1.什么是unittest
unittest 是 Python 标准库中的一个单元测试框架,采用类似于 JUnit 的风格。它提供了创建和运行测试用例、组织测试用例为测试套件、进行测试结果报告等功能。unittest 支持自动化测试、测试用例的组织、断言检查、测试结果的收集等,广泛应用于 Python 项目中的单元测试。
与其他测试框架的主要区别:
- 与 pytest:
unittest是 Python 的内置框架,而pytest是一个第三方框架,具有更简洁和灵活的语法。pytest允许使用更简便的断言语法(例如assert),而unittest则使用一系列的断言方法(如assertEqual)。pytest更易于使用和扩展,支持更多插件,自动发现测试等高级特性。unittest更适合标准化和结构化的测试,符合传统的 xUnit 风格。
- 与 nose:
nose是另一种基于unittest的框架,提供了更多的自动化和发现功能,但目前已不再积极维护。unittest提供了更多的官方支持和集成,nose主要依赖于社区维护。
unittest 的优点:
- 内置支持:作为 Python 的标准库,
unittest不需要额外安装,直接可用。 - 兼容性:支持与其他工具和框架的兼容性,如集成到 CI/CD 流程中。
- 结构化:测试用例、测试套件和测试执行的结构清晰,容易管理和组织。
- 报告和断言:内置支持多种断言方法和详细的测试报告功能,方便调试和查看测试结果。
- 良好的文档和社区支持:由于是官方标准库,
unittest具有广泛的文档支持,且社区活跃,容易找到帮助和解决方案。
unittest 的使用场景:
- 标准化单元测试:当你希望确保代码的每个模块都按预期运行时,使用
unittest编写单元测试是非常合适的。 - 集成到 CI/CD 流程中:由于
unittest的兼容性好,它可以无缝集成到持续集成和部署(CI/CD)流程中。 - 团队协作的测试管理:由于
unittest提供了清晰的结构和组织方法,适合团队中的多人协作和代码共享。 - 大型项目中的自动化测试:当项目中有大量的模块和函数时,
unittest的自动发现功能和测试套件管理可以有效地组织和执行测试,确保项目质量。
总结:
unittest是一个功能齐全的标准库框架,适合用于结构化的单元测试和集成测试。- 它与
pytest等其他框架相比,虽然语法较为严格,但由于其内置支持和结构化优势,在大型项目中非常有用。 - 使用场景包括但不限于单元测试、自动化测试、持续集成以及测试报告和分析等。
2.什么是 Fixture(测试夹具)?
在单元测试中,Fixture(测试夹具) 是指在每个测试方法执行之前和之后进行设置和清理的一些操作。它提供了必要的环境准备(比如数据库连接、文件创建、外部服务的模拟等)以及测试结束后的清理(比如关闭连接、删除临时文件等)。
目的和作用
- 准备测试环境:在每个测试用例执行之前,Fixture 可以用来准备测试所需的环境或数据。
- 清理资源:测试结束后,Fixture 可以确保资源的清理(比如关闭文件、释放网络连接等)。
- 避免重复代码:使用 Fixture 可以将设置和清理工作集中管理,避免在每个测试中重复这些操作,从而提高代码的复用性和可维护性。
测试夹具的常见应用场景
- 初始化数据:例如,创建一个模拟数据库连接、初始化文件系统、设置网络连接等。
- 模拟外部依赖:如模拟 API 调用、数据库查询结果等。
- 清理操作:如关闭文件、删除临时文件、断开数据库连接、清理缓存等。
在不同测试框架中的使用
Fixture 主要用于 单元测试框架 中,如 unittest、pytest 等。
- 在
unittest中使用 Fixture
在 Python 的 unittest 框架中,测试夹具是通过 setUp() 和 tearDown() 方法来实现的。
setUp():在每个测试方法执行前调用,用来准备测试环境。tearDown():在每个测试方法执行后调用,用来清理测试环境。
示例:
import unittest
class MyTestCase(unittest.TestCase):
def setUp(self):
# 这里可以做一些初始化操作,比如连接数据库、初始化文件等
print("Test setup - preparing test environment")
self.test_data = [1, 2, 3]
def tearDown(self):
# 这里可以做一些清理工作,比如关闭数据库连接、删除临时文件等
print("Test teardown - cleaning up after test")
del self.test_data
def test_addition(self):
self.assertEqual(sum(self.test_data), 6)
def test_multiplication(self):
self.assertEqual(self.test_data[0] * 2, 2)
setUp():在每个测试用例执行前都会被调用,用于准备数据或测试环境。tearDown():在每个测试用例执行后被调用,用于清理环境、释放资源。
- 在
pytest中使用 Fixture
pytest 提供了更强大和灵活的 Fixture 支持。通过使用 @pytest.fixture 装饰器,可以定义一个 Fixture,它可以在测试函数中直接作为参数传入。
示例:
import pytest
# 定义 Fixture
@pytest.fixture
def setup_data():
print("Setting up data for test")
return [1, 2, 3]
def test_addition(setup_data):
assert sum(setup_data) == 6
def test_multiplication(setup_data):
assert setup_data[0] * 2 == 2
-
@pytest.fixture装饰器:用来标记一个方法作为 Fixture,pytest会在需要时自动调用它并传递给测试方法。 -
Fixture 的作用范围:Fixture 可以设置作用范围(如函数级、模块级、会话级等),通过
scope参数来控制 Fixture 的生命周期。例如:
scope="function":默认设置,表示每个测试函数都会调用该 Fixture。scope="module":表示每个模块只会调用一次 Fixture,适用于模块级的资源准备。scope="session":表示会话级别的 Fixture,在测试会话开始时调用一次,适合于长期存在的资源(如数据库连接等)。
import pytest
@pytest.fixture(scope="module")
def db_connection():
print("Connecting to the database...")
# 模拟数据库连接
db = "Connected"
yield db # 返回连接对象
print("Disconnecting from the database...")
# 清理:断开数据库连接
db = None
Fixture 的高级用法
-
依赖于其他 Fixtures:Fixture 可以依赖于其他 Fixture。如果某个 Fixture 需要其他 Fixture 来进行初始化,可以通过将其他 Fixture 作为参数传递给它。
示例:
@pytest.fixture def database_connection(): print("Setting up database connection") return "Database connection" @pytest.fixture def user(database_connection): print("Setting up user with", database_connection) return "User created" def test_user(user): assert user == "User created" -
返回多种数据类型:Fixture 可以返回任意类型的数据,如对象、字典、列表等。
示例:
@pytest.fixture def data(): return {'key': 'value'} def test_data(data): assert data['key'] == 'value' -
Fixture 的清理操作:你可以使用
yield语句来在 Fixture 中定义清理操作,yield前的代码执行的是初始化,yield后的代码执行的是清理工作。
Fixture的类方法
在 unittest 框架中,setUpClass 和 tearDownClass 是类方法,用于在测试类的所有测试方法执行之前和之后进行一次性设置和清理。它们与实例方法 setUp 和 tearDown 不同,setUpClass 和 tearDownClass 只会在整个测试类的生命周期中各执行一次,而不是每个测试方法执行前后都调用。
@classmethod 装饰器
@classmethod 是一个 Python 装饰器,用于将方法标记为类方法。类方法的第一个参数是类本身 (cls),而不是实例 (self)。这使得类方法可以在不实例化对象的情况下直接通过类来调用。
setUpClass 和 tearDownClass 的作用
setUpClass:在测试类中的所有测试方法执行之前执行一次。通常用于进行一些类级别的初始化操作,例如创建数据库连接、初始化共享资源等。tearDownClass:在测试类中的所有测试方法执行之后执行一次。通常用于清理类级别的资源,如关闭数据库连接、释放文件句柄等。
示例代码
import unittest
class MyTestCase(unittest.TestCase):
@classmethod
def setUpClass(cls):
"""在所有测试方法之前执行一次,通常用于类级别的初始化"""
print("Setting up class-level resources...")
cls.shared_resource = "Shared Resource"
@classmethod
def tearDownClass(cls):
"""在所有测试方法之后执行一次,通常用于类级别的清理"""
print("Tearing down class-level resources...")
del cls.shared_resource
def setUp(self):
"""在每个测试方法执行之前执行,通常用于实例级别的初始化"""
print("Setting up for a test...")
def tearDown(self):
"""在每个测试方法执行之后执行,通常用于实例级别的清理"""
print("Tearing down after a test...")
def test_example_1(self):
"""示例测试方法1"""
print("Running test_example_1")
self.assertEqual(1 + 1, 2)
def test_example_2(self):
"""示例测试方法2"""
print("Running test_example_2")
self.assertTrue(True)
运行结果说明
Setting up class-level resources...
Setting up for a test...
Running test_example_1
Tearing down after a test...
Setting up for a test...
Running test_example_2
Tearing down after a test...
Tearing down class-level resources...
关键点:
setUpClass和tearDownClass是类级别的方法,会在测试类的生命周期内调用一次。setUp和tearDown是实例级别的方法,会在每个测试方法执行前后调用一次。- 使用
@classmethod装饰器时,方法的第一个参数必须是cls,表示类本身。
使用场景:
setUpClass:用于需要在整个测试类中共享的资源初始化(如数据库连接、外部服务连接等)。tearDownClass:用于清理类级别的资源,避免在每个测试方法中都重复执行清理操作。
Fixture 与单元测试的关系
- 提高代码的可重用性:Fixture 可以避免重复写环境初始化和清理代码,让测试代码更加简洁、可维护。
- 增强测试环境的隔离性:每个测试用例都可以使用独立的 Fixture 来设置和清理不同的环境,这样可以确保测试之间不会相互干扰。
- 提高测试效率:通过合理使用 Fixture,可以减少测试前后环境的初始化和清理时间,尤其是对于资源密集型的测试(如数据库、网络请求等)。
总结
- Fixture 是单元测试中用于设置和清理测试环境的机制,通常用于资源的初始化和释放。
- 在 unittest 中,使用
setUp()和tearDown()方法来实现。 - 在 pytest 中,使用
@pytest.fixture装饰器来定义 Fixture,提供了更强大和灵活的功能。 - Fixture 可以用于环境初始化、数据准备、模拟外部依赖、清理资源等多种场景,目的是避免在每个测试用例中重复编写相同的代码,提升测试的效率和可维护性。
test测试方法之间的依赖和信息传递
利用python中类属性和实例属性的特性,创造方法间的依赖关系:使用类属性在每一个方法里传参即可。
-
Python中的特性:如果实例没有相应属性,类属性有,则Python自动访问类属性替代
-
class BasicTestCase(unittest.TestCase): @classmethod def setUpClass(cls): cls.guide = 'yu' # 在类方法下,定义类属性cls.guide = 'yu' pass def test1(self): guide = self.guide # 3.在这段话中,这句话也可以获取guide = 'yu',因为语句虽然为self.guide,实例没有定义guide属性, # 3.Python中的特性:如果实例没有属性,Python自动访问类属性替代 if __name__ == '__main__': # 设定条件执行unittest的主函数 unittest.main()
在方法间传参:
class BasicTestCase(unittest.TestCase):
def setUp(self):
self.guide = 'ba' # 在setUp()方法下,定义"全局"实例属性self.guide = 'ba'
def test1(self):
guide = 'shi' # 在test1中定义"当局"实例属性guide = 'shi'
print(guide) # 这里拿到的guide = 'shi'
def test2(self):
guide = self.guide
print(guide) # 这里拿到的guide = 'ba',而不是'shi',说明普通方法中的实例变量生命周期仅限"当局",无法互相依赖
if __name__ == '__main__': # 设定条件执行unittest的主函数
unittest.main()
跳过测试用例skip操作
1.跳过的类型
# 1.跳过语句:直接跳过、条件跳过
# @unittest.skip('跳过的原因')
# @unittest.skipIf('跳过条件', '跳过的原因')
# @unittest.skipUnless('不跳过的条件', '不跳过的原因')
# 实例演示:下列测试仅仅执行test3,因为test1跳过、test2满足跳过条件,test3满足不跳过条件
class BasicTestCase(unittest.TestCase):
@unittest.skip('因为我想跳过所以跳过') # 直接跳过
def test1(self):
print('执行test1')
@unittest.skipIf(888 < 999, '因为888比999小,所以跳过') # 条件性跳过
def test2(self):
print('执行test2')
@unittest.skipUnless('你真厉害', '因为你真厉害,所以不跳过')
def test3(self):
print('执行test3')
if __name__ == '__main__': # 设定执行unittest的主函数
unittest.main()
2.关于判定条件中的参数
必须在类下直接定义
因为@unittest.skipIf()语句执行优先级大于所有def,即无论是setUp()、setUpClass()还是test2()都在其之后执行,所以定义必须在类下
class BasicTestCase(unittest.TestCase):
number = '888'
@unittest.skipIf(number < '999', '因为number比999小,所以跳过')
def test2(self): # 不会被执行,因为888满足跳过的条件
print('执行test2')
3.测试用例之间参数联动
使用测试用例之间(例如:test1()、test2())相关参数联动设定跳过的方法
语句编码+类属性变量---类属性变量通常用列表、字典等,解决多条件依赖时方便
class BasicTestCase(unittest.TestCase):
judge = {'first': 0}
def test2(self):
print('执行test2')
BasicTestCase.judge['first'] = 888 # 更改下个测试所要依赖的变量值
def test3(self):
if BasicTestCase.judge['first'] == 888: # 设定判定条件看是否需要跳过
return # 若满足条件则直接return结束,此test下的之后的语句均不执行
# print('执行test3') # 此段代码中这句话加与不加都并不会被执行,测试通过但执行语句并没有执行,因为根据依赖的条件test3已经结束
if __name__ == '__main__': # 设定条件执行unittest的主函数
unittest.main()
数据驱动测试DDT
1.概念
ddt 是一个第三方库,用于增强 unittest 框架,支持数据驱动的测试。
当我们进行测试时遇到执行步骤相同,只需要改变入口参数的测试时,使用DDT可以简化代码
# 未使用数据驱动测试的代码:
class BasicTestCase(unittest.TestCase):
def test1(self, num1):
num = num1 + 1
print('number:', num)
def test2(self, num2):
num = num2 + 1
print('number:', num)
def test3(self, num3):
num = num3 + 1
print('number:', num)
首先,我们观察这三个测试用例,我们会发现,三个测试用例除了入口参数需要变化,
其测试执行语句都是相同的,因此,为了简化测试代码,我们可以使用数据驱动测试的理论将三个方法写作一个方法
import unittest
from ddt import ddt, data
@ddt
class BasicTestCase(unittest.TestCase):
@data('666', '777', '888')
def test(self, num):
num = int(num) + 1
print('数据驱动的number:', num)
@ddt 来自 ddt 模块的装饰器, 它允许你在测试类中使用数据驱动的测试案例,而不需要为每组测试数据编写独立的测试方法
@data装饰器:
@data是ddt提供的另一个装饰器,用于将多个数据项传递给测试方法。它将每个数据项作为参数传递给test方法进行测试。- 在这个例子中,
@data('666', '777', '888')表示我们希望对test方法运行三次,每次传入不同的参数值('666','777','888')。
test(self, num):
test方法是实际的测试用例。在@data装饰器的作用下,test方法会被执行三次,每次传入一个不同的num值。print('数据驱动的number:', num)会打印每次传入的num值,即'666','777','888'。
执行过程
@ddt 装饰器 会扩展 unittest.TestCase,让它支持数据驱动的测试。
@data 装饰器 将数据 ['666', '777', '888'] 传递给 test 方法,需要的是逐个传递的数据。
每个数据项都会单独执行一次 test 方法,每次执行时,num 参数会依次被赋值为 '666', '777', 和 '888'。
每次执行 test 方法时,print('数据驱动的number:', num) 会输出相应的数据。
执行结果
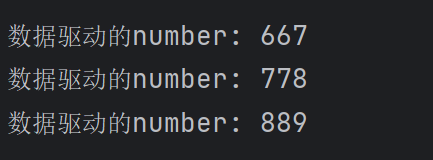
上面的就是DDT的 单一参数的数据驱动测试
2.多参数的数据驱动测试(一个测试参数中含多个元素)
unpack
只有在test函数需要多个参数时,才需要unpack进行解包
导包——设置@ddt装饰器——设置@unpack解包——写入参数——形参传递——调用
# 多参数的数据驱动
# 在单一参数包的基础上,额外导入一个unpack的包,from ddt import ddt, data, unpack
# 步骤:导包——设置@ddt装饰器——设置@unpack解包——写入参数——形参传递——调用
@ddt
class BasicTestCase(unittest.TestCase):
@data(['张三', '18'], ['李四', '19']) # 设置@data装饰器,并将同一组参数写进中括号[]
@unpack # 设置@unpack装饰器顺序解包,缺少解包则相当于name = ['张三', '18']
def test(self, name, age):
print('姓名:', name, '年龄:', age)
# 程序会执行两次测试,入口参数分别为['张三', '18'],['李四', '19'],测试结果见下图
import unittest
from ddt import ddt, data, unpack
@ddt
class BasicTestCase(unittest.TestCase):
@data(['张三', '18'], ['李四', '19'])
@unpack
def test(self, name, age):
print('姓名:', name, '年龄:', age)
执行结果

接下来笔者会介绍数据驱动测试的核心理念——数据与代码分离!!!(数据和代码在不同的文件里,方便维护代码和快速修改数据)
*数据驱动测试的核心——数据与代码分离*
*接下来介绍txt格式、json格式、yaml格式数据的单参数、多参数数据驱动方法*
3.txt格式文件驱动
3.1单一参数数据驱动
核心:编写阅读数据文件的函数、@data入口参数加*读取
# 单一参数txt文件
# 新建num文件,txt格式,按行存储777,888,999
# num文件内容(参数列表):
# 777
# 888
# 999
# 编辑阅读数据文件的函数
# 记住读取文件一定要设置编码方式,否则读取的汉字可能出现乱码!!!!!!
def read_num():
lis = [] # 以列表形式存储数据,以便传入@data区域
with open('num', 'r', encoding='utf-8') as file: # 以只读'r',编码方式为'utf-8'的方式,打开文件'num',并命名为file
for line in file.readlines(): # 循环按行读取文件的每一行
lis.append(line.strip('\n')) # 每读完一行将此行数据加入列表元素,记得元素要删除'/n'换行符!!!
return lis # 将列表返回,作为@data接收的内容
@ddt
class BasicTestCase(unittest.TestCase):
@data(*read_num()) # 入口参数设定为read_num(),因为返回值是列表,所以加*表示逐个读取列表元素
def test(self, num):
print('数据驱动的number:', num)
文件关系 num文件内容
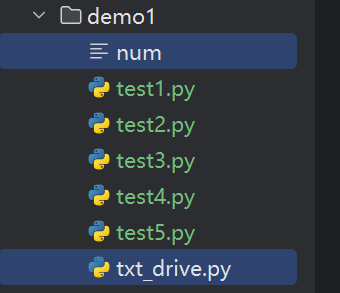
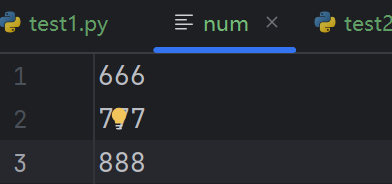
代码
import unittest
from ddt import ddt, data
def read_num():
lis = []
with open('num', 'r', encoding='utf-8') as file:
for line in file.readlines():
lis.append(line.strip('\n'))
return lis
class BasicTestCase(unittest.TestCase):
@data(*read_num())
def test(self, num):
print('数据驱动的number:', num)
结果
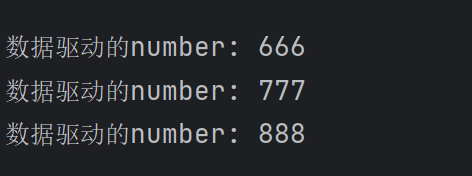
3.2多参数数据驱动
读取函数中的数据分割、@unpack解包
# 多参数txt文件
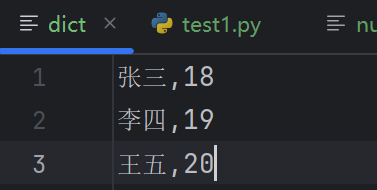
# dict文件内容(参数列表)(按行存储):
# 张三,18
# 李四,19
# 王五,20
def read_dict():
lis = [] # 以列表形式存储数据,以便传入@data区域
with open('dict', 'r', encoding='utf-8') as file: # 以只读'r',编码方式为'utf-8'的方式,打开文件'num',并命名为file
for line in file.readlines(): # 循环按行读取文件的每一行
lis.append(line.strip('\n').split(',')) # 删除换行符后,列表为['张三,18', '李四,19', '王五,20']
# 根据,分割后,列表为[['张三', '18'], ['李四', '19'], ['王五', '20']]
return lis # 将列表返回,作为@data接收的内容
@ddt
class BasicTestCase(unittest.TestCase):
@data(*read_dict()) # 加*表示逐个读取列表元素,Python中可变参数,*表示逐个读取列表元素,列表为[['张三', '18'], ['李四', '19'], ['王五', '20']]
@unpack # 通过unpack解包,逐个传参,缺少这句会将['张三', '18']传给name,从而导致age为空
def test(self, name, age): # 设置两个接收参数的形参
print('姓名为:', name, '年龄为:', age)
dict内容
代码
import unittest
from ddt import ddt, data, unpack
def read_dict():
lis = [] # 以列表形式存储数据,以便传入@data区域
with open('dict', 'r', encoding='utf-8') as file:
for line in file.readlines(): # 循环按行读取文件的每一行
lis.append(line.strip('\n').split(','))
return lis # 将列表返回,作为@data接收的内容
@ddt
class BasicTestCase(unittest.TestCase):
@data(*read_dict())
@unpack
def test(self, name, age): # 设置两个接收参数的形参
print('姓名为:', name, '年龄为:', age)

4. json格式文件驱动
4.1单一参数数据驱动
核心:使用json解析包读取文件
# 单一参数——json文件
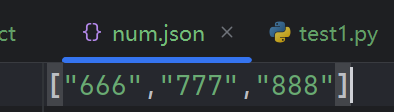
# num.json文件内容(参数列表)(注意命名后缀):
# ["666","777","888"]
# 注意JSON文件中,数据元素如果是字符串必须得用双引号
# 使用语句import json导入json包,快速读取文件用
def read_num_json():
return json.load(open('num.json', 'r', encoding='utf-8')) # 使用json包读取json文件,并作为返回值返回,注意读取的文件名
@ddt # 数据驱动步骤和txt相同
class BasicTestCase(unittest.TestCase):
@data(*read_num_json()) # *是一种解包操作
def test(self, num):
print('读取的数字是', num)
结果
读取的数字是 666
读取的数字是 777
读取的数字是 888
4.2 多参数数据驱动(列表形式)
(以列表形式存储多参数)
核心:@unpack装饰器的添加
和前面类似,不再赘述
# 数据分离
# 多参数——json文件
# 步骤和单一参数类似,仅需加入@unpack装饰器以及多参数传参入口
# dict文件内容(参数列表)(非规范json文件格式):
# [["张三", "18"], ["李四", "19"], ["王五", "20"]]
# 注意json文件格式中字符串用双引号
def read_dict_json():
return json.load(open('dict.json', 'r', encoding='utf-8')) # 使用json包读取json文件,并作为返回值返回
@ddt
class BasicTestCase(unittest.TestCase):
@data(*read_dict_json())
@unpack # 使用@unpack装饰器解包
def test(self, name, age): # 因为是非规范json格式,所以形参名无限制,下文会解释规范json格式
print('姓名:', name, '年龄:', age)
# 测试结果见下图
4.3多参数数据驱动(对象形式)
形参名字与json中对象key名相同
dictx.json
[
{"name":"张三", "age":"18"},
{"name":"李四", "age":"19"},
{"name":"王五", "age":"20"}
]
代码
import unittest
import json
from ddt import ddt, data, unpack
def read_dict_json():
return json.load(open('dictx.json', 'r', encoding='utf-8')) # 使用json包读取json文件,并作为返回值返回
@ddt
class BasicTestCase(unittest.TestCase):
@data(*read_dict_json())
@unpack
def test(self, name, age): # 令形参名字和json中命名相同name=name,age=age
print('姓名:', name, '年龄:', age)
结果

5. yaml格式文件驱动
在自动化测试领域中,yaml数据格式是举足轻重的,因此笔者在此特地进行yaml格式解析
在unittest测试框架中,对yaml数据格式的支持十分强大,使用非常方便
yaml文件的数据驱动执行代码十分简单!!!(但是要注意细节)
关于@file_data(filename)
加载和映射关系
dict.yml
name: John
age: 30
@file_data(dict.yml)得到的内容
{
"name": "John",
"age": 30
}
dict.yml
- person:
name: John
age: 30
- person:
name: Alice
age: 25
- person:
name: Bob
age: 35
@file_data('dict.yml')会把dict.yml文件中的数据,它会将整个文件加载为一个 Python 列表,每个列表元素是一个字典加载到一个字典里[ {"person": {"name": "John", "age": 30}}, {"person": {"name": "Alice", "age": 25}}, {"person": {"name": "Bob", "age": 35}} ]
5.1 单一参数数据驱动
核心:使用yaml解析包读取文件,导入file_fata驱动数据
from ddt import ddt, file_data # 导入file_data驱动数据
import unittest
@ddt
class BasicTestCase(unittest.TestCase):
@file_data('num.yml') # 采用文件数据驱动
def test(self, num):
print('读取的数字是', num)
结果
5.2 多参数数据驱动
核心:形参入口和数据参数key命名统一(下文介绍参数无法统一的解决办法)
import unittest
from ddt import ddt, file_data
@ddt
class BasicTestCase(unittest.TestCase):
@file_data('dict.yml')
def test(self, name, age): # 设置入口参数名字与数据参数命名相同即可
print('姓名是:', name, '年龄为:', age)
dict.yml
-
name: 张三
age: 18
-
name: 李四
age: 19
-
name: 王五
age: 20
结果
姓名是: 张三 年龄为: 18
姓名是: 李四 年龄为: 19
姓名是: 王五 年龄为: 20
5.3 特殊情况
当入口与文件中数据参数无法统一命名时,解决办法
层层剥皮,利用**将内容转为字典,进行解包
dict_special.yml
- name: John
age: 30
- name: Alice
age: 25
- name: Bob
age: 35
yaml_drive_special.py
import unittest
from ddt import ddt, file_data
@ddt
class BasicTestCase(unittest.TestCase):
@file_data('dict_special.yml')
def test(self, **cdata): # Python中可变参数传递的知识:**按对象顺序执行
print('姓名是:', cdata['name'], '年龄为:', cdata['age']) # 通过对象访问语法即可调用
dict_spe.yml
- person:
name: John
age: 30
- person:
name: Alice
age: 25
- person:
name: Bob
age: 35
yaml_drive_spe.py
import unittest
from ddt import ddt, file_data
@ddt
class BasicTestCase(unittest.TestCase):
@file_data('dict_spe.yml')
def test(self, **cdata): # 使用 ** 解包
print('姓名是:', cdata['person']['name'], '年龄为:', cdata['person']['age'])
测试套件TestSuite
1.概述
TestSuite 是 unittest 框架中的一个类,用于将多个测试用例或测试类组织在一起,形成一个测试集合。通过使用 TestSuite,可以灵活地控制测试的执行顺序,以及运行特定的测试组。
使用场景
- 组织多个测试用例或测试类。
- 按特定顺序运行测试。
- 灵活控制哪些测试需要运行,而不是运行整个测试模块。
例如:
登陆类测试用例:1.登录成功 2.登录失败
账户类测试用例:1.用户A 2.用户B
测试套件的功能:可单独执行登录类测试用例、执行用户A+登录成功的用例
一个例子
import unittest
class Testcase1_login(unittest.TestCase):
def test1(self):
print('执行Testcase1_login的test1')
def test2(self):
print('执行Testcase1_login的test2')
class Testcase2_data(unittest.TestCase):
def test1(self):
print('执行Testcase2_data的test1')
def test2(self):
print('执行Testcase2_data的test2')
- Testcase.py中有两类测试用例(login和data类),每一类测试用例下有两个测试用例
项目测试目录框架通常为
project/
│
├── tests/ # 存放所有测试用例的目录
│ ├── __init__.py
│ ├── test_math_operations.py
│ └── test_string_operations.py
│
└── test_suite.py # 测试套件文件
测试用例文件和测试套件文件要分开
2.TestSuite的基本框架
import unittest
import Testcases # 导入测试用例,这里模块名是自己建立的测试用例文件名
suite = unittest.TestSuite() # 类的实例化!!!要加括号才是实例化
# 一次添加单个测试用例
suite.addTest(Testcases.Testcase1_login('test1')) # 添加第1类测试用例中的第1个测试用例
suite.addTest(Testcases.Testcase2_data('test1')) # 添加第2类测试用例中的第1次测试用例
r = unittest.TextTestRunner() # 类的实例化!!!要加括号才是实例化,文本运行测试
r.run(suite) # 运行测试套件
如想简化代码,一次添加多个测试用例
suite.addTests([Testcases.Testcase1_login('test1'), Testcases.Testcase2_data('test1')])
通过变量形式指定需要测试的内容,增加可读性
suite = unittest.TestSuite()
# 以变量形式存储指定测试内容,便于修改且增加程序可读性
tests = [
Testcases.Testcase1_login('test1'), # 这里的test1是方法名,特指该方法
Testcases.Testcase2_data('test1')
] # 列表内为测试内容
suite.addTests(tests)
r = unittest.TextTestRunner()
r.run(suite)
3.装载器的分类和使用
在 unittest 框架中,测试套件(TestSuite) 的装载器(TestLoader)用于加载测试用例。它的主要作用是从测试类或测试模块中自动发现并加载测试方法,组织成测试套件以便执行。
它有几种不同的加载方式,主要有以下几种类型和方法:
3.1 loadTestsFromTestCase
- 作用:从一个测试用例类(
TestCase子类)中加载所有测试方法。 - 使用场景:当你想从一个具体的测试类中加载所有的测试方法时使用。
- 示例:
import unittest
class TestMathOperations(unittest.TestCase):
def test_add(self):
self.assertEqual(1 + 1, 2)
def test_subtract(self):
self.assertEqual(5 - 3, 2)
loader = unittest.TestLoader()
suite = loader.loadTestsFromTestCase(TestMathOperations)
runner = unittest.TextTestRunner()
runner.run(suite)
这会自动加载 TestMathOperations 类中的所有以 test_ 开头的方法。
3.2 loadTestsFromModule
- 作用:从指定的模块中加载测试用例。可以是一个 Python 文件或模块。
- 使用场景:当测试方法分散在多个模块中时,使用该方法加载模块中的测试。
- 示例:
import unittest
import my_tests # 假设 my_tests.py 包含测试用例
loader = unittest.TestLoader()
suite = loader.loadTestsFromModule(my_tests)
runner = unittest.TextTestRunner()
runner.run(suite)
这会加载 my_tests.py 中所有符合条件的测试方法。
3.3 loadTestsFromName
- 作用:通过名称加载指定的测试用例或测试方法。你可以通过传递测试用例类的完整路径或测试方法名来加载。
- 使用场景:当你只想加载一个特定的测试用例或测试方法时。
- 示例:
import unittest
class TestMathOperations(unittest.TestCase):
def test_add(self):
self.assertEqual(1 + 1, 2)
def test_subtract(self):
self.assertEqual(5 - 3, 2)
loader = unittest.TestLoader()
suite = loader.loadTestsFromName('TestMathOperations.test_add')
runner = unittest.TextTestRunner()
runner.run(suite)
这里,loadTestsFromName 会加载 TestMathOperations 类中的 test_add 方法。
3.4 loadTestsFromNames
- 作用:与
loadTestsFromName类似,但它可以接受多个名称的列表来加载多个测试方法或用例。 - 使用场景:当你需要加载多个特定的测试方法或测试用例时使用。
- 示例:
import unittest
class TestMathOperations(unittest.TestCase):
def test_add(self):
self.assertEqual(1 + 1, 2)
def test_subtract(self):
self.assertEqual(5 - 3, 2)
loader = unittest.TestLoader()
suite = loader.loadTestsFromNames(['TestMathOperations.test_add', 'TestMathOperations.test_subtract'])
runner = unittest.TextTestRunner()
runner.run(suite)
这会加载 TestMathOperations 类中的 test_add 和 test_subtract 方法。
3.5. discover
- 作用:从一个指定的目录或包中自动发现所有符合条件的测试方法。通常与路径和模式结合使用。
- 使用场景:当你的测试用例分布在多个文件中,并希望自动加载指定目录下所有的测试用例时使用。
- 示例:
import unittest
loader = unittest.TestLoader()
suite = loader.discover(start_dir='tests', pattern='test_*.py')
runner = unittest.TextTestRunner()
runner.run(suite)
这里,discover 会从 tests 目录中加载所有符合 test_*.py 模式的文件,并加载其中的测试方法。
总结:
loadTestsFromTestCase:从一个TestCase类中加载所有测试方法。loadTestsFromModule:从一个模块中加载所有测试方法。loadTestsFromName:根据测试方法的名称加载特定的测试方法。loadTestsFromNames:加载多个指定名称的测试方法或用例。discover:自动发现并加载目录下符合条件的测试用例。
使用装载器的好处: 通过使用装载器,你可以避免手动管理测试方法的列表,而是通过自动化方式来组织和运行你的测试用例,尤其适合处理大量测试用例的情况。
4.装载器的作用
装载器的作用: 装载器(TestLoader)用于从测试用例类、模块或目录中自动加载测试方法。它帮助你管理和组织测试用例的加载过程,使得你可以灵活地加载指定的测试方法或测试套件。
相对于不使用装载器的优势:
- 自动化加载:无需手动列出每个测试方法或用例,装载器可以根据指定的条件自动加载所有符合要求的测试。
- 灵活性:可以加载单个测试方法、多个方法、整个测试类或模块,甚至支持按文件目录和名称模式批量加载。
- 可扩展性:适用于测试用例数量较多时,避免手动管理大量测试方法,提升测试的可维护性和可扩展性。
- 提高效率:在运行测试时,可以动态地选择和加载测试方法,减少人工干预和可能的遗漏。
使用场景:
- 自动发现测试用例:当你希望自动从目录或模块中加载符合一定命名规范的测试用例时,使用
discover方法。 - 加载特定测试用例或方法:使用
loadTestsFromTestCase、loadTestsFromModule或loadTestsFromName来加载特定的测试类、模块或方法。 - 分布式测试管理:在多个测试文件或模块中分散测试用例时,使用装载器可以方便地将这些分散的测试用例统一管理并执行。
- 定制化测试加载:需要根据特定条件(如路径、名称模式等)动态加载测试用例时,装载器提供了灵活的解决方案。
通过装载器,你可以高效地管理和执行测试,尤其在测试用例很多的情况下。
5.生成测试报告网页版
第三方包:https://github.com/findyou/HTMLTestRunnerCN/tree/master/python3x
在装载器的代码中,修改运行部分即可
import unittest
from demo3.HTMLTestReportCN import HTMLTestRunner
class Testcase1_login(unittest.TestCase):
def test1(self):
print('执行Testcase1_login的test1')
def test2(self):
print('执行Testcase1_login的test2')
class Testcase2_data(unittest.TestCase):
def test1(self):
print('执行Testcase2_data的test1')
def test2(self):
print('执行Testcase2_data的test2')
# 前文提到过滤装载器的代码
all_tests = unittest.defaultTestLoader.discover(start_dir='./', pattern='Testcase*.py')
runner = unittest.TextTestRunner()
runner.run(all_tests)
# 在过滤装载器代码基础上,改动runner部分生成HTML报告
# 笔者下载了HTMLTestReportCN为例,注意HTMLTestReportCN.py放在同一文件夹下
# 使用语句from HTMLTestReportCN import HTMLTestRunner导入生成HTML的Runner
all_tests = unittest.defaultTestLoader.discover(start_dir='./', pattern='Testcase*.py')
r = open('report_file.html', 'wb') # 新建一个html文件并以二进制方式写入
runner = HTMLTestRunner(title='测试报告标题', description='测试描述', stream=r) # 改变Runner,设置报告参数
runner.run(all_tests)
结果
