聚水潭盘亏-金蝶其他出库:高效数据集成方案
在企业管理系统中,如何实现不同平台间的数据无缝对接一直是一个关键挑战。本文将分享一个具体的技术案例:如何通过轻易云数据集成平台,将聚水潭的盘亏数据高效集成到金蝶云星空的其他出库模块。
背景与需求分析
在本次集成项目中,我们需要从聚水潭获取盘亏数据,并将其准确、及时地写入到金蝶云星空的其他出库模块。这一过程不仅要求高吞吐量的数据写入能力,还需确保数据质量和实时监控,以避免任何漏单或错误。
技术要点
-
API接口调用:
- 聚水潭:使用
inventory.count.query接口抓取盘亏数据。 - 金蝶云星空:利用
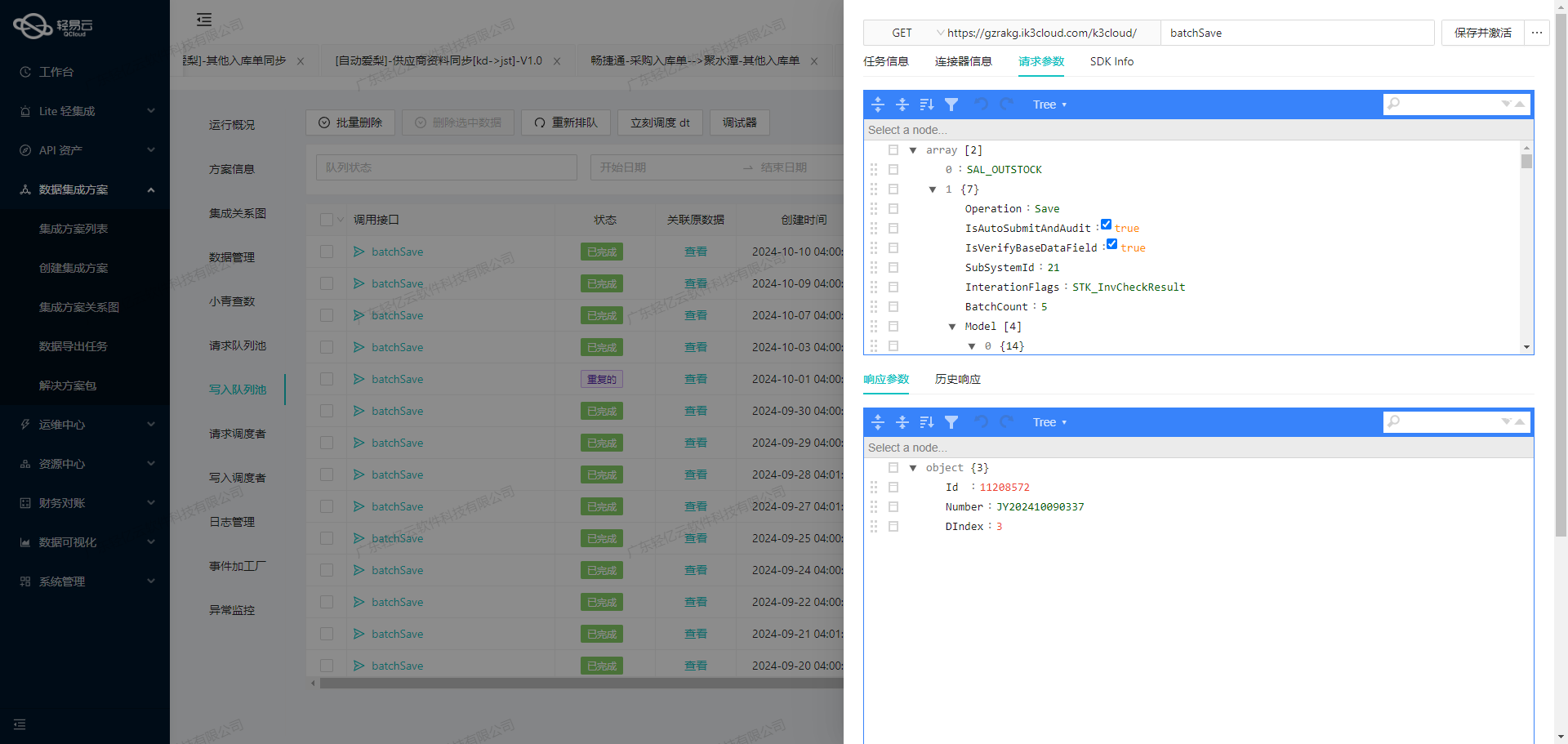
batchSave接口批量写入其他出库数据。
- 聚水潭:使用
-
高吞吐量支持:
轻易云平台提供了强大的高吞吐量数据写入能力,使得大量盘亏数据能够快速被集成到金蝶云星空,极大提升了处理时效性。 -
集中监控与告警系统:
集中的监控和告警系统实时跟踪每个数据集成任务的状态和性能,确保在出现异常时能够及时发现并处理,保障整个流程的稳定运行。 -
自定义转换逻辑与格式差异处理:
在实际操作中,不同平台的数据格式往往存在差异。通过自定义的数据转换逻辑,我们可以灵活适应特定业务需求,确保从聚水潭获取的数据能够正确映射到金蝶云星空所需的格式。 -
分页与限流机制:
为了有效处理聚水潭接口可能存在的分页和限流问题,我们设计了一套可靠的分页抓取策略,并结合限流控制机制,保证在大规模数据传输过程中不丢失任何重要信息。 -
异常处理与重试机制:
数据对接过程中难免会遇到各种异常情况。我们实现了一套完善的异常处理与错误重试机制,在发生错误时自动进行重试,确保最终所有数据都能成功写入目标系统。
通过上述技术手段,本次“聚水潭盘亏-金蝶其他出库”项目不仅实现了两大平台间的数据无缝对接,还显著提升了业务透明度和效率,为企业管理提供了坚实的数据支撑。

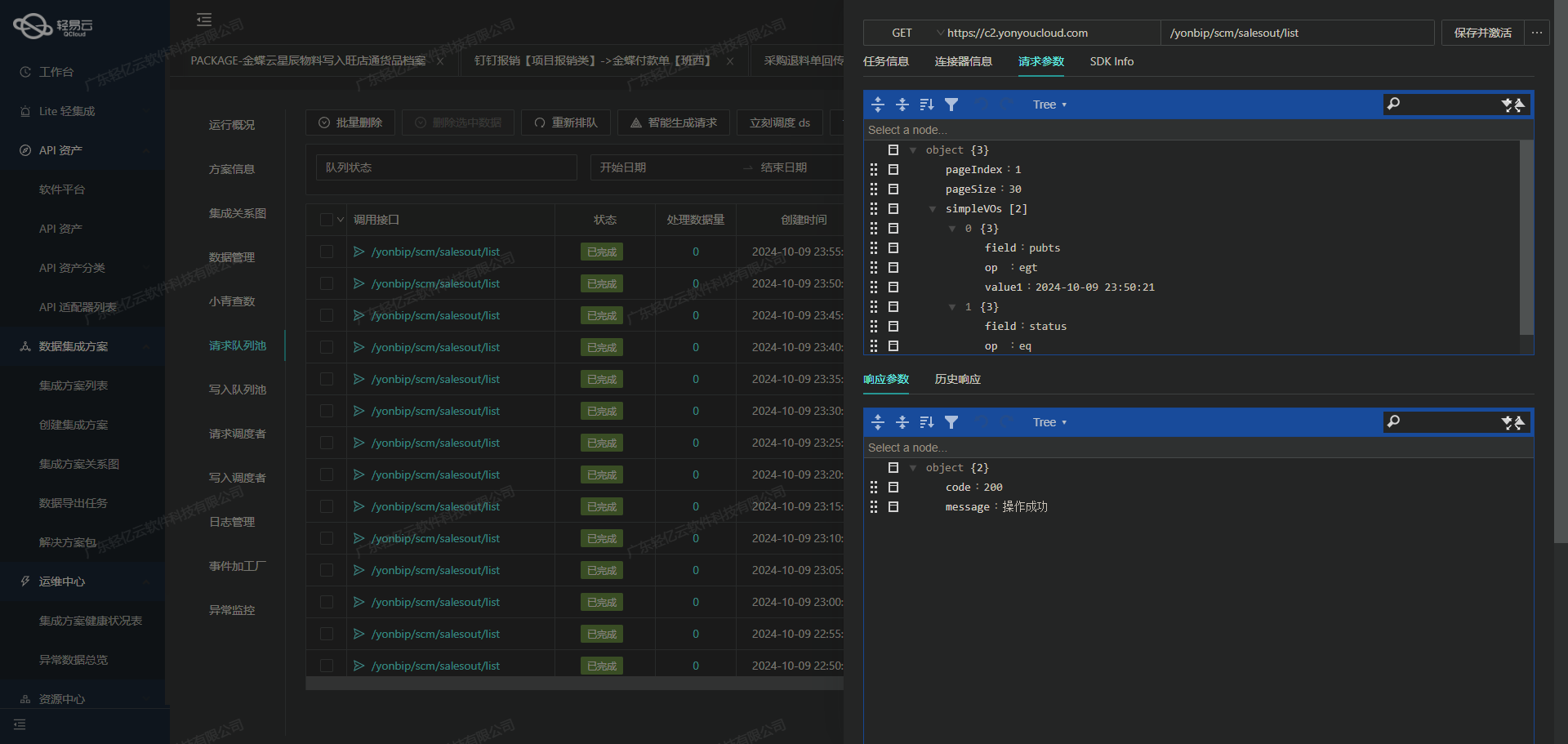
调用聚水潭接口inventory.count.query获取并加工数据
在轻易云数据集成平台的生命周期中,调用源系统接口是至关重要的一步。本文将详细探讨如何通过调用聚水潭的inventory.count.query接口来获取盘亏数据,并进行初步加工处理。
聚水潭接口配置与请求参数
首先,我们需要了解inventory.count.query接口的基本配置和请求参数。根据元数据配置,该接口使用POST方法,主要参数包括分页信息、时间范围、单据状态等。
{
"api": "inventory.count.query",
"method": "POST",
"number": "io_id",
"id": "io_id",
"condition": [
[{"field":"items.qty","logic":"lt","value":0}],
[{"field":"batchs.qty","logic":"lt","value":0}]
],
"request": [
{"field":"page_index","label":"开始页码","type":"string","describe":"第几页,从第一页开始,默认1"},
{"field":"page_size","label":"每页条数","type":"string","describe":"每页多少条,默认30,最大50"},
{"field":"modified_begin","label":"修改开始时间","type":"string","describe":"修改起始时间,和结束时间必须同时存在,时间间隔不能超过七天,与线上单号不能同时为空", "value": "{{LAST_SYNC_TIME|datetime}}"},
{"field":"modified_end","label":"修改结束时间","type":"string", "describe": "修改结束时间,和起始时间必须同时存在,时间间隔不能超过七天,与线上单号不能同时为空", "value": "{{CURRENT_TIME|datetime}}"},
{"field": "io_ids", "label": "盘点单号", "type": "string", "describe": "指定盘点单号,多个用逗号分隔,最多50,和时间段不能同时为空"},
{"field": "status", "label": “单据状态”, “type”: “string”, “describe”: “单据状态, Confirmed=生效, WaitConfirm待审核, Creating=草拟, Archive=归档, Cancelled=作废”, “value”: “Confirmed”}
]
}
数据请求与清洗
在实际操作中,我们需要确保分页请求能够顺利进行,并处理好可能出现的限流问题。以下是关键步骤:
- 分页处理:由于每次请求返回的数据量有限(最大50条),我们需要通过循环分页来获取所有符合条件的数据。
- 限流控制:为了避免触发API限流机制,可以在每次请求之间设置适当的延时或使用批量处理策略。
- 数据过滤与清洗:根据业务需求,对返回的数据进行初步过滤,例如只保留数量小于零(即盘亏)的记录。
示例代码片段如下:
def fetch_inventory_data(api_url, headers):
page_index = 1
all_data = []
while True:
payload = {
'page_index': page_index,
'page_size': 50,
'modified_begin': get_last_sync_time(),
'modified_end': get_current_time(),
'status': 'Confirmed'
}
response = requests.post(api_url, headers=headers, json=payload)
data = response.json()
if not data['items']:
break
all_data.extend(data['items'])
page_index += 1
return [item for item in all_data if item['qty'] < 0]
数据转换与写入准备
在完成数据清洗后,需要对数据进行必要的转换,以便后续写入到目标系统(金蝶云星空)。这一步通常涉及字段映射、格式转换等操作。例如,将聚水潭中的字段名转换为金蝶云星空所需的字段名,并调整日期格式等。
def transform_data(raw_data):
transformed_data = []
for item in raw_data:
transformed_item = {
'outbound_id': item['io_id'],
'product_code': item['product_code'],
'quantity': abs(item['qty']),
'warehouse_code': item['warehouse_code'],
# 更多字段映射...
}
transformed_data.append(transformed_item)
return transformed_data
实时监控与异常处理
为了确保整个集成过程的稳定性和可靠性,需要实现实时监控和异常处理机制。轻易云平台提供了集中监控和告警系统,可以实时跟踪任务状态并及时发现问题。此外,还可以设置错误重试机制,以应对临时网络故障或API响应异常。
try:
rawData = fetch_inventory_data(api_url, headers)
processedData = transform_data(rawData)
write_to_kingdee(processedData)
except Exception as e:
log_error(e)
retry_task()
通过以上步骤,我们可以高效地调用聚水潭接口获取盘亏数据,并进行初步加工,为后续的数据写入做好准备。这不仅提升了数据处理效率,也确保了业务流程的连续性和准确性。
聚水潭盘亏数据集成到金蝶云星空的ETL转换与写入
在数据集成生命周期的第二步,我们需要将已经从源平台(聚水潭)获取的数据进行ETL转换,以符合目标平台(金蝶云星空)的API接口要求,并最终将转换后的数据写入金蝶云星空。这一步骤的核心在于理解和配置元数据,确保数据格式和业务逻辑的正确性。
数据转换与写入的关键步骤
-
数据解析与映射:
- 首先,我们需要解析从聚水潭获取的数据,并将其映射到金蝶云星空API所需的字段。通过元数据配置,我们可以清晰地定义每个字段的映射关系及其转换逻辑。
{"field":"FBillNo","label":"单据编号","type":"string","describe":"单据编号","value":"{io_id}"}例如,聚水潭中的
io_id字段对应金蝶云星空中的FBillNo字段。 -
复杂类型处理:
- 对于复杂类型(如数组或嵌套对象),我们需要进一步细化其子字段。例如,明细信息
FEntity包含多个子字段,每个子字段都需要单独映射和转换。
{"field":"FEntity","label":"明细信息","type":"array","children":[{"field":"FMaterialId","label":"物料编码","type":"string","describe":"基础资料","parser":{"name":"ConvertObjectParser","params":"FNumber"},"value":"{{items.sku_id}}"}]}上述配置中,
items.sku_id被映射为FMaterialId,并使用了ConvertObjectParser进行格式转换。 - 对于复杂类型(如数组或嵌套对象),我们需要进一步细化其子字段。例如,明细信息
-
自定义转换逻辑:
- 针对特定业务需求,我们可以定义自定义函数进行数据处理。例如,将实发数量乘以-1,以满足金蝶云星空对负库存的要求。
{"field":"FQty","label":"实发数量","type":"string","describe":"数量","value":"_function {{items.qty}} *(-1)"} -
批次管理与日期处理:
- 对于批次管理和日期字段,我们可以根据条件动态生成值。例如,根据物料编码判断是否启用批次管理,从而设置生产日期和有效期。
{"field":"FLot","label":"批号","type":"string","describe":"批次","value":"_function case _findCollection find FIsBatchManage from d36b5c74-bdf8-3bcb-a345-22dac34d52aa where FNumber={{items.sku_id}} _endFind when true then 'DY20230421' else '' end"} -
接口调用与错误处理:
- 配置完成后,通过调用金蝶云星空的API接口,将转换后的数据批量写入目标平台。为了确保可靠性,需要设置错误重试机制和异常处理逻辑。
{"api":"batchSave","method":"POST"}
关键技术特性
-
高吞吐量写入能力:
- 支持大量数据快速写入到金蝶云星空,有效提升数据处理时效性。
-
实时监控与日志记录:
- 提供集中的监控系统,实时跟踪数据集成任务状态,及时发现并处理异常情况。
-
分页与限流处理:
- 在调用聚水潭接口时,通过分页机制和限流策略,确保数据抓取过程稳定可靠。
-
定制化数据映射:
- 支持根据业务需求进行定制化的数据映射和转换,灵活适应不同的数据结构。
-
异常处理与重试机制:
- 针对接口调用失败情况,设置自动重试机制,提高系统整体可靠性。
-
数据质量监控:
- 实时监控数据质量,通过异常检测及时发现并修正问题,确保数据准确性。
通过以上步骤和技术特性的应用,我们可以高效地将聚水潭盘亏数据集成到金蝶云星空,实现跨平台的数据无缝对接,为企业提供可靠的数据支撑。