近期在大规模基础模型上的进展引发了对训练高效大型视觉模型的广泛关注。一个普遍的共识是必须聚合大量高质量的带注释数据。然而,鉴于计算机视觉中密集任务(如目标检测和分割)标注的固有挑战,实际的策略是结合并利用所有可用的数据进行训练。
论文提出了
Plain-Det,提供了灵活性以适应新的数据集,具有跨多样数据集的稳健性能、训练效率和与各种检测架构的兼容性。结合Def-DETR和Plain-Det,在COCO上达到51.9的mAP,匹配当前最先进的检测器。在13个下游数据集上进行了广泛的实验,Plain-Det展现了强大的泛化能力。来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: Plain-Det: A Plain Multi-Dataset Object Detector

Introduction
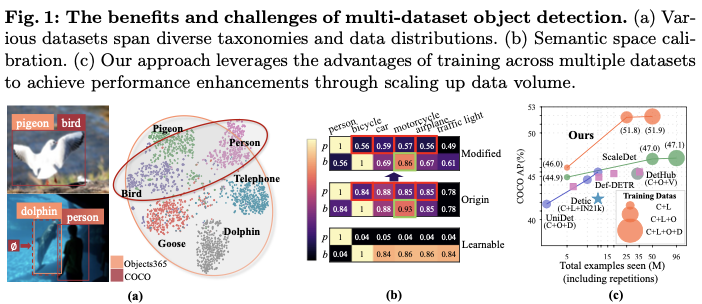
大规模数据集促进了计算机视觉的显著进步,从用于图像分类的ImageNet到最近的图像分割数据集SA-1B。目标检测作为计算机视觉中的基本任务之一,固有地需要大规模的带注释数据。然而,注释如此广泛和密集的对象既昂贵又具有挑战性。另一种直接且实用的方法是统一多个现有的目标检测数据集,以训练一个统一的目标检测器。然而,数据集之间的不一致性,例如如图1a所示的不同分类法和数据分布,给多数据集训练带来了挑战。
论文旨在解决使用多个目标检测数据集训练一个有效且统一的检测器所面临的挑战,期望该检测器应具备以下特性:
- 对新数据集具有灵活性,以无缝且可扩展的方式进行适应,而不需要手动调整、复杂设计或从头开始训练。
- 在逐渐引入新数据集时性能具有稳健性,始终能够提高性能,或者至少保持稳定的性能。
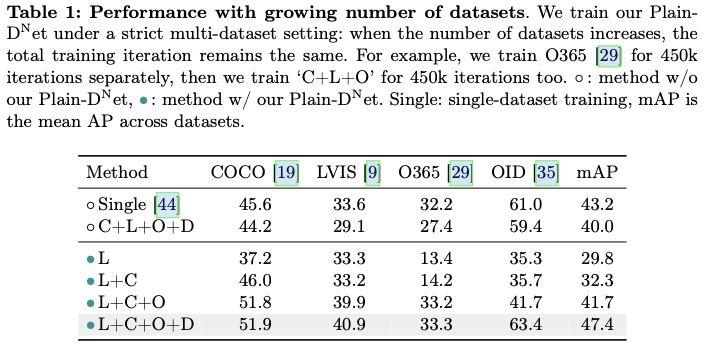
- 训练效率。多数据集训练所需的训练迭代次数不应超过单一数据集的训练次数。
- 与检测系列的兼容性,例如
Faster-RCNN系列和基于DETR的检测架构。
首先,引入一个简单而灵活的多数据集目标检测基线,这大胆挑战了一些近期的设计原则,同时保持其他进展。近期的研究明确将不同数据集之间的分类法统一为一个单一的统一分类法。然而,尽管它们采用了自动化方法,但仍然需要精心设计的组件,并在扩展到更多数据集时缺乏灵活性。这主要是因为1) 从数据集特定标签空间到统一标签空间的映射自动学习后,随着标签空间大小的增长变得越来越嘈杂;2) 结合新数据集需要重构统一的分类法。
因此,论文引入一个共享检测器,拥有完全数据集特定的分类头,以自然地防止不同分类法之间的冲突,并确保灵活性。此外,利用类别标签的文本嵌入构建所有标签的共享语义空间。值得注意的是,语义空间隐式地建立了来自不同分类器的标签之间的连接,使得尽管有数据集特定的分类头,仍然能够充分利用所有训练数据。尽管多数据集基线模型展示了灵活性,但其性能显著低于单一数据集目标检测器。
为此,论文探讨了影响基线成功的关键因素,并提供了三个见解,以使其不仅具有超强的灵活性,同时也具有高度的有效性:
-
Semantic space calibration
语义空间校准的灵感源于质疑使用固定文本嵌入的分类器是否适用于目标检测。图1b的origin展示了类别之间文本嵌入的相似性矩阵,这与由可学习分类权重生成的矩阵(图1b的learnable)明显不同。
这种偏差源于CLIP的训练数据分布,例如CLIP中的文本-图像对通常在名词频率上表现出长尾分布。这导致频繁出现的名词(如图1b中的person)的文本嵌入与其他词(包括NULL)之间具有高相似性。反过来,论文发现不常出现的NULL与频繁出现的词具有高相似性,而与不常出现的词具有低相似性。
因此,可以将空字符串NULL视为一个无意义的基准,以提取受频率驱动的基准,从而得到图1b的modified中所示的校准相似性矩阵。
-
Sparse proposal generation
在目标检测中,目标提案生成至关重要,尤其是在多数据集场景下。这是因为相同的目标提案用作锚点,以预测不同数据集的不同目标集。例如,虽然COCO和LVIS共享相同的图像集,但标注类别存在显著差异。这要求在同一图像中相同的目标提案能够锚定来自COCO的80个类别和LVIS的1203个类别的不同目标。
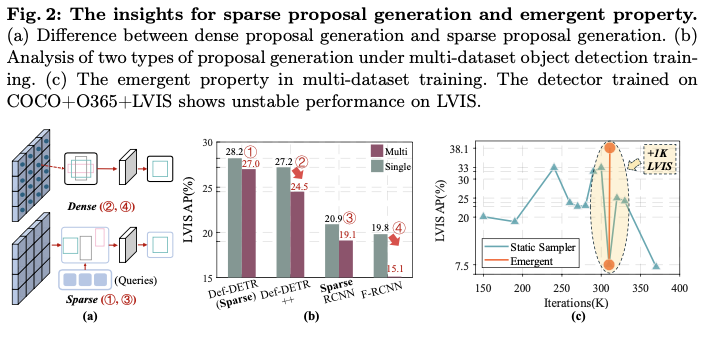
目前,目标提案生成方法大致可分为两种类型:1) 密集或从密集到稀疏的提案生成,生成跨越所有图像网格的提案或从密集提案中选择一个小子集,以及2) 稀疏提案生成,通常直接生成一组可学习的提案(见图2a)。
因此,论文对这两种类型的提案生成方法在COCO和LVIS数据集的多数据集目标检测中进行了初步实验和比较。结果表明,稀疏提案生成方法在两个目标检测器系列中始终优于密集方法,如图2b所示。一个可能的原因是,与密集提案生成相比,稀疏提案(即稀疏查询)被证明能够捕捉数据集的分布,使得从多个数据集中学习联合分布变得更加容易。然而,由于需要相同的查询来捕捉不同数据集的先验,多数据集训练的性能仍低于单数据集训练。
因此,论文基于统一的语义空间和图像先验改进稀疏查询为类感知查询,这缓解了一组查询必须适应多个数据集的挑战。
-
Dynamic sampling strategy inspired by the emergent property
尽管上述两个见解解锁了在像COCO和LVIS这样的多个数据集上训练统一检测器的潜力,但纳入数据集Objects365会导致训练过程中检测性能的大幅波动(如图2b的static sampler),主要是由于数据集大小的不平衡(见图2c)。
令人惊讶的是,论文观察到,即使在某次迭代中检测器在某个数据集上的精度较低,它也可以通过对该特定数据集进行几次额外的训练迭代显著提高其精度(如图2b的emergent)。论文将这一现象归因于多数据集检测训练的涌现特性:在多个数据集上训练的检测器,固有地具备比单一数据集训练更一般化的检测能力,并且这种能力可以通过几次特定于数据集的迭代被激活并适应特定的数据集。
受到这一特性的启发,论文提出了一种动态采样策略,以在不同数据集之间实现更好的平衡,该策略在后续迭代中根据先前观察到的数据集特定损失动态调整多数据集采样策略。
最后,论文提出了Plain-Det,这是一种简单但有效的多数据集目标检测器,得益于基线的灵活性,可以通过直接将上述三项见解应用于基线来轻松实现。
总而言之,论文的贡献为:
-
提供了三项关键见解,以应对多数据集目标检测训练的挑战,包括标签空间的校准、稀疏查询的应用和改进,以及少量迭代的特定数据集训练的涌现特性。
-
基于这三项见解,提出了一种简单但灵活的多数据集检测框架,称为
Plain-Det,满足以下标准:能够灵活适应新数据集、在不同数据集上表现出良好的鲁棒性、训练效率高,以及与各种检测架构兼容。 -
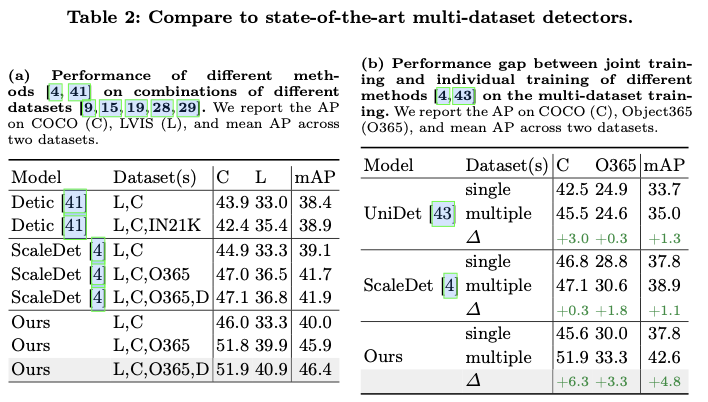
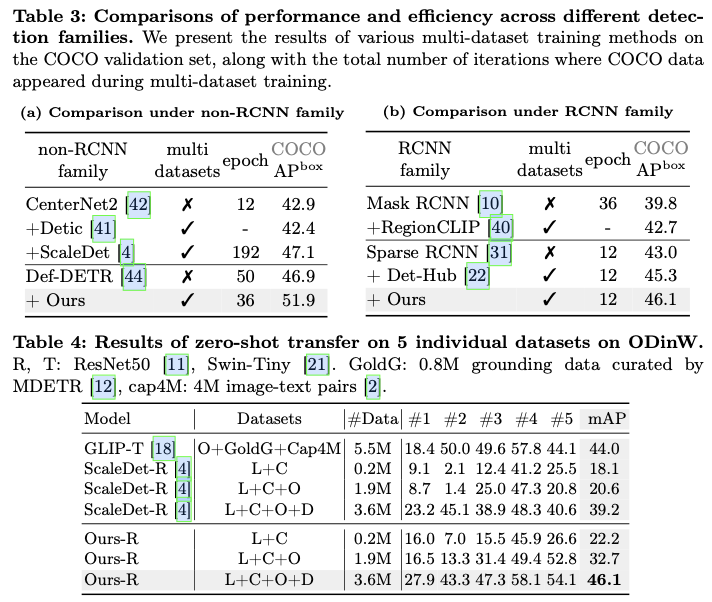
将
Plain-Det集成到Def-DETR模型中,并在公共数据集上进行联合训练,这些数据集包含2,249个类别和400万张图像。这一集成将Def-DETR模型在COCO上的mAP性能从46.9%提升至51.9%,达到了与当前最先进的目标检测器相当的性能。此外,它在多个下游数据集上创造了新的最先进的结果。
Our Method
Preliminaries
-
Query-based object detector
通过将目标检测重新构造成一组预测问题,最近的基于查询的目标检测器利用可学习或动态选择的对象查询直接生成最终对象集的预测,例如基于DETR的方法或Sparse-RCNN。这种方法消除了对手工制作组件的需求,如锚框预设和后处理非极大抑制(NMS)。
一个基于查询的检测器由三个组成部分构成:一组对象查询、一个图像编码器(例如,DETR中的Transformer编码器或Sparse-RCNN中的CNN),以及一个解码器(例如,DETR中的Transformer解码器或Sparse-RCNN中的动态头)。
对于给定的图像 \(I\) ,图像编码器 \(Enc(\cdot)\) 提取图像特征,这些特征随后与对象查询 \(\mathcal{Q}\) 一起输入解码器 \(Dec(\cdot)\) ,以预测每个查询的类别 \(C\) 和边界框 \(B\) 。通常情况下,分类头 \(\mathcal{H}_c(\cdot)\) 和框回归头 \(\mathcal{H}_b(\cdot)\) 由几层多层感知机(MLP)构成。
整个检测管道可以如下所示:
\[\begin{equation} \begin{aligned} \hat{\mathcal{Q}} &= Dec( Enc(I), \mathcal{Q}), \\ C &= \mathcal{H}_c(\hat{\mathcal{Q}}), \quad B=\mathcal{H}_b(\hat{\mathcal{Q}}), \end{aligned} \end{equation} \]其中, \(\hat{\mathcal{Q}}\) 是经过解码器层查询优化后的查询特征。为了简化演示,用 \(f(\cdot)\) 表示目标检测器,其中编码器 \(Enc(\cdot)\) 、解码器 \(Dec(\cdot)\) 、可学习或选择的查询 \(\mathcal{Q}\) 、分类头 \(\mathcal{H}_c(\cdot)\) 和框回归头 \(\mathcal{H}_b(\cdot)\) 是其组成部分。
-
Single-dataset object detection training
对于在单一数据集 \(D\) 上的训练,基于查询的目标检测器的优化目标可以表述如下:
\[\begin{equation} \underset{\Theta = \{Enc, Dec, \mathcal{Q}, \mathcal{H}_b,\mathcal{H}_c\}}{\operatorname{argmin}} \quad \mathbb{E}_{(I,\hat{B}) \sim D}[\ell(f(I; \Theta), \hat{B})], \end{equation} \]其中( \(I\) , \(\hat{B}\) )表示来自数据集 \(D\) 的图像和标注对。损失函数 \(\ell\) 通常是类别预测的交叉熵损失和框回归的广义交并比损失。
Dataset-specific Head with Frozen Classifier
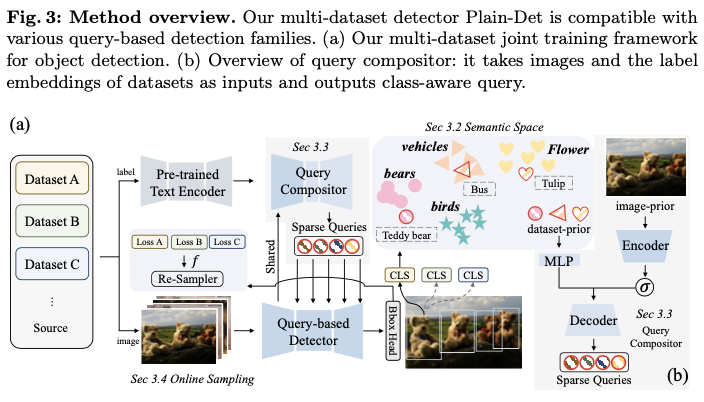
论文的多数据集目标检测框架与任何基于查询的目标检测架构兼容。为了支持多个数据集,为每个数据集设定了一个独特的数据集特定分类头。在这些分类头中,分类器在训练期间是预先提取并且被冻结的。
-
Object detector with dataset-specific classification head
多个数据集 \(D_1\) , \(D_2\) , ..., \(D_M\) 及其对应的标签空间 \(L_1\) , \(L_2\) , \(...\) , \(L_M\) 可能具有不一致的分类法。例如,Obj365数据集中的 “dolphin” 类在COCO数据集中被标记为背景。因此,最近的工作通过串联每个数据集特定的标签空间、学习从每个标签空间到统一标签空间的映射,或为类名的子词集分配软标签,手动或自动地为 \(M\) 个数据集创建一个统一的标签空间。然而,统一的标签空间在扩展到更多数据集时缺乏灵活性,并且随着标签空间大小的增加,往往变得更加嘈杂。
因此,论文提出保持每个标签空间的独立,以直接和自然地解决不一致分类法的问题。具体而言,通过添加 \(M\) 个数据集特定的分类头 \(\mathcal{H}_{c}^{1}(\cdot)\) , \(\mathcal{H}_{c}^{2}(\cdot)\) , ..., \(\mathcal{H}_{c}^{M}(\cdot)\) 来增强基于查询的目标检测器,每个分类头专注于对其对应标签空间内的对象进行分类:
\[\begin{equation} \begin{aligned} \hat{\mathcal{Q}} &= Dec( Enc(I), \mathcal{Q}), \\ C^m &= \mathcal{H}_{c}^{m}(\hat{\mathcal{Q}}), \quad B=\mathcal{H}_b(\hat{\mathcal{Q}}), \end{aligned} \end{equation} \]其中 \(\mathcal{H}_{c}^{m}(\cdot)\) 是数据集 \(D_m\) 在标签空间 \(L_m\) 上的分类头。编码器 \(Enc(\cdot)\) 、解码器 \(Dec(\cdot)\) 、对象查询 \(\mathcal{Q}\) 和类无关的框回归头 \(\mathcal{H}_b(\hat{\mathcal{Q}})\) 在各个数据集之间是共享的。值得注意的是,尽管检测器在形式上与分区检测器相似,但分类头是根据各自的目标独立优化的。相比之下,分区检测器随后优化分区检测器的输出,以统一分类法为目标。
-
Frozen classifiers with a shared semantic space
虽然数据集特定的头部解决了由于不一致的分类法引起的冲突,但它们并未充分利用来自不同数据集的相似语义类,例如共同类“person”,以实现全面学习。为了解决这个问题并在不同数据集之间传递共有知识,论文选择利用预训练的CLIP模型的特征空间作为类标签的共享语义空间。
具体而言,对于每个数据集 \(D_m\) 及其标签空间 \(L_m\) ,将其标签的CLIP文本嵌入作为其分类头 \(\mathcal{H}_{c}^{m}(\cdot)\) 中的分类器 \(W^m\) :
其中 \(\text{Prompt}(L_m)\) 为标签空间 \(L_m\) 中的每个类生成文本提示 " \(\textit{the photo is}\) [class name]", \(Enc_{\text{text}}(\cdot)\) 是CLIP的冻结文本编码器。
为了纠正因CLIP的训练数据分布而产生的偏差,通过去除基础偏差来校准文本嵌入,具体如下:
其中 \(\text{Enc}_{\text{text}}(\texttt{NULL})\) 是空字符串的文本嵌入,Norm是L2归一化。
Class-Aware Query Compositor
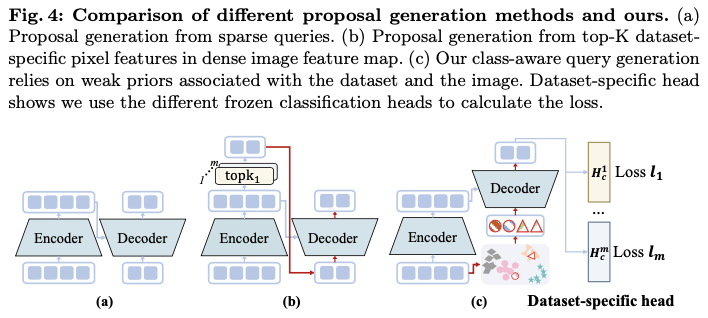
-
Object query generation
作为基于查询的目标检测器的核心组件,目标查询生成在单数据集训练中得到了广泛的研究,产生了多种类型,基于它们与图像的独立性。在多数据集目标检测中,由于涉及的多个数据集的多样性,初始化目标查询变得更加重要,这超出了单数据集目标检测中查询初始化的范围。
在单数据集目标检测中,查询通常是随机初始化或根据数据集特定的Top-K分数从输入图像特征图生成的(见图4a和b)。在对多数据集目标检测的初步实验中,从编码器(图2中的Def-DETR++)中选择Top-K像素特征导致性能显著下降,而相比之下,单数据集训练的性能更好。这是因为图像内的Top-K候选对象在很大程度上依赖于数据集分类法,并且与数据集密切相关。过于强烈的数据集先验使检测器向特定于数据集的解码倾斜,从而阻碍了解码器充分利用多个数据集进行全面学习。相反,数据集无关的查询初始化(图2中的Def-DETR)在所有数据集之间共享相同的可学习目标查询。
基于这些观察和见解,论文提出了一种新颖的多数据集目标检测查询初始化方法(见图4c)。类感知查询初始化既不是数据集无关的,也不是强烈依赖数据集的,而是依赖于与数据集和图像相关的弱先验。
给定图像 \(I\) 及其对应数据集 \(D_m\) 的分类器 \(\hat{W}^m\) ,首先根据分类器构造数据集特定的弱查询嵌入 \(\mathcal{Q}^b\) ,具体如下:
\[\begin{equation} \mathcal{Q}^b = \text{MLP} (\hat{W}^m). \end{equation} \]值得注意的是,尽管是数据集特定的,但与直接选择特定于数据集的图像内容的强先验不同,通过使用其数据集特定的分类器获得了一个弱先验,该分类器在不同的数据集中共享相同的语义空间。通过这个弱先验,不同数据集之间的相似语义标签可以被共享。
随后,选择提取全局图像特征,而不是Top-K本地内容特征,作为弱图像先验,将它与特定于数据集的查询结合如下:
其中Max-Pool对整个图像执行最大池化,而 \(\mathcal{W}\) 可以被视为一个弱图像先验。 \(\mathcal{Q}^c\) 表示输入到解码器的最终查询特征。重要的是,论文的修改仅专注于分类头和查询初始化,使其能够轻松应用于所有基于查询的目标检测器,并与其兼容。
Training with Hardness-indicated Sampling
除了上述的检测器架构调整以适应多个数据集外,训练一个多数据集检测器还带来了额外的挑战,这些挑战源于数据集分布、图像数量、标签空间大小等方面的显著差异。
论文首先制定多数据集训练的目标,然后基于对图2中引入的突现特性的观察来改进训练策略。总的来说,用于在 \(M\) 个数据集 \(D_1\) , \(D_2\) , ..., \(D_M\) 上训练多数据集目标检测器的优化目标可以表述如下:
其中,除了针对特定任务的分类头 \(\mathcal{H}_c^{m}\) 外,目标检测器 \(f(\cdot)\) 的其余组件,包括编码器 \(Enc(\cdot)\) 、解码器 \(Dec(\cdot)\) 、用于生成目标查询 \(\mathcal{Q}^c\) 的轻量级MLPs(公式7)以及与类别无关的框回归头 \(\mathcal{H}_b(\cdot)\) ,在不同数据集之间是共享的。多亏了特定于数据集的分类头 \(\mathcal{H}_c^{m}(\cdot)\) ,损失 \(\ell_m\) 能够自然地针对特定数据集进行定制,确保针对每个数据集单独保留原始训练损失和采样策略。例如,对长尾LVIS数据集应用RFS,但不用于COCO数据集。
虽然特定于数据集的损失可以适应每个数据集的内部特征,但数据集之间的显著差异,例如数据集大小的差异,带来了必须解决的训练挑战。因此,论文提出了一种硬度指示的采样策略,以平衡不同数据集之间的图像数量,并在在线训练过程中动态评估数据集的难度。
首先定期记录不同数据集的框损失 \(L_1, \ldots, L_m\) 。然后按如下方式计算在线采样权重 \(w_m\) :
\[\begin{equation} {w_{m} }=\frac{L_{m}}{\min(\{L_{i}\}_{i=1}^{m})} [\frac{\max(\{S_{i}\}_{i=1}^{m}))}{S_{m}}]^\frac{1}{2}, \end{equation} \]其中 \(S_i\) 表示第 i 个数据集中图像的数量, \(w_m\) 将涉及控制数据采样中每个数据集的权重。在线采样器将根据其对应的权重 \(w_m\) 的比例从每个数据集中采样数据。
Experiment
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
