)更具描述性。
它被计算为每个数据点与整个样本的中位数的偏差的中位数。 也就是说,对于随机变量X,绝对中位差是 median(|median(X) - Xi|)。
示例
假设我们的数据代表 1 到 5 星的产品评论。 这样的评论通常被汇总为一个平均值,这很容易理解,但不能描述评论的可变性。 估算绝对中位差可以让我们了解到评论之间的差异有多大。
在本例中,我们有一个平均评级为3星的产品。 让我们看看它的评级的绝对中位差,以确定它们的变化程度
GET reviews/_search
{
"size": 0,
"aggs": {
"review_average": {
"avg": {
"field": "rating"
}
},
"review_variability": {
"median_absolute_deviation": {
"field": "rating"
}
}
}
}
rating必须是一个 numeric 字段
由此产生的绝对中位差值2告诉我们,在评级中有相当多的可变性。 点评的人肯定对这个产品有不同的看法。
{
...
"aggregations": {
"review_average": {
"value": 3.0
},
"review_variability": {
"value": 2.0
}
}
}
近似值
计算绝对中位差的简单实现将整个样本存储在内存中,因此这种聚合计算的是近似值。 它使用 TDigest 数据结构来近似样本中值和样本中值偏差的中值。 有关 TDigests 的近似特征的更多信息,请参考百分位数(通常)是近似的。
参数 compression 控制着资源使用和 TDigest 分位数近似值的精确度之间的权衡,因此也控制着该聚合的绝对中位差近似值的精确度。 较高的 compression 设置以较高的内存使用率为代价提供了更精确的近似值。 有关 TDigest 参数 compression 的特征的更多信息,请参考 compression。
GET reviews/_search
{
"size": 0,
"aggs": {
"review_variability": {
"median_absolute_deviation": {
"field": "rating",
"compression": 100
}
}
}
}
此聚合的默认 compression 的值是1000。 在这个压缩级别上,该聚合通常与确切结果的差距在 5% 以内,但观察到的性能将取决于样本数据。
脚本
该度量聚合支持脚本。 在上面的例子中,产品评论的等级是 1 到 5。 如果我们想将它们修改为 1 到 10,可以使用脚本。
如果要使用内联脚本:
GET reviews/_search
{
"size": 0,
"aggs": {
"review_variability": {
"median_absolute_deviation": {
"script": {
"lang": "painless",
"source": "doc['rating'].value * params.scaleFactor",
"params": {
"scaleFactor": 2
}
}
}
}
}
}
要指定一个存储的脚本:
GET reviews/_search
{
"size": 0,
"aggs": {
"review_variability": {
"median_absolute_deviation": {
"script": {
"id": "my_script",
"params": {
"field": "rating"
}
}
}
}
}
}
缺失的值
参数 missing 定义应该如何处理有缺失值的文档。 默认情况下,它们将被忽略,但也可以将它们视为有一个值。
让我们乐观一点,假设一些点评的人非常喜欢这个产品,以至于忘记给它打分。我们会给他们 5 颗星:
GET reviews/_search
{
"size": 0,
"aggs": {
"review_variability": {
"median_absolute_deviation": {
"field": "rating",
"missing": 5
}
}
}
}
percentiles(百分位数聚合)
一个 multi-value(多值) 度量聚合,计算从聚合文档中提取的数值的一个或多个百分位数。 这些值可以由给定的脚本生成,也可以从文档中的特定数值或 histogram 字段 中提取。
百分位数表示观察值出现一定百分比的点。 例如,第 95 百分位是大于观察值的 95% 的值。
百分位数通常用于发现异常值。 在正态分布中,第 0.13 和 99.87 百分位代表平均值的 3 个标准差。 任何超出 3 个标准偏差的数据通常被认为是异常的。
当检索到一个百分比范围时,可以使用它们来估计数据分布,并确定数据是否倾斜、双峰等。
假设数据由网站加载时间组成。 加载时间的平均值和中值对管理员来说不是很有用。 最大值可能很有趣,但它很容易被一个缓慢的响应所扭曲。
让我们看看代表加载时间(load_time)的百分比范围:
GET latency/_search
{
"size": 0,
"aggs" : {
"load_time_outlier" : {
"percentiles" : {
"field" : "load_time"
}
}
}
}
- 字段
load_time必须是一个 numeric 类型的字段。
默认情况下,percentile度量将生成一个百分位数范围:[ 1, 5, 25, 50, 75, 95, 99 ]。 响应将如下所示:
{
...
"aggregations": {
"load_time_outlier": {
"values" : {
"1.0": 5.0,
"5.0": 25.0,
"25.0": 165.0,
"50.0": 445.0,
"75.0": 725.0,
"95.0": 945.0,
"99.0": 985.0
}
}
}
}
如你所见,该聚合返回默认范围内每个百分位的计算值。 如果假设响应时间以毫秒为单位,很明显网页通常在 10-725 毫秒内加载,但偶尔会达到 945-985毫秒。
通常,管理员只对异常值-极端的百分位数-感兴趣。 我们可以只指定我们感兴趣的百分比(请求的百分位数必须是0-100之间的值,包括0和100):
GET latency/_search
{
"size": 0,
"aggs" : {
"load_time_outlier" : {
"percentiles" : {
"field" : "load_time",
"percents" : [95, 99, 99.9]
}
}
}
}
- 使用
percents参数指定要计算的特定百分位数
keyed 响应
默认情况下,keyed 标志设置为 true,它将唯一的字符串键与每个桶相关联,并将范围作为哈希而不是数组返回。 将 keyed 标志设置为 false 将禁用此行为:
GET latency/_search
{
"size": 0,
"aggs": {
"load_time_outlier": {
"percentiles": {
"field": "load_time",
"keyed": false
}
}
}
}
响应:
{
...
"aggregations": {
"load_time_outlier": {
"values": [
{
"key": 1.0,
"value": 5.0
},
{
"key": 5.0,
"value": 25.0
},
{
"key": 25.0,
"value": 165.0
},
{
"key": 50.0,
"value": 445.0
},
{
"key": 75.0,
"value": 725.0
},
{
"key": 95.0,
"value": 945.0
},
{
"key": 99.0,
"value": 985.0
}
]
}
}
}
脚本
百分位数度量支持脚本。 例如,如果加载时间是以毫秒为单位的,但我们希望以秒为单位计算百分位数,我们可以使用一个脚本来进行动态转换:
GET latency/_search
{
"size": 0,
"aggs" : {
"load_time_outlier" : {
"percentiles" : {
"script" : {
"lang": "painless",
"source": "doc['load_time'].value / params.timeUnit",
"params" : {
"timeUnit" : 1000
}
}
}
}
}
}
- 参数
field被替换为script,它使用脚本来生成计算百分位的值 - 像任何其他脚本一样,这里的脚本支持参数化输入
这将使用 painless(无痛) 脚本语言,没有脚本参数。 要使用存储的脚本,请使用以下语法:
GET latency/_search
{
"size": 0,
"aggs" : {
"load_time_outlier" : {
"percentiles" : {
"script" : {
"id": "my_script",
"params": {
"field": "load_time"
}
}
}
}
}
}
百分位数(通常)是近似值
有许多不同的算法来计算百分位数。 简单的实现只是将所有的值存储在一个有序的数组中。 要找到第50个百分位数,只需找到位于 my_array[count(my_array) * 0.5] 的值。
显然,简单的实现是不可伸缩的——排序后的数组随着数据集中值的数量线性增长。 要计算 Elasticsearch 集群中潜在的数十亿个值的百分位数,需要计算近似(approximate)百分位数。
percentile 度量使用的算法称为 TDigest (由 Ted Dunning 在使用 T-Digests 计算精确分位数)中引入)。
使用这一度量时,需要记住一些准则:
- 精度与
q(1-q)成正比。 这意味着极端百分位数(例如99%)比不太极端的百分位数(例如中值)更准确 - 对于小的数值集合,百分位数是高度准确的(如果数据足够小,可能是100%准确)。
- 随着桶中值的数量增加,算法开始近似百分位数。 这实际上是在用准确性来减少内存的使用量。 不准确的确切程度很难概括,因为它取决于数据分布和要聚合的数据量
下图显示了均匀分布的相对误差,它取决于采集值的数量和要求的百分位数:
![[percentiles_error.png]](https://doucment-img.oss-cn-hangzhou.aliyuncs.com/ElasticSearch/Elasticsearch%20Images/percentiles_error.png)
它显示了极端百分位数的精度更好。 对于大量的值,误差减小的原因是大数定律使值的分布越来越均匀,t-digest 树可以更好地进行汇总。 在偏态分布上就不是这样了。
百分位数聚合也是不确定的(non-deterministic)。 这意味着使用相同的数据可以得到稍微不同的结果。
压缩(compression)
近似算法必须平衡内存利用率和估计精度。 这种平衡可以使用参数 compression 来控制:
GET latency/_search
{
"size": 0,
"aggs" : {
"load_time_outlier" : {
"percentiles" : {
"field" : "load_time",
"tdigest": {
"compression" : 200
}
}
}
}
}
compression控制内存使用和近似误差
TDigest 算法使用多个“节点”来近似百分位数,可用的节点越多,与数据量成比例的精度(和大内存占用)就越高。 参数compression将最大节点数限制为20 * compression。
因此,通过增加compression的值,可以以更多内存为代价来提高百分位数的准确性。 较大的compression值也会使算法变慢,因为底层树数据结构的大小会增加,从而导致更昂贵的操作。compression的默认值为100。
一个“节点”使用大约 32 字节的内存,因此在最坏的情况下(大量数据被排序并按顺序到达),默认设置将产生大约 64KB 大小的 TDigest。 实际上,数据往往更加随机,TDigest 将使用更少的内存。
HDR 直方图(Histogram)
此设置公开了 HDR 直方图的内部实现,语法将来可能会改变。
HDR直方图(High Dynamic Range Histogram, 高动态范围直方图)是一种替代实现,在计算延迟测量的百分位数时非常有用,因为它比 t-digest 实现更快,但需要更大的内存。 这种实现保持固定的最坏情况百分比误差(指定为有效数字的数量)。 这意味着,如果在设置为 3 个有效数字的直方图中记录的数据值从 1 微秒到 1 小时(3,600,000,000微秒),则对于 1 毫秒和 3.6 秒(或更好)的最大跟踪值(1小时),它将保持 1 微秒的值分辨率。
通过在请求中指定参数 method,可以使用 HDR 直方图:
GET latency/_search
{
"size": 0,
"aggs" : {
"load_time_outlier" : {
"percentiles" : {
"field" : "load_time",
"percents" : [95, 99, 99.9],
"hdr": {
"number_of_significant_value_digits" : 3
}
}
}
}
}
hdr对象表示应该使用HDR直方图来计算百分位数,并且可以在对象内部指定该算法的特定设置number_of_significant_value_digits指定直方图数值的分辨率,以有效位数表示
HDR 直方图仅支持正值,如果向其传递负值,将会出错。 如果值的范围未知,使用HDR 直方图也不是一个好主意,因为这可能会导致很高的内存使用率。
缺失的值
参数 missing 定义应该如何处理有缺失值的文档。 默认情况下,它们会被忽略,但也可以将它们视为有一个(默认)值。
GET latency/_search
{
"size": 0,
"aggs" : {
"grade_percentiles" : {
"percentiles" : {
"field" : "grade",
"missing": 10
}
}
}
}
grade字段中没有值的文档将与值为10的文档落入同一个桶。
percentile_ranks 聚合
一个 multi-value(多值) 度量聚合,计算从聚合文档中提取的数值的一个或多个百分位数排名。 这些值可以由给定的脚本生成,也可以从文档中的特定数值或 histogram 字段中提取。
要了解有关百分位等级聚合(percentile ranks aggregation)的近似值和内存使用的建议,请参阅百分位(通常)是近似值及压缩。
百分位数等级显示低于特定值的观察值的百分比。 例如,如果一个值大于或等于所有观察值中的 95% ,则称其处于第 95 百分位。
假设数据由网站加载时间组成。 可能有一个服务协议,内容是 95% 的页面加载在 500 毫秒内完成,99% 的页面加载在 600 毫秒内完成。
让我们看看代表加载时间(load_time)的百分比范围:
GET latency/_search
{
"size": 0,
"aggs" : {
"load_time_ranks" : {
"percentile_ranks" : {
"field" : "load_time",
"values" : [500, 600]
}
}
}
}
- 字段
load_time必须是 numeric 类型的
响应将如下所示:
{
...
"aggregations": {
"load_time_ranks": {
"values" : {
"500.0": 90.01,
"600.0": 100.0
}
}
}
}
根据这些信息,可以确定达到了 99% 的加载时间目标,但没有完全达到 95% 的加载时间目标(在 500 毫秒内加载完成的只达到了 90.01%)
keyed 响应
默认情况下,keyed 标志设置为 true,它将唯一的字符串键与每个桶相关联,并将范围作为哈希而不是数组返回。 将 keyed 标志设置为 false 将禁用此行为:
GET latency/_search
{
"size": 0,
"aggs": {
"load_time_ranks": {
"percentile_ranks": {
"field": "load_time",
"values": [500, 600],
"keyed": false
}
}
}
}
响应:
{
...
"aggregations": {
"load_time_ranks": {
"values": [
{
"key": 500.0,
"value": 90.01
},
{
"key": 600.0,
"value": 100.0
}
]
}
}
}
脚本
百分位数等级度量支持脚本。 例如,如果加载时间是以毫秒为单位的,但我们希望以秒为单位提供值,我们可以使用一个脚本来进行动态转换:
GET latency/_search
{
"size": 0,
"aggs" : {
"load_time_ranks" : {
"percentile_ranks" : {
"values" : [500, 600],
"script" : {
"lang": "painless",
"source": "doc['load_time'].value / params.timeUnit",
"params" : {
"timeUnit" : 1000
}
}
}
}
}
}
- 参数
field被替换为script,它使用脚本来生成计算百分位等级的值 - 像任何其他脚本一样,这里的脚本支持参数化输入
这将使用 painless(无痛) 脚本语言,没有脚本参数。 要使用存储的脚本,请使用以下语法:
GET latency/_search
{
"size": 0,
"aggs" : {
"load_time_ranks" : {
"percentile_ranks" : {
"values" : [500, 600],
"script" : {
"id": "my_script",
"params": {
"field": "load_time"
}
}
}
}
}
}
HDR直方图(Histogram)
此设置公开了 HDR直方图的内部实现,语法将来可能会改变。
HDR直方图(High Dynamic Range Histogram, 高动态范围直方图)是一种替代实现,在计算延迟测量的百分位等级时非常有用,因为它比 t-digest 实现更快,但需要更大的内存。 这种实现保持固定的最坏情况百分比误差(指定为有效数字的数量)。 这意味着,如果在设置为 3 个有效数字的直方图中记录的数据值从 1 微秒到 1 小时(3,600,000,000 微秒),则对于 1 毫秒和 3.6 秒(或更好)的最大跟踪值(1 小时),它将保持 1 微秒的值分辨率。
通过在请求中指定参数 method,可以使用 HDR 直方图:
GET latency/_search
{
"size": 0,
"aggs" : {
"load_time_ranks" : {
"percentile_ranks" : {
"field" : "load_time",
"values" : [500, 600],
"hdr": {
"number_of_significant_value_digits" : 3
}
}
}
}
}
hdr对象表示应该使用 HDR直方图来计算百分位数,并且可以在对象内部指定该算法的特定设置number_of_significant_value_digits指定直方图数值的分辨率,以有效位数表示
HDR直方图仅支持正值,如果向其传递负值,将会出错。 如果值的范围未知,使用HDR直方图也不是一个好主意,因为这可能会导致很高的内存使用率。
缺失的值
参数 missing 定义应该如何处理有缺失值的文档。 默认情况下,它们会被忽略,但也可以将它们视为有一个(默认)值。
GET latency/_search
{
"size": 0,
"aggs" : {
"load_time_ranks" : {
"percentile_ranks" : {
"field" : "load_time",
"values" : [500, 600],
"missing": 10
}
}
}
}
load_time字段中没有值的文档将与值为10的文档落入同一个桶。
scripted_metric 聚合
使用脚本执行以提供度量输出的度量聚合。
示例:
POST ledger/_search?size=0
{
"query" : {
"match_all" : {}
},
"aggs": {
"profit": {
"scripted_metric": {
"init_script" : "state.transactions = []",
"map_script" : "state.transactions.add(doc.type.value == 'sale' ? doc.amount.value : -1 * doc.amount.value)",
"combine_script" : "double profit = 0; for (t in state.transactions) { profit += t } return profit",
"reduce_script" : "double profit = 0; for (a in states) { profit += a } return profit"
}
}
}
}
init_script是一个可选的参数,其他的脚本都是必需的。
上面的聚合演示了如何使用脚本聚合来计算销售和成本交易的总利润。
其响应如下:
{
"took": 218,
...
"aggregations": {
"profit": {
"value": 240.0
}
}
}
在上面的例子中也可以指定存储的脚本,如下所示:
POST ledger/_search?size=0
{
"aggs": {
"profit": {
"scripted_metric": {
"init_script" : {
"id": "my_init_script"
},
"map_script" : {
"id": "my_map_script"
},
"combine_script" : {
"id": "my_combine_script"
},
"params": {
"field": "amount"
},
"reduce_script" : {
"id": "my_reduce_script"
}
}
}
}
}
init、map和combine脚本的脚本参数必须在全局params对象中指定,以便可以在脚本之间共享。
有关指定脚本的更多详细信息,请参考脚本文档。
允许的返回类型
虽然在单个脚本中可以使用任何有效的脚本对象,但是脚本必须在 state 对象中仅返回或存储以下类型:
- 原始类型(primitive types)
- 字符串(string)
- 映射(map,仅包含此处列出的类型的键和值)
- 数组(array,仅包含此处列出的类型的元素)
脚本的范围
脚本化度量聚合在其执行的 4 个阶段中使用脚本:
- init_script
在收集任何文件之前执行。允许聚合设置任何初始状态。在上面的例子中,init_script在state对象中创建了一个数组transactions。 - map_script
每个收集的文档执行一次。这是一个必需的脚本。如果没有指定combine_script,那么结果状态需要存储在state对象中。在上面的示例中,map_script检查type字段的值。 如果值为 sale,则amount字段的值将被添加到transactions数组中。 如果type字段的值不是 sale,则将amount字段取反的值添加到transactions中。 - combine_script
文档收集完成后,在每个分片上执行一次。这是一个必需的脚本。允许聚合合并从每个分片返回的状态。在上面的例子中,combine_script遍历所有存储的transactions,对profit变量中的值求和,最后返回profit。 - reduce_script
在所有分片返回结果后,在协调节点上执行一次。 这是一个必需的脚本。 该脚本提供了对变量states的访问,该变量是每个分片上的 combine_script 结果的数组。在上面的例子中,reduce_script遍历每个分片返回的profit,对这些值求和,然后返回最终的组合的 profit(利润),该利润将在聚合的响应中返回。
示例
设想这样一种情况,你将下面的文档索引到一个包含两个分片的索引中:
PUT /transactions/_bulk?refresh
{"index":{"_id":1}}
{"type": "sale","amount": 80}
{"index":{"_id":2}}
{"type": "cost","amount": 10}
{"index":{"_id":3}}
{"type": "cost","amount": 30}
{"index":{"_id":4}}
{"type": "sale","amount": 130}
假设文档 1 和 3 最终在分片 A 上,文档 2 和 4 最终在分片 B 上。 下面是上例中每个阶段的汇总结果。
在 init_script 之前
state 被初始化为一个新的空对象。
"state" : {}
在 init_script 之后
在执行任何文档收集之前,这将在每个分片上运行一次,因此我们将在每个分片上有一个副本:
- 分片 A
"state" : { "transactions" : [] } - 分片 B
"state" : { "transactions" : [] }
在 map_script 之后
每个分片收集它的文档,并在收集的每个文档上运行 map_script:
- 分片 A
"state" : { "transactions" : [ 80, -30 ] } - 分片 B
"state" : { "transactions" : [ -10, 130 ] }
在 combine_script 之后
在文档收集完成后,在每个分片上执行 combine_script,并将所有 transactions 减少到每个分片的单个利润数字(通过对 transactions 数组中的值求和),该数字被传递回协调节点:
- 分片 A
50 - 分片 B
120
在 reduce_script 之后
reduce_script 接收一个 states 数组,其中包含每个分片的组合脚本的结果:
"states" : [
50,
120
]
它将分片的响应减少到最终的总利润(profit)数值(通过对这些值求和),并将其作为聚合的结果返回,以生成响应:
{
...
"aggregations": {
"profit": {
"value": 170
}
}
}
其他参数
| 参数 | 含义 |
|---|---|
| params | 可选的。 一个对象,其内容将作为变量传递给 init_script、map_script 和 combine_script。 这对于允许用户控制聚合行为以及存储脚本之间的状态非常有用。 如果未指定,默认情况下相当于指定了:"params" : {} |
空桶
如果脚本化度量聚合的父桶没有收集任何文档,将从分片返回一个值为 null 的空聚合响应。 在这种情况下,reduce_script 的 states 变量将包含 null 作为来自该分片的响应。 因此,reduce_script 应该期望并处理来自分片的 null 响应。
string_stats(字符串统计聚合)
一种multi-value(多值) 度量聚合,计算从聚合文档中提取的字符串值的统计数据。 这些值可以从文档中指定的 keyword 字段中检索,也可以由提供的脚本生成。
字符串统计信息聚合返回以下结果:
count- 计算的非空字段的数量。min_length- 最短的词项的长度。max_length- 最长的词项的长度。avg_length- 所有词项的平均长度。entropy- 对聚合收集的所有术语计算的香农熵(Shannon Entropy)。 香农熵量化了字段中包含的信息量。 这是一个非常有用的度量,用于测量数据集的各种属性,如多样性、相似性、随机性等。
假设数据由 twitter 消息组成:
POST /twitter/_search?size=0
{
"aggs" : {
"message_stats" : { "string_stats" : { "field" : "message.keyword" } }
}
}
上面的聚合计算所有文档中 message 字段的字符串统计信息。 聚合类型是 string_stats,参数 field 定义了将计算统计数据的文档的字段。 上面的查询将返回以下内容:
{
...
"aggregations": {
"message_stats" : {
"count" : 5,
"min_length" : 24,
"max_length" : 30,
"avg_length" : 28.8,
"entropy" : 3.94617750050791
}
}
}
聚合的名称(上面的message_stats)也用作 key,通过它可以从返回的响应中检索聚合结果。
字符分布
香农熵(Shannon Entropy)的计算基于每个字符出现在聚合收集的所有词项中的概率。 要查看所有字符的概率分布,可以添加参数 show_distribution (默认值:false)。
POST /twitter/_search?size=0
{
"aggs" : {
"message_stats" : {
"string_stats" : {
"field" : "message.keyword",
"show_distribution": true
}
}
}
}
- 将参数
show_distribution设置为true,以便在结果中返回所有字符的概率分布。
{
...
"aggregations": {
"message_stats" : {
"count" : 5,
"min_length" : 24,
"max_length" : 30,
"avg_length" : 28.8,
"entropy" : 3.94617750050791,
"distribution" : {
" " : 0.1527777777777778,
"e" : 0.14583333333333334,
"s" : 0.09722222222222222,
"m" : 0.08333333333333333,
"t" : 0.0763888888888889,
"h" : 0.0625,
"a" : 0.041666666666666664,
"i" : 0.041666666666666664,
"r" : 0.041666666666666664,
"g" : 0.034722222222222224,
"n" : 0.034722222222222224,
"o" : 0.034722222222222224,
"u" : 0.034722222222222224,
"b" : 0.027777777777777776,
"w" : 0.027777777777777776,
"c" : 0.013888888888888888,
"E" : 0.006944444444444444,
"l" : 0.006944444444444444,
"1" : 0.006944444444444444,
"2" : 0.006944444444444444,
"3" : 0.006944444444444444,
"4" : 0.006944444444444444,
"y" : 0.006944444444444444
}
}
}
}
distribution 对象显示每个字符在所有词项中出现的概率。字符按概率降序排列。
脚本
基于脚本计算消息(message)的字符串统计信息:
POST /twitter/_search?size=0
{
"aggs" : {
"message_stats" : {
"string_stats" : {
"script" : {
"lang": "painless",
"source": "doc['message.keyword'].value"
}
}
}
}
}
这将把 script 参数解释为一个inline(内联) 脚本,使用 painless(无痛) 脚本语言,没有脚本参数。 要使用存储的脚本,请使用以下语法:
POST /twitter/_search?size=0
{
"aggs" : {
"message_stats" : {
"string_stats" : {
"script" : {
"id": "my_script",
"params" : {
"field" : "message.keyword"
}
}
}
}
}
}
值脚本(value script)
可以使用值脚本来修改消息(例如,我们可以添加前缀)并计算新的统计数据:
POST /twitter/_search?size=0
{
"aggs" : {
"message_stats" : {
"string_stats" : {
"field" : "message.keyword",
"script" : {
"lang": "painless",
"source": "params.prefix + _value",
"params" : {
"prefix" : "Message: "
}
}
}
}
}
}
缺失的值
参数 missing 定义应该如何处理有缺失值的文档。 默认情况下,它们会被忽略,但也可以将它们视为有一个(默认)值。
POST /twitter/_search?size=0
{
"aggs" : {
"message_stats" : {
"string_stats" : {
"field" : "message.keyword",
"missing": "[empty message]"
}
}
}
}
message字段中没有值的文档将被视为具有值[empty message]的文档。
sum 聚合
一个 single-value(单值) 度量聚合,对从聚合文档中提取的数值进行汇总。 这些值可以从文档中指定的 numeric 字段中提取,也可以由提供的脚本生成。
假设数据由代表销售记录的文档组成,可以用以下公式计算所有帽子的销售价格(hat_prices):
POST /sales/_search?size=0
{
"query" : {
"constant_score" : {
"filter" : {
"match" : { "type" : "hat" }
}
}
},
"aggs" : {
"hat_prices" : { "sum" : { "field" : "price" } }
}
}
结果是:
{
...
"aggregations": {
"hat_prices": {
"value": 450.0
}
}
}
聚合的名称(上面的hat_prices)也用作 key,通过它可以从返回的响应中检索聚合结果。
脚本
还可以使用一个脚本来获取销售价格:
POST /sales/_search?size=0
{
"query" : {
"constant_score" : {
"filter" : {
"match" : { "type" : "hat" }
}
}
},
"aggs" : {
"hat_prices" : {
"sum" : {
"script" : {
"source": "doc.price.value"
}
}
}
}
}
这将把 script 参数解释为一个inline(内联) 脚本,使用 painless(无痛) 脚本语言,没有脚本参数。 要使用存储的脚本,请使用以下语法:
POST /sales/_search?size=0
{
"query" : {
"constant_score" : {
"filter" : {
"match" : { "type" : "hat" }
}
}
},
"aggs" : {
"hat_prices" : {
"sum" : {
"script" : {
"id": "my_script",
"params" : {
"field" : "price"
}
}
}
}
}
}
值脚本(value script)
也可以使用_value从脚本中访问字段值。 例如,下面的查询计算所有帽子的价格平方的和:
POST /sales/_search?size=0
{
"query" : {
"constant_score" : {
"filter" : {
"match" : { "type" : "hat" }
}
}
},
"aggs" : {
"square_hats" : {
"sum" : {
"field" : "price",
"script" : {
"source": "_value * _value"
}
}
}
}
}
缺失的值
参数 missing 定义应该如何处理有缺失值的文档。 默认情况下,它们会被忽略,但也可以将它们视为有一个(默认)值。 例如,下面的查询将所有销售的不带价格的帽子的价格视为 100。
POST /sales/_search?size=0
{
"query" : {
"constant_score" : {
"filter" : {
"match" : { "type" : "hat" }
}
}
},
"aggs" : {
"hat_prices" : {
"sum" : {
"field" : "price",
"missing": 100
}
}
}
}
top_hits 聚合
top_hits 度量聚合器跟踪被聚集的最相关的文档。 这个聚合器被用作子聚合器,这样就可以对每个桶聚合最匹配的文档。
top_hits 聚合器可以有效地用于通过桶聚合器按特定字段对结果集进行分组。 一个或多个桶聚合器决定了将结果集划分到哪些属性中。
选项
from- 要获取的第一个结果的偏移量。size- 每个桶返回的最大匹配命中数。默认情况下,会返回前3个匹配项。sort- 命中应该如何排序。默认情况下,命中按主查询的得分排序。
per hit(单次命中支持的功能)
top_hits 聚合返回常规搜索命中,因为可以支持许多单次命中功能:
- 高亮 (highlighting)
- 解释 (explain)
- 命名过滤器和查询 (named filters and queries)
- 源过滤(source filtering)
- 存储的字段 (stored fields)
- 脚本字段(script fields)
- 文档值字段(doc value fields)
- 包含版本(include versions)
- 包含序列号和主词(include Sequence Numbers and Primary Terms)
如果你只需要docvalue_fields、size和sort,那么top_metrics 聚合可能是比 top_hits 聚合更有效率的选择。
示例
在下面的示例中,我们按类型对销售进行分组,并按类型显示最后一笔销售。 对于每笔销售,源中只包含日期和价格字段。
POST /sales/_search?size=0
{
"aggs": {
"top_tags": {
"terms": {
"field": "type",
"size": 3
},
"aggs": {
"top_sales_hits": {
"top_hits": {
"sort": [
{
"date": {
"order": "desc"
}
}
],
"_source": {
"includes": [ "date", "price" ]
},
"size" : 1
}
}
}
}
}
}
响应可能是:
{
...
"aggregations": {
"top_tags": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "hat",
"doc_count": 3,
"top_sales_hits": {
"hits": {
"total" : {
"value": 3,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "sales",
"_type": "_doc",
"_id": "AVnNBmauCQpcRyxw6ChK",
"_source": {
"date": "2015/03/01 00:00:00",
"price": 200
},
"sort": [
1425168000000
],
"_score": null
}
]
}
}
},
{
"key": "t-shirt",
"doc_count": 3,
"top_sales_hits": {
"hits": {
"total" : {
"value": 3,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "sales",
"_type": "_doc",
"_id": "AVnNBmauCQpcRyxw6ChL",
"_source": {
"date": "2015/03/01 00:00:00",
"price": 175
},
"sort": [
1425168000000
],
"_score": null
}
]
}
}
},
{
"key": "bag",
"doc_count": 1,
"top_sales_hits": {
"hits": {
"total" : {
"value": 1,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "sales",
"_type": "_doc",
"_id": "AVnNBmatCQpcRyxw6ChH",
"_source": {
"date": "2015/01/01 00:00:00",
"price": 150
},
"sort": [
1420070400000
],
"_score": null
}
]
}
}
}
]
}
}
}
字段折叠示例
字段折叠或结果分组是一项功能,它将结果集逻辑地分组,每个组返回前几个文档。 组的排序由组中第一个文档的相关性决定。 在 Elasticsearch 中,这可以通过将一个top_hits聚合器包裹为子聚合器的桶聚合器来实现。
在下面的例子中,我们搜索抓取的网页。 对于每个网页,我们存储网页的 body 及其所属的域(domain)。 通过在 domain 字段上定义一个 terms 聚合器,我们按照域对网页的结果集进行分组。 然后将 top_hits 聚合器定义为子聚合器,这样就可以收集每个桶的匹配命中的前几个。
此外,还定义了一个 max 聚合器,terms聚合器的排序特性使用该聚合器按照桶中最相关文档的相关性顺序返回桶。
POST /sales/_search
{
"query": {
"match": {
"body": "elections"
}
},
"aggs": {
"top_sites": {
"terms": {
"field": "domain",
"order": {
"top_hit": "desc"
}
},
"aggs": {
"top_tags_hits": {
"top_hits": {}
},
"top_hit" : {
"max": {
"script": {
"source": "_score"
}
}
}
}
}
}
}
目前,需要max(或min)聚合器来确保来自terms聚合器的桶根据每个域的最相关网页的分数排序。 不幸的是,top_hits聚合器还不能用于terms 聚合器的order选项。
嵌套或反向嵌套聚合器中对 top_hits 的支持
如果 top_hits 聚合器包裹在嵌套(nested)或反嵌套(reverse_nested)聚合器中,则返回嵌套的命中。 嵌套的命中在某种意义上是隐藏的迷你文档,它们是常规文档的一部分,其中在映射中已经配置了嵌套字段类型。 如果 top_hits 聚合器被包装在nested或reverse_nested聚合器中,那么它能够取消隐藏这些文档。 了解有关嵌套类型映射中嵌套的更多信息。
如果已经配置了嵌套类型,那么单个文档实际上被索引为多个 Lucene 文档,并且它们共享相同的 id。 为了确定嵌套命中的身份,需要的不仅仅是 id,这就是为什么嵌套命中还包括它们的嵌套身份。 嵌套标识保存在搜索命中的_nested字段下,并且包括嵌套命中所属的数组字段和数组字段中的偏移量。 偏移量从零开始。
让我们用一个例子来看看它是如何工作的。比如下面这个映射:
PUT /sales
{
"mappings": {
"properties" : {
"tags" : { "type" : "keyword" },
"comments" : {
"type" : "nested",
"properties" : {
"username" : { "type" : "keyword" },
"comment" : { "type" : "text" }
}
}
}
}
}
comments是一个数组,它保存product对象下的嵌套文档。
并添加几个文档:
PUT /sales/_doc/1?refresh
{
"tags": ["car", "auto"],
"comments": [
{"username": "baddriver007", "comment": "This car could have better brakes"},
{"username": "dr_who", "comment": "Where's the autopilot? Can't find it"},
{"username": "ilovemotorbikes", "comment": "This car has two extra wheels"}
]
}
现在可以执行下面的 top_hits 聚合(包裹在一个 nested 聚合中):
POST /sales/_search
{
"query": {
"term": { "tags": "car" }
},
"aggs": {
"by_sale": {
"nested" : {
"path" : "comments"
},
"aggs": {
"by_user": {
"terms": {
"field": "comments.username",
"size": 1
},
"aggs": {
"by_nested": {
"top_hits":{}
}
}
}
}
}
}
}
具有嵌套命中的前几个命中响应片段,位于数组字段 comments 的第一个槽中:
{
...
"aggregations": {
"by_sale": {
"by_user": {
"buckets": [
{
"key": "baddriver007",
"doc_count": 1,
"by_nested": {
"hits": {
"total" : {
"value": 1,
"relation": "eq"
},
"max_score": 0.3616575,
"hits": [
{
"_index": "sales",
"_type" : "_doc",
"_id": "1",
"_nested": {
"field": "comments",
"offset": 0
},
"_score": 0.3616575,
"_source": {
"comment": "This car could have better brakes",
"username": "baddriver007"
}
}
]
}
}
}
...
]
}
}
}
}
- 包含嵌套命中的数组字段的名称
- 嵌套命中包含数组时的位置
- 嵌套命中的源
如果请求_source,则只返回嵌套对象的部分源,而不是文档的整个源。 nested 内部对象级别上的存储字段也可以通过驻留 在nested或reverse_nested聚合器中的top_hits聚合器来访问。
只有嵌套命中才会在命中中有_nested字段,非嵌套(常规)命中不会有_nested字段。
如果没有启用_source,那么_nested中的信息也可以用来解析其他地方的原始源。
如果在映射中定义了多级嵌套对象类型,那么_nested信息也可以是分层的,以便表达两层或更多层的嵌套命中的身份。
在下面的示例中,嵌套命中驻留在字段nested_grand_child_field的第一个槽中,然后驻留在nested_child_field字段的第二个槽中:
...
"hits": {
"total" : {
"value": 2565,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "a",
"_type": "b",
"_id": "1",
"_score": 1,
"_nested" : {
"field" : "nested_child_field",
"offset" : 1,
"_nested" : {
"field" : "nested_grand_child_field",
"offset" : 0
}
}
"_source": ...
},
...
]
}
...
top_metrics(最顶端的度量聚合)
top_metrics 聚合从文档中选择具有最大或最小 "sort"(排序) 值的度量。 下面的例子将获得文档中具有最大值 s 的文档的 m 字段的值:
POST /test/_bulk?refresh
{"index": {}}
{"s": 1, "m": 3.1415}
{"index": {}}
{"s": 2, "m": 1.0}
{"index": {}}
{"s": 3, "m": 2.71828}
POST /test/_search?filter_path=aggregations
{
"aggs": {
"tm": {
"top_metrics": {
"metrics": {"field": "m"},
"sort": {"s": "desc"}
}
}
}
}
它将返回:
{
"aggregations": {
"tm": {
"top": [ {"sort": [3], "metrics": {"m": 2.718280076980591 } } ]
}
}
}
top_metrics 在本质上与 top_hits 非常相似,但是因为对它的限制更多,所以它能够使用更少的内存来完成工作,并且通常更快。
sort
度量请求中的 sort 字段与 search 请求中的 sort 字段功能完全相同,除了: * 它不能用于 binary、flattened、ip、keyword 和 text 字段。 * 它只支持单个 排序(sort) 值,因此当排序值相同时无法区分哪个在前。
聚合返回的度量是搜索请求返回的第一个命中结果。因此,
"sort": {"s": "desc"}
从具有最大s值的文档中获取度量"sort": {"s": "asc"}
从具有最小s值的文档中获取度量"sort": {"_geo_distance": {"location": "35.7796, -78.6382"}}
从location(位置) 最接近35.7796, -78.6382的文档中获取度量"sort": "_score"
从相关性评分最高的文档中获取度量
metrics
metrics 选择要从"最顶端(top)"的文档返回的字段。 可以使用类似 "metric": {"field": "m"} 什么的来请求单个度量,或者通过使用类似 "metric": [{"field": "m"}, {"field": "i"} 的度量列表来请求多个度量。 下面是一个更完整的例子:
PUT /test
{
"mappings": {
"properties": {
"d": {"type": "date"}
}
}
}
POST /test/_bulk?refresh
{"index": {}}
{"s": 1, "m": 3.1415, "i": 1, "d": "2020-01-01T00:12:12Z"}
{"index": {}}
{"s": 2, "m": 1.0, "i": 6, "d": "2020-01-02T00:12:12Z"}
{"index": {}}
{"s": 3, "m": 2.71828, "i": -12, "d": "2019-12-31T00:12:12Z"}
POST /test/_search?filter_path=aggregations
{
"aggs": {
"tm": {
"top_metrics": {
"metrics": [
{"field": "m"},
{"field": "i"},
{"field": "d"}
],
"sort": {"s": "desc"}
}
}
}
}
它返回:
{
"aggregations": {
"tm": {
"top": [ {
"sort": [3],
"metrics": {
"m": 2.718280076980591,
"i": -12,
"d": "2019-12-31T00:12:12.000Z"
}
} ]
}
}
}
size
top_metrics 可以使用 size 参数返回前几个文档的度量值:
POST /test/_bulk?refresh
{"index": {}}
{"s": 1, "m": 3.1415}
{"index": {}}
{"s": 2, "m": 1.0}
{"index": {}}
{"s": 3, "m": 2.71828}
POST /test/_search?filter_path=aggregations
{
"aggs": {
"tm": {
"top_metrics": {
"metrics": {"field": "m"},
"sort": {"s": "desc"},
"size": 3
}
}
}
}
它将返回:
{
"aggregations": {
"tm": {
"top": [
{"sort": [3], "metrics": {"m": 2.718280076980591 } },
{"sort": [2], "metrics": {"m": 1.0 } },
{"sort": [1], "metrics": {"m": 3.1414999961853027 } }
]
}
}
}
size 的默认值是 1。 size 的最大值默认是 10,因为聚合的工作存储是“密集的”,这意味着我们为每个桶分配 size 大小的槽。 10 是一个非常保守的默认最大值,如果你需要,可以通过更改索引设置 top_metrics_max_size 来提高该值。 但是你要知道,更大的 size 值会占用相当多的内存,特别是如果它们在一个会生成很多桶的聚合中,比如一个很大的 terms 聚合。 如果你仍然想提高它,类似这样操作:
PUT /test/_settings
{
"top_metrics_max_size": 100
}
如果 size 大于 1,top_metrics 聚合不能用作排序的目标。
示例
和 terms 一起使用
这种聚合在 terms 聚合 内部应该非常有用,比如说,要找到每个服务器报告的最后一个值。
PUT /node
{
"mappings": {
"properties": {
"ip": {"type": "ip"},
"date": {"type": "date"}
}
}
}
POST /node/_bulk?refresh
{"index": {}}
{"ip": "192.168.0.1", "date": "2020-01-01T01:01:01", "m": 1}
{"index": {}}
{"ip": "192.168.0.1", "date": "2020-01-01T02:01:01", "m": 2}
{"index": {}}
{"ip": "192.168.0.2", "date": "2020-01-01T02:01:01", "m": 3}
POST /node/_search?filter_path=aggregations
{
"aggs": {
"ip": {
"terms": {
"field": "ip"
},
"aggs": {
"tm": {
"top_metrics": {
"metrics": {"field": "m"},
"sort": {"date": "desc"}
}
}
}
}
}
}
它返回:
{
"aggregations": {
"ip": {
"buckets": [
{
"key": "192.168.0.1",
"doc_count": 2,
"tm": {
"top": [ {"sort": ["2020-01-01T02:01:01.000Z"], "metrics": {"m": 2 } } ]
}
},
{
"key": "192.168.0.2",
"doc_count": 1,
"tm": {
"top": [ {"sort": ["2020-01-01T02:01:01.000Z"], "metrics": {"m": 3 } } ]
}
}
],
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0
}
}
}
与 top_hits 不同的是,可以根据此度量的结果对桶进行排序:
POST /node/_search?filter_path=aggregations
{
"aggs": {
"ip": {
"terms": {
"field": "ip",
"order": {"tm.m": "desc"}
},
"aggs": {
"tm": {
"top_metrics": {
"metrics": {"field": "m"},
"sort": {"date": "desc"}
}
}
}
}
}
}
它返回:
{
"aggregations": {
"ip": {
"buckets": [
{
"key": "192.168.0.2",
"doc_count": 1,
"tm": {
"top": [ {"sort": ["2020-01-01T02:01:01.000Z"], "metrics": {"m": 3 } } ]
}
},
{
"key": "192.168.0.1",
"doc_count": 2,
"tm": {
"top": [ {"sort": ["2020-01-01T02:01:01.000Z"], "metrics": {"m": 2 } } ]
}
}
],
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0
}
}
}
混合的排序类型
按不同索引中具有不同类型的字段对 top_metrics 进行排序会产生一些意想不到的结果:浮点型字段总是独立于整型字段进行排序。
# 插入的文档的m字段的值有浮点型,也有整型
POST /test/_bulk?refresh
{"index": {"_index": "test1"}}
{"s": 1, "m": 3.1415}
{"index": {"_index": "test1"}}
{"s": 2, "m": 1}
{"index": {"_index": "test2"}}
{"s": 3.1, "m": 2.71828}
#搜索
POST /test*/_search?filter_path=aggregations
{
"aggs": {
"tm": {
"top_metrics": {
"metrics": {"field": "m"},
"sort": {"s": "asc"}
}
}
}
}
它返回:
{
"aggregations": {
"tm": {
"top": [ {"sort": [3.0999999046325684], "metrics": {"m": 2.718280076980591 } } ]
}
}
}
虽然这比返回一个错误要好,但它可能不是你想要的。 虽然它确实损失了一些精度,但是你可以使用类似下面的代码将整个数值字段显式地转换为浮点型:
POST /test*/_search?filter_path=aggregations
{
"aggs": {
"tm": {
"top_metrics": {
"metrics": {"field": "m"},
"sort": {"s": {"order": "asc", "numeric_type": "double"}}
}
}
}
}
它返回的数据与我们期望的更接近:
{
"aggregations": {
"tm": {
"top": [ {"sort": [1.0], "metrics": {"m": 3.1414999961853027 } } ]
}
}
}
value_count(值数量聚合)
一个 single-value(单值) 度量聚合,计算从聚合文档中提取的值的数量。 这些值可以从文档的指定字段中提取,也可以由提供的脚本生成。 通常,此聚合器将与其他单值聚合一起使用。 例如,在计算 avg(平均值) 时,人们可能会对计算平均值的值的数量感兴趣。
POST /sales/_search?size=0
{
"aggs" : {
"types_count" : { "value_count" : { "field" : "type" } }
}
}
响应为:
{
...
"aggregations": {
"types_count": {
"value": 7
}
}
}
聚合的名称(上面的 types_count)也用作 key,通过它可以从返回的响应中检索聚合结果。
script (脚本)
计算脚本生成的值:
POST /sales/_search?size=0
{
"aggs" : {
"type_count" : {
"value_count" : {
"script" : {
"source" : "doc['type'].value"
}
}
}
}
}
这将把 script 参数解释为一个 inline(内联) 脚本,使用 painless(无痛) 脚本语言,没有脚本参数。 要使用存储的脚本,请使用以下语法:
POST /sales/_search?size=0
{
"aggs" : {
"types_count" : {
"value_count" : {
"script" : {
"id": "my_script",
"params" : {
"field" : "type"
}
}
}
}
}
}