Ingest and split data in a flow
https://docs.outerbounds.com/recsys-tutorial-L2/
Given our dataset is in a parquet file, in this lesson you will learn how to leverage an open-source, a hyper-performant database for analytics workloads called DuckDB. You can follow along with the code in this flow. DuckDB has become popular as a fast way to keep Pandas DataFrame interfaces while processing data faster and consuming less memory, as demonstrated in these public benchmarks and described in this post.
In this flow, you will see how to prepare the dataset using DuckDB queries. The data is then split into train, validation, and test splits. In general, it is good practice to have a validation set for choosing the best hyperparameters and a held out test set to give an estimate of performance on unseen data. Later, you will extend this flow to evaluate, tune, and deploy a model to make real-time predictions.
from metaflow import FlowSpec, step, S3, Parameter, current
class DataFlow(FlowSpec):
IS_DEV = Parameter(
name='is_dev',
help='Flag for dev development, with a smaller dataset',
default='1'
)
@step
def start(self):
self.next(self.prepare_dataset)
@step
def prepare_dataset(self):
"""
Get the data in the right shape by reading the parquet dataset
and using DuckDB SQL-based wrangling to quickly prepare the datasets for
training our Recommender System.
"""
import duckdb
import numpy as np
con = duckdb.connect(database=':memory:')
con.execute("""
CREATE TABLE playlists AS
SELECT *,
CONCAT (user_id, '-', playlist) as playlist_id,
CONCAT (artist, '|||', track) as track_id,
FROM 'cleaned_spotify_dataset.parquet'
;
""")
con.execute("SELECT * FROM playlists LIMIT 1;")
print(con.fetchone())
tables = ['row_id', 'user_id', 'track_id', 'playlist_id', 'artist']
for t in tables:
con.execute("SELECT COUNT(DISTINCT({})) FROM playlists;".format(t))
print("# of {}".format(t), con.fetchone()[0])
sampling_cmd = ''
if self.IS_DEV == '1':
print("Subsampling data, since this is DEV")
sampling_cmd = ' USING SAMPLE 10 PERCENT (bernoulli)'
dataset_query = """
SELECT * FROM
(
SELECT
playlist_id,
LIST(artist ORDER BY row_id ASC) as artist_sequence,
LIST(track_id ORDER BY row_id ASC) as track_sequence,
array_pop_back(LIST(track_id ORDER BY row_id ASC)) as track_test_x,
LIST(track_id ORDER BY row_id ASC)[-1] as track_test_y
FROM
playlists
GROUP BY playlist_id
HAVING len(track_sequence) > 2
)
{}
;
""".format(sampling_cmd)
con.execute(dataset_query)
df = con.fetch_df()
print("# rows: {}".format(len(df)))
print(df.iloc[0].tolist())
con.close()
train, validate, test = np.split(
df.sample(frac=1, random_state=42),
[int(.7 * len(df)), int(.9 * len(df))])
self.df_dataset = df
self.df_train = train
self.df_validate = validate
self.df_test = test
print("# testing rows: {}".format(len(self.df_test)))
self.next(self.end)
@step
def end(self):
pass
if __name__ == '__main__':
DataFlow()
parquet
https://www.databricks.com/glossary/what-is-parquet
What is Parquet?
Apache Parquet is an open source, column-oriented data file format designed for efficient data storage and retrieval. It provides efficient data compression and encoding schemes with enhanced performance to handle complex data in bulk. Apache Parquet is designed to be a common interchange format for both batch and interactive workloads. It is similar to other columnar-storage file formats available in Hadoop, namely RCFile and ORC.
Characteristics of Parquet
- Free and open source file format.
- Language agnostic.
- Column-based format - files are organized by column, rather than by row, which saves storage space and speeds up analytics queries.
- Used for analytics (OLAP) use cases, typically in conjunction with traditional OLTP databases.
- Highly efficient data compression and decompression.
- Supports complex data types and advanced nested data structures.
Benefits of Parquet
- Good for storing big data of any kind (structured data tables, images, videos, documents).
- Saves on cloud storage space by using highly efficient column-wise compression, and flexible encoding schemes for columns with different data types.
- Increased data throughput and performance using techniques like data skipping, whereby queries that fetch specific column values need not read the entire row of data.
Apache Parquet is implemented using the record-shredding and assembly algorithm, which accommodates the complex data structures that can be used to store the data. Parquet is optimized to work with complex data in bulk and features different ways for efficient data compression and encoding types. This approach is best especially for those queries that need to read certain columns from a large table. Parquet can only read the needed columns therefore greatly minimizing the IO.
Advantages of Storing Data in a Columnar Format:
- Columnar storage like Apache Parquet is designed to bring efficiency compared to row-based files like CSV. When querying, columnar storage you can skip over the non-relevant data very quickly. As a result, aggregation queries are less time-consuming compared to row-oriented databases. This way of storage has translated into hardware savings and minimized latency for accessing data.
- Apache Parquet is built from the ground up. Hence it is able to support advanced nested data structures. The layout of Parquet data files is optimized for queries that process large volumes of data, in the gigabyte range for each individual file.
- Parquet is built to support flexible compression options and efficient encoding schemes. As the data type for each column is quite similar, the compression of each column is straightforward (which makes queries even faster). Data can be compressed by using one of the several codecs available; as a result, different data files can be compressed differently.
- Apache Parquet works best with interactive and serverless technologies like AWS Athena, Amazon Redshift Spectrum, Google BigQuery and Google Dataproc.
Difference Between Parquet and CSV
CSV is a simple and common format that is used by many tools such as Excel, Google Sheets, and numerous others. Even though the CSV files are the default format for data processing pipelines it has some disadvantages:
- Amazon Athena and Spectrum will charge based on the amount of data scanned per query.
- Google and Amazon will charge you according to the amount of data stored on GS/S3.
- Google Dataproc charges are time-based.
Parquet has helped its users reduce storage requirements by at least one-third on large datasets, in addition, it greatly improved scan and deserialization time, hence the overall costs. The following table compares the savings as well as the speedup obtained by converting data into Parquet from CSV.
Dataset
Size on Amazon S3
Query Run Time
Data Scanned
Cost
Data stored as CSV files
1 TB
236 seconds
1.15 TB
$5.75
Data stored in Apache Parquet Format
130 GB
6.78 seconds
2.51 GB
$0.01
Savings
DuckDB
https://duckdb.org/
DuckDB is a fast
portable|
database systemQuery and transform your data anywhere
Installation Documentation
using DuckDB's feature-rich SQL dialect1
- SQL
- Python
- R
- Java
- Node.js
2
3
4
5
6
7
8Aggregation query Live demo-- Get the top-3 busiest train stations SELECT station_name, count(*) AS num_services FROM train_services GROUP BY ALL ORDER BY num_services DESC LIMIT 3;DuckDB at a glance
Simple
DuckDB is easy to install and deploy. It has zero external dependencies and runs in-process in its host application or as a single binary.
Read morePortable
DuckDB runs on Linux, macOS, Windows, and all popular hardware architectures. It has idiomatic client APIs for major programming languages.
Read moreFeature-rich
DuckDB offers a rich SQL dialect. It can read and write file formats such as CSV, Parquet, and JSON, to and from the local file system and remote endpoints such as S3 buckets.
Read moreFast
DuckDB runs analytical queries at blazing speed thanks to its columnar engine, which supports parallel execution and can process larger-than-memory workloads.
Read moreExtensible
DuckDB is extensible by third-party features such as new data types, functions, file formats and new SQL syntax.
Read moreFree
DuckDB and its core extensions are open-source under the permissive MIT License.
Read more
DuckDB:适用于非大数据的进程内Python分析
https://juejin.cn/post/7375152719482437666
大数据已死?
总之,DuckDB 是一个具有革命性意图的快速数据库,即使对于非常大的数据集,它也可以实现单计算机分析。它质疑 基于大数据的解决方案 的必要性。
在 2023 年 MotherDuck 博客的一篇广为流传的帖子中,挑衅地题为“ 大数据已死”,Jordan Tigani 指出“大多数应用程序不需要处理海量数据”。
他写道:“用于分析工作负载处理的数据量几乎肯定比你想象的要小。”因此,在投入更昂贵的数据仓库或分布式分析系统之前,先考虑一个简单的基于单计算机的分析软件是有意义的。
为什么量化人应该使用duckdb?
http://www.jieyu.ai/blog/2024/02/01/why-should-you-use-duckdb/
为什么量化人应该使用duckdb?
上一篇笔记介绍了通过duckdb,使用SQL进行DataFrame的操作。我们还特别介绍了它独有的 Asof Join 功能,由于量化人常常处理跨周期行情对齐,这一功能因此格外实用。但是duckdb的好手段,不止如此。
- 完全替代sqlite,但命令集甚至超过了Postgres
- 易用性极佳
- 性能怪兽
作为又一款来自人烟稀少的荷兰的软件,北境这一苦寒之地,再一次让人惊喜。科技的事儿,真是堆人没用。
sqlite非常轻量,基于内存或者文件作为存储,无须像其它数据库一样进行复杂的服务器安装和设置。它是市占率最高的数据库 -- 但未来可能会有所不同:仅就功能而言,duckdb不仅仅完全实现了sqlite的所有功能,它甚至可能比postgres的语法还要丰富。而在性能上,sqlite就更是难以望其项背 -- 实际上,在大数据集的join和group by操作上,H2O.ai的测试表明,在与clickhouse, porlars一众明星选手打排位赛,duckdb都能排在第一位!
为什么DuckDB变得越来越受欢迎?
https://zhuanlan.zhihu.com/p/666164886
现在有许多原因使公司开始在DuckDB上搭建产品。该数据库专为快速分析查询而设计,因此它针对大型数据集上的聚合、连接和复杂查询进行了优化,这些类型的查询通常在分析和报告中使用。此外:
- 它易于安装、部署和使用。没有需要配置的服务器——DuckDB在应用程序内部嵌入运行。这使得它易于集成到不同的编程语言和环境中。
- 尽管它很简单,但DuckDB具有丰富的功能集。它支持完整的SQL标准、事务、二级索引,并且与流行的数据分析编程语言如Python和R集成良好。
- DuckDB是免费的,任何人都可以使用和修改它,这降低了开发人员和数据分析师采用它的门槛。
- DuckDB经过充分的测试和稳定性验证。它有一个广泛的测试套件,并在各种平台上进行持续集成和测试,以确保稳定性。
- DuckDB提供与专门的OLAP数据库相当的性能,同时更易于部署。这使得它既适用于中小型数据集的分析查询,也适用于大型企业数据集。
简而言之,DuckDB将SQLite的简单易用性与专业列存储数据库的分析性能相结合。所有这些因素——性能、简单性、功能和开源许可——促使DuckDB在开发人员和数据分析师中越来越受欢迎。
Architecture Overview
https://zhuanlan.zhihu.com/p/626311150
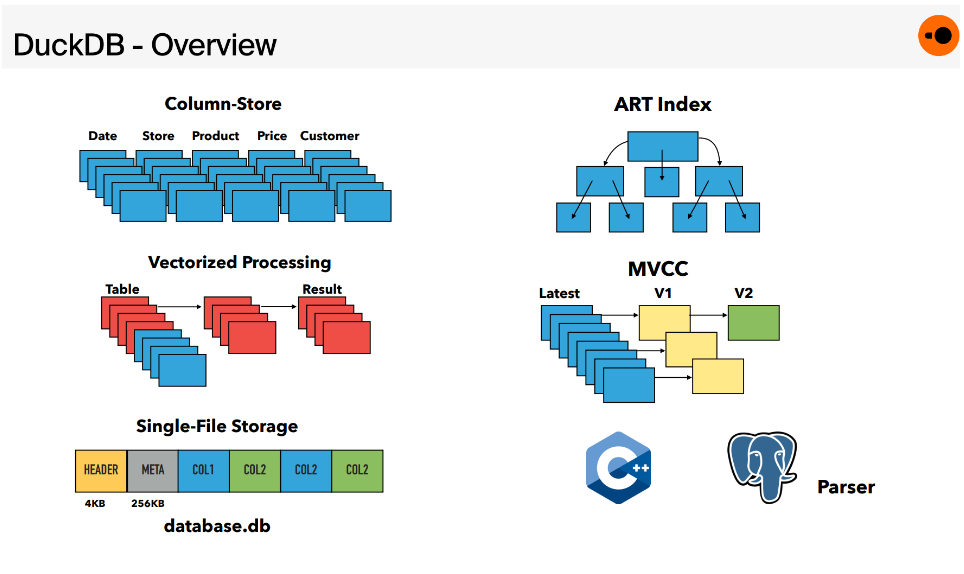
DuckDB 各个组件之间的架构非常的 "textbook",也就是说会把整个数据库分为:Parser, logical planner, optimizer, physical planner
, execution engine,transaction and storage managers。
作为嵌入式数据库,DuckDB没有客户端协议接口或服务器进程,而是使用C/C++ API进行访问。此外,DuckDB提供了SQLite兼容层,允许以前使用SQLite的应用程序通过重新链接或库 overload 来使用DuckDB。
- Parser
- SQL Parser 源自 Postgres SQL Parser
- Logical Planner
- binder, 解析所有引用的 schema
,将 binder 生成的 AST 转换为由基本 logical query 查询运算符组成的树,就得到了一颗 type-resolved logical query plan。 DuckDB 还保留存储数据的统计信息,并将其作为规划过程中不同表达式树
- 中的对象(如 table 或 view)的表达式,将其与列名和类型匹配。
- plan generator
- 的一部分进行传播。这些统计信息用于优化程序本身,并且也用于防止整数溢出
和常量折叠
- Optimizer
- 使用动态规划进行 join order 的优化,针对复杂的 join graph 会 fallback 到贪心算法
- 会消除所有的 subquery
- 有一组 rewrite rules 来简化 expression tree,例如执行公共子表达式消除
- 。
- Cardinality estimation 是使用采样和
HyperLogLog的组合完成的,这个过程将优化 logical plan。- physical planner 将 logical plan 转换为 physical plan,在适用时选择合适的实现方式,例如 sort-merge join or hash join。
- DuckDB 最开始采用了基于 Pull-based 的
Vector Volcano的执行引擎,后来切换到了 Push-based 的 pipelines 执行方法- DuckDB 采用了向量化计算来来加速计算,具有内部实现的多种类型的 vector 以及向量化的 operator
- 另外出于可移植性原因,没有采用 JIT,因为 JIT引擎依赖于大型编译器库(例如LLVM),具有额外的传递依赖。
- Transactions:
- DuckDB 通过 MVCC 提供了 ACID 的特性,实现了HyPer专门针对混合OLAP / OLTP系统定制的可串行化MVCC 变种 。该变种立即 in-place 更新数据,并将先前状态存储在单独的 undo buffer
- 中,以供并发事务和 abort 使用
- Persistent Storage
- 单文件存储
- DuckDB 使用面向读取优化的 DataBlocks 存储布局(单个文件)。逻辑表被水平分区为 chunks of columns,并使用轻量级压缩方法压缩成 physical block
- 。每个块都带有每列的
min/max索引,以便快速确定它们是否与查询相关。此外,每个块还带有每列的轻量级索引,可以进一步限制扫描的值数量。
, execution, storage 多做一些介绍,其他部分暂时略过…
Vectors
DuckDB 内部是一个 vectorized push-based model,在执行过程中,vector 会在各个操作符之间流转,而不是一个个 tuple
。
DuckDB 具有非常多自定义的 vector format,非常类似 Arrow,但是对于执行更加友好,是和 volox team 一起设计的,所以很 volex team 的 vector 有很多相似之处。
每个 vector 只保存单个类型的数据,这里有 logical array
和实际物理实现的区别,对外的操作符看来就是一致的 logical array。
可以看到下面举例了四种类型的 vector,各自都有自己的逻辑和物理表达形式。
标签:df,self,parquet,DuckDB,Parquet,data,id From: https://www.cnblogs.com/lightsong/p/18638573