本文深入探讨Transformer模型中三种关键的注意力机制:自注意力、交叉注意力和因果自注意力。这些机制是GPT-4、Llama等大型语言模型(LLMs)的核心组件。通过理解这些注意力机制,我们可以更好地把握这些模型的工作原理和应用潜力。
我们不仅会讨论理论概念,还将使用Python和PyTorch从零开始实现这些注意力机制。通过实际编码,我们可以更深入地理解这些机制的内部工作原理。
文章目录
- 自注意力机制- 理论基础- PyTorch实现- 多头注意力扩展
- 交叉注意力机制- 概念介绍- 与自注意力的区别- PyTorch实现
- 因果自注意力机制- 在语言模型中的应用- 实现细节- 优化技巧
通过这种结构,我们将逐步深入每种注意力机制从理论到实践提供全面的理解。让我们首先从自注意力机制开始,这是Transformer架构的基础组件。
自注意力概述
自注意力机制自2017年在开创性论文《Attention Is All You Need》中被提出以来,已成为最先进深度学习模型的核心,尤其是在自然语言处理(NLP)领域。考虑到其广泛应用,深入理解自注意力的运作机制变得尤为重要。
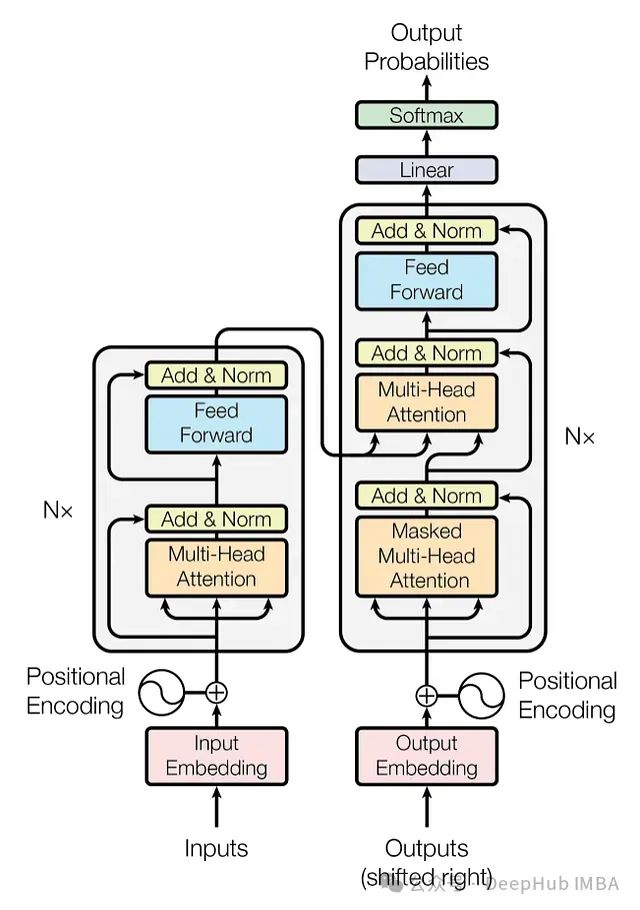
图1:原始Transformer架构
在深度学习中,"注意力"概念的引入最初是为了改进递归神经网络(RNNs)处理长序列或句子的能力。例如,在机器翻译任务中,逐字翻译通常无法捕捉语言的复杂语法和表达方式,导致翻译质量低下。
https://avoid.overfit.cn/post/e8a9be7f1a02402d8ce72c9526d7afa5
标签:Transformer,模型,PyTorch,Pytorch,机制,注意力,因果 From: https://www.cnblogs.com/deephub/p/18461904