>>更多PDF文件处理应用技巧请前往 96缔盟PDF处理器 主页 查阅!
———————————————————————————————————————
当然了,单个文件或者其他任意的文件个数的拆分也是支持的!
序言
我之前的文章也有介绍过如何使用96缔盟PDF处理器对PDF文件批量拆分的介绍,但是当时是使用DMPDFUtilTool1.0版本进行的,当时的功能尚不完善,还不支持拖拽添加文件,而且产品本身也存在一些BUG。DMPDFUtilTool1.2版本的发版,增加了拖拽添加文件的功能,同时对各个功能和一些已知BUG做了修复。尤其对批量拆分PDF的功能在性能和稳定性上有了较大的提高和改善。因此,本文重新对PDF文件的批量拆分做介绍。
一、需求背景
在日常工作中,可能需要将一个较大的PDF文件分割成多个较小的PDF文件,以便满足诸如提高查阅效率、打印、团队合作与分发以及文件的管理与存储等需要。
同时,当我们需要提取的文件是同类型模板的大批量的文件时,哪怕有专业的PDF拆分工具,如果不能同一时间拆分多份文件,对用户来讲,仍然需要相当的工作量来逐个文件处理。因此用户盼望有一个PDF分割工具可以对某一批量的文件做分割,96缔盟PDF处理器的拆分功能也应运而生,满足用户对批量PDF文件的拆分处理。
对于大批量PDF文件的拆分和处理,对软件的处理性能要求就比较高,往往很多专业的PDF处理工具在分割处理一个或者少量普通文件的时候没有问题,但是同时处理这种大批量的PDF文件就会出现运行缓慢、报错率高等稳定性低下的问题,甚至还会出现长时间卡顿、闪退等严重问题。
同超大PDF文件的处理一样,大批量PDF文件同时处理,也是对软件处理能力的极限考验!很多专业的PDF处理工具都倒在了这样的极限考验之下。所幸,96缔盟PDF处理器经受住了考验,对于大批量文件的处理,它展现出了极高的处理效率和超高的稳定性。
下面的内容我们详细介绍一下,如何对大批量的PDF文件进行分割。小编准备了30个文件,每个文件为668页进行分割。相当于一次性处理的总页数达到了20040页,当然这也不是软件的极限,仅仅作为演示,来初步展示一下96缔盟PDF处理器的超强性能。如下图所示:
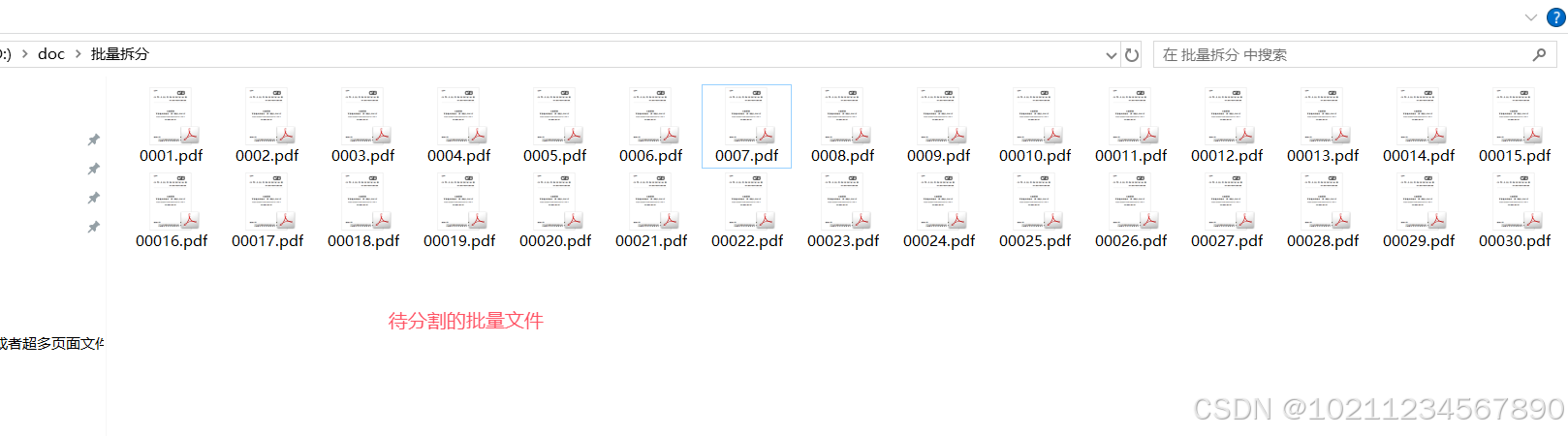
我们的处理需求是批量的将这30个文件中的每个文件都分割成每10页一个小文件。以下是具体操作步骤。
- 操作步骤
- 打开主界面,点击“PDF文件拆分”,进入PDF分割的操作界面。
如下图:
进入PDF文件拆分的子界面,如下图:
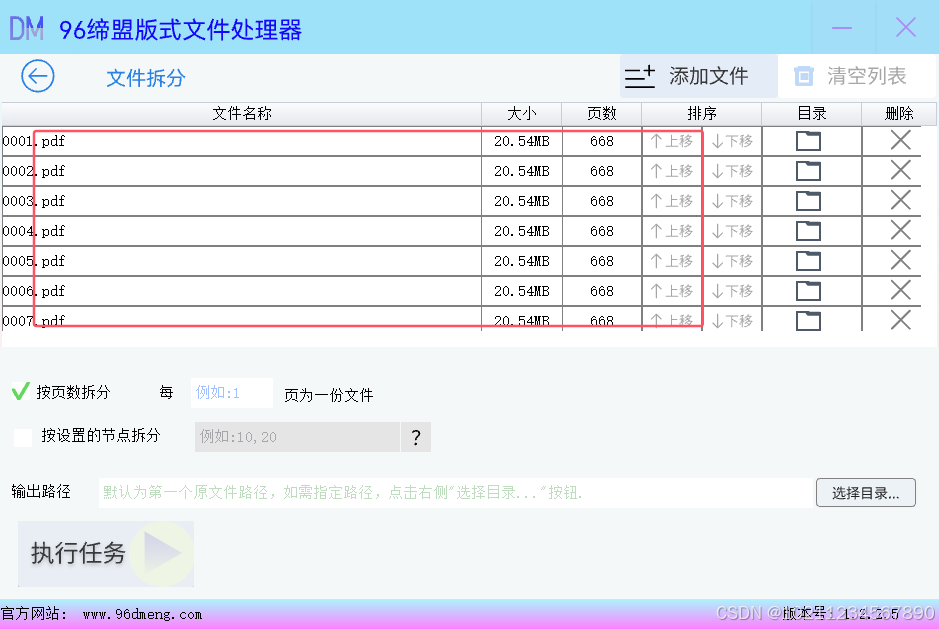
- 添加需要分割的批量PDF文件
可以直接将批量 PDF 文件拖拽到PDF拆分子界面的文件列表框中,或者点击右上方的”添加文件”按钮,在选择文件对话框里批量选择多个文件,当然,也可以通过多次拖拽或多次添加的方式添加文件。如下图所示,总共添加了30个文件,每个文件668页,即需要处理的文件总页数为20040页
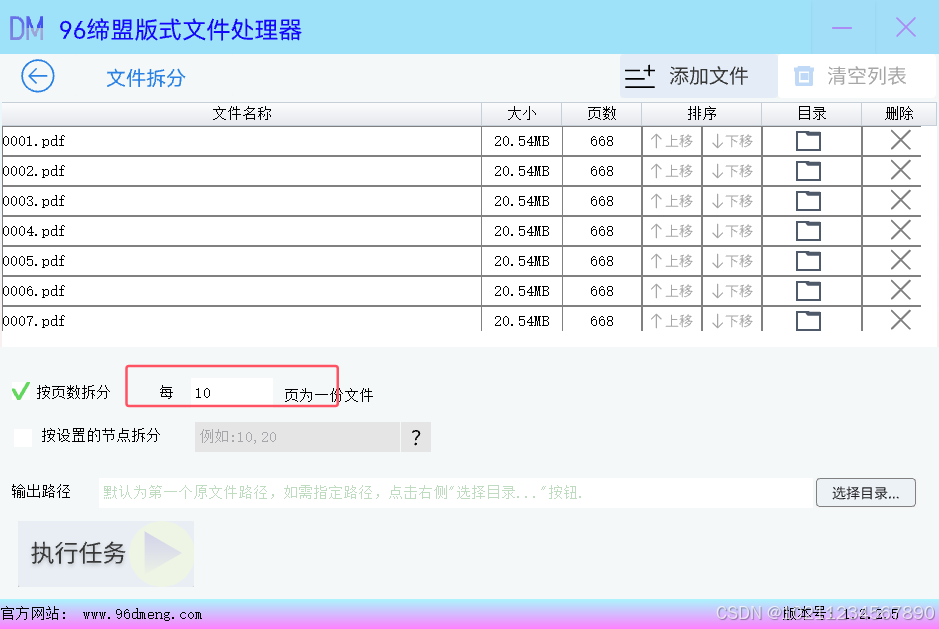
- 设置拆分方式
我们选择”按页数拆分”的方式,并在右侧的编辑框里输入”10”,表示我们将选定的所有PDF文件每一个文件都分割成每10页为一个小文件。如下图:
- 输出路径选择
默认可以不用选择,操作完成执行后的文件将在第一个原文件所在的路径下创建一个新的文件夹存放操作后的文件。如果想指定那么可以点击右侧的“选择目录…”指定需要的目录。如下图
- 执行拆分任务
点击一下“执行任务”按钮即可!虽然PDF文件很多,每一个PDF文件的页数很多,需要分割的小PDF文件数量也很多,但是本次分割也仅仅耗时大约10秒左右就完成了!如图:
- 查看拆分后的执行结果
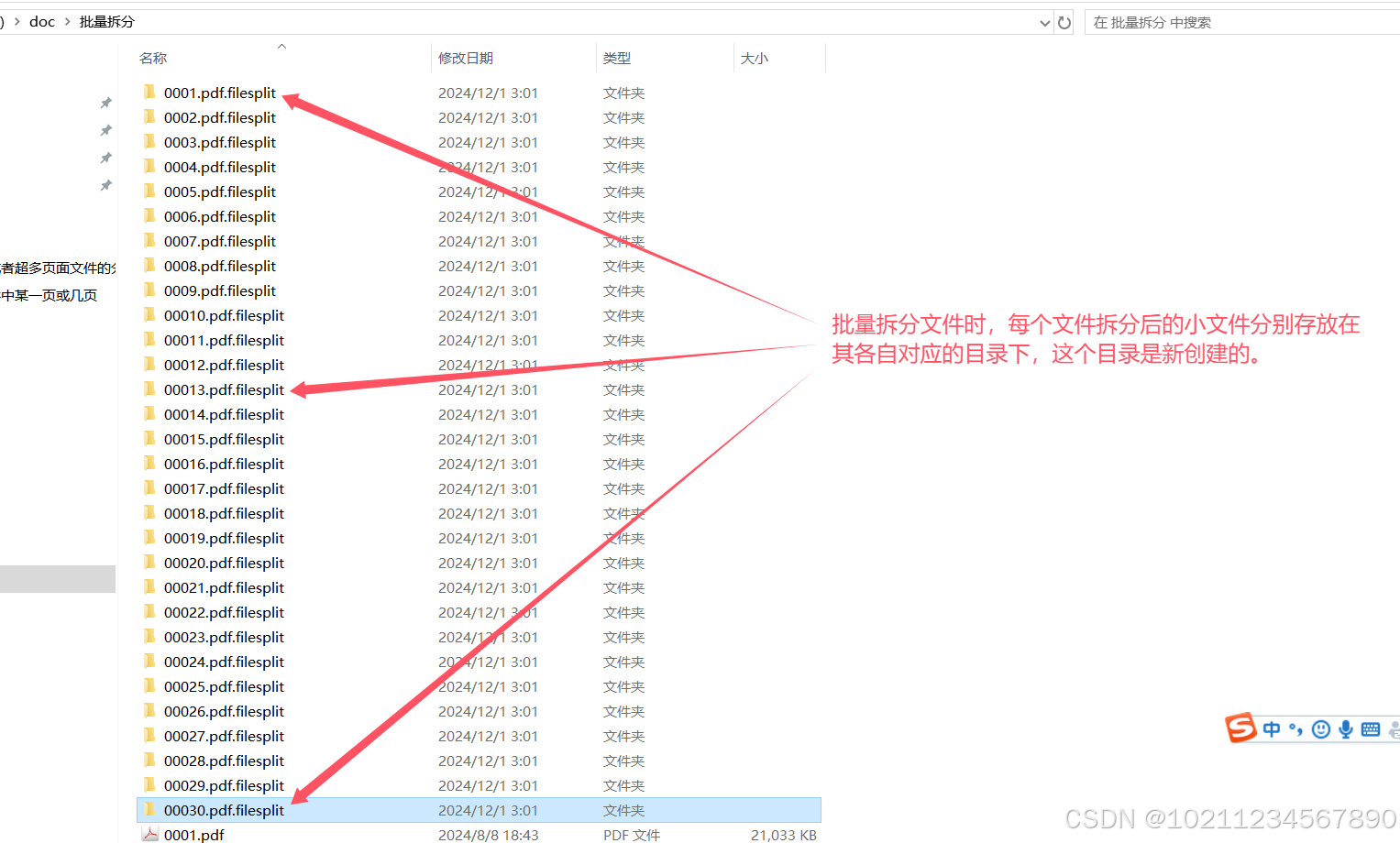
说明:默认情况,本工具会在原始文件的目录下为每一个需要分割的PDF文件创建一个新的目录用来保存分割后的小PDF文件,名为”原始文件名(默认是文件列表的第一个原始文件). filesplit”的目录。
我们进入其中的目录查看,每一个对应的分割目录里面有软件为我们分割好的67个小文件,如下图:
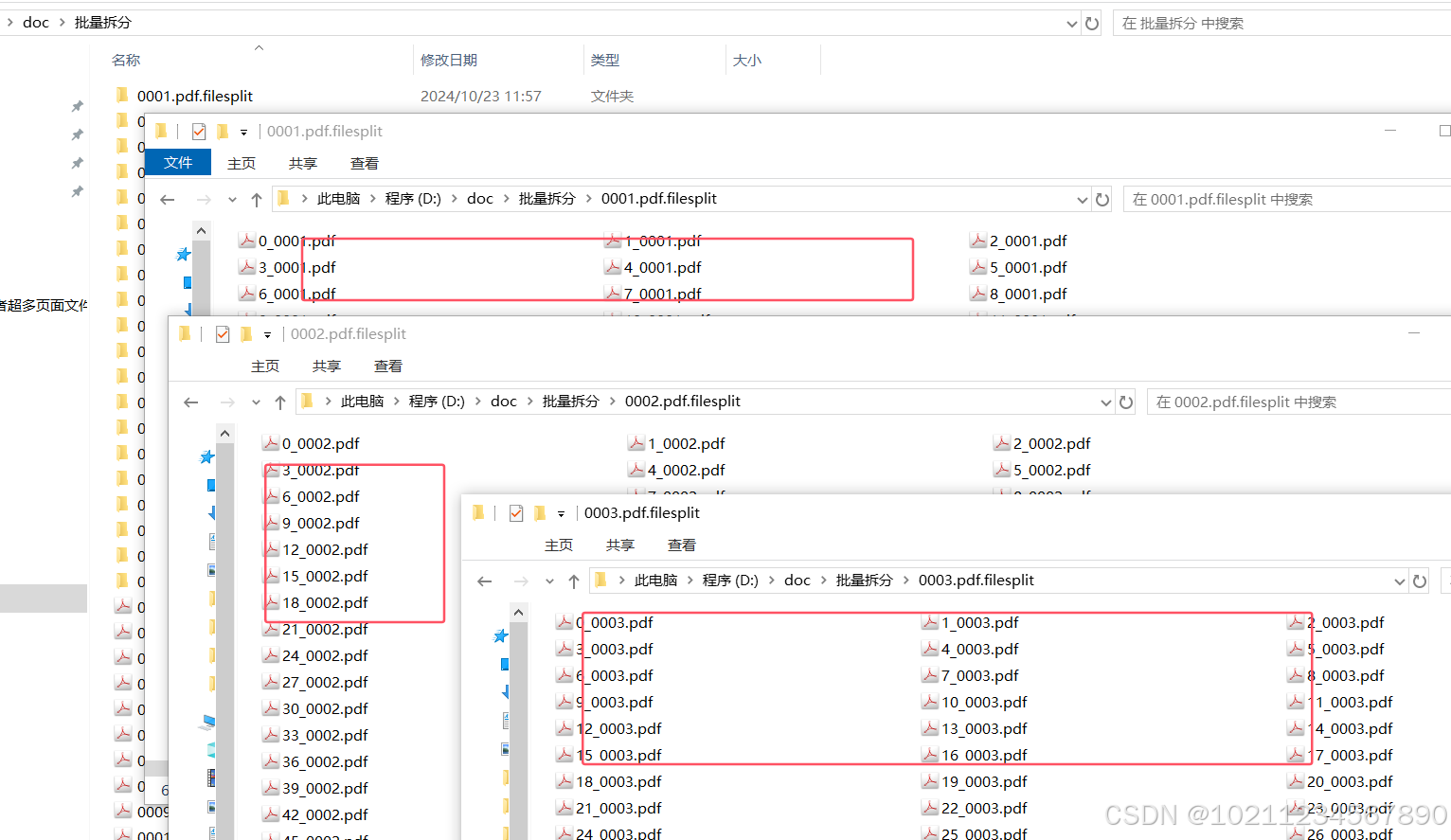
依次进入各个目录打开各个文件查看,依次按指定的页码顺序,每10为一个小文件,如下图:
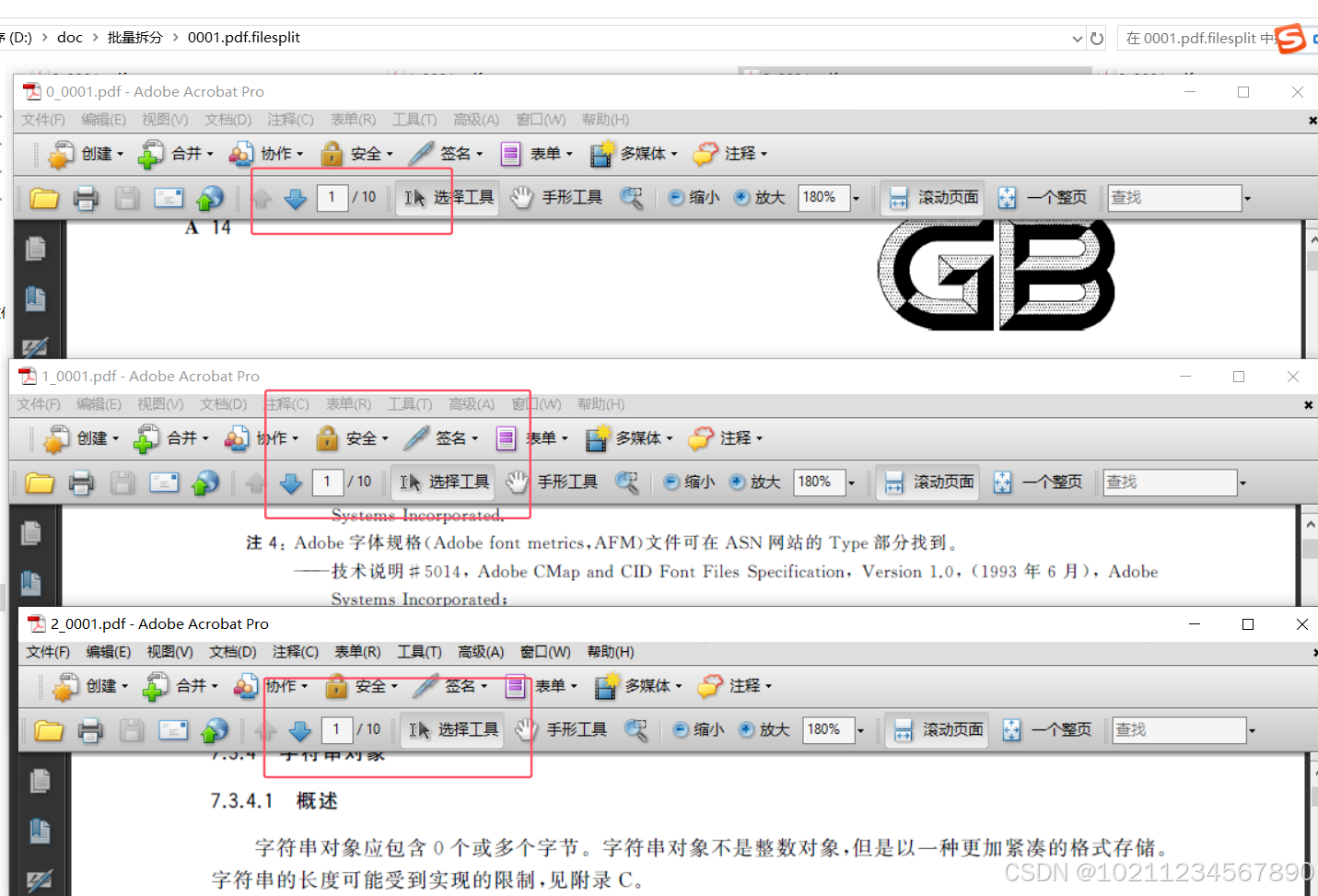
就这样,我们轻松的就完成了30个PDF文件,总页数20040页的文件的分割工作,且非常高效、准确、稳定的完成了!可见,96缔盟PDF处理器其实丝毫不亚于同类产品中的大厂家的产品!
三、96缔盟pdf版式文件处理器
96缔盟PDF版式文件处理器(下载地址:https://www.96dmeng.com/)是一款完全免费的PDF处理工具。操作简单实用,并且非常专业、高效、安全!而且虽然是免费使用,但也不会做在处理后的文件页面添加水印等流氓行为。
目前提供的功能有PDF文件的拆分、合并,转换图片、提取图片和文本内容、添加水印、设置权限密码/修改密码/解除密码,以及破损的PDF文件修复等诸多实用性非常强的功能,并且提供了绿色版和安装版供用户自行选择。
标签:缔盟,分割,批量,文件,处理,拆分,PDF From: https://blog.csdn.net/2403_87127097/article/details/144271523