信息搜集
- 域名信息(whois,备案信息,子域名)
- 服务器信息(端口、服务、真是IP)
- 网站信息(网站架构、操作系统、中间件、数据库、编程语言、指纹信息,WAF、敏感目录、敏感文件、源码泄露、旁站、C段)
- 管理员信息(姓名,职务,生日,联系电话、邮件地址)
一、查看CND,域名注册信息[被动搜集]
1、爱站查看域名注册信息
查看相关域名信息
2、微步社区云沙箱检测
查看域名解析
3、DNS检测
nslookup [域名]
C:\Users\Lxp>nslookup www.baidu.com
服务器: public-dns-a.baidu.com
Address: 180.76.76.76
非权威应答:
名称: www.baidu.com
Addresses: 240e:ff:e020:966:0:ff:b042:f296
240e:ff:e020:9ae:0:ff:b014:8e8b
183.2.172.185
183.2.172.42
C:\Users\Lxp>nslookup www.jlthedu.com
服务器: public-dns-a.baidu.com
Address: 180.76.76.76
非权威应答:
名称: www.jlthedu.com
Address: 122.137.69.228 #不存在CDN 真是IP为122.137.69.228
4、国外whois
5、阿里云域名信息查询
6、腾讯查询
https://whois.cloud.tencent.com/
7、中国互联网信息中心
8、ICP(Internet Content Provider)备案查询
可以查询该单位备案的其它网站
9、国家企业信用信息公示系统
http://www.gsxt.gov.cn/index.html
10、ICP备案查询网
11、ICP备案查询 - 站长工具
12、天眼查
根据前面获取的企业名称可以获取目标企业的微信公众号、微博、备案站点、APP、软件著作权等信息
13、企查查
等等搜索引擎工具
14、子域名搜集客户端
https://www.exploit-db.com/google-hacking-database
https://fofa.info/
https://hunter.qianxin.com/
domain="yijinglab.com"
https://www.zoomeye.org/ site:"yijinglab.com"
https://www.zoomeye.org/ hostname:yijinglab.com
子域名收集工具
https://gitee.com/yijingsec/LayerDomainFinder
https://gitee.com/yijingsec/OneForAll
C段主机存活探测
-
nmap探测
-
TXPortMap探测
15、CDN绕过
1、多地ping:用各种多地ping服务,查看对应IP地址是否唯一
http://www.webkaka.com/Ping.aspx
2、国外ping:因为有些网站设置CDN可能没有把国外的访问包含进去,所以可以这么绕过
总结:通过各大威胁情报集团的搜索引擎,尽可能全面的收集有用的攻击面,然后 查看各大子域名平台中是否有关联链接,子域名链接等一系列的信息,把我们的信息手机做到极致,把我们的攻击面扩充到最大
二、主动搜集
1、端口扫描
nmap ip
2、敏感目录和文件扫描
使用御剑、dirbuster、dirsearch等工具对目标进行扫描
dirb url
dirsearch -u url
三、指纹识别
1、Wapplyzer
2、指纹识别在线平台
(3)http://whatweb.bugscaner.com/look/
(4)https://fp.shuziguanxing.com/
1、第三方网站
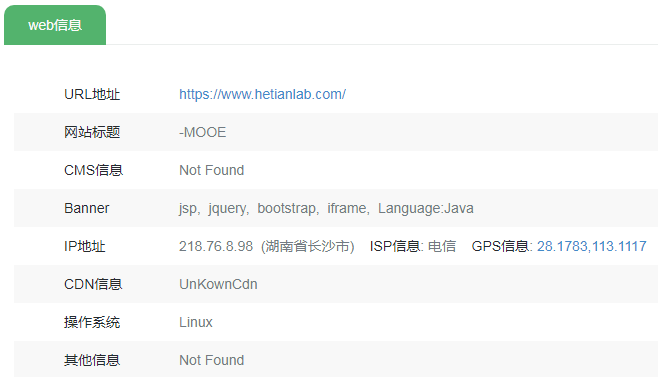
- whatweb:https://www.whatweb.net/
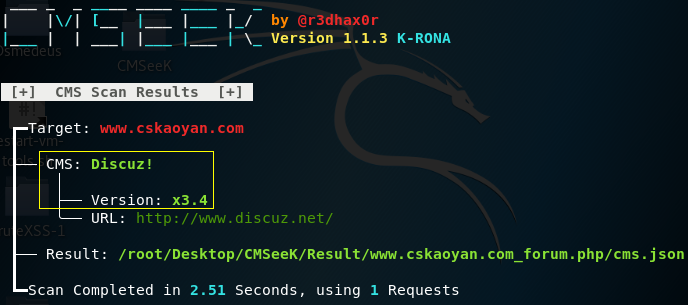
2、CMSeeK
CMS 检测和开发套件 - 扫描 WordPress, Joomla, Drupal 和 180 多个其他 CMS
使用Python3构建,超过180个CMS的基本CMS检测,包括版本检测、用户枚举、插件枚举、主题枚举、核心漏洞检测、配置泄露检测等。
工具地址:https://gitee.com/yijingsec/CMSeeK
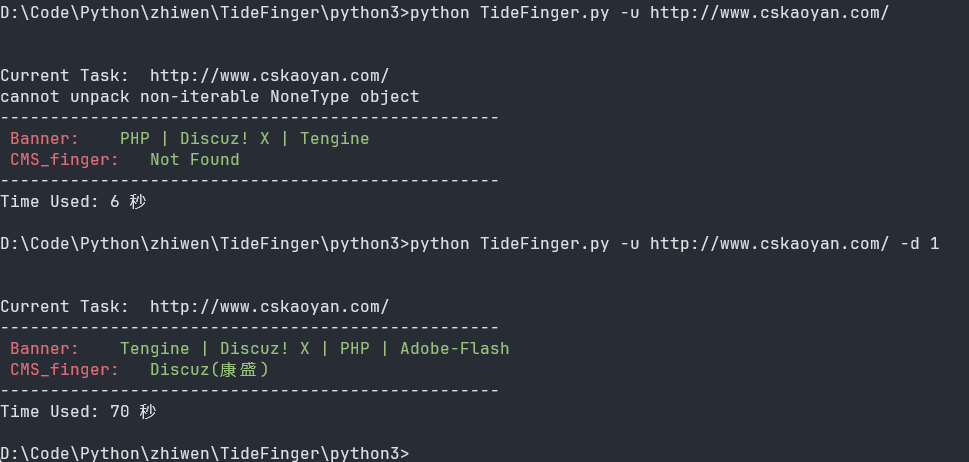
3、TideFinger
指纹识别小工具,汲取整合了多个web指纹库,结合了多种指纹检测方法,让指纹检测更快捷、准确。
工具地址:https://gitee.com/yijingsec/TideFinger
python TideFinger.py -u http://www.cskaoyan.com/
python TideFinger.py -u http://www.cskaoyan.com/ -d 1
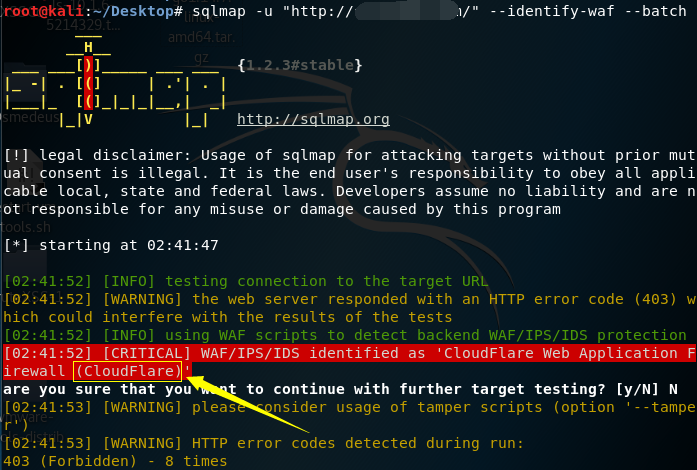
四、WAF
1、Nmap探测waf
nmap -p80,443 --script=http-waf-detect ip
nmap -p80,443 --script=http-waf-fingerprint ip
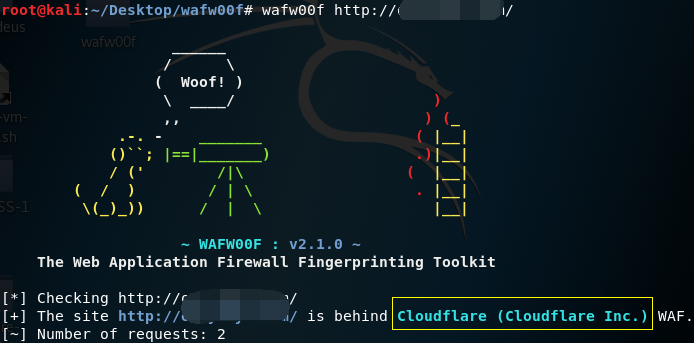
2、WAFW00F探测WAF
wafw00f -a 域名
wafw00f 是一个用于识别和指纹识别Web应用防火墙(WAF)的开源工具。它通过发送HTTP请求并分析响应来检测网站是否使用了WAF,并且如果使用了WAF,尝试确定其类型或品牌。
工具地址:https://gitee.com/yijingsec/wafw00f
Kali 地址: https://www.kali.org/tools/wafw00f/
工作原理:首先发送正常的 HTTP 请求并分析响应,如果不成功,将发送多个 HTTP 请求(可能是恶意的),并使用简单的逻辑来推断出它是哪个 WAF。如果还是不成功,将分析先前返回的响应,并使用另一种简单的算法来猜测 WAF 或安全解决方案是否正在积极响应我们的攻击。
wafw00f http://10.0.0.103
3、域名添加敏感字符
https://www.jlthedu.com/Web_Pro/index.aspx <script>alter('xss')</script>
4、本地客户端
铸剑
5、SQLMAP
SQLMAP 中自带了识别 WAF 的模块,可以识别出网站的 WAF 种类。如果安装的 WAF 没有什么特征,识别出来的就是 Generic(Unknown)。