Lab3 Raft
1.Getting Started
代码位置:
-
基础框架代码位置:src/raft/raft.go
-
测试代码:src/raft/test_test.go
建议测试时使用-race
2.The code
-
向
raft/raft.go添加代码来实现Raft。 -
实现必须支持以下接口
// 创建一个Raft Server rf := Make(peers, me, persister, applyCh) func Make(peers []*labrpc.ClientEnd, me int, persister *Persister, applyCh chan ApplyMsg); // start agreement on a new log entry: rf.Start(command interface{}) (index, term, isleader) // ask a Raft for its current term, and whether it thinks it is leader rf.GetState() (term, isLeader) // each time a new entry is committed to the log // each Raft peer should send an ApplyMsg to the // service (or tester) type ApplyMsg通过调用
Make(peers,me,…)来创建Raft peer。peers:Raft所有Server的网络标识符(比如IP地址),包括该peer本身,用于RPC。me:该peer在peers数组中的下标。
Start(command):要求Raft开始处理、将命令追加到复制日志。Start()应立即返回,无需等待日志追加完成。service期望您的实现将每个新提交的日志条目的
ApplyMsg发送到Make()的applyChchannel参数。?? -
raft.go包含发送RPC(sendRequestVote())和处理传入RPC(RequestVote())的示例代码。您的Raft peer应使用labrpc Go包(位于src/labrpc)交换RPC。测试组件可以告诉labrpc延迟某个RPC、重新排序并丢弃它们以模拟各种网络故障。你可以临时修改labrpc,但请确保你的Raft与原始labrpc兼容,因为需要使用它来测试和评分。您的Raft实例必须仅与RPC交互;例如,它们不允许使用共享变量或文件进行通信 -
后续实验都以该实验为基础,编写可靠的代码非常重要。
Part 3A: leader election (moderate)
Task:
实现Raft的Leader选举和心跳(没有日志条目的AppendEntries RPC)机制。本节的目标是选举出Leader,如果Leader没有失效,其将保持Leader状态;如果旧Leader失效或旧Leader的消息丢失,则选出新Leader接管。
运行
go test -run 3A来测试你的代码。
提示:
- 直接运行你的Raft实现会有些困难;你可以通过测试器来运行它,即
go test -run 3A。 - 遵循论文中的图2。本节你只需关注发送和接收
RequestVote RPC、Leader选举规则,以及选举相关的State属性。 - 将图2中的Leader选举状态添加到
raft.go的Raft结构体中。还需要定义一个结构体存储每个日志条目的信息。 - 填写
RequestVoteArgs和RequestVoteReply结构体。修改Make()函数以创建一个后台goroutine,该goroutine会定期启动领导者选举,通过发送RequestVoteRPC来实现,尤其是在一段时间没有收到其他节点的响应时。实现RequestVote()RPC处理器,以便服务器之间能够投票。 - 为实现心跳,定义一个
AppendEntries RPC结构体(暂时不需要所有的参数),并使Leader定期发送RPC。编写一个AppendEntries RPC处理方法。 - 测试器要求Leader每秒发送心跳RPC的次数不超过十次。
- 测试器要求你的Raft在旧领导者失败后(如果多数节点仍能通信),五秒内选举出新的领导者。
- 论文的第5.2节提到选举超时范围为150到300ms。由于测试器限制每秒最多发送十次心跳,因此你需要使用比150到300毫秒更大的选举超时时间,但又不能太大,以免在五秒内无法选出Leader。
- 你可能会发现Go的
rand很有用。 - 你需要编写周期性或延迟时间后执行的代码。最简单的方法是创建一个 goroutine,并在循环中调用
time.Sleep();请参见Make()为此目的创建的ticker()goroutine。不要使用Go的time.Timer或time.Ticker,因为它们很难正确使用。 - 如果你的代码无法通过测试,请重新阅读论文中的图2;Leader选举的完整逻辑分布在图的多个部分。
- 不要忘记实现
GetState()。 - 测试器在关闭一个实例时会调用
rf.Kill()。你可以通过rf.killed()检查Kill()是否已被调用。你可能需要在所有循环中进行检查,以避免死掉的Raft实例打印出混乱的消息。 - Go RPC只发送字段名以大写字母开头的结构体字段。子结构体的字段名也必须以大写字母开头(例如,数组中的日志记录字段)。
labgob包会警告你这点;不要忽视这些警告。 - 本实验中最具挑战性的部分可能是调试。记得让你的实现易于调试。
如果实现正确,你的测试结果会和下图类似
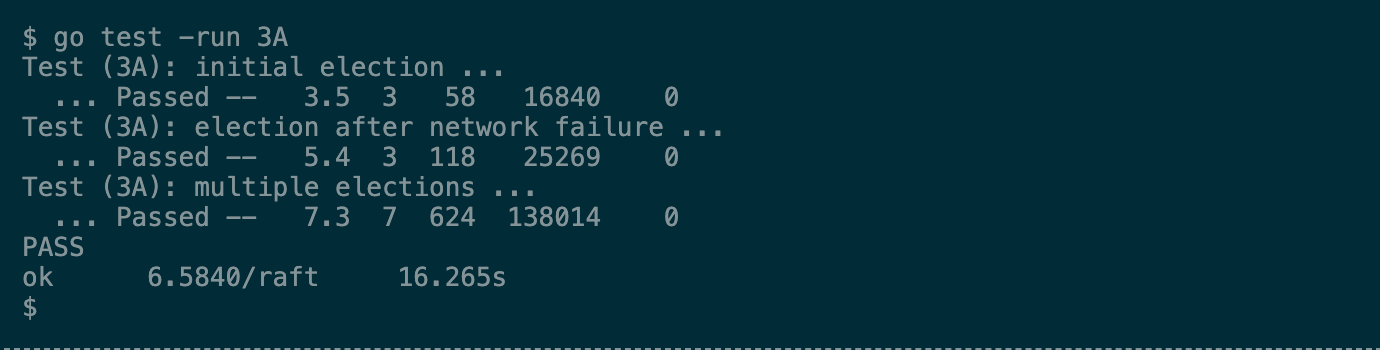
每行Passed包含五个数字:分别是
- 测试花费的时间(秒)
- Raft节点数量
- 测试期间发送的RPC数量
- RPC消息的总字节数
- Raft报告已提交的日志条目数量
你可以忽略这些数字,但它们会有助于你检查实现中发送的RPC数量。在后续Lab中,如果测试go test总花费超过600秒,或任何单个测试超过120秒,会判定失败。
Part 3B: log (hard)
Task
完成Leader和Follower代码,实现Append New Log Entries的功能,通过
go test -run 3B的测试。
提示:
- 第一个目标是通过
TestBasicAgree3B()测试。首先实现Start(),然后编写代码通过AppendEntries RPC发送和接收新的日志条目,如图2所示。在每个对等点上的applyCh上发送每个新提交的条目。 - 您将需要实现选举限制(论文中第5.4.1节)。
- 您的代码中可能存在反复检查某些事件的循环。不要让这些循环不停地执行,这会减慢代码速度,导致测试失败。使用Go的条件变量,或在每个循环迭代中插入
time.Sleep(10 * time.Millisecond)。 - 为方便之后的Lab,编写干净清晰的代码。如需参考,请重新访问我们的指导页面,其中包含开发和调试代码的建议。
- 如果测试失败,请查看
test_test.go和config.go了解正在测试的内容。config.go还说明了测试如何使用Raft API。
如果代码运行速度太慢,测试可能会失败,可以使用time命令检查代码使用了多少实际时间和CPU时间。以下是典型的输出:
$ time go test -run 3B
Test (3B): basic agreement ...
... Passed -- 0.9 3 16 4572 3
Test (3B): RPC byte count ...
... Passed -- 1.7 3 48 114536 11
Test (3B): agreement after follower reconnects ...
... Passed -- 3.6 3 78 22131 7
Test (3B): no agreement if too many followers disconnect ...
... Passed -- 3.8 5 172 40935 3
Test (3B): concurrent Start()s ...
... Passed -- 1.1 3 24 7379 6
Test (3B): rejoin of partitioned leader ...
... Passed -- 5.1 3 152 37021 4
Test (3B): leader backs up quickly over incorrect follower logs ...
... Passed -- 17.2 5 2080 1587388 102
Test (3B): RPC counts aren't too high ...
... Passed -- 2.2 3 60 20119 12
PASS
ok 6.5840/raft 35.557s
real 0m35.899s
user 0m2.556s
sys 0m1.458s
$
ok 6.5840/raft 35.557s表示3B测试所用时间为35.557秒的实际时间。user 0m2.556s表示代码消耗了2.556秒的CPU时间,即实际执行指令(而不是等待或休眠)所用的时间。- 如果你的代码在3B测试中使用的实际时间远超一分钟,或者CPU时间远超5秒,您以后可能会遇到麻烦。寻找以下情况:花费时间在休眠或等待RPC超时,循环在没有休眠或等待条件或通道消息的情况下运行,或者发送大量RPC。
Part 3C: persistence (hard)
如果Raft服务器重启,它应该从上次中断的地方继续运行。这要求Raft能够保存和恢复持久化状态。论文的图2显示了哪些状态属于持久化状态。
你需要在每次状态发生变化时将持久化状态写入磁盘,并在重启后从磁盘读取状态。本次Lab不使用磁盘,而是通过Persister对象保存和恢复持久化状态(参见 persister.go)。Raft.Make()的调用方会提供Persister,该对象包含Raft最近的持久化状态(如果有的话)。Raft应该从Persister中获取之前保存的状态并初始化自己,并在每次状态变化时将持久化状态保存进去。本节主要使用Persister的ReadRaftState()和Save()方法。
TASK:
完成
raft.go中的persist()和readPersist()函数,实现保存和恢复持久化状态的功能。你需要将持久化状态序列化为字节数组,传递给Persister。使用
labgob编码器;查看persist()和readPersist()中的注释。labgob类似于Go的gob编码器,但如果编码的结构体中有以小写开头的字段名,labgod会报错。你可以传递
nil作为persister.Save()的第二个参数。在持久化状态发生更改的地方调用persist()进行存储。完成这些步骤后,如果你的其余实现正确,你应该可以通过所有3C测试。
你可能需要一种优化,即一次回退nextIndex多个条目。查看Raft论文的第7页底部和第8页顶部(灰色线标记处)。
当拒绝AppendEntries请求时,Follower可以将冲突条目的term以及该term它存储的第一个Index返回给Leader。Leader通过这些信息减少nextIndex,以跳过该任期的所有冲突条目;对于每个包含冲突条目的term,只需要一个AppendEntries RPC,而不是每个条目都需要一个RPC
论文在细节上较为模糊,你需要自行补充其中的空白。一种可能的实现是让拒绝消息包含以下内容:
XTerm: 冲突条目的term(如果有的话)
XIndex: Follower中,XTerm的第一个条目的Index(如果有的话)
XLen: Log的长度
Leader的处理逻辑如下:
Case 1: Leader中没有XTerm的条目:
nextIndex = XIndex
Case 2: Leader有XTerm的条目:
nextIndex = leader's last entry for XTerm
Case 3: Follower日志的长度太短:
nextIndex = XLen
一些提示:
- 运行
git pull更新Lab代码。- 3C测试比3A或3B测试要求更高,如果失败,可能是由3A或3B中的问题引起的
你的代码应通过所有3C测试(如下所示),以及3A和3B测试。
$ go test -run 3C
Test (3C): basic persistence ...
... Passed -- 5.0 3 86 22849 6
Test (3C): more persistence ...
... Passed -- 17.6 5 952 218854 16
Test (3C): partitioned leader and one follower crash, leader restarts ...
... Passed -- 2.0 3 34 8937 4
Test (3C): Figure 8 ...
... Passed -- 31.2 5 580 130675 32
Test (3C): unreliable agreement ...
... Passed -- 1.7 5 1044 366392 246
Test (3C): Figure 8 (unreliable) ...
... Passed -- 33.6 5 10700 33695245 308
Test (3C): churn ...
... Passed -- 16.1 5 8864 44771259 1544
Test (3C): unreliable churn ...
... Passed -- 16.5 5 4220 6414632 906
PASS
ok 6.5840/raft 123.564s
$
在提交之前,多次运行测试并PASS确保代码正确。
$ for i in {0..10}; do go test; one
Part 3D: log compaction (hard)
Raft论文第7章概述了SnapShot的思想,需要自行设计完成其中的细节
必须提供以下函数,服务可以调用该函数,并传入其状态的序列化快照:
Snapshot(index int, snapshot []byte)
在Lab 3D中,测试会定期调用Snapshot()。在Lab4中,你将编写一个调用 Snapshot()的键值服务器;快照将包含完整的键值对表。服务层会在每个节点上调用 Snapshot()(不仅仅是在领导者上)。
index表示快照中最高日志条目。Raft应该丢弃该点之前的日志条目。你需要修改Raft代码,使其在仅存储日志尾部的情况下工作。
你需要实现论文中讨论的InstallSnapshotRPC,允许Raft Leader通知落后的节点用快照替换其状态。你需要仔细思考InstallSnapshot如何与图2中的状态和规则进行交互。
当Follower接收到InstallSnapshot RPC时,它可以使用applyCh将快照发送给服务,在ApplyMsg中进行传递。ApplyMsg 结构定义已经包含了你需要的字段(以及测试器期望的字段)。注意,这些快照只能推进服务的状态,而不能使其倒退。
如果服务器崩溃,它必须从持久化数据重新启动。你的Raft应该同时持久化Raft状态和相应的快照。使用persister.Save()的第二个参数保存快照。如果没有快照,传递nil作为第二个参数。
当服务器重新启动时,读取持久化的快照并恢复其保存的状态。
Task:
实现 Snapshot() 和 InstallSnapshot RPC 以及对 Raft 的更改以支持这些功能(例如,使用精简后的日志操作)。当你的解决方案通过 3D 测试(以及之前所有的 Lab 3 测试)时,表示已经完成。
提示:
-
运行
git pull确保你拥有最新的软件。 -
一个好的起点是修改你的代码,使其能够存储从索引X开始的部分日志。开始可以将X设置为0并运行3B/3C测试。然后让
Snapshot(index)丢弃index之前的日志,并将X设置为index。如果一切顺利,你现在应该能够通过第一个3D测试。 -
接下来:当Leader没有所需的日志条目以使Follower赶上时,发送一个
InstallSnapshot RPC。 -
通过一个
InstallSnapshotRPC发送完整快照,不要实现图13中拆分快照的offset机制。 -
Raft必须以某种方式丢弃旧的日志条目,以使Go的垃圾收集器能够释放并重新使用内存;这要求不能有可达的引用(指针)指向丢弃的日志条目。
-
对于完整的Lab 3测试集(3A+3B+3C+3D)
- 不带
-race,合理耗时大约是6分钟实际时间和1分钟CPU时间 - 带
-race,合理耗时大约是10分钟实际时间和2分钟CPU时间
- 不带
你的代码应通过所有3D测试(如下所示),以及3A,3B和3C测试。
$ go test -run 3D
Test (3D): snapshots basic ...
... Passed -- 11.6 3 176 61716 192
Test (3D): install snapshots (disconnect) ...
... Passed -- 64.2 3 878 320610 336
Test (3D): install snapshots (disconnect+unreliable) ...
... Passed -- 81.1 3 1059 375850 341
Test (3D): install snapshots (crash) ...
... Passed -- 53.5 3 601 256638 339
Test (3D): install snapshots (unreliable+crash) ...
... Passed -- 63.5 3 687 288294 336
Test (3D): crash and restart all servers ...
... Passed -- 19.5 3 268 81352 58
PASS
ok 6.5840/raft 293.456s
坑:
-
Leader发给Follower的RPC,Follower都能收到,但是Follower的回复,Leader一直收不到,
比如Follower已经有了1~8的Log,然后进行提交中
当发送到6时,Leader发来了最新的Snapshot,包含Index [1~9]的日志,然后我们将其提交,提交完后
Follower又提交了Index为8的Log,此时就出错了,因为Raft预期收到Index = 10的Log
怎么办?
接收到Snapshot时,不要自行提交,全部交给一个方法去提交