大语言模型(LLMs)在推理任务中,如数学问题求解和编程,已经展现出了优秀的性能。尽管它们能力强大,但在实现能够通过计算和交互来改进其回答的算法方面仍然面临挑战。现有的自我纠错方法要么依赖于提示工程,要么需要使用额外的模型进行微调,但这些方法都有局限性,往往无法产生有意义的自我纠错。
这是谷歌9月发布在arxiv上的论文,研究者们提出了一种新方法自我纠错强化学习(SCoRe),旨在使大语言模型能够在没有任何外部反馈或评判的情况下"即时"纠正自己的错误。SCoRe通过在线多轮强化学习,使用自生成的数据来训练单一模型。这种方法解决了监督式微调中的一些挑战,如模型倾向于进行微小编辑而不做实质性改进,以及训练数据与推理数据之间分布差异所带来的问题。
方法详细描述
SCoRe的工作原理分为两个阶段:
- 初始化阶段:- 训练模型优化纠错性能,同时保持其初始回答接近基础模型的回答。- 这可以防止模型在第一次尝试时偏离太远。
- 强化学习阶段:- 模型进行多轮强化学习,以最大化初始回答和纠正后回答的奖励。- 包含一个奖励加成,以鼓励从第一次到第二次尝试有显著改进。
通过这种训练结构,SCoRe确保模型不仅仅是产生最佳的初始回答并进行最小化纠正,而是学会对其初始答案进行有意义的改进。
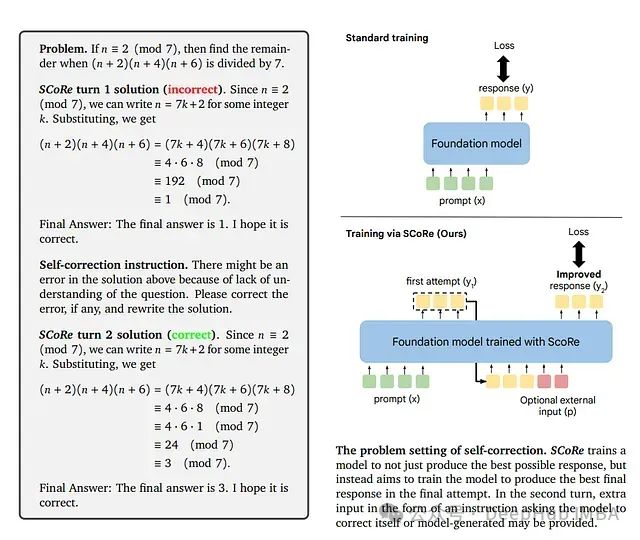
如图所示,SCoRe的方法概述包括了初始化阶段和强化学习阶段,展示了如何通过这两个阶段来优化模型的自我纠错能力。
https://avoid.overfit.cn/post/84d1cd5034a94a7bb51dfbe951b30ed2
标签:模型,自我,学习,SCoRe,教导,强化,纠错 From: https://www.cnblogs.com/deephub/p/18445530