1. 又说“前端已死”
为什么说“又”呢?因为前两年我在一些博客网站三天两头就能看到这个标题,虽然今年好像换话题了,但感觉前端每年都要死个七八次,当然这里面还是标题党偏多,不过也体现了有一些开发者对自己当前所做的工作内容的忧虑,尤其是这一次冲击的浪潮是来自于 AI 的,经历了两年的火热,我们已经感受到 AI 对行业的影响,今天在这里想借初学 AI 绘画的一些技术总结来探讨 AI 对我们工作产生的影响。
绘画与摄影
回顾 2022 年的 AI 热潮,最先受到冲击的就是绘画行业,现在翻看当时的讨论,有很多人抱持悲观态度,说出了“绘画已死”,但这也不是第一次有人这么说,无独有偶,1839 年法国画家 H·保罗·德拉罗什看到银版摄影摄影法的成品后,留下了一句话:
此时此刻,绘画死了。
摄影在现在的我们看来,与绘画是两个门类,但当时的画家为什么会有如此激动呢?因为当时的欧洲古典绘画,有两个最重要的技巧——结构和透视,而在摄影中只要按下快门就能完美地记录场景和人物,不像画家需要穷极一生去练习这两种技法,而当下的 AI 绘画好像可以只通过几个关键词就能生成以往需要大量练习才能得到的图片,但事实真是如此吗?我们先看下 AI 技术怎么改变前端的。
2. AI 网页开发
我们先跳过设计和框架搭建阶段,最常用的场景是拿到设计图后,将其转化成网页代码,能实现这个步骤的 AI 工具也有不少了,我找了几个稍微有些口碑的试用,尽量选了一些横平竖直的设计图,因为试了一些较复杂的海报,发现效果差很多。
设计图如下:

FrontendAI
生成了两次,结构还算正常,细节不够:
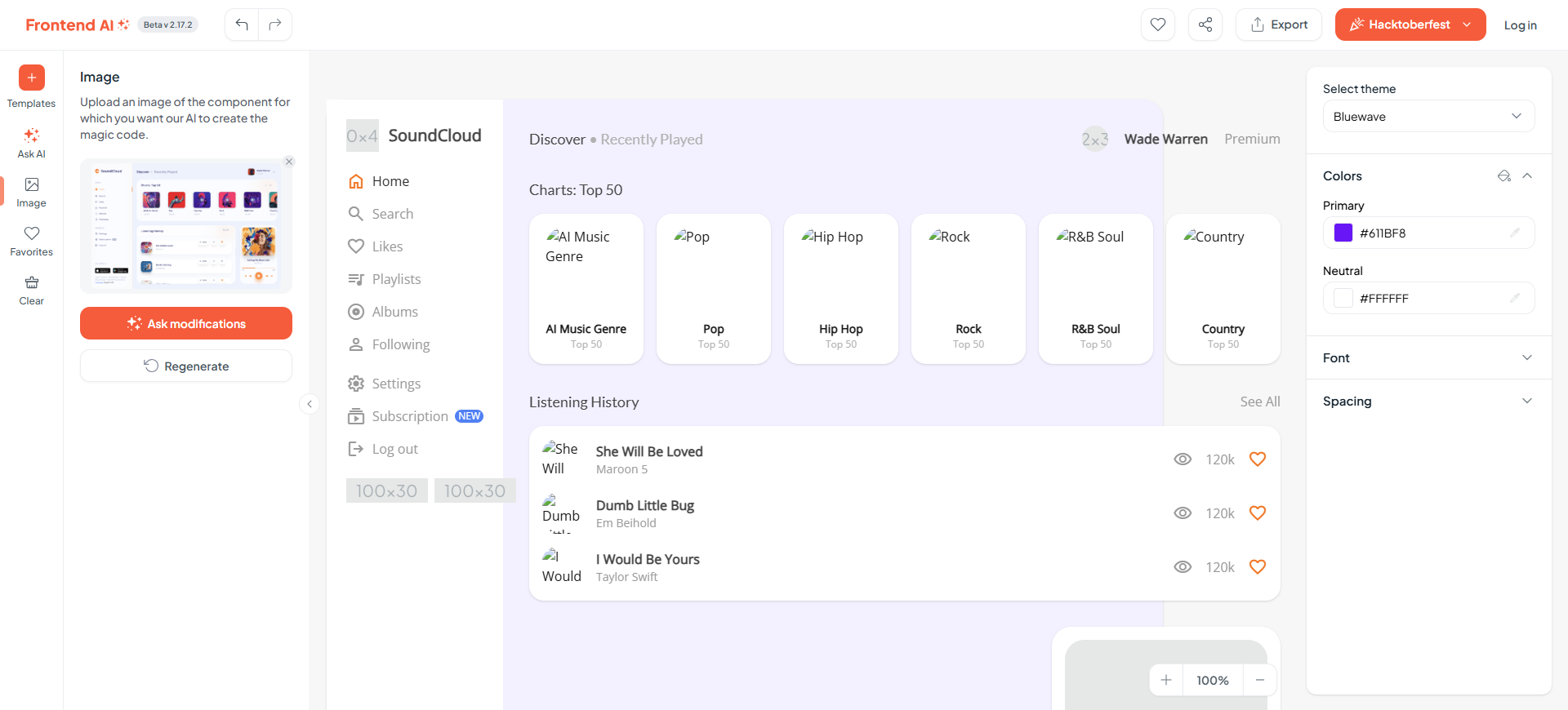
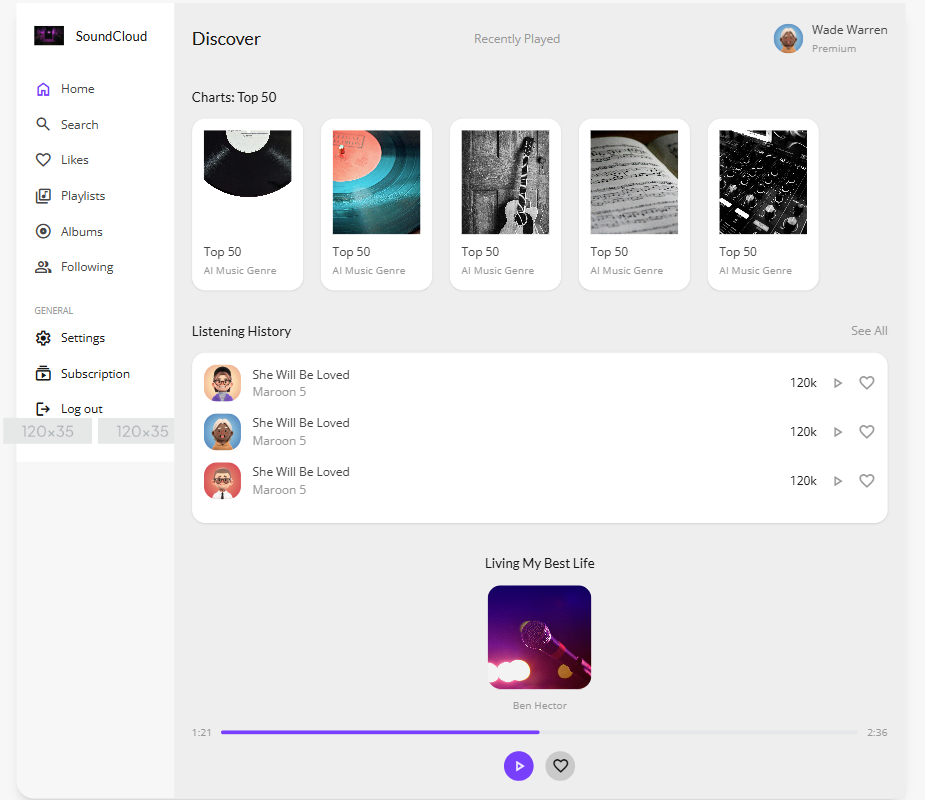
要求将播放器改为浮动的:
代码可以选择不同的框架:
Open UI
只有极简的结构:
Screenshot to Code
最近没有准备 GPT 的 key,无法试用。
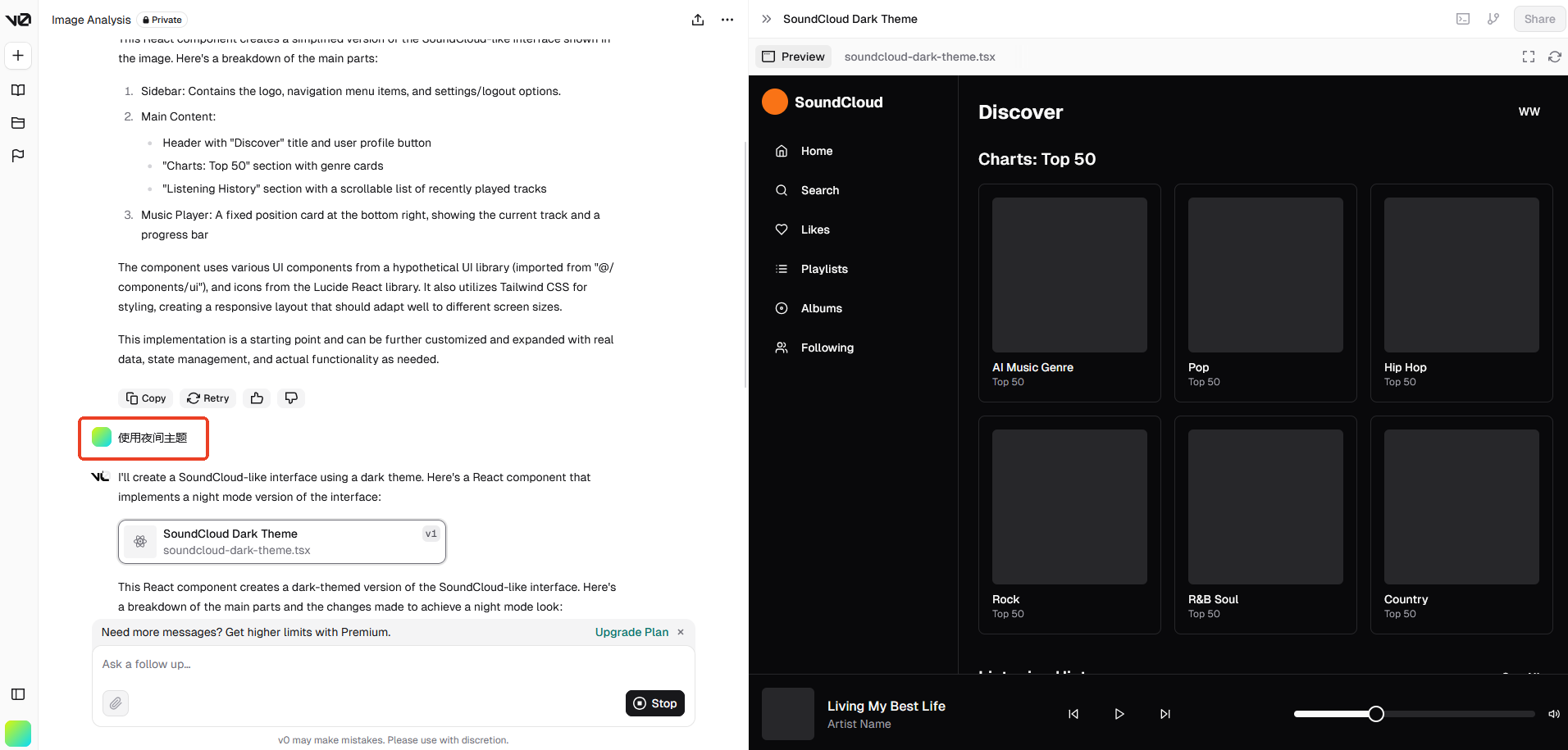
v0
效果比较好的是 Vercel 推出的一款 AI 代码生成工具,可以快速生成前端组件代码。
Vercel 本身也是一个前端部署平台,性质类似 GitHub Pages,这方面也比较有发言权。
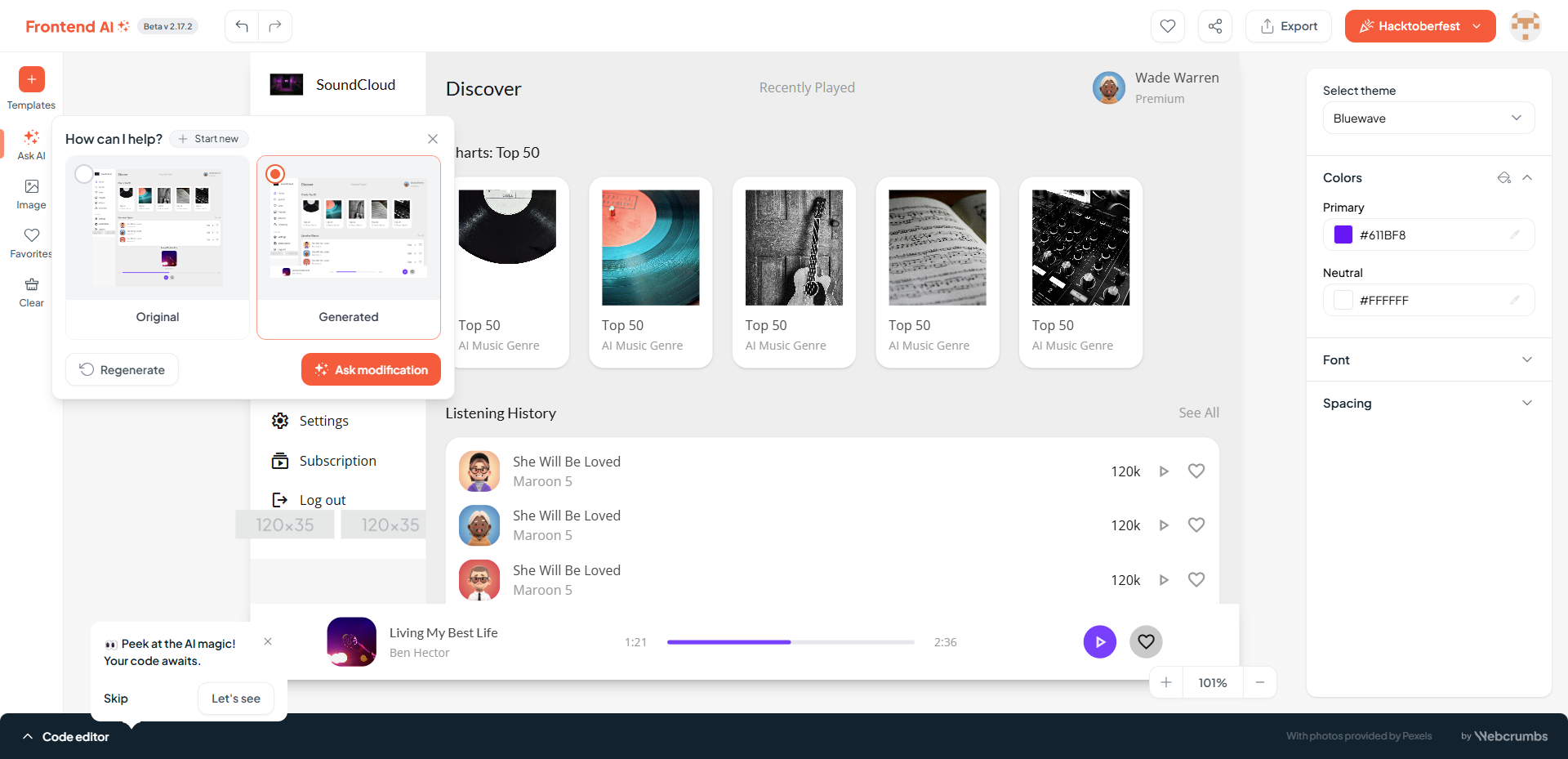
生成的网页截图:
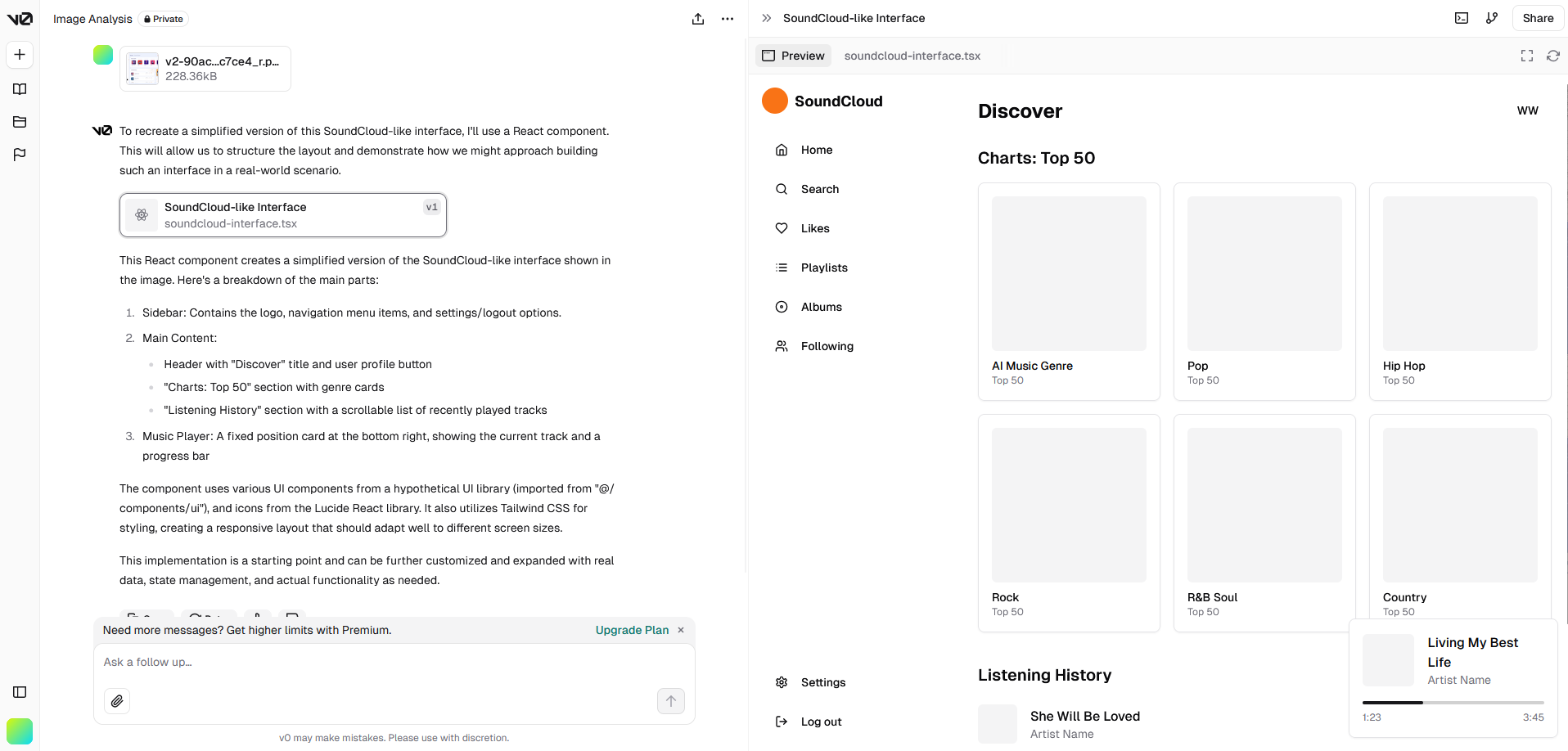
第一次生成的结果来看,只能说样子有了,细节是完全不够的。
默认生成 React 代码:
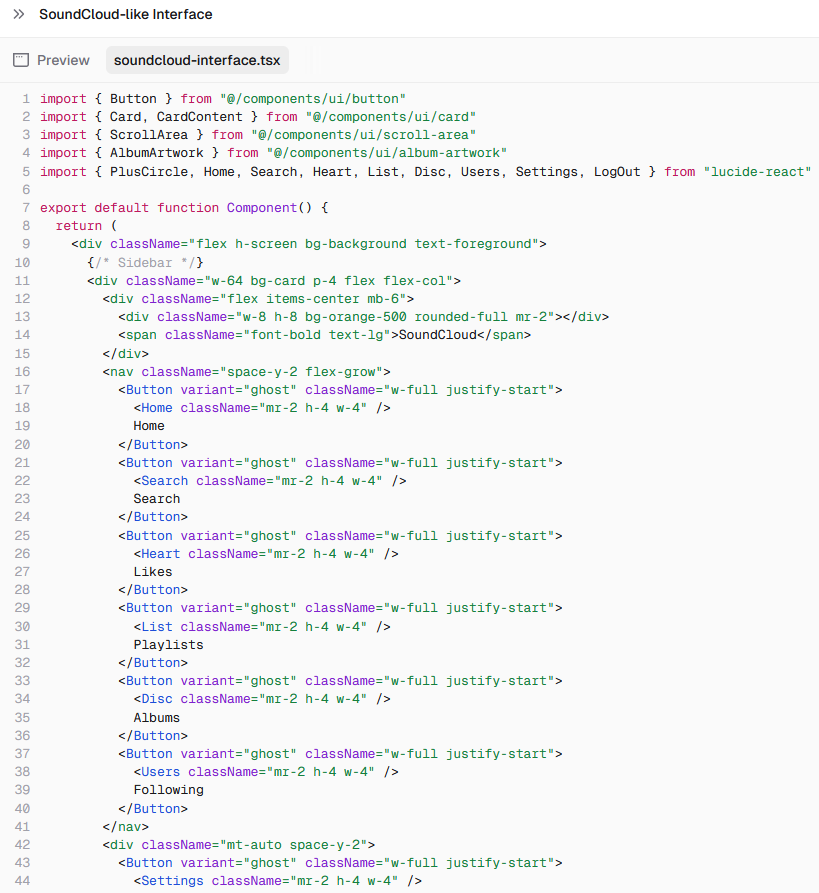
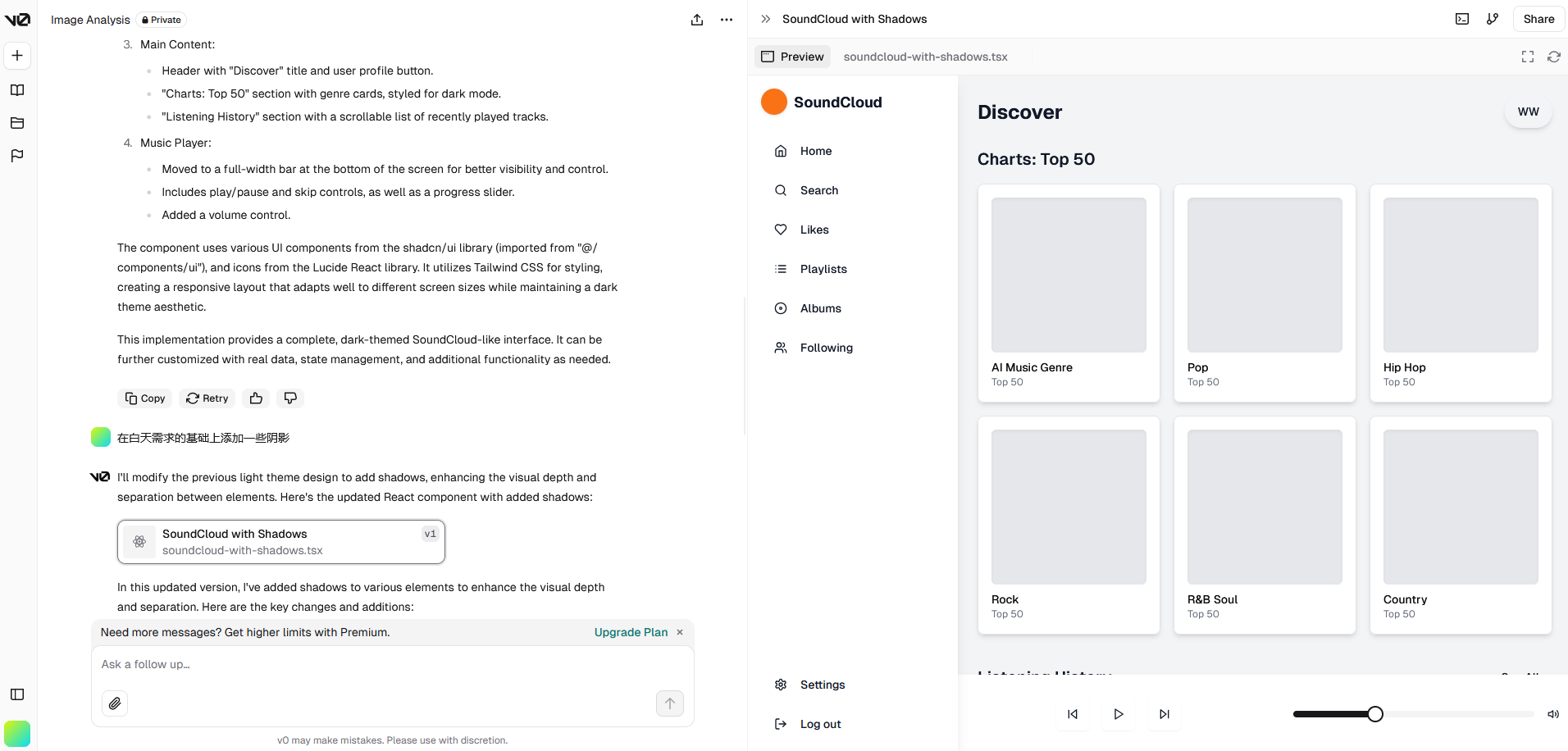
可以用自然语言描述需求并且一步步细化:
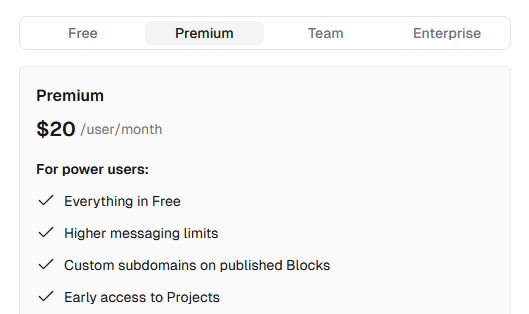
收费情况:付费方式是会员制,可以试用一两个项目。
总结
从收费模式上来看,除了 v0 是收费的,其他三个都是开源的,可以自己部署,但要使用 GPT 的 key,但相对地,生成效果都要差一些。
功能上来看都可以用自然语言说明需求,应该是结合了 Chat-GPT,通过一步步的描述细化需求,可以得到更好的结果。
结果上来看个人认为这个还原度还是比较一般的,很难将设计图的细节完全表现出来,不过确实能快速生成代码,可以用作结构参考甚至直接拿 HTML 部分的结构来用,但样式肯定是要调整的。
然后再仔细看看代码部分,这几个框架全部采用了原子化 CSS 方案,用多个类名代替 CSS 属性,这两年在前端领域也算比较流行,比如 Open AI 官网就使用 Tailwind CSS 框架,另一个框架 UnoCSS 也在一些网站得到应用,但在大型的和样式较复杂的项目中运用还有些争议,如果团队中并不是所有人都熟悉这种写法,那么这种代码的可维护性还是比较差的。

稍微有一点像当年的 Dreamweaver,可以通过拖控件生成代码,但大家都知道,全部都是行内样式有多难维护。不过如今的生成代码质量要好得多。
抛开代码的优劣,可以看到 AI 生成网页的前景还是有的,比如集成在 IDE 中的插件,可以读取当前项目的代码风格进行生成,也可以做到如上几个项目的效果时,可以生成更符合项目的风格的代码,也更方便操作选取需要重新生成的部分,这一点在 AI 绘画部分也有用到。另一方面来说,像 v0 这种产品作为快速生成原型用于验证设计的工具已经足够了。
高情商说法:进步空间还很大。
而且将设计图转为代码只是前端工作的冰山一角,暂时想完全依赖还是挺难的,直接用 Copilot 这种 AI 代码提示工具进行开发,效率也差不多。
3. AI 绘画
AI 暂时还不能替代前端,那么最先受到冲击的绘画行业呢?我看先简单看下 AI 绘画的原理:
上述几个 AI 生成代码的工具,都具有两种形式的输入,一种是自然语言,一种是设计图,也可以描述为文生图和图生图,这两种输入方式也是在 AI 绘画中最主要的,在对 AI 设计工具的探索中,我也产生了一些疑问,AI 是怎么从一张图片生成代码的呢?这个过程中 AI 是如何理解图片的呢?
原理方面,已经有很多深入浅出的资料了,后面也会贴出参考资料,如果直接开始就看尝试去理解原理,可能会有些困难,我们先看下流程,这里只挑几个对生成影响比较大的重点说一下:
- 文字生成图片:
- 文字输入
- clip_tokenizer(文字转换成数字)
- text_encoder(对输入的文字进行特征编码,用于引导 diffusion 模型进行内容生成)
- diffusion_model(核心部分,下面说)
- decoder(将潜在特征解码成图片)
- 图片生成图片:
- 图片输入
- image_encoder 转为文字
- clip_tokenizer
- text_encoder
- diffusion_model
- decoder
这里面有两个重要的模型:
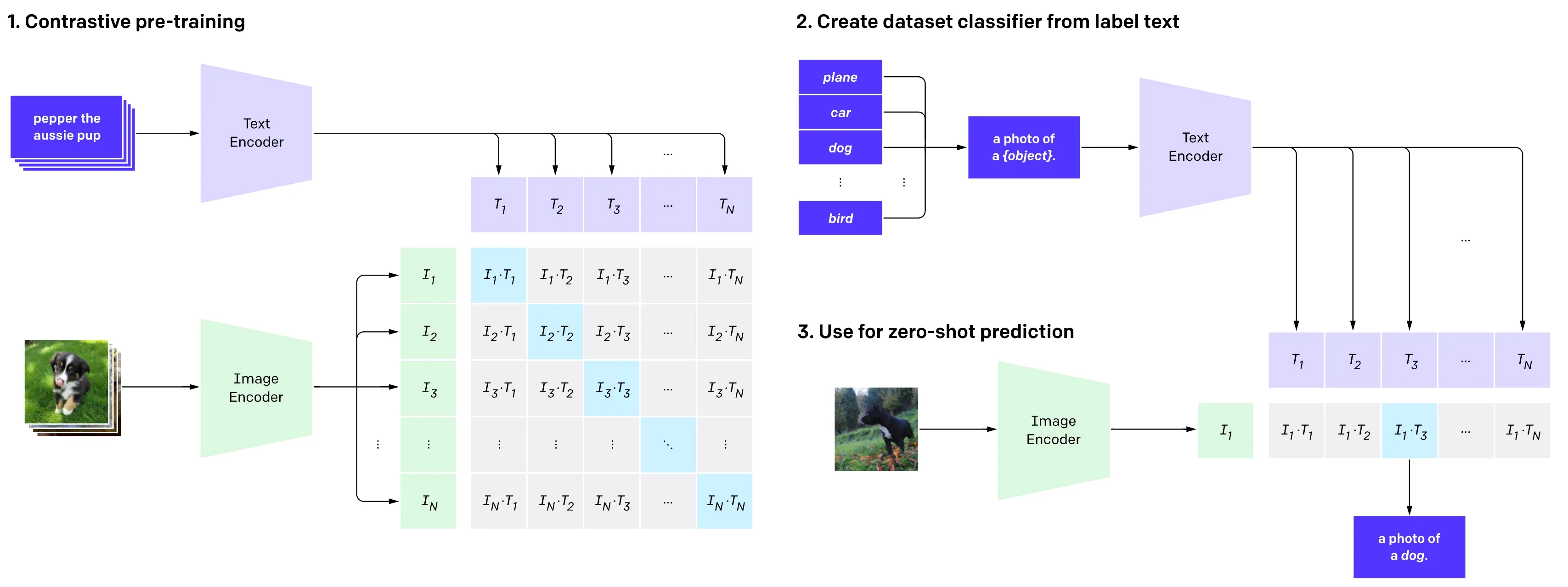
Clip 模型
由 OpenAI 在 2021 年提出,用大量图片和文字对模型进行训练,让模型学会理解图片和文字之间的关系,降低了标注的成本,提高了模型的泛化能力,说人话就是给一张图片打标签。
Diffusion 模型
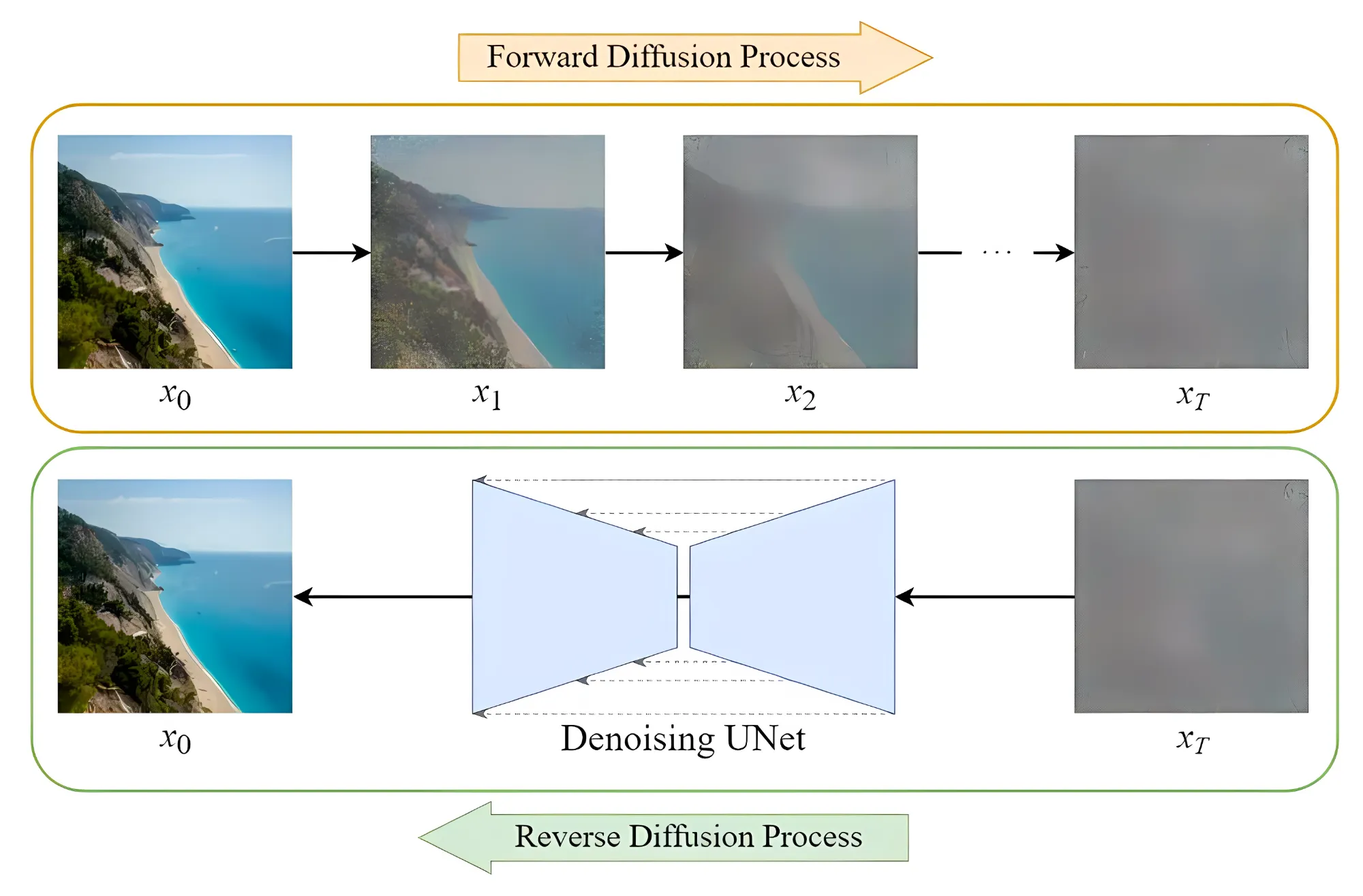
这个是当下 AI 绘画的核心技术,简单来说,先通过对照片添加噪声,然后在这个过程中学习到当前图片的各种特征。之后再随机生成一个服从高斯分布的噪声图片,然后一步一步的减少噪声直到生成预期图片。
2021 年,Open AI 发布了一个名为 DALL-E 的模型,声称这个模型可以从任何文字中创建高质量图像,它所使用的技术即为 Diffusion Models。很快,基于 Diffusion Models 模型的图片生成成为主流。2022 年又发布了 DALL-E 2,可以生成更高质量的图片。但是 OpenAI 一直都没有公开 DALL·E 的算法和模型。
3.1 AI 绘画工具的发展
可以看到,当下的 AI 绘画的理论模型在 2021 年趋于完善,接下来就是 2022 年走上快车道,各种 AI 绘画工具百花齐放:
我 21 年换的显卡,没有关心前沿科技,还选了 AMD
标签:Diffusion,网页,AI,模型,漫谈,生成,绘画,图片 From: https://www.cnblogs.com/LFeather/p/18516912