Zookeeper 基础学习
Zookeeper 官网: http://zookeeper.apache.org/ 注:以下操作在CentOS7环境操作。
Zookeeper 是 Apache 的一个分布式服务框架,是 Apache Hadoop 的一个子项目。官方文档上这么解释 Zookeeper,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。简单来说 zookeeper=文件系统+监听通知机制。
学前须知
Zoopeeker数据模型
ZooKeeper 数据模型采用层次化的多叉树形结构,每个节点上都可以存储数据,这些数据可以是数字、字符串或者是二进制序列。并且。每个节点还可以拥有 N 个子节点,最上层是根节点以“/”来代表。每个数据节点在 ZooKeeper 中被称为 Znode,它是 ZooKeeper 中数据的最小单元。并且,每个 znode 都有一个唯一的路径标识。
graph TD / --> /app1 / --> /app2 /app1 --> /app1/child1 /app1 --> /app1/child2 /app1 --> /app1/child3 /app2 --> ...Znode
在 Zookeeper 中,znode 是一个跟 Unix 文件系统路径相似的节点,可以向节点存储数据或者获取数据。Zookeeper 底层是一套数据结构。这个存储结构是一个树形结构,其上的每一个节点,我们称之为 “Znode”。
其中每一个 Znode 默认能够存储 1MB 的数据(Zookeeper主要是协调服务的,而不是用来存储业务数据的,所以不要放比较大的数据)
Znode 节点的 4 中不同的类型:
PERSISTENT-持久化目录节点
客户端与 zookeeper 断开连接后,该节点依旧存在。
PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点
客户端与 zookeeper 断开连接后,该节点依旧存在,只是 Zookeeper 给该节点名称进行顺序编号。
EPHEMERAL-临时目录节点
客户端与 zookeeper 断开连接后,该节点被删除。
EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点
客户端与 zookeeper 断开连接后,该节点被删除,只是 Zookeeper 给该节点名称进行顺序编号。
监听通知机制
ZooKeeper使用了一种类似于观察者设计模式的方法来实现实时的数据变化通知机制。当客户端注册监听它关心的目录节点(ZNode)时,如果该目录节点发生了变化(如数据改变、被删除、子节点增加或删除),ZooKeeper会通过Watcher机制通知客户端
零、环境安装
(一)、安装单机版本
首先准备一个Linux操作系统,可以是云服务器或者是虚拟机。
1、上传Zookeeper对应版本的压缩包并解压
# 解压
tar -zxf apache-zookeeper-3.6.0-bin.tar.gz
# 如果以前使用过其它版本可以查看并停止
ps -ef | grep zookeeper
kill -9 (id)
2、目录结构
bin:放置运行脚本和工具脚本,
conf:zookeeper 默认读取配置的目录,里面会有默认的配置文件
docs:zookeeper 相关的文档
lib:zookeeper 核心的 jar
logs(默认没有这个目录):zookeeper 日志
3、配置Zookeeper
Zookeeper 在启动时默认的去 conf 目录下查找一个名称为 zoo.cfg 的配置文件。在 zookeeper 应用目录中有子目录 conf。其中有配置文件模板:zoo_sample.cfg。zookeeper 应用中的配置文件为 conf/zoo.cfg。
# 使用拷贝指令先生成一个配置文件
cp zoo_sample.cfg zoo.cfg
然后:修改配置文件 zoo.cfg 中的 dataDir参数,指定了ZooKeeper实例的数据目录,也就是ZooKeeper保存其数据(如事务日志和快照文件)。
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/tmp/zookeeper # 修改为你创建的目录 mkdir xxx
# 如
dataDir=/www/apache-zookeeper-3.6.0-bin/data
其余参数:
clientPort:指定客户端连接ZooKeeper服务端口。
tickTime:ZooKeeper的基本时间单位,以毫秒为单位。
initLimit:初始化阶段允许的最大tick数。
syncLimit:同步阶段允许的最大tick数。
4、启动ZooKeeper
这里可以使用默认启动的方式,同时也可以通过指定配置文件路径来启动。(该文件在bin目录下)
# 默认的会去 conf 目录下加载 zoo.cfg 配置文件
./zkServer.sh start
# 指定加载配置文件
./zkServer.sh start 配置文件的路径。
启动成功后logs目录就会出现
5、停止ZooKeeper
./zkServer.sh stop
6、查看ZooKeeper状态
./zkServer.sh status
# 显示信息:
/usr/local/jdk1.8.0_144/bin/java
ZooKeeper JMX enabled by default
Using config: /www/apache-zookeeper-3.6.0-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: standalone
7、连接Zookeeper
注意配置文件zoo.cfg中是否修改对应的客户端连接端口号
# 连接成功输出:
Welcome to ZooKeeper!
...
[zk: localhost:2181(CONNECTED) 0] [root@hcss-ecs-369d bin]#
连接方式一
当然呢,下面的文件也在bin里面,建议不知道的小伙伴可以自己找找,你只需要清楚是运行当前目录下的sh所以找到就行了_
# 默认连接地址为本机地址,默认连接端口为 2181
./zkCli.sh
连接方式二
# 连接指定 IP 地址与端口
./zkCli.sh -server ip:port
查看一下(后续会有指令介绍):
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper]
# Ctrl + C 退出
(二)、集群安装
1、基础了解
首先Zookeeper 集群中的角色主要有以下三类,这表示我们想要构建一个集群是需要这些角色的即三个:
| 角色 | 说明 |
|---|---|
| Leader(领导者) | 为客户端提供读和写的服务,负责投票的发起和决议,更新系统状态。 |
| Follower(跟随者) | 为客户端提供读服务,如果是写服务则转发给 Leader。参与选举过程中的投票。 |
| Observer(观察者) | 为客户端提供读服务,如果是写服务则转发给 Leader。不参与选举过程中的投票,也不参与“过半写成功”策略。在不影响写性能的情况下提升集群的读性能。此角色于 ZooKeeper3.3 系列新增的角色。 |
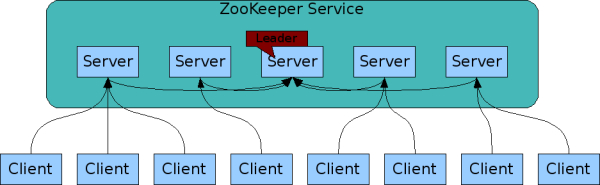
2、集群配置
(1)、首先
停止开始启动的单体zookeeper,可以使用linux命令进行检查,参考:1、上传Zookeeper对应版本的压缩包并解压,或者确定启动的情况下可以使用停止启动的指令:./zkServer.sh stop
(2)、其次
使用 3 个 Zookeeper 应用搭建一个伪集群(即通过不同部署在一台服务器上,使用不同端口区分)。客户端监听端口分别为:2181、2182、2183。投票选举端口分别为 2881/3881、2882/3882、2883/3883。
这里我们将已经解压好的Zookeeper,拷贝三份放在一个新的目录中,如集群目录(自己mkdir一个):zookeeperCluster
# 将 apache-zookeeper-3.6.0-bin 目录 拷贝到对应的 ./zookeeperCluster 目录中
cp -r apache-zookeeper-3.6.0-bin ./zookeeperCluster
为了利于集群标识:
# 这里我们通过移动的方式,将其改名为第一个 01,后续在拷贝 02 03
mv apache-zookeeper-3.6.0-bin zookeeper01
注意:如果是根据前面的单体拷贝过来的,已经创建的data还在,当然你可以删除里面的内容,如果直接看的集群,就需要创建这个文件,并且构建配置文件 zoo.cfg
这里和单体类似,我们先准备一个data目录存储 (参考:3、配置Zookeeper)
mkdir data # 我直接就在其根目录下创建
# 拷贝准备配置文件
cp zoo_sample.cfg zoo.cfg
# 拷贝另外两个
cp -r zookeeper01 zookeeper02
cp -r zookeeper01 zookeeper03
(3)、再次
修改三个服务对应的配置文件中的 dataDir 属性地址为对应的路径:
# 01
dataDir=/www/zookeeperCluster/zookeeper01/data
# 02
dataDir=/www/zookeeperCluster/zookeeper02/data
# 03
dataDir=/www/zookeeperCluster/zookeeper03/data
(4)、再次
在 Zookeeper 集群中,每个节点需要一个唯一标识。这个唯一标识要求是自然数。且唯一标识保存位置是:数据缓存目录(dataDir=/usr/local/zookeeper/data)的 myid 文件中。
其中“数据缓存目录”为配置文件 zoo.cfg 中的配置参数在 data 目录中创建文件 myid :
# 创建文件
touch myid
# 为应用提供唯一标识。本环境中使用 1、2、3 作为每个节点的唯一标识。
vi myid
简化方式为: echo [唯一标识] >> myid。 echo 命令为回声命令,系统会将命令发送的数据返回。 '>>'为定位,代表系统回声数据指定发送到什么位置。 此命令代表系统回声数据发送到 myid 文件中。 如果没有文件则创建文件。
# 参考命令,即将内容 1 写入 >> 后的文件,如果文件不存在则先创建文件
echo 1 >> ./zookeeper01/data/myid
echo 2 >> ./zookeeper02/data/myid
echo 3 >> ./zookeeper03/data/myid
# 使用 cat 确定一下
cat ./zookeeper01/data/myid
(6)、最后
修改配置文件 zoo.cfg - 设置监听客户端、投票、选举端口
# 进行编辑
vim zoo.cfg
写入下面内容(注意:server.[这里的数字就是你对应myid中设置的值]):
注意:下面的服务所在的ip如果你是一台服务器部署就用localhost这样不用设置安全组也可以测试是否成功,当然如果你使用的是对应的公网ip那就需要设置对应的安全组。
#服务端口根据应用做对应修改,zk01-2181,zk02-2182,zk03-2183
clientPort=2181
# 以下每一个服务都要加,相互之间要能找到对方,毕竟没有使用nginx来找,只放在领导者,万一领导者挂了=_=
server.1=服务所在的ip:2881:3881
server.2=服务所在的ip:2882:3882
server.3=服务所在的ip:2883:3883
检查以下,没有问题就可以启动了:
# 启动
zookeeper01/bin/zkServer.sh start
zookeeper02/bin/zkServer.sh start
zookeeper03/bin/zkServer.sh start
# 查看状态
zookeeper01/bin/zkServer.sh status
# 如果出现这个,看看是不是配置了公网ip没有设置安全组
Error contacting service. It is probably not running.
可以看到下面效果就已经ok了:

(7)Observer 哪去了?
Observer 则需要进步修改配置,当然前提是你的版本 >= ZooKeeper3.3 。
# 修改配置文件
server.1=localhost:2881:3881
server.2=localhost:2882:3882
server.3=localhost:2883:3883:observer # 这个表示你要将这个服务作为 观察者
此时:

(8)、关于客户端连接
前面提及了单体中有两种连接方式,其中第二种方式发挥作用了,可以使用任何节点中的客户端工具连接集群中的任何节点:
# 这里可以自行测试,比如使用第一个服务的客户端连接第二个服务
./zkCli.sh -server 对应集群中的一个服务的ip:对应端口
3、使用脚本简化集群启动和关闭
1、启动
选择一个合适的位置放置脚本,这里取决于文件相对目录
# 创建一个脚本文件
vim startall.sh
# 写入内容
zookeeper01/bin/zkServer.sh start
zookeeper02/bin/zkServer.sh start
zookeeper03/bin/zkServer.sh start
# 赋予权限,ll查看权限,并验证
# 在 Linux 中可以使用 chmod 命令为文件授权。
# 777 表示为文件分配可读,可写,可执行权限
chmod 777 startall.sh
# 使用ll命令查看,文件变绿一般就是可执行了
2、关闭
关闭同理
# 创建一个脚本文件
vim stopall.sh
# 写入内容
zookeeper01/bin/zkServer.sh stop
zookeeper02/bin/zkServer.sh stop
zookeeper03/bin/zkServer.sh stop
# 赋予权限,ll查看权限,并验证
# 在 Linux 中可以使用 chmod 命令为文件授权。
# 777 表示为文件分配可读,可写,可执行权限
chmod 777 stopall.sh
# 使用ll命令查看,文件变绿一般就是可执行了
# 验证是否关闭
ps -ef | grep zookeeper