
11月26日,华为Mate品牌盛典上,HUAWEI Mate X6正式亮相。继去年的HUAWEI Mate X5一机难求之后,华为又一次点燃了折叠屏市场。
作为到手即可升级“纯血鸿蒙”的折叠屏手机、华为首个“自研完全体”的折叠屏旗舰,HUAWEI Mate X6在多个维度实现了再跨越:轻薄、坚固、耐用、性能、功耗、通信、续航、AI智能化等等。
从没有被超越过的华为折叠屏,每一次创新都是对自己的再跨越。
这一次HUAWEI Mate X6成为了折叠屏全能新标杆。用华为常务董事、终端BG董事长、智能汽车解决方案BU董事长余承东的话说就是:“折叠引领者,巅峰再跨越,HUAWEI Mate X6从内到外强得飞起,为消费者带来全面革新的折叠屏体验。”
吊摩托,切冰块,强得飞起
未售先火。因为预见到新一代折叠机Mate X6一机难求的局面,华为早早开启了预约,只有预约的用户,才有资格购买。说白了,想买的人太多了,先举手报名才有机会。
为什么HUAWEI Mate X6预售这么火?一是华为几代折叠屏手机沉淀下来的口碑,已经形成很强的用户认知:折叠屏,华为的最好。二是这一代新折叠屏堪称华为黑科技的集大成之作,在折叠屏市场一路领跑五年,特别是今年三折叠的亮相,更是使得华为的技术水平实现了跨越式的成长。有了三折叠的磨练,再做一个双折叠,只会更优秀。
在盛典现场,懂懂对两个演示印象深刻。

为了手机更坚固,华为创新了内屏支撑层的材料。这个碳纤维有多强呢?抗变形能力达380GPa,刚度提升65%。在现场有一个非常有趣的实验,一小块碳纤维,可以吊起一辆308斤重的摩托车,如果不是亲眼所见,懂懂是不敢相信的。

折叠屏做得更薄,散热就是问题,为了解决这个难题,华为研发了全新具备超高导热性的石墨稀材料,等效导热系数达2000W/m-K,导热能力提升33%。这个超高导热的材料,切冰可以像切豆腐一样轻松。
透过这两个实例,看到华为的每一项技术跨越,背后都是无数个极致创新换来的。
在懂懂看来,内外兼修,样样都强的HUAWEI Mate X6值得拎出来说说的创新非常多,在这里重点说四个。

一是创新的分布式玄武架构。通过对整机架构的重构以及新材料工艺的研发,外部机身更坚固,整机更轻薄,内部则有更多的空间去提升散热和通信能力,实现整机能力的全方位的跨越。

二是通信能力。专业通信起家的华为,一直是手机信号最强的品牌。这一次不仅综合信号强度提升60%,更重要的是卫星通信能力再跨越,华为Mate X6三网卫星典藏版成为全球首款支持三网卫星通信的大众智能手机(低轨卫星互联网系统测试中,预计将于2025年下半年开启众测)。

三是影像,华为让自己的长板更长。华为拍照好已是用户共识,但华为永不止步,每一次产品迭代都要比好更好。HUAWEI Mate X6突破性地采用150万多光谱通道红枫原色摄像头,色彩还原度提升120%,无论肤色、衣色还是自然色彩,都能准确捕捉并还原。我们知道,今天智能手机拍照普遍不错,但是有很多美来自于软件修片的能力,有些用户追求真实,希望所见及所得,还原肉眼所见。此次红枫原色影像系统,就是将真实还给用户,记录自然之美。

四是大屏应用。折叠屏之所以被用户喜爱,不止是因为形态新颖,更是因为大屏不能被取代的应用体验。比如,全景多窗可以同时打开三个应用,开会、查资料、聊天三不误。再比如钉钉文档和搜狐新闻可实现智能摘要,微博支持智能扩写。多家头部应用都针对Mate X6大屏做了适配,Mate X6可以轻松处理文档,可以沉浸式观影、打游戏,炒股的时候可以一屏尽览全局。这些体验,都是直板机上无法感受的。
特别值得一提的是隔空操作,基于鸿蒙生态的设备之间可以隔空取“图”,使用更便捷。这次Mate X6还在大屏上设计了一个隔空投篮的游戏,大屏模式下,游戏画面得以全面扩展,带来更沉浸的投篮体验。
影像再跨越,性能再跨越,通信于跨越,续航再跨越,大屏体验再跨越,这一次华为HUAWEI Mate X6是一个全能选手,不止是没短板,而是面面俱强,强得飞起。给出了折叠屏的“全能教科书”。
风景独好,来自于绝对优势

一年爆三次,华为折叠屏每推出一款都会在市场上引起一阵轰动。
今年2月上市的全新小折叠旗舰手机HUAWEI Pocket 2,作为科技美学的新标杆在时尚圈掀起一波热潮,为消费者提供多样的高奢时尚选择,特别是在女性用户群体中大受欢迎。
今年9月上市的三折叠Mate XT非凡大师,可以说是给整个市场带来极大的震撼,Mate XT非凡大师折叠后的轻薄、以及打开后的大屏,让人们对未来手机发展的空间有了无限的象限力。虽然是市场上最贵的折叠屏,但仍然是一机难求,那时候能抢到一台Mate XT非凡大师,很值得在朋友圈里炫耀一番。
再就是这次Mate X6,延续着去年Mate X5的热度,售价12999元起,上市前已经预订破百万。
与华为折叠屏持续保持高热度不太一样的是,今年整体折叠屏市场似乎有点低迷。
作为一个新品类,过去几年间折叠屏一直被认为是智能手机市场增长的新引擎。在过去四年间,折叠屏也确实经历了高速增长阶段,连续四年实现超过100%的同比增长。但是今年以来整体折叠屏行业增速放缓,市场调研机构CINNO Research公布了2024年国内第三季度折叠屏手机销售情况,第三季度销量为354万台,同比增长79%,环比增长35%。Canalys的数据是2024年前三季度全球折叠屏出货1380万,相较于去年同期增长25%。其中,中国折叠屏市场占全球43%,前三季度出货590万,同比增长38%,增速维持高位的情况下有所放缓。
与此同时,部分厂商陷销量难题,甚至有的停止部分机型的更新。两三年前众厂商对折叠屏的热情已经消退。
整体市场的略显低迷与华为折叠屏的一路高歌猛进形成反差,并不是折叠屏这个品类不行,而是一些厂商没有想清楚如何做好一台用户喜爱的折叠屏。好的折叠屏,依然受到用户的追捧。
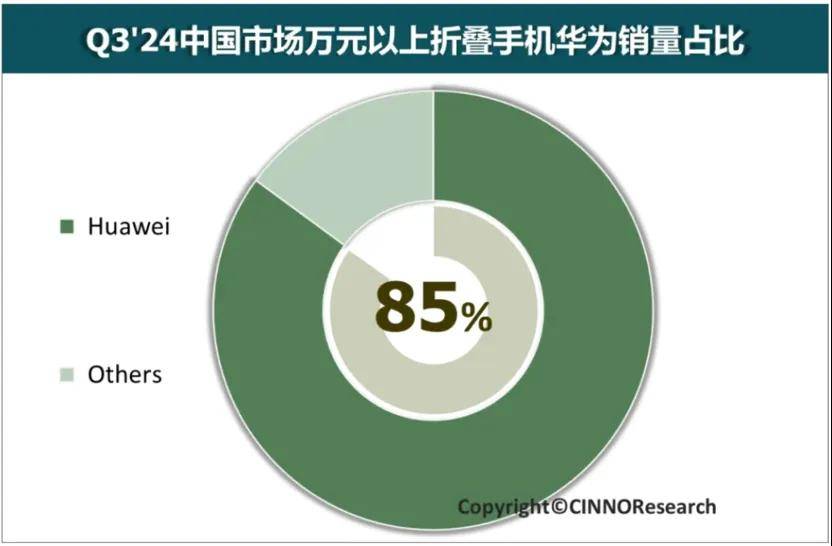
IDC数据显示,2024年第三季度国内折叠屏市场华为占比高达41%,份额是第二名的约两倍。CINNO Research最新数据,在真正万元以上的“金线市场”,华为折叠屏更是占据了85%的市场份额,形成了高端市场“无对手”的绝对领跑优势。
为什么华为风景独好?
折叠屏产品经历了五年探索、打磨,产品形态已经基本稳定。从渗透率看,今年Q3每卖出100台手机就有4台折叠屏手机。可以确定折叠屏处于小众高端区间。

折叠屏本身还是高端产品,吸引的是喜欢尝鲜的、追求科技感的人群。对他们而言,价格并不是最敏感的因素。高端用户更在意产品品质与体验,折叠屏于他们是身份象征,也是生产力工具。
所以我们看到市场上有的产品以低配做折叠屏手机,以低价冲市场,效果并不显著,甚至还影响了口碑。在一众厂商将折叠屏价格下探至3000元的中低端价格段的时候,华为的万元以上折叠机依然供不应求。
华为风景独好的背后,是折叠屏市场正在形成“一极多强”的新格局。华为在折叠屏市场的绝对优势已经确立。
一步先,步步先,每一步都是一大步
五年前,当折叠屏刚刚来到人们面前的时候,一面是对全新产品的惊呼,一面是对新形态的质疑:折叠屏真有的存在的价值吗?不是过渡性产品吗?
当时,折叠屏的第一道门坎还没有迈过,就是如何更好的折叠,手机厚重、折痕明显、折叠寿命短、续航差,硬件形态的第一关需要铰链、屏幕、架构等持续创新才能被突破。
2019年推出第一款折叠屏HUAWEI Mate X,实现了零的突破,让人们相信折叠屏可以实现。
以铰链为例,这是折叠屏实现的一个关键技术,并且没有现成的供应商。“一切都是从用户体验出发”的华为死磕技术。华为 Mate X 首创的鹰翼折叠铰链技术,开创折叠屏手机“无缝外折”的先河。到华为 Mate X2 采用楔形机身和水滴铰链,首次实现了折叠屏的无缝内折。华为P50 Pocket升级新一代水滴铰链,先行落地无缝小折叠。Mate X3的铰链在结构与材料上持续优化,则首次做到了比直板手机更轻薄,让厚重不再是制约折叠屏手机手感的因素。
可以说,至此华为引领折叠屏进入第二个阶段,从能折到能可用。必须承认一点,早年很多买折叠屏的用户是被新的产品形态吸引,那时候的折叠屏还不是很完美,软件适配生态不完善,比旗舰机厚重,有一些应用创新,但大屏刚需不显著。
从能折到可用,华为带领折叠屏这个新品类也实现了从零的突破到品类确立的跃迁:折叠屏比肩旗舰的厚度、重量、应用体验,让更多的人愿意选择折叠屏,用户的心态多猎奇到尝鲜,体会到折叠屏带来的真正好处。
去年下半年上市的Mate X5创造了折叠屏的高光时刻,集成灵犀通信、隔空手势、湿手触控、XMAGE影像、AI云增强等众多黑科技,成为“无短板”的“十项全能”折叠屏。折叠屏从能折、可用进入到第三阶段——好用。
折叠屏在品类确立之后,也开始进入新的发展阶段,以前很多用户会对比旗舰机和折叠屏,两个产品现在已经两条赛道上奔跑,各有个的优势,各有个的受众。

五年时间,华为通过不断创新,为市场带来了内折、外折、竖向小折、三折全品类折叠屏,每一种形态都有独特的应用场景,满足用户不同的需求。华为是目前折叠屏市场品类最全的厂商,技术创新使得华为在折叠屏领域一步领先、步步领先。余承东之所以用“再跨跃”这个词,正是因为华为每一步都是一大步,带着产业不断向前跨跃。
在折叠屏的赛道上,华为是开拓者,引路人,也是铺路人。五年前,折叠屏的供应链为零,铰链、柔性屏、电池等技术都要与上游供应商联合创新,还要带着他们一起建生产线,一起提升良品率,把控品质。华为的折叠屏创新史,也是中国手机供应链的成长史。供应链的成长与成熟,将有帮助中国的手机厂商走得更远。
昨天在盛典上,余承东说了一句话:“靠抄袭是没有未来的。“其实这句话用在折叠屏市场非常恰当。华为一直在引领创新,也自然成为市场的赢家,用户对华为的折叠屏产生了强信任感。所以才会带来强得飞起的体验和”风景独好“的盛况。
标签:折叠,跨越,HUAWEI,华为,Mate,X6 From: https://www.cnblogs.com/dongdongbiji/p/18575469