Transformer中的位置编码(Positional Encoding)
标准位置编码
原理上Transformer是无法隐式学到序列的位置信息的,为了可以处理序列问题,Transformer提出者的解决方案是使用位置编码(Position Encode/Embedding,PE)[1][2] . 大致的处理方法是使用sin和cos函数交替来创建位置编码PE, 计算公式如下:
\[PE_{t,2i}=\sin(t/10000^{2i/d}),\\PE_{t,2i+1}=\cos(t/10000^{2i/d}), \]在这个公式中, \(t\) 表示的是token的位置, \(i\) 表示的是位置编码的维度
他的最终可视化效果长这样
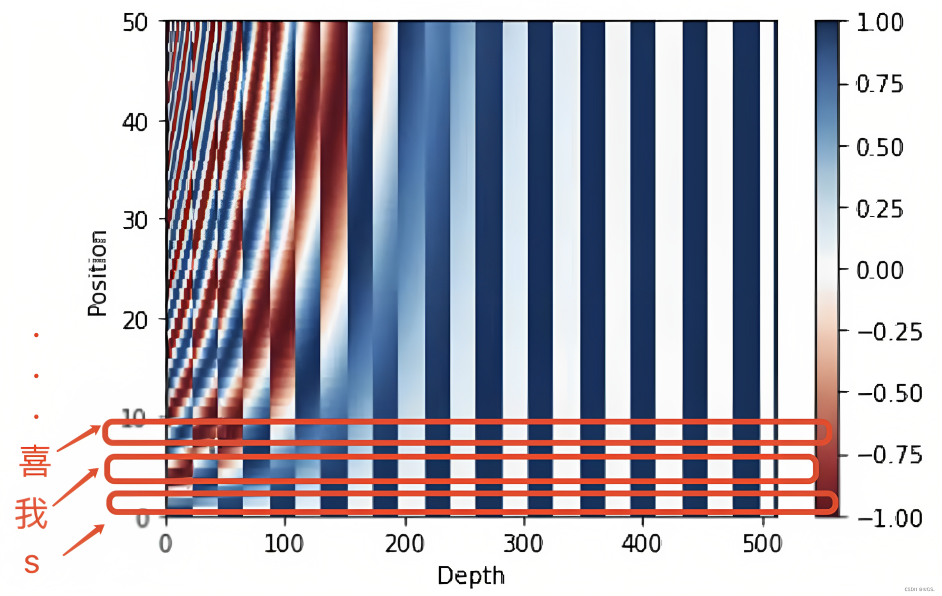
位置编码的作用, 就简而言之就是将每个位置编号,从而每个编号对应一个向量,最终通过结合位置向量和词向量,作为输入embedding,就给每个词都引入了一定的位置信息,这样Attention就可以分辨出不同位置的词了[3],这篇文章[3:1]有标准位置编码的具体实现.
旋转位置编码(RoPE)
reference