easy_lab2
作业地址:https://github.com/BUPT-OS/easy_lab/tree/lab2
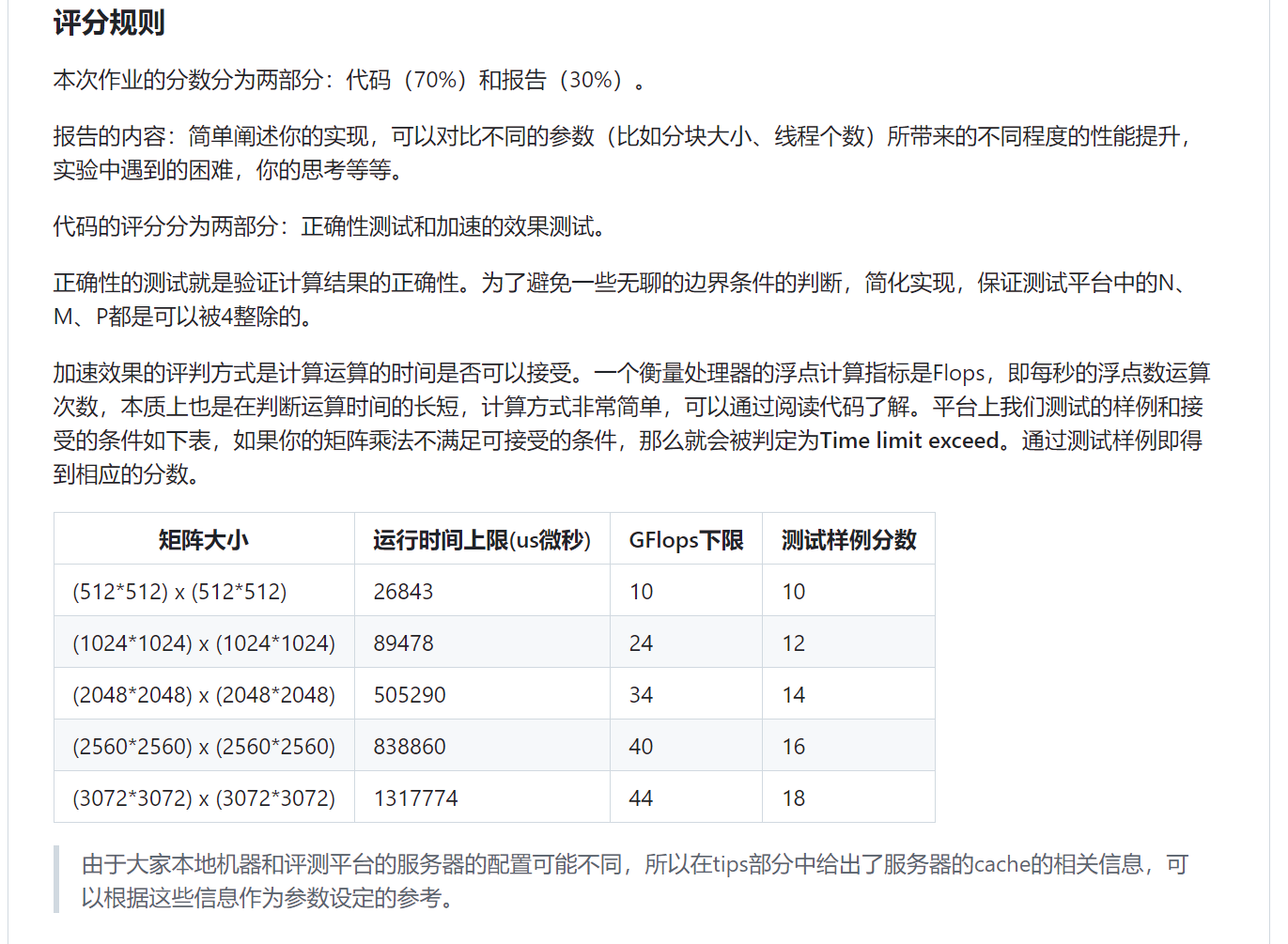
以下均为multiply.cpp代码
22分多线程,分块,调整计算顺序
#include "multiply.h"
#include <emmintrin.h> // SSE2
#include <pmmintrin.h> // SSE3
#include <thread>
#include <vector>
// 定义块大小和线程数量
#define BLOCK_SIZE 32
void block_multiply(double matrix1[N][M], double matrix2[M][P], double result_matrix[N][P],
int i_start, int i_end, int j_start, int j_end)
{
for (int ii = i_start; ii < i_end; ii += BLOCK_SIZE) {
for (int jj = j_start; jj < j_end; jj += BLOCK_SIZE) {
for (int kk = 0; kk < M; kk += BLOCK_SIZE) {
// 块内循环
for (int i = ii; i < ii + BLOCK_SIZE && i < i_end; i++) {
for (int j = jj; j < jj + BLOCK_SIZE && j < j_end; j++) {
__m128d sum = _mm_setzero_pd(); // 初始化 SIMD 累加器
// 使用循环展开和 SIMD 加速
int k;
for (k = kk; k <= kk + BLOCK_SIZE - 2 && k < M; k += 2) {
__m128d m1 = _mm_loadu_pd(&matrix1[i][k]);
__m128d m2 = _mm_set_pd(matrix2[k+1][j], matrix2[k][j]);
sum = _mm_add_pd(sum, _mm_mul_pd(m1, m2));
}
double temp[2];
_mm_storeu_pd(temp, sum);
result_matrix[i][j] += temp[0] + temp[1];
// 处理剩余的元素
for (; k < kk + BLOCK_SIZE && k < M; k++) {
result_matrix[i][j] += matrix1[i][k] * matrix2[k][j];
}
}
}
}
}
}
}
void matrix_multiplication(double matrix1[N][M], double matrix2[M][P], double result_matrix[N][P])
{
// 初始化结果矩阵
for (int i = 0; i < N; i++) {
for (int j = 0; j < P; j++) {
result_matrix[i][j] = 0.0;
}
}
// 确定线程数量
int num_threads = std::thread::hardware_concurrency();
std::vector<std::thread> threads;
int rows_per_thread = N / num_threads;
// 创建线程池
for (int t = 0; t < num_threads; t++) {
int i_start = t * rows_per_thread;
int i_end = (t == num_threads - 1) ? N : (t + 1) * rows_per_thread;
// 每个线程处理矩阵的一个子块
threads.emplace_back(block_multiply, matrix1, matrix2, result_matrix, i_start, i_end, 0, P);
}
// 等待所有线程完成
for (auto &th : threads) {
th.join();
}
}
36分
#include "multiply.h"
#include <cstdio>
#include <thread>
#include <immintrin.h>
#include <pmmintrin.h>
#include <algorithm>
#include <pthread.h>
#define L1_BLOCK_SIZE 64
#define L2_BLOCK_SIZE 128
#define L3_BLOCK_SIZE 256
typedef struct {
int thread_id;
double (*matrix1)[M];
double (*matrix2)[P];
double (*result_matrix)[P];
int block_size;
} ThreadData;
void block_matrix_multiply(double (*matrix1)[M], double (*matrix2)[P], double (*result_matrix)[P],
int row_start, int row_end, int col_start, int col_end, int mid_start, int mid_end, int block_size) {
for (int i = row_start; i < row_end; i++) {
double *temp_rm = result_matrix[i];
for (int k = mid_start; k < mid_end; k++) {
double temp_m1 = matrix1[i][k];
double *temp_m2 = matrix2[k];
int j = col_start;
for (; j + 7 < col_end; j += 8) {
__m512d m1 = _mm512_set1_pd(temp_m1);
__m512d m2 = _mm512_loadu_pd(temp_m2 + j);
__m512d rm = _mm512_loadu_pd(temp_rm + j);
__m512d res = _mm512_fmadd_pd(m1, m2, rm); // FMA 优化
_mm512_storeu_pd(temp_rm + j, res);
}
for (; j < col_end; j++) {
temp_rm[j] += temp_m1 * temp_m2[j];
}
}
}
}
void* thread_matrix_multiply(void* arg) {
ThreadData* data = (ThreadData*)arg;
int NUM_THREADS = std::thread::hardware_concurrency();
int rows_per_thread = (N + NUM_THREADS - 1) / NUM_THREADS;
int start_row = data->thread_id * rows_per_thread;
int end_row = std::min(start_row + rows_per_thread, N);
for (int i = start_row; i < end_row; i += data->block_size) {
int block_i_end = std::min(i + data->block_size, end_row);
for (int j = 0; j < P; j += data->block_size) {
int block_j_end = std::min(j + data->block_size, P);
for (int k = 0; k < M; k += data->block_size) {
int block_k_end = std::min(k + data->block_size, M);
block_matrix_multiply(data->matrix1, data->matrix2, data->result_matrix,
i, block_i_end, j, block_j_end, k, block_k_end, data->block_size);
}
}
}
pthread_exit(NULL);
}
void matrix_multiplication(double matrix1[N][M], double matrix2[M][P], double result_matrix[N][P]) {
// 初始化结果矩阵
for (int i = 0; i < N; ++i) {
for (int j = 0; j < P; ++j) {
result_matrix[i][j] = 0.0;
}
}
int NUM_THREADS = std::thread::hardware_concurrency();
pthread_t threads[NUM_THREADS];
ThreadData thread_data[NUM_THREADS];
// 动态选择分块大小
int block_size;
if (N >= 2048) {
block_size = L3_BLOCK_SIZE;
} else if (N >= 1024) {
block_size = L2_BLOCK_SIZE;
} else {
block_size = L1_BLOCK_SIZE;
}
for (int i = 0; i < NUM_THREADS; i++) {
thread_data[i].thread_id = i;
thread_data[i].matrix1 = matrix1;
thread_data[i].matrix2 = matrix2;
thread_data[i].result_matrix = result_matrix;
thread_data[i].block_size = block_size;
pthread_create(&threads[i], NULL, thread_matrix_multiply, (void*)&thread_data[i]);
}
for (int i = 0; i < NUM_THREADS; i++) {
pthread_join(threads[i], NULL);
}
}
70分:加上o3优化,会快非常多
#include "multiply.h"
#include <cstdio>
#include <thread>
#include <immintrin.h>
#include <pmmintrin.h>
#include <algorithm>
#include <pthread.h>
#pragma GCC optimize("O3")
#define L1_BLOCK_SIZE 64
#define L2_BLOCK_SIZE 128
#define L3_BLOCK_SIZE 256
typedef struct {
int thread_id;
double (*matrix1)[M];
double (*matrix2)[P];
double (*result_matrix)[P];
int block_size;
} ThreadData;
void block_matrix_multiply(double (*matrix1)[M], double (*matrix2)[P], double (*result_matrix)[P],
int row_start, int row_end, int col_start, int col_end, int mid_start, int mid_end, int block_size) {
for (int i = row_start; i < row_end; i++) {
double *temp_rm = result_matrix[i];
for (int k = mid_start; k < mid_end; k++) {
double temp_m1 = matrix1[i][k];
double *temp_m2 = matrix2[k];
int j = col_start;
for (; j + 7 < col_end; j += 8) {
__m512d m1 = _mm512_set1_pd(temp_m1);
__m512d m2 = _mm512_loadu_pd(temp_m2 + j);
__m512d rm = _mm512_loadu_pd(temp_rm + j);
__m512d res = _mm512_fmadd_pd(m1, m2, rm); // FMA 优化
_mm512_storeu_pd(temp_rm + j, res);
}
for (; j < col_end; j++) {
temp_rm[j] += temp_m1 * temp_m2[j];
}
}
}
}
void* thread_matrix_multiply(void* arg) {
ThreadData* data = (ThreadData*)arg;
int NUM_THREADS = std::thread::hardware_concurrency();
int rows_per_thread = (N + NUM_THREADS - 1) / NUM_THREADS;
int start_row = data->thread_id * rows_per_thread;
int end_row = std::min(start_row + rows_per_thread, N);
for (int i = start_row; i < end_row; i += data->block_size) {
int block_i_end = std::min(i + data->block_size, end_row);
for (int j = 0; j < P; j += data->block_size) {
int block_j_end = std::min(j + data->block_size, P);
for (int k = 0; k < M; k += data->block_size) {
int block_k_end = std::min(k + data->block_size, M);
block_matrix_multiply(data->matrix1, data->matrix2, data->result_matrix,
i, block_i_end, j, block_j_end, k, block_k_end, data->block_size);
}
}
}
pthread_exit(NULL);
}
void matrix_multiplication(double matrix1[N][M], double matrix2[M][P], double result_matrix[N][P]) {
// 初始化结果矩阵
for (int i = 0; i < N; ++i) {
for (int j = 0; j < P; ++j) {
result_matrix[i][j] = 0.0;
}
}
int NUM_THREADS = std::thread::hardware_concurrency();
pthread_t threads[NUM_THREADS];
ThreadData thread_data[NUM_THREADS];
// 动态选择分块大小
int block_size;
if (N >= 2048) {
block_size = L3_BLOCK_SIZE;
} else if (N >= 1024) {
block_size = L2_BLOCK_SIZE;
} else {
block_size = L1_BLOCK_SIZE;
}
for (int i = 0; i < NUM_THREADS; i++) {
thread_data[i].thread_id = i;
thread_data[i].matrix1 = matrix1;
thread_data[i].matrix2 = matrix2;
thread_data[i].result_matrix = result_matrix;
thread_data[i].block_size = block_size;
pthread_create(&threads[i], NULL, thread_matrix_multiply, (void*)&thread_data[i]);
}
for (int i = 0; i < NUM_THREADS; i++) {
pthread_join(threads[i], NULL);
}
}