我心里有个疑问,一根成品网线或者自己制作的网线传输质量到底好不好,应该如何判断?这些网线速度到底如何是拿测线器测不出来的,毕竟测线器只能测试线路的通断,但线路质量是测试不出的。

我们也没有高大上的福禄克设备

毕竟对于家里的几根线,动用这么专业高价的设备也不值当的。
今天就找到一个用两台电脑测试网线的方法。
首先要说一下,所谓的测网速其实就是给自己吃个定心丸,测试时候的网络速度和真正使用网络的时候速度差异会很大这是因为你在测试的时候永远是一个相对比较简单的理想环境。测试过程中硬件几乎100%的用来处理网络流量。
而如果你的计算机配置并不是特别高,而且内部的网卡还比较吃CPU,你测试出来的结果恐怕就没有太大的参考意义了,例如你在吃鸡的时候网络延迟加大,就是因为你的CPU不够。
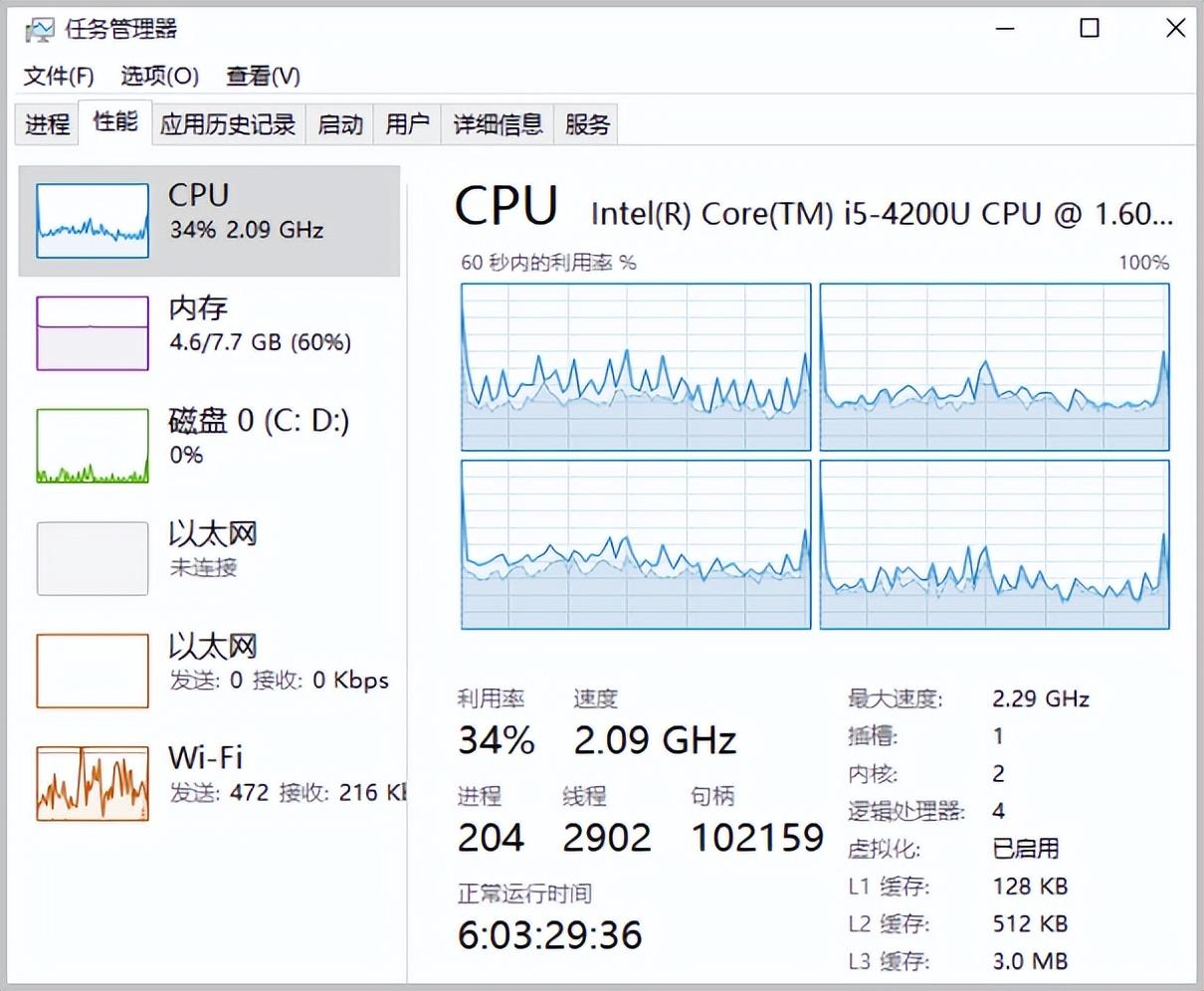
所以,即便是在测试过程中网络跑不到满满到1000Mbps其实也未必是你的网络问题,而很可能是你的计算机速度慢。
一般iN用iperf3来测试网络速度,这是一个开源的网络测试工具。主要就是用来测试网络性能。
如果要使用iperf3则需要两台计算机,在这两台计算机上安装iperf3,其实也就是把这个软件的两个文件拷贝到电脑可执行的文件夹中。
一台计算机作为服务器,在命令行窗口运行 “iperf3 -s”这条指令开启服务器模式
另一台计算机作为客户机,在命令行状态下执行 “iperf3 -c 服务器IP地址”来联通服务器进行测试。
例如iN这边的作为测试的服务器IP地址为 “172.161.149.154”,所以在另一台电脑上 就直接输入 “iperf3 -c 172.161.1.154”就可以开启测试。
在全部的网络测试开始前你得知道自己的计算机到底有啥问题,所以首先你得做一个基准测试看一下自己的系统到底能承载多少网络流量。iN在装修现场都是放的比较旧的机器做调试,所以本身速度也就像之前说的未必是可以跑满的。
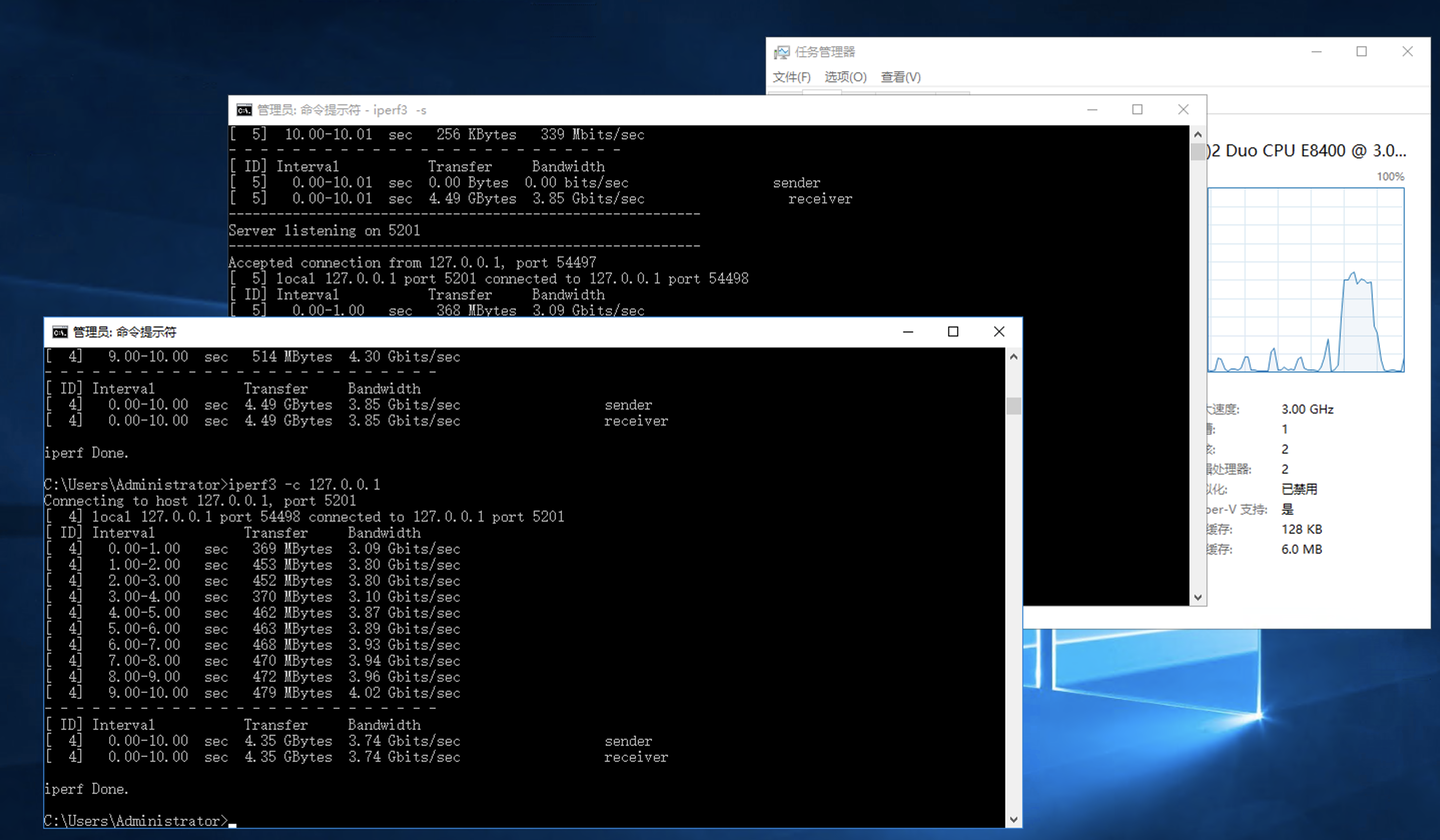
做基准测试的时候分别在两台计算机上开启两个命令行窗口,一个命令行窗口开启服务器模式,另一个命令行窗口开启测试模式,在测试客户窗口执行 “iperf3 -c 127.0.0.1”。这时候你跑出来的是一个基准测试数值,同时你可以观察到CPU占用率的飙升。
在两台机器上都做一遍,这时候你就知道自己的计算机在内部环路上跑网络数据的最大承载量了。也就是你的计算机在不借助网卡的支持单纯的TCP/IP性能。
同理你还可以做“iperf3 -c 本地ip地址”的测试,看一下网卡和计算机主板接口之间的TCP/IP性能测试。
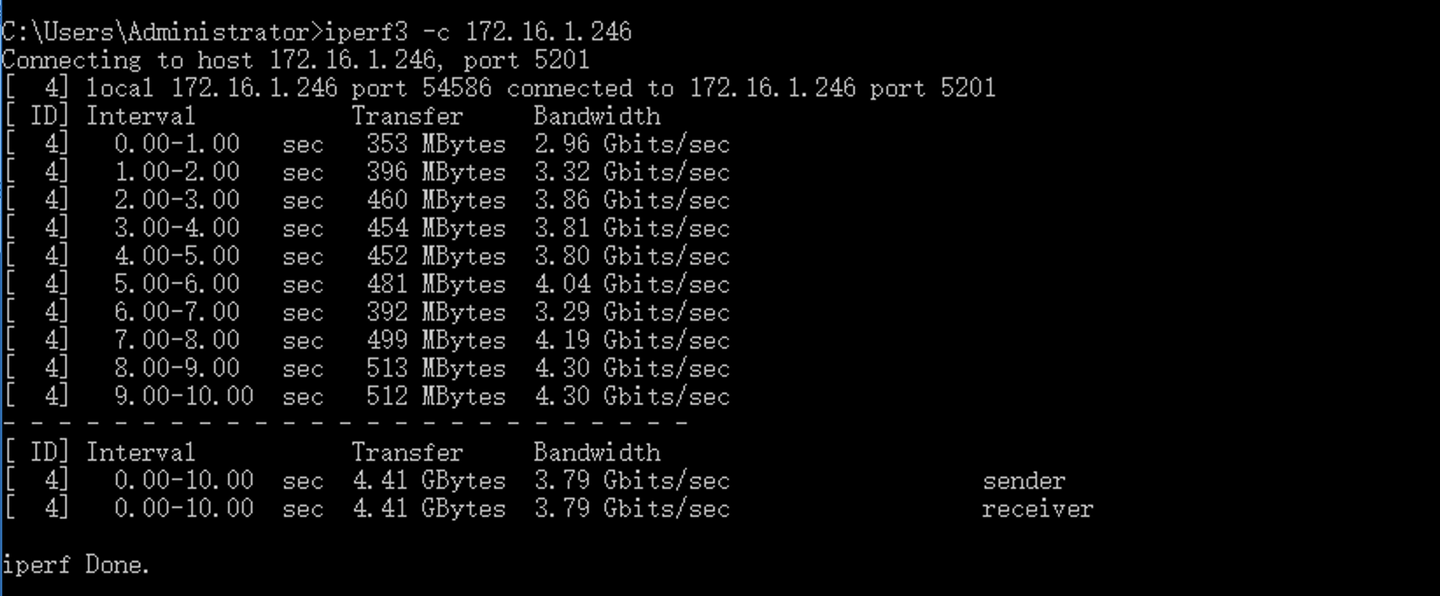
当然了 你现在看到的数值可以远大于你的网卡标称数值,但其实这个数据已经是有很大的损失了(G41芯片组是可以跑到6G左右的)。
做完这个基准量测试你就可以做网络测试了。首先用网线直接连接这两台电脑,跑一个得分:
一根高品质成品网络跳线,几乎不会带来网速上的损失,在这根网线上跑出来的成绩其实默认为你的电脑可以跑到的最高成绩(926Mbps)。
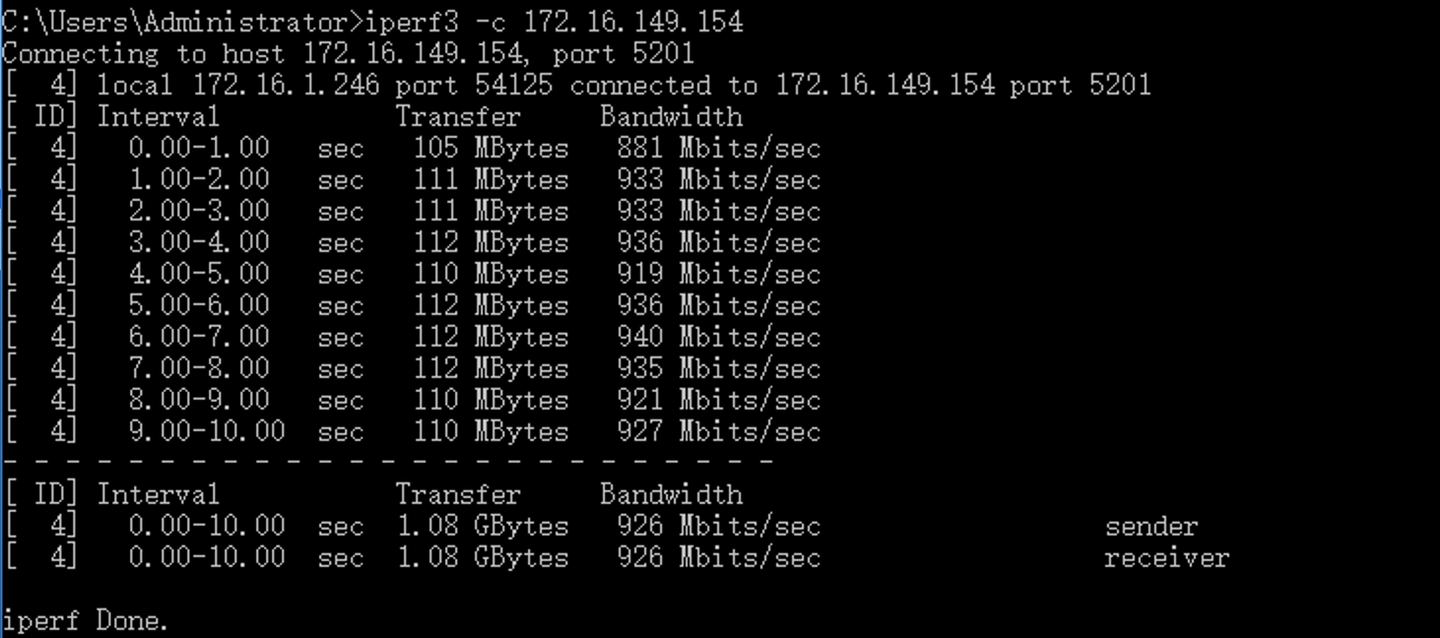
在这种情况下没跑满1000Mbps其实就是电脑性能的问题了。
测试完单根网线之后,将两台电脑接入到家里的网络链路中。
基本上iN的做法就是接入墙上的墙面插座中。接入后继续在两台电脑上做iperf3的测试,
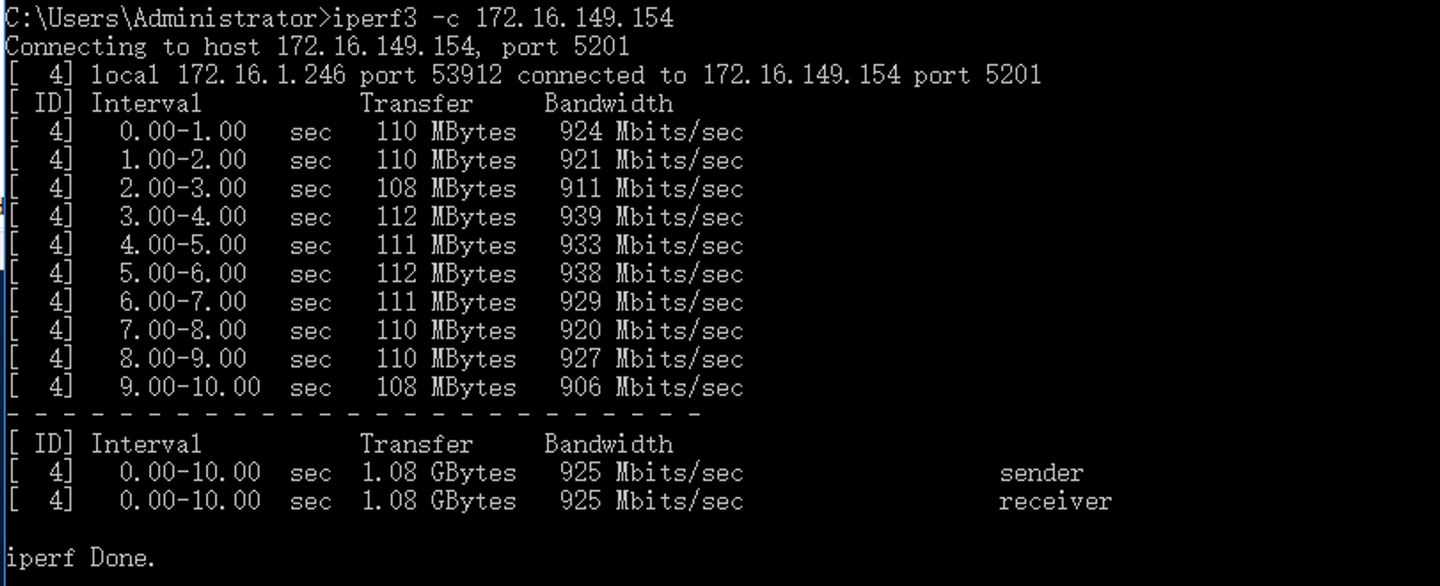
例如这里的测试结果是925Mbps,已经接近于单独连线的效果了。在你将所有的网络链路都测试过之后,你就可以得到家里网络的一个总体带宽情况。数值上差别不大就证明你的网络线路施工已经足够好了。但如果你发现其中某个点的带宽数值过低,或者根本跑不通,就需要重新检查线路,那么这条线即便是被测线器测试合格,也是充满隐患的线路就需要重新制作了。这个部分iN没法给大家演示,iN这边还没有找出来不合格的线路。
同理,对于无线,你依旧可以去iperf一下无线的ip地址,这样你也就可以知道在某一个点位上无线设备的最大流量到底是多少:
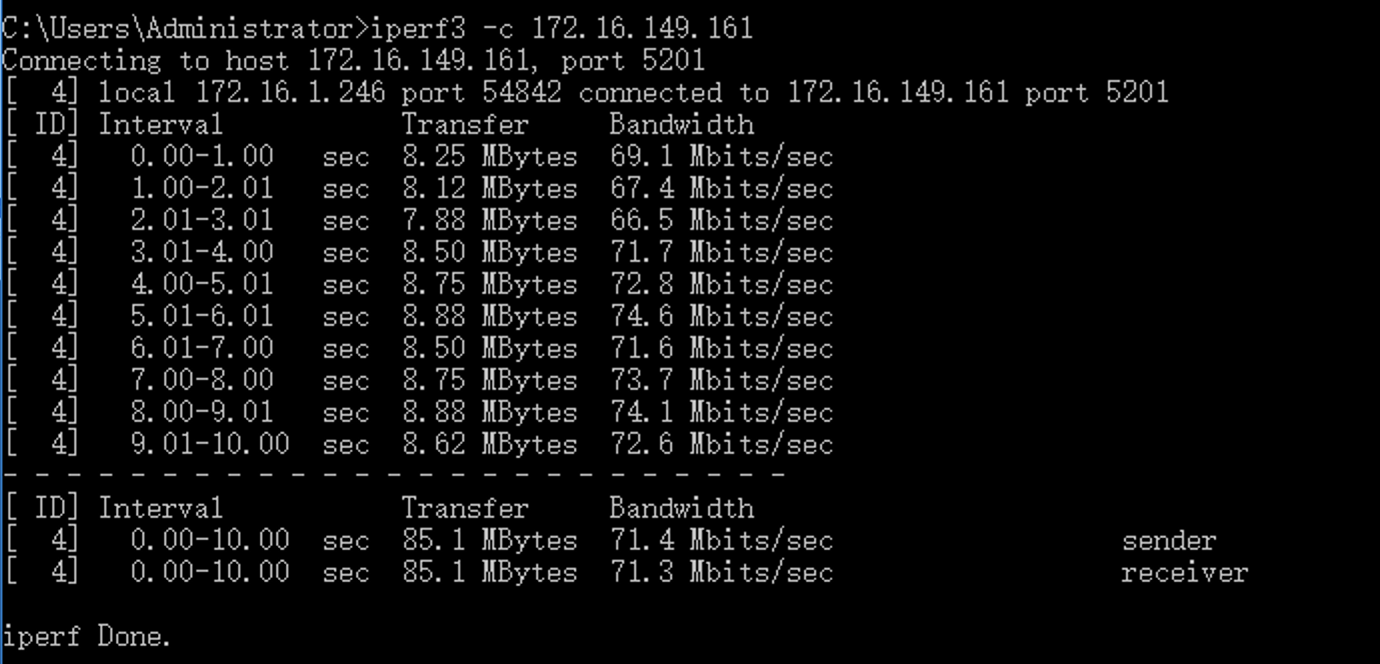
这种测试你可以在装修的各个阶段都来做,甚至无线的测试你也可以在毛坯房阶段就做出来,用作后期装修设计时的无线规划。
标签:iperf3,计算机,电脑,网络,网线,传输,测试 From: https://www.cnblogs.com/ifcon/p/18567106