简述
我们想象一下:
自来水厂到你家的水管网是一个复杂的有向图,每一节水管都有一个最大承载流量。
水厂不放水,你家就断水了。但是就算水厂拼命的往管网里面注水,你家收到的水流量也有上限(毕竟每根水管承载量有限)。
你想知道你能够拿到多少水,这就是一种最大流问题。
有一个汇点(你家),一个源点(自来水厂),和若干的边(管道),水一定是从汇点流向源点。
最大流就是要最大化到你家(汇点)的流量。
本文中,我们用 \(f(u, v)\) 表示 \((u, v)\) 边上的流量,\(c(u, v)\) 表示 \((u, v)\) 边上的上限,\(c_f(u, v) = c(u, v) - f(u, v)\)。
Ford-Fulkerson 增广
Ford-Fulkerson 增广是计算最大流的一类算法的总称。
该方法运用贪心的思想,通过寻找增广路来更新并求解最大流。
概述
我们引入一个概念:增广路。
在这里,我们称一条从源点到汇点的路就是一条增广路。
现在对于上面的那个问题,有个暴力的想法:
随便找增广路,然后给路径上的每条边减去最小的流量(这条路上上限最小的权值)。
而我们将这个操作叫增广挺奇怪的名字。
那么求解的过程就可以看成好多次增广的流量之和了。
但如果只是单纯的这样明显很随机。
还记得反悔贪心吗?我们也可以给它增加一个反悔操作。
我们给每条边都加一个反边,在增广减去原边的流量的时候,我们给反边增加上这个流量。
当我们在反边上增广的时候,我们会和之前的流量抵消,那么就是在反悔。
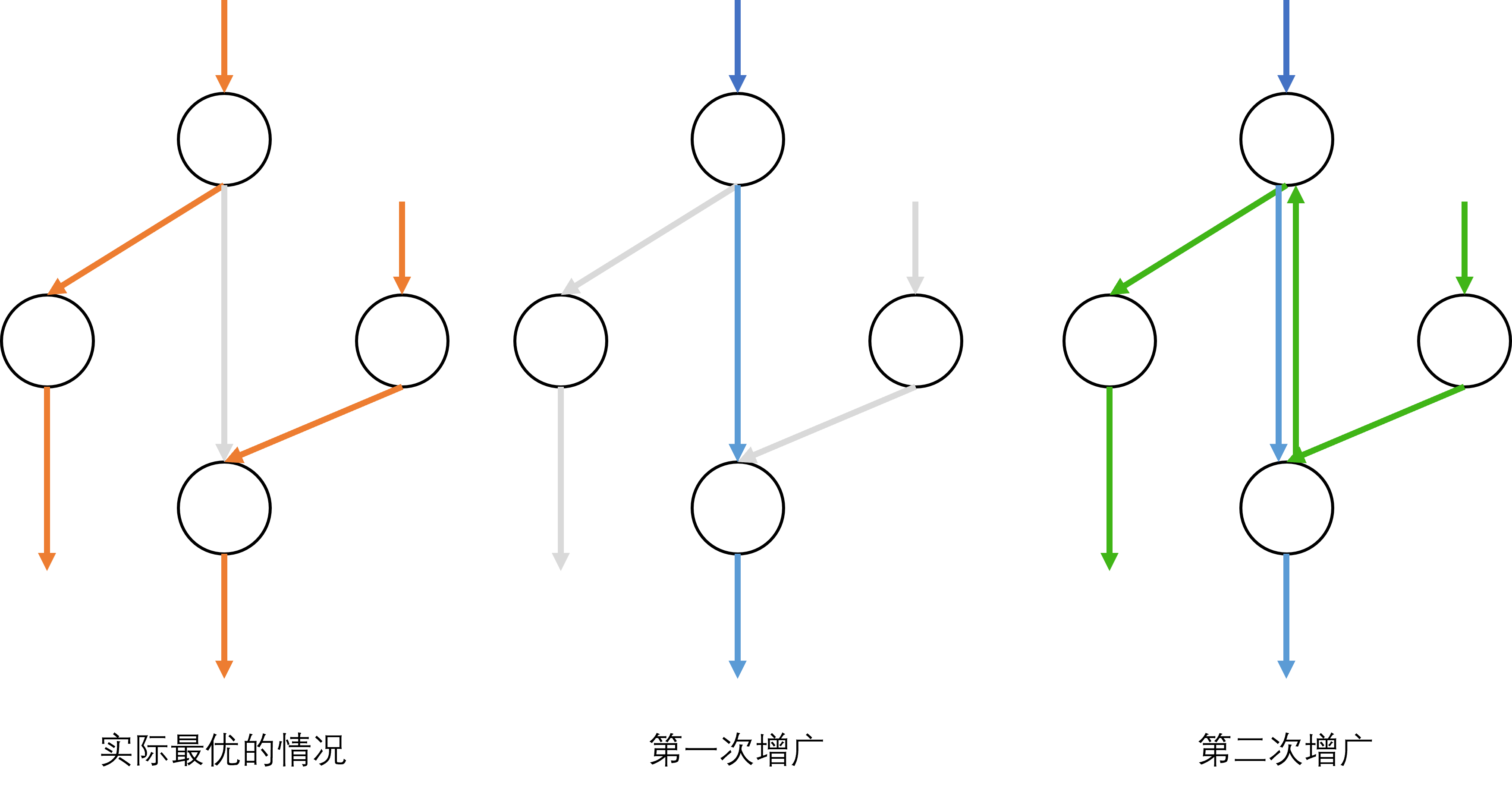
在下面那张图中,第一种和第三种其实是等价的。
灰色是没有流量的边。
实现提示:
在代码实现时,我们往往需要支持快速访问反向边的操作。
一个优秀的方法是用链式前向星。
我们让第一条边从偶数开始(我的是 \(2\)),在插入边的时候将反边紧贴的插入。
那么第 \(i\) 条边的反边编号就是 \(i \oplus 1\) 了。
在实现中,我们不会记录它的最大流量,我们之后记录它的剩余流量。
正确性证明
我们大致了解了 Ford–Fulkerson 增广的思想,可是如何证明这一方法的正确性呢?
实际上,Ford–Fulkerson 增广的正确性和最大流最小割定理(The Maxflow-Mincut Theorem)等价。
这一定理指出,对于任意网络 \(G = (V, E)\),其最大流 \(f\) 和最小割 \(\{S, T\}\) 总是满足 \(\left|f\right| = \left\| S, T\right\|\)。
割的含义:
对于图 \(G=(V,E)\),将所有的点划分为 \(S\) 和 \(T=V\setminus S\) 两个集合,其中源点 \(s\in S\),汇点 \(t\in T\)。
而 \(\left\| S,T\right\| = \sum_{u\in S}\sum_{v\in T}c(u, v)\)。
为了证明最大流最小割定理,我们先从一个引理出发:
对于网络 \(G = (V, E)\),任取一个流 \(f\) 和一个割 \(\{S, T\}\),总是有 \(\left|f\right| \leq \left\| S, T\right\|\)。
其中等号成立当且仅当 \(\{(u, v) | u \in S, v \in T\}\) 的所有边均满流,且 \(\{(u, v) | u \in T, v \in S\}\) 的所有边均空流。
引理的证明:
\[\begin{aligned} \left|f\right| & = \sum_{u \in S} f(u) \\ & = \sum_{u \in S} \left( \sum_{v \in V} f(u, v) - \sum_{v \in V} f(v, u) \right) \\ & = \sum_{u \in S} \left( \sum_{v \in T} f(u, v) + \sum_{v \in S} f(u, v) - \sum_{v \in T} f(v, u) - \sum_{v \in S} f(v, u) \right) \\ & = \sum_{u \in S} \left( \sum_{v \in T} f(u, v) - \sum_{v \in T} f(v, u) \right) + \sum_{u \in S} \sum_{v \in S} f(u, v) - \sum_{u \in S} \sum_{v \in S} f(v, u) \\ & = \sum_{u \in S} \left( \sum_{v \in T} f(u, v) - \sum_{v \in T} f(v, u) \right) \\ & \leq \sum_{u \in S} \sum_{v \in T} f(u, v) \\ & \leq \sum_{u \in S} \sum_{v \in T} c(u, v) \\ & = \left\| S, T\right\| \\ \end{aligned} \]为了取等,第一个不等号需要 \(\{(u, v) \mid u \in T, v \in S\}\) 的所有边均空流。
第二个不等号需要 \(\{(u, v) \mid u \in S, v \in T\}\) 的所有边均满流。
原引理得证。
那么,对于任意网络,以上取等条件是否总是能被满足呢?如果答案是肯定的,则最大流最小割定理得证。
证明:
假设某一轮增广后,我们得到流 \(f\) 使得 \(G\) 上不存在增广路,即 \(G\) 上不存在 \(s\) 到 \(t\) 的路径。
此时我们记从 \(s\) 出发可以到达的结点组成的点集为 \(S\),并记 \(T = V \setminus S\)。
显然,\(\{S, T\}\) 是 G 的一个割,且 \(\left\| S, T\right\| = \sum_{u \in S} \sum_{v \in T} c_f(u, v) = 0\)。
由于剩余容量是非负的,这也意味着对于任意 \(u \in S, v \in T, (u, v) \in E_f\),均有 \(c_f(u, v) = 0\)。
以下我们将这些边分为存在于原图中的边和反向边两种情况讨论:
\((u, v) \in E\):此时,\(c_f(u, v) = c(u, v) - f(u, v) = 0\),因此有 \(c(u, v) = f(u, v)\),即 \(\{(u, v) \mid u \in S, v \in T\}\) 的所有边均满流;
\((v, u) \in E\):此时,\(c_f(u, v) = c(u, v) - f(u, v) = 0 - f(u, v) = f(v, u) = 0\),即 \(\{(v, u) \mid u \in S, v \in T\}\) 的所有边均空流。
因此,增广停止后,上述流 \(f\) 满足取等条件。
根据引理指出的大小关系,自然地,\(f\) 是 \(G\) 的一个最大流,\(\{S, T\}\) 是 \(G\) 的一个最小割。
时间复杂度
我们可以简单的认为是 \(O(m\left|f\right|)\) 的。
\(m\) 表示总边数,\(\left|f\right|\) 表示图中的最大流。
因为每次增广肯定会使总流量增加,最多是 \(\left|f\right|\) 次,而每次增广复杂度为 \(O(m)\)。
当然,不同的实现,复杂度也是大相径庭。
接下来介绍主流的 \(4\) 种算法实现。
EK
我们用 BFS 从 \(s\) 到 \(t\) 找到新的增广路 \(p\)。
我们取 \(\Delta = min_{(u, v) \in p} c_f(u, v)\),然后对路径上的边的剩余流量减 \(\Delta\),其反边加 \(\Delta\)。
重复这个操作,直到没有增广路为止。
BFS 轮数的上限是 \(O(nm)\) 的,每轮是 \(O(m)\) 的。
所以 EK 的时间复杂度是 \(O(nm^2)\)。
具体证明见 oi-wiki。
//3376 会 TLE
#include<bits/stdc++.h>
using namespace std;
#define endl '\n'
#define FL(a, b, c) for(int a = (b), a##end = (c); a <= a##end; a++)
#define FR(a, b, c) for(int a = (b), a##end = (c); a >= a##end; a--)
#define lowbit(x) ((x) & -(x))
#define eb emplace_back
#define int long long
constexpr int N = 1e6 + 10;
int n, m, s, t, head[N], tot = 1, inq[N];
struct edge{
int v, nxt, w;
}e[N];
struct p{
int edge, x;
}pre[N];
void add(int u, int v, int w){
e[++tot] = {v, head[u], w}, head[u] = tot;
e[++tot] = {u, head[v], 0}, head[v] = tot;
}
bool bfs(){
memset(inq, 0, sizeof inq);
memset(pre, 0, sizeof pre);
queue<int>q;
q.emplace(s), inq[s] = 1;
while(!q.empty()){
for(int x = q.front(), i = head[x], v; i; i = e[i].nxt)
if(e[i].w && !inq[v = e[i].v]){
inq[v] = 1, pre[v].x = x, pre[v].edge = i;
if(v == t)return 1;
q.emplace(v);
}
q.pop();
}
return 0;
}
int EK(){
int ans = 0;
while(bfs()){
int mi = 1e10;
for(int i = t; i != s; i = pre[i].x)mi = min(mi, e[pre[i].edge].w);
for(int i = t; i != s; i = pre[i].x)e[pre[i].edge].w -= mi, e[pre[i].edge ^ 1].w += mi;
ans += mi;
}
return ans;
}
int32_t main(){
cin.tie(0)->sync_with_stdio(0);
int u, v, w;
cin >> n >> m >> s >> t;
while(m--)cin >> u >> v >> w, add(u, v, w);
cout << EK();
return 0;
}
Dinic
先用 BFS 从 \(s\) 到 \(t\) 分层。
然后用 DFS 找增广路,并且经过 \(u\) 的流量只能往其下一层流。
重复这个操作,直到 BFS 不能到 \(t\) 为止。
我们注意 DFS 的过程。
如果有出题人故意给 \(u\) 放一堆边,还经常让你经过 \(u\),这样的复杂度就假了,那么就需要优化。
我们多用一个 \(now\) 数组,记录 \(u\) 上一次遍历到的最后一条边,我们就从这条边开始重新遍历。
这是因为,前面的边 \((u, v)\) 一定是流满的(否则不会遍历下一条边),我们就不用尝试了。
这个优化的方式叫当前弧优化,前面说了没有当前弧优化的 Dinic 的复杂度是假的。
我们看这张图(点中是层数,黑边是原边,蓝边是反边):
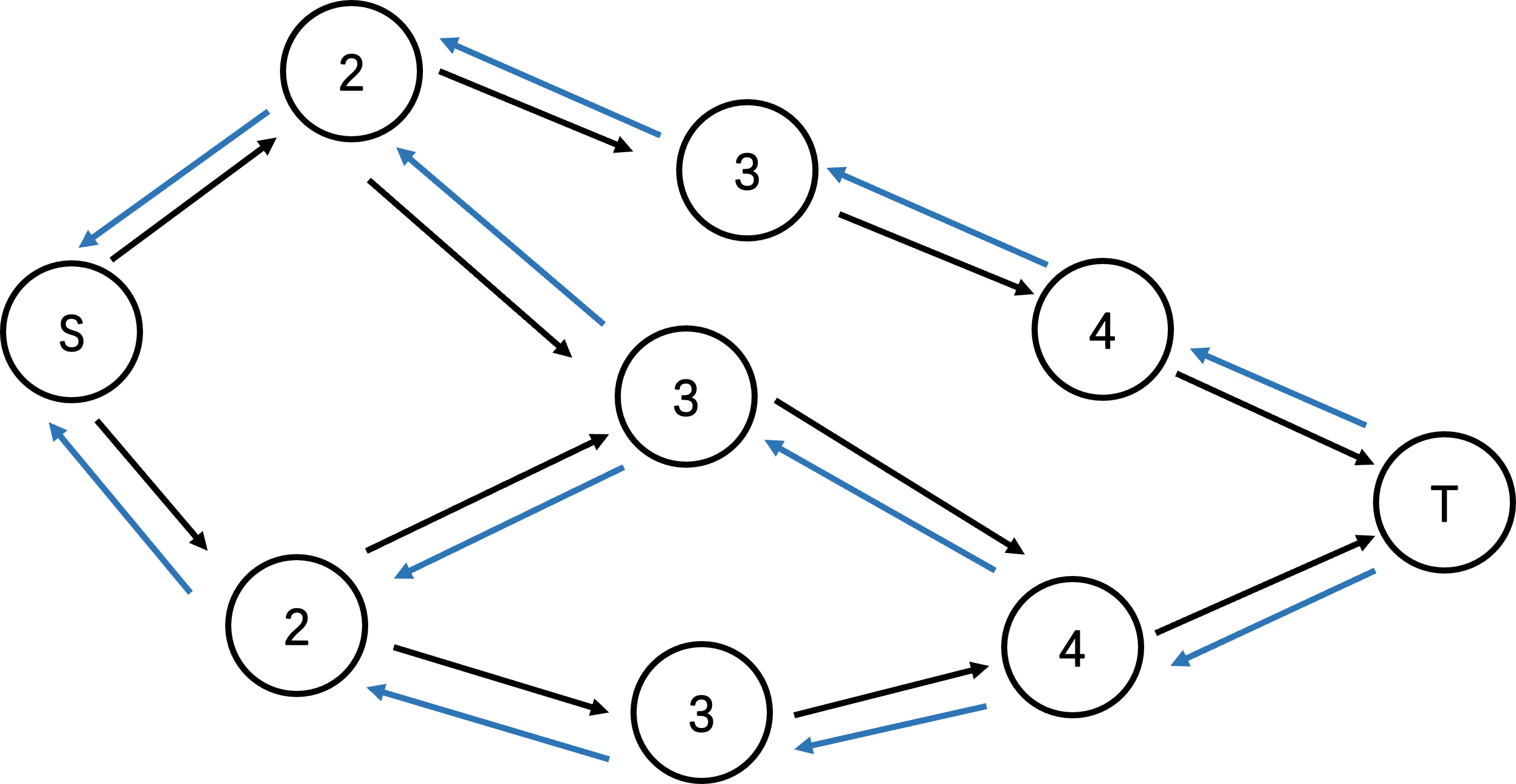
我们现在要找增广路:
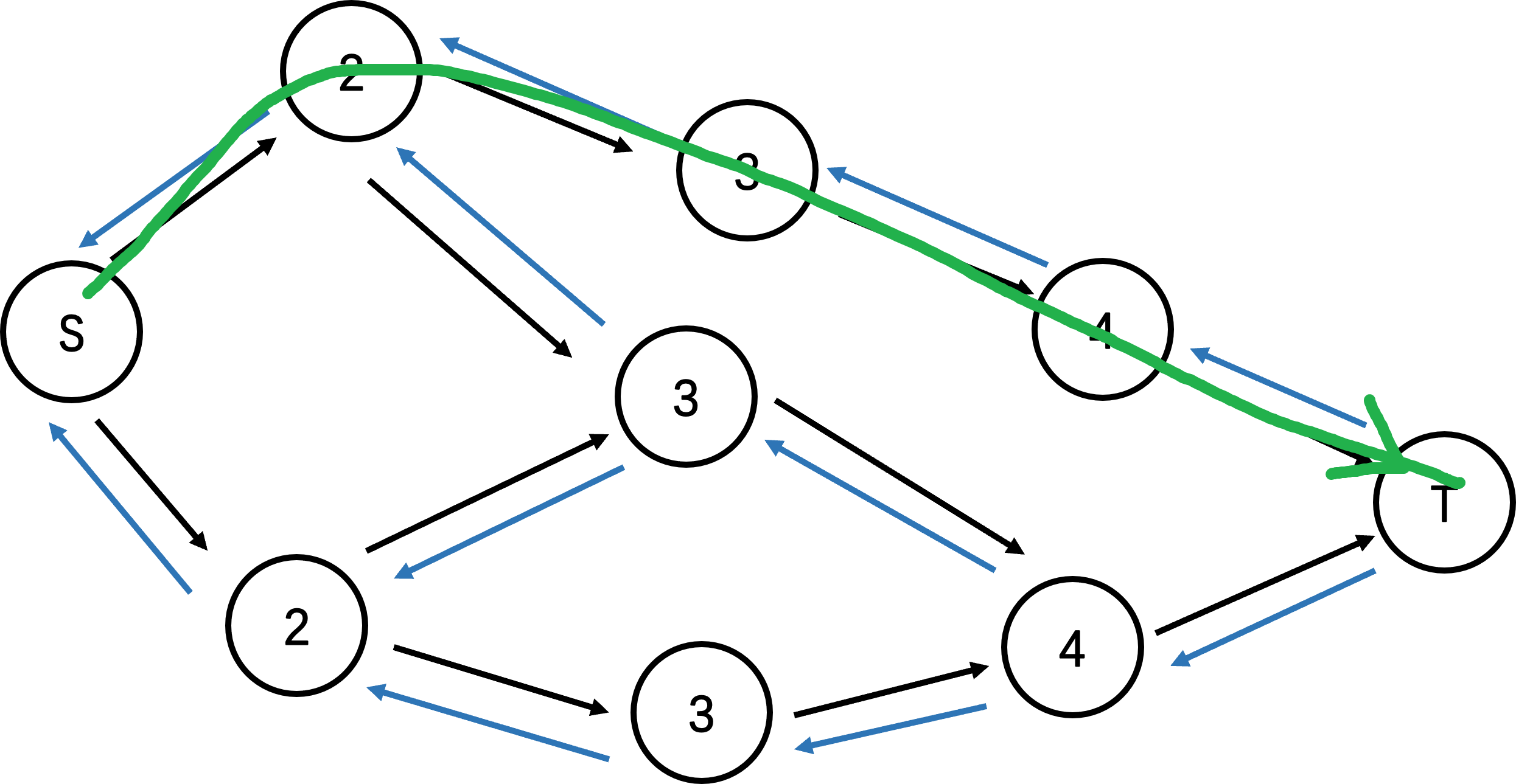
其实仔细看,我们还能看到好几条增广路,而我们现在的层数也能接着使用。
如果直接重新 BFS 就太浪费了,那么我们可以利用 DFS 回溯的性质,一次找好几条路。
这就是多路增广,当然,这只是常数优化。
在单轮 DFS 的时间复杂度是 \(O(nm)\),最多有 \(n\)。
所以在一般情况是 \(O(n^2m)\) 的一般卡不满。
而要是所有边的容量都是 \(1\),我们称这个图 \(G\) 是单位容量的。
在单位容量的网络中,Dinic 的单轮复杂度是 \(O(m)\) 的,最多有 \(\min(m^{\frac{1}{2}}, n^{\frac{2}{3}})\) 轮。
如果除源汇点外每个结点 \(u\) 都满足出度或入度为 \(1\),则 Dinic 算法的增广轮数是 \(O(n^{\frac{1}{2}})\)。
具体的证明见 oi-wiki。
//P3376
#include<bits/stdc++.h>
using namespace std;
#define endl '\n'
#define FL(a, b, c) for(int a = (b), a##end = (c); a <= a##end; a++)
#define FR(a, b, c) for(int a = (b), a##end = (c); a >= a##end; a--)
#define lowbit(x) ((x) & -(x))
#define eb emplace_back
#define int long long
constexpr int N = 2100;
struct edge{
int v, nxt, w;
}e[500000];
int tot = 1, head[N], dis[N], t, s, now[N], ans;
void add(int u, int v, int w){//加入原边和反边
e[++tot] = {v, head[u], w}, head[u] = tot;
e[++tot] = {u, head[v], 0}, head[v] = tot;
}
bool bfs(){
memset(dis, 0, sizeof dis);
queue<int>q;
q.emplace(s), dis[s] = 1;
while(!q.empty()){
for(int x = q.front(), i = (now[x] = head[x]), v; i; i = e[i].nxt)
if(e[i].w && !dis[v = e[i].v])dis[v] = dis[x] + 1, q.emplace(v);
q.pop();
}
return dis[t];
}
int dfs(int x, int last){
if(x == t)return last;
int res = last, k;
for(int i = now[x], v; i && res; i = e[i].nxt)
if(e[now[x] = i].w && (dis[v = e[i].v] == dis[x] + 1))
if(k = dfs(v, min(res, e[i].w)))e[i].w -= k, e[i ^ 1].w += k, res -= k;
else dis[v] = 0;//满流剪枝
return last - res;
}
int32_t main(){
cin.tie(0)->sync_with_stdio(0);
int n, m, u, v;
long long w;
cin >> n >> m >> s >> t;
while(m--)cin >> u >> v >> w, add(u, v, w);
while(bfs())ans += dfs(s, 1e10);
cout << ans << endl;
return 0;
}
MPM
MPM 和 Dinic 其他过程是相似的。
但是 MPM 的单轮的复杂度是 \(O(n^2)\) 的。
MPM 算法需要考虑顶点而不是边的容量。
在分层网络 \(G\) 中,如果定义点 \(v\) 的容量 \(p(v)\) 为其传入残量和传出残量的最小值,则有:
我们称节点 \(u\) 是参考节点当且仅当 \(p(u) = \min{p(v)}\)。
对于一个参考节点 \(u\),我们一定可以让经过 \(u\) 的流量增加 \(p(u)\) 以使其容量变为 \(0\)。
所以我们一定能找到一条从 \(s\) 经过 \(u\) 到达 \(t\) 的有向路径。那么我们让这条路上的边流量都增加 \(p(u)\) 即可。
这条路即为这一阶段的增广路,寻找增广路可以用 BFS。
增广完之后所有满流边都可以从 G 中删除,因为它们不会在此阶段后被使用。
同样,所有与 \(s\) 和 \(t\) 不同且没有出边或入边的节点都可以删除。
ISAP
在 Dinic 中,我们要跑多次 BFS,ISAP 就是减少了 BFS 的次数。
我们 BFS 从 \(t\) 到 \(s\) 做分层,在每次增广的时候只选择层数少一的节点。
接下来不一样的是,在 ISAP 中,我们在 DFS 的时候就会重新处理分层。
我们每次将增广路上流满的点的层数加一,当 \(s\) 点的层数 \(> n\) 的时候就可以结束了。
相似的,ISAP 也有当前弧优化,和多路增广。
另外,ISAP 还有一个的 GAP 优化。
我们记录层数为 \(i\) 的数量为 \(num_i\),当 \(num_i = 0\) 的时候意味着图中有了断层,也就可以直接结束了。
//3376
#include<bits/stdc++.h>
using namespace std;
#define endl '\n'
#define FL(a, b, c) for(int a = (b), a##end = (c); a <= a##end; a++)
#define FR(a, b, c) for(int a = (b), a##end = (c); a >= a##end; a--)
#define lowbit(x) ((x) & -(x))
#define eb emplace_back
#define int long long
constexpr int N = 21000;
struct edge{
int v, nxt, w;
}e[500000];
int tot = 1, head[N], dis[N], t, s, now[N], num[N], ans, n;
void add(int u, int v, int w){
e[++tot] = {v, head[u], w}, head[u] = tot;
e[++tot] = {u, head[v], 0}, head[v] = tot;
}
void bfs(){
memset(dis, 0, sizeof dis);
queue<int>q;
q.emplace(t), num[dis[t] = 1]++;
//从 t 到 s。
while(!q.empty()){
for(int x = q.front(), i = head[x], v; i; i = e[i].nxt)
if(!dis[v = e[i].v])
num[dis[v] = dis[x] + 1]++, q.emplace(v);
q.pop();
}
}
int dfs(int x, int last){
if(x == t)return last;
int res = last, k;
for(int i = now[x], v; i && res; i = e[i].nxt)
if(e[now[x] = i].w && (dis[v = e[i].v] + 1 == dis[x]))
if(k = dfs(v, min(res, e[i].w)))
e[i].w -= k, e[i ^ 1].w += k, res -= k;
if(!res)return last;
//更改层级
if(!--num[dis[x]])dis[s] = n + 1;
return num[++dis[x]]++, last - res;
}
int32_t main(){
cin.tie(0)->sync_with_stdio(0);
int m, u, v, w;
cin >> n >> m >> s >> t;
while(m--)cin >> u >> v >> w, add(u, v, w);
bfs();
while(dis[s] <= n)memcpy(now, head, sizeof head), ans += dfs(s, 1e15);
//记得将 now 数组重新赋值。
cout << ans << endl;
return 0;
}
Push-Relabel 预流推进算法
概述
我们换一种思路:
让源点拼命放水,再看看能流到汇点有多少水就好了。
我们允许每个节点都有一个水库,这些储存在非汇原点的水流叫超额流。
同时伺机将自己的超额流推送出去,最算法结束时会让除汇源点外的节点都没有超额流。
相似的,这里也需要反边,进行反悔操作。
为了避免两个节点来回推送,我们像现实的水一样:向低处流。
我们给每个节点定义高度,只允许高的节点向低的节点流。
如果一个节点不能再推送超额流,我们需要给这个节点的高度抬高(重贴标签)。
总结一下:
接下来,\(h_u\) 表示 \(u\) 的高度,\(c_u\) 表示 \(u\) 的超额流。
先将所有的节点的高度设为 \(0\),\(h_s\) 设为 \(n\),并将其所有边流满推送出去。
接着,我们将还有超额流的节点放进一个优先队列中,以高度排序。
每次找到最高的节点 \(u\),检查 \(u\) 的所有有流量的出边 \((u, v)\),满足 \(h_v = h_u - 1\)。
然后在超额流足够的情况下,尽可能的流满 \((u, v)\),如果 \(v\) 不在队列,就将它放入队列。
如果推送结束后还有超额流,设有流量的边 \((u, v)\),我们使 \(h_x = min(h_v) + 1\),并重新放入队列。
HLPP
上面的算法虽然正确,但上限较紧,在随机数据下比较吃亏,还需要优化。
显然,我们可以像增广路算法一样,提前进行一次 BFS,来减少重贴标签的次数(\(h_s\) 依然是 \(n\))。
我们也记录一下对每个 \(i h_u = i\) 的数量 \(num_i\),如果 \(num_i = 0\) 说明所有 \(h_u > i\) 的节点都到不了 \(t\) 了,我们将 \(h_u\) 设为 \(n + 1\),让它流回源点。
图解:
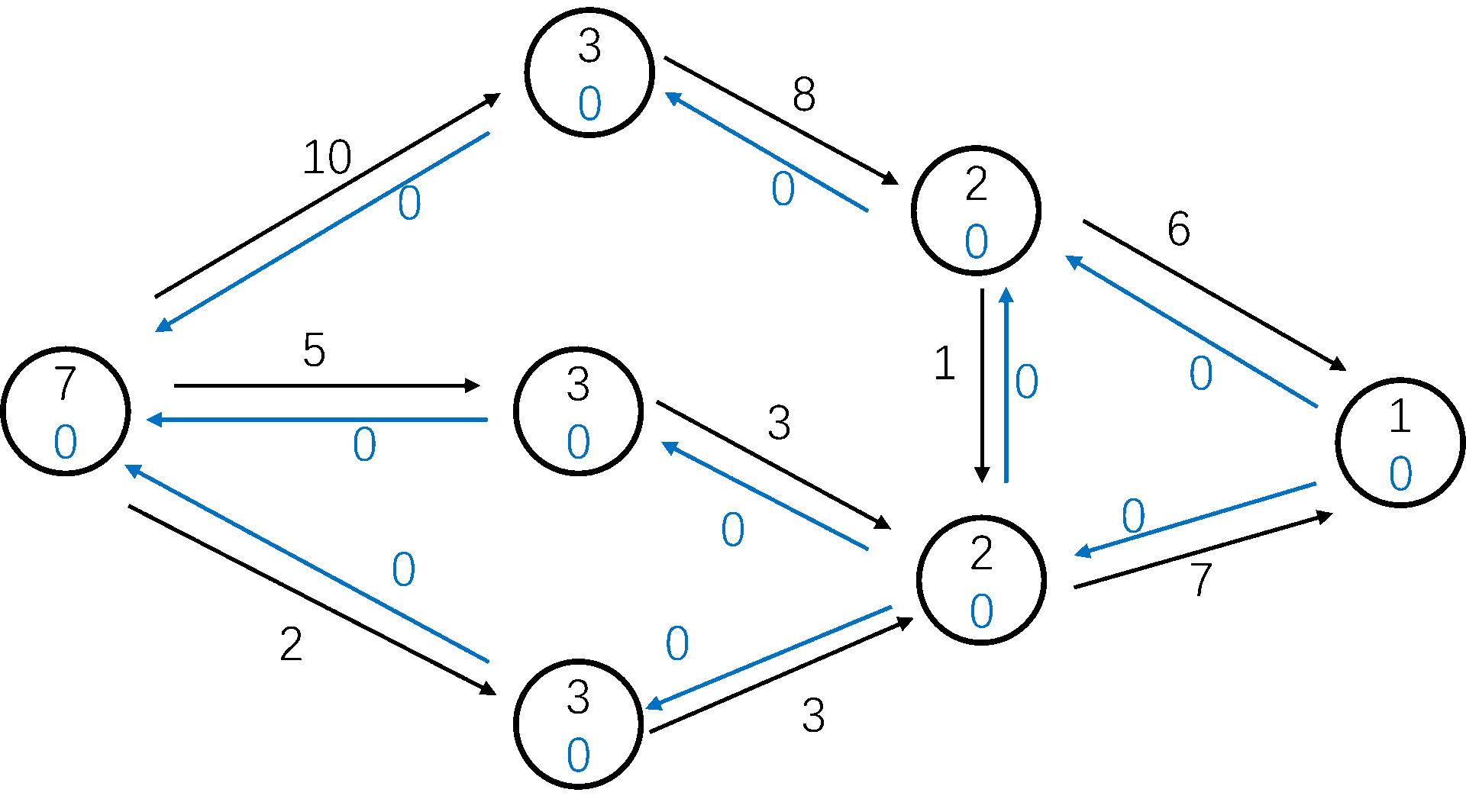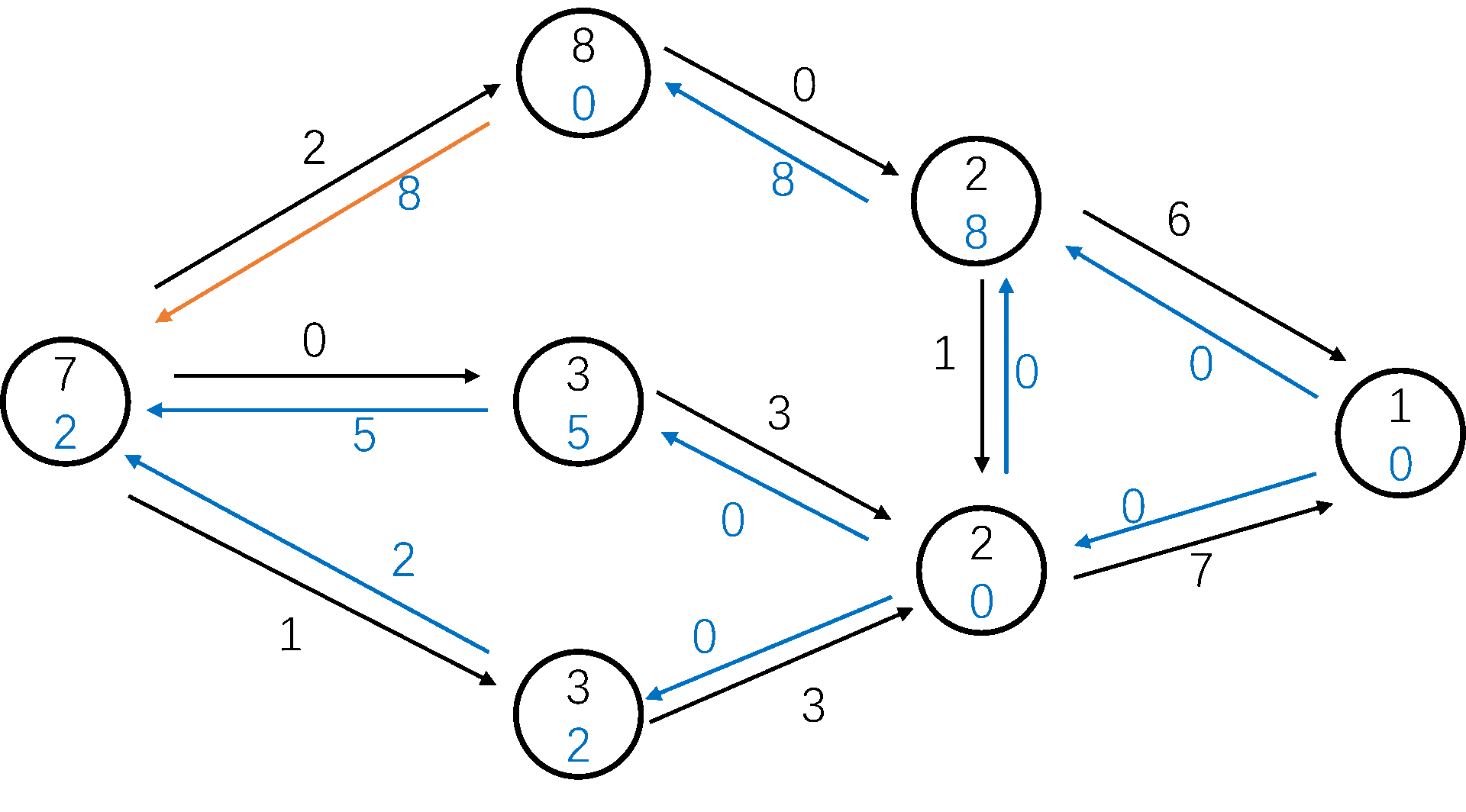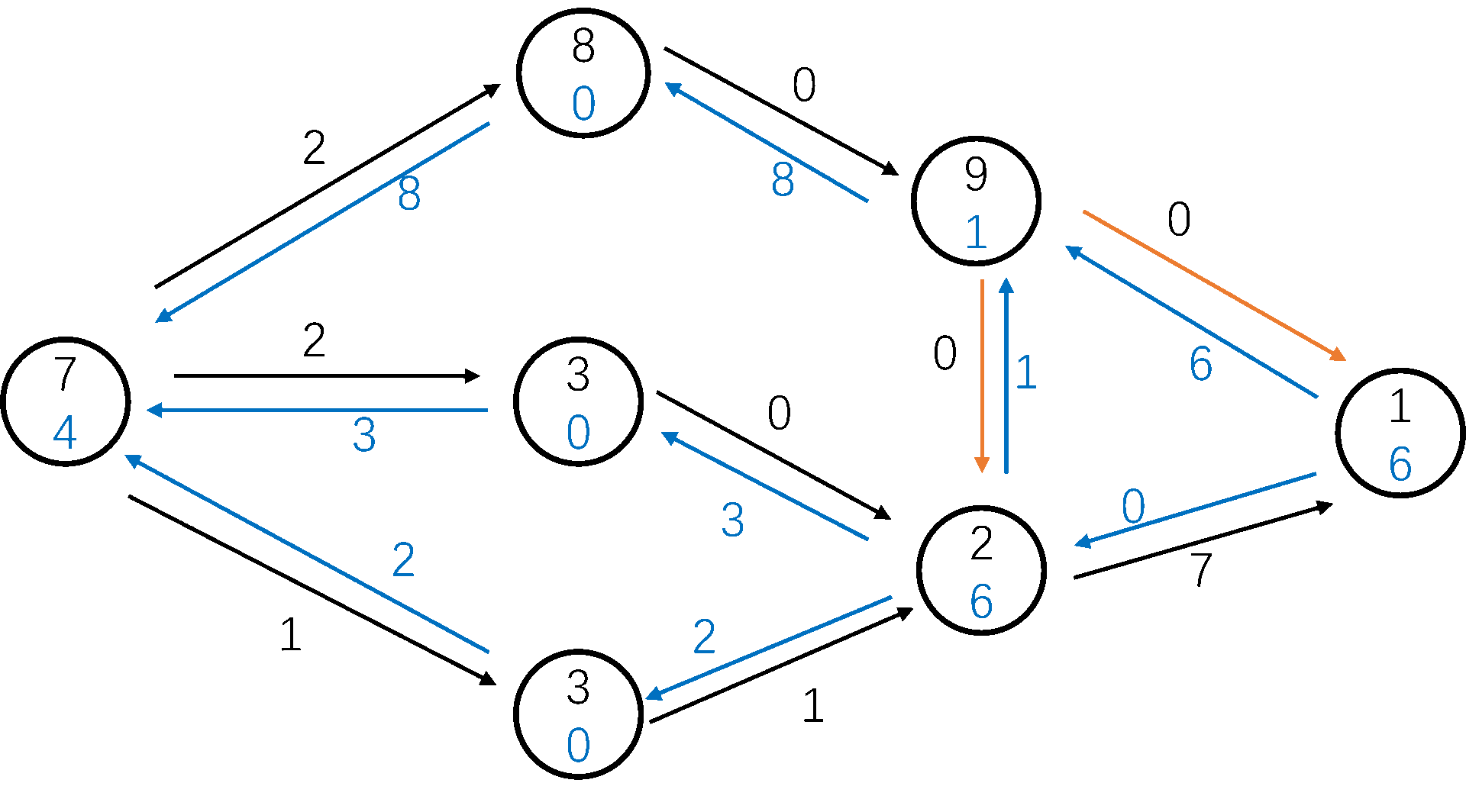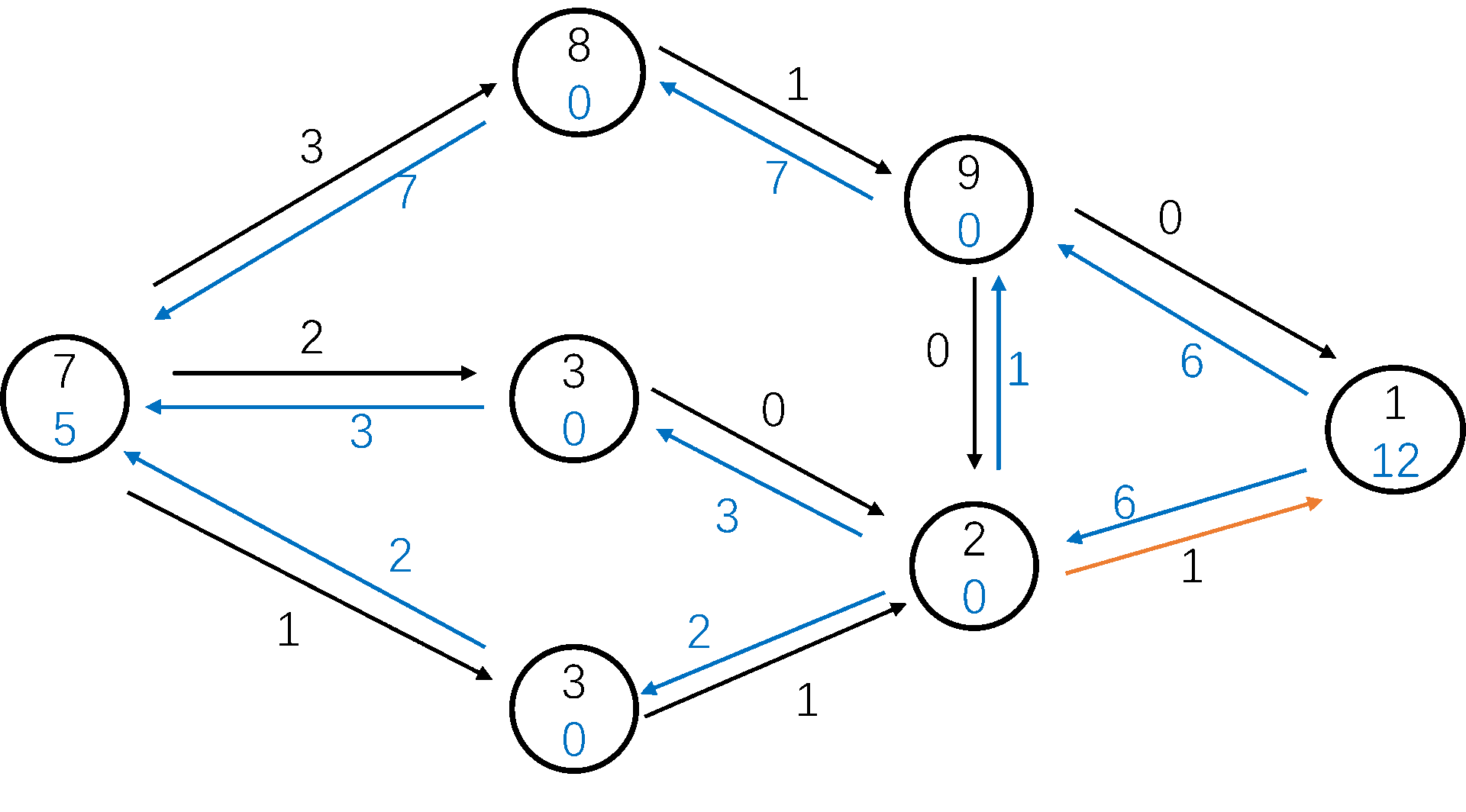
HLPP 的时间复杂度十分优秀,为 \(O(n^2 \sqrt m)\)。
//洛谷P4722
#include<bits/stdc++.h>
using namespace std;
#define endl '\n'
#define FL(a, b, c) for(int a = (b), a##end = (c); a <= a##end; a++)
#define FR(a, b, c) for(int a = (b), a##end = (c); a >= a##end; a--)
#define lowbit(x) ((x) & -(x))
#define int long long
#define eb emplace_back
constexpr int N = 1300, M = 3e5 + 10, inf = 1e5;
int n, m, s, t, tot = 1, head[N];
struct edge{int v, nxt, w;}e[M];
void add(int u, int v, int w){
e[++tot] = {v, head[u], w}, head[u] = tot;
e[++tot] = {u, head[v], 0}, head[v] = tot;
}
int num[N << 1], inq[N], c[N], h[N];
struct cmp{
bool operator()(const int a, const int b)const{
return h[a] < h[b];
}
};
priority_queue<int, vector<int>, cmp>q;
bool bfs(){
queue<int>q;
memset(h, 0x7f, sizeof h);
num[h[t] = 0]++, q.emplace(t);
while(!q.empty()){
for(int x = q.front(), i = head[x], v; i; i = e[i].nxt)
if(h[v = e[i].v] > n)num[h[v] = h[x] + 1]++, q.emplace(v);
q.pop();
}
return h[s] <= n;
}
void relabel(int x){
for(int i = head[h[x] = inf, x]; i; i = e[i].nxt)
if(e[i].w && h[e[i].v] + 1 < h[x])h[x] = h[e[i].v] + 1;
}
void push(int x){
for(int i = head[x], v, d; i && c[x]; i = e[i].nxt)
if(e[i].w && h[v = e[i].v] == h[x] - 1){
d = min(e[i].w, c[x]);
e[i].w -= d, e[i ^ 1].w += d, c[x] -= d, c[v] += d;
if(!inq[v]) q.emplace(v), inq[v] = 1;
}
}
int hlpp(){
if(!bfs())return 0;
h[s] = n, inq[s] = inq[t] = 1;
for(int i = head[s], v, d; i; i = e[i].nxt)
if(h[v = e[i].v] <= inf && (d = e[i].w)){
e[i].w -= d, e[i ^ 1].w += d, c[v] += d;
if(!inq[v])inq[v] = 1, q.emplace(v);
}
while(!q.empty()){
int x = q.top();
inq[x] = 0, q.pop(), push(x);
if(!c[x])continue;
if(!--num[h[x]])
FL(i, 1, n)if(i != s && h[i] <= inf && h[i] > h[x])h[i] = max(h[i], n + 1);
relabel(x), ++num[h[x]], q.emplace(x), inq[x] = 1;
}
return c[t];
}
int32_t main(){
cin.tie(0)->sync_with_stdio(0);
int u, v, w;
cin >> n >> m >> s >> t;
while(m--)cin >> u >> v >> w, add(u, v, w);
cout << hlpp();
return 0;
}
应用
网络流主要考查建图,一般 Dinic 或 ISAP 就够了。
二分图最大匹配
新建 \(s,t\) 节点。
并将 \(s\) 向左边的每个点连一条权值为 \(1\) 的边,右边节点向 \(t\) 连边。
再连上原图中的边,接着跑最大流即可,复杂度 \(O(n\sqrt{n})\)。
最少链覆盖
将每个点 \(u\) 拆成两个点 \(u_0, y_1\),如果有边 \((u, v)\),就将 \(u_0, v_1\) 链接。
得到二分图,跑二分图匹配答案为 \(s\),那么 \(ans = n - s\)。
证明:
一开始每个点都是独立的为一条路径,总共有 \(n\) 条。
我们每次在二分图里找一条匹配边就相当于把两条路径合成了一条路径,也就相当于路径数减少了1。
所以找到了几条匹配边,路径数就减少了多少。
例题:洛谷 P2764,CF1630F。
最小割
模型 1
题目:
有 \(n\) 个物品和两个集合 \(A,B\),如果一个物品没有放入 \(A\) 集合会花费 \(a_i\),没有放入 \(B\) 集合会花费 \(b_i\)。
还有若干个形如 \(u_i,v_i,w_i\) 限制条件,表示如果 \(u_i\) 和 \(v_i\) 同时不在一个集合会花费 \(w_i\)。
每个物品必须且只能属于一个集合,求最小的代价。
我们对于设置源点 \(s\) 和汇点 \(t\),第 \(i\) 个点由 \(s\) 连一条容量为 \(a_i\) 的边、向 \(t\) 连一条容量为 \(b_i\) 的边。
对于限制条件 \(u,v,w\),我们在 \(u,v\) 之间连容量为 \(w\) 的双向边。
注意到当源点和汇点不相连时,代表这些点都选择了其中一个集合。
如果将连向 \(s\) 或 \(t\) 的边割开,表示不放在 \(A\) 或 \(B\) 集合,如果把物品之间的边割开,表示这两个物品不放在同一个集合
例题:AGC38F,洛谷 P4313
模型 2
即给定一张有向图,每个点都有一个权值(int 范围),你需要选择一个权值和最大的子图,使得子图中每个点的后继都在子图中。
建立超级源点 \(s\) 和超级汇点 \(t\)。若节点 \(u\) 权值为正,则 \(s\) 向 \(u\) 连一条有向边,边权即为该点点权。若节点 \(u\) 权值为负,则由 \(u\) 向 \(t\) 连一条有向边,边权即为该点点权的相反数。
原图上所有边权改为 \(\infty\)。跑网络最大流,将所有正权值之和减去最大流,即为答案。
切糕模型
有 \(n\) 个整数变量 \(x_i\)。\(x_i\) 可以取 \([1,m]\),取 \(j\) 需要 \(a_{i,j}\) 的代价。有若干个约束,形如 \(x_u \le x_v + w\)。给变量赋值,最小化总代价。
将每个 \(x_i\) 拆成 \(m + 1\) 个点,连一条 \(s\rightarrow x_{i, 1}, \rightarrow x_{i, 2} \rightarrow \ldots \rightarrow x_{i, m + 1} \rightarrow t\) 的链。
\(s\rightarrow x_{i, 1} = \infty, x_{i, m + 1} \rightarrow t = \infty, x_{i, j} \rightarrow x_{i, j + 1} = a_{i, j}\)。
对每个 \(u, v, w\),连 \(x_{v, j + w} \rightarrow x_{u, j} = \infty\)。
跑最小割即可。
例题:洛谷 P3227,洛谷 P6054。