
开发者朋友们大家好:
这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement) 领域内「有话题的 新闻 」、「有态度的 观点 」、「有意思的 数据 」、「有思考的 文章 」、「有看点的 会议 」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。
本期编辑:@SSN,@鲍勃
01 有话题的新闻
1、OpenAI 发布「学院」计划:为开发者提供 100 万美元 API 信用额度及技术指导
OpenAI 于昨日(9 月 23 日)宣布推出「OpenAI 学院」,旨在帮助开发者和组织利用 AI 解决难题,并推动社区经济增长。该平台将确保生成式 AI 的强大功能在全球范围内广泛普及,包括中低收入国家。
OpenAI 表示,许多国家的科技行业发展迅速,拥有才华横溢的开发者和创新型组织,但仍然缺乏高级培训和技术资源的支持。通过投资于本地 AI 人才的发展,可以促进包括医疗、农业、教育和金融等行业的经济增长与创新。
该项目将提供如下方面的支持:
- 培训与技术指导: OpenAI 专家将为利用 AI 的开发者和使命驱动型组织提供支持。
- API 使用额度: 初步分发 100 万美元的 API 使用额度,以扩大对 OpenAI 模型的访问,帮助参与者构建和部署创新应用。
- 社区建设: 培养全球开发者网络,促进协作、知识共享与集体创新。
- 竞赛与孵化器: 与慈善家合作,投资于在社区前线解决问题的组织。
为进一步支持全球开发者,OpenAI 还资助并发布了「大规模多任务语言理解」(MMLU)基准的专业翻译,覆盖了 14 种语言,包括阿拉伯语、孟加拉语、中文、法语、德语、印地语、印尼语、意大利语、日语、韩语、葡萄牙语、西班牙语、斯瓦希里语和约鲁巴语。据介绍,该基准是衡量通用人工智能的标准。(@IT 之家)
2、美图「奇想大模型」视频生成能力已完成全面升级,可生成 1 分钟视频
美图公司旗下「奇想大模型」已完成全面升级,其中最为瞩目的是其视频生成功能。视频生成时长与画质、流畅性、真实性及可信度等方面提升显著,后续将逐步覆盖到美图旗下各产品中。
美图公司旗下的「奇想大模型」视频生成能力完成全面升级,在实现生成能力、生成效率以及模型性能的三重进阶基础上,结合美图在计算机视觉领域的多项自研技术,实现了视频生成时长、画质、流畅性、真实性及可信度等方面的提升。
据悉,美图奇想大模型的单次文生视频时长、单次图生视频时长均达 5 秒,支持生成 1 分钟、24FPS、1080P 的超长视频,升级后的视频生成功能将逐步覆盖美图秀秀、美颜相机、Wink、开拍、美图设计室、WHEE、MOKI 等产品。
据此前报道,今年 1 月 2 日,美图公司自研 AI 视觉大模型 MiracleVision(奇想智能)通过《生成式人工智能服务管理暂行办法》备案,将面向公众开放。美图 AI 视觉大模型 MiracleVision(奇想智能)于 2023 年 6 月内测,为美图秀秀、美颜相机、Wink、美图设计室、WHEE、美图云修等产品提供 AI 模型能力的同时,也帮助美图公司搭建起由底层、中间层和应用层构建的人工智能产品生态。(@IT 之家)
3、GPT-4o 能玩《黑神话:悟空》:精英怪胜率超人类,无强化学习纯大模型方案
阿里巴巴的研究人员们提出了一个新型 VARP(视觉动作角色扮演)智能体框架。它能直接将游戏截图作为输入,通过视觉语言模型推理,最终生成 Python 代码形式的动作,以此来操作游戏。
以玩《黑神话・悟空》为例,该智能体在 90% 简单和中等水平战斗场景中取胜。
研究人员以《黑神话・悟空》为研究平台,一共定义了 12 个任务,75% 与战斗有关。他们构建了一个人类操作数据集,包含键鼠操作和游戏截图,一共 1000 条有效数据。每个操作都是由原子命令的各种组合组成的序列。原子命令包括轻攻、闪避、重攻击、回血等。
然后,他们提出了 VARP 智能体框架。主要包含动作规划系统和人类引导轨迹系统。其中动作规划系统由情境库、动作库和人类引导库组成,利用 VLMs 进行动作推理和生成,引入分解特定任务的辅助模块和自我优化的动作生成模块。人类引导轨迹系统利用人类操作数据改进智能体性能,对于困难任务,通过查询人类引导库获取相似截图和操作,生成新的人类引导动作。
框架分别使用了 GPT-4o(2024-0513 版本)、Claude 3.5 Sonnet 和 Gemini 1.5 Pro。对比人类和 AI 的表现结果,可以看到小怪部分 AI 们的表现达到人类玩家水平。到了牯护院时,Claude 3.5 Sonnet 败下阵来,GPT-4o 胜率最高。但是对于新手玩家普遍头疼的幽魂,AI 们也都束手无策了。
另外研究还提到,由于 VLMs 推理速度受到限制,是无法实时输入每一帧画面的。它只能间隔输入关键帧,这也会导致 AI 在一些情况下错过 boss 攻击的关键信息。以及由于游戏中没有明确的道路引导且存在很多空气墙,在没有人类引导下,智能体也不能自已找到正确的路线。(@量子位)
4、PDF2Audio:将 PDF 文件转换为播客、讲座、摘要等音频内容
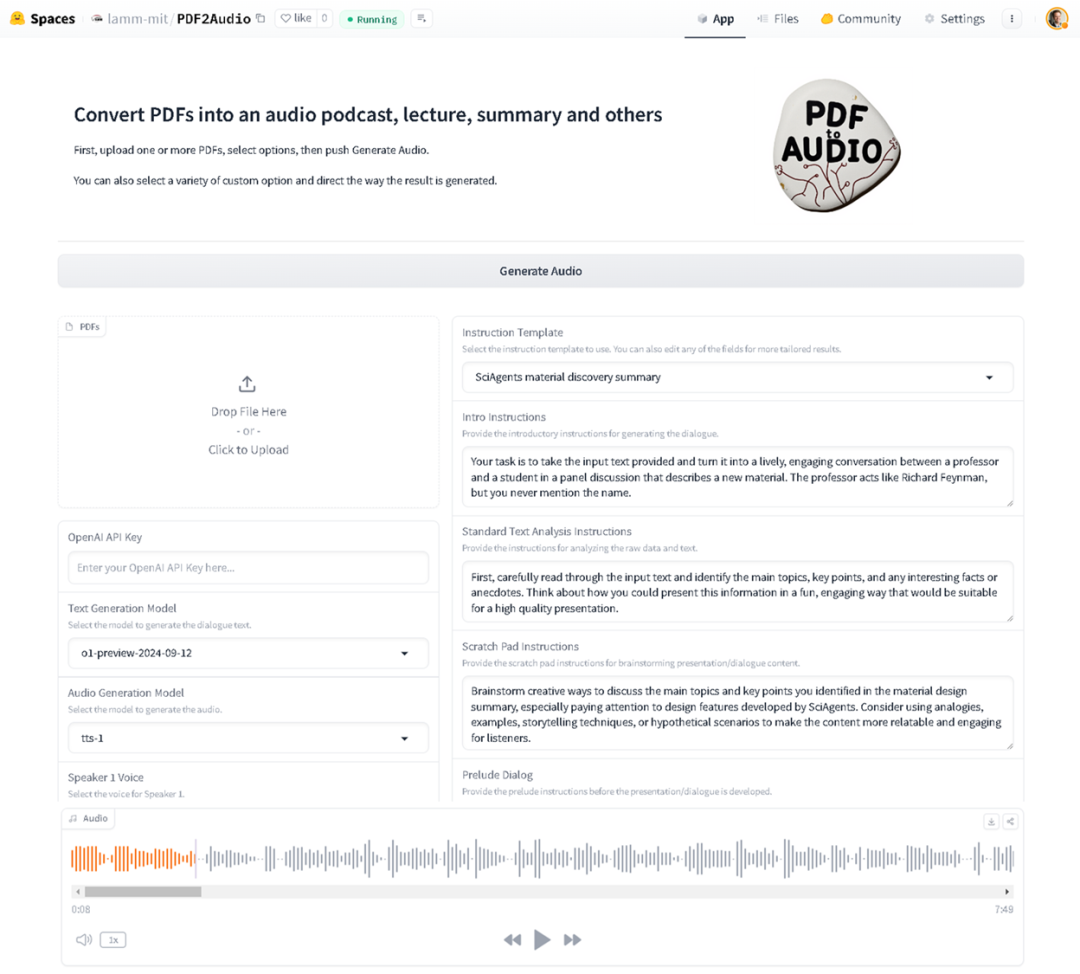
PDF2Audio 是一个开源项目,旨在将 PDF 文件转换为音频格式,如播客、讲座或摘要。该项目利用 OpenAI 的 GPT 模型进行文本生成和文本转语音(TTS)转换。用户可以上传多个 PDF 文件,并根据不同的模板(例如播客、讲座、摘要)生成音频内容。
功能亮点
- 支持多个 PDF 文件上传: 用户可以同时上传多个 PDF 文件,批量处理文档。
- 多种模板选择: 根据用户需求,支持生成不同类型的音频内容,模板包括播客、讲座、摘要等不同场景。
- 自定义生成模型: 用户可以自定义选择 GPT 模型和文本转语音(TTS)模型,以生成符合特定需求的音频内容。
- 不同语音选择: 支持选择多种语音风格和音色,为生成的音频提供不同的听觉体验。(小互 AI)
5、李开复发布新 AI 搜索引擎 BeaGo
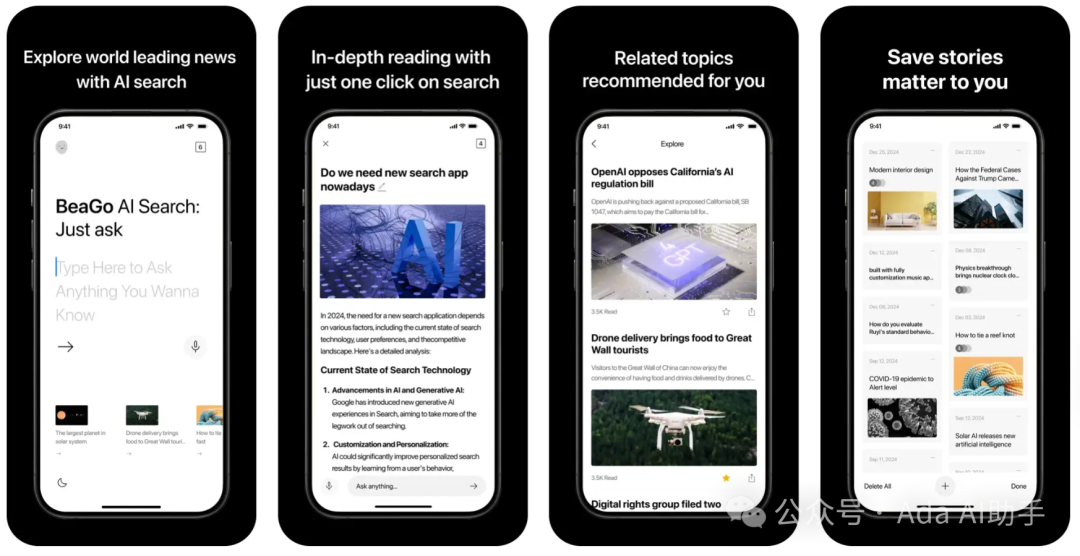
「零一万物」的 CEO 李开复推出了一款名为 BeaGo 的 AI 搜索引擎,它在提供搜索结果时致力于为用户提供每个查询的单一搜索结果同时包含图片,避免在有限屏幕空间内打开多个标签页的不便。
此前,李开复曾在 2005 年加入 Google,并在此后创立了创新工场 VC 基金,近年来专注于 AI 领域。(@APPSO)
02 有态度的观点
1、李飞飞最新 a16z 对话:空间智能不仅适用虚拟世界生成,还可融合现实世界,AI 技术进步将带来无法想象的新应用场景
近日,李飞飞与 a16z 合伙人 Martin Casado 以及研究者 Justin Johnson 展开讨论了 AI 领域的历史、现状以及未来发展方向,话题涵盖了 AI 技术的各个层面,特别是生成式 AI 和空间智能的未来潜力。
李飞飞强调,生成式 AI 在她的研究生阶段就已经存在,但早期技术还不成熟。随着深度学习和计算能力的飞跃,生成式 AI 在最近几年取得了令人瞩目的进展,成为 AI 领域的核心突破之一。
她还介绍了最新创业项目 World Labs,专注于「空间智能」,即机器在 3D 和 4D 空间中的理解和互动能力,用团队自己的话来说,「AI 在三维空间和时间中以三维方式感知、推理和行动的能力,并与现实世界进行交互」。
她指出,空间智能不仅适用于虚拟世界的生成,还可以融合现实世界,广泛应用于增强现实(AR)、虚拟现实(VR)和机器人领域,而 AI 技术的进步将为我们带来无法想象的新应用场景,包括虚拟世界生成、增强现实和与物理世界的交互。「如果能够实时、完美地理解周围的三维环境,会淘汰我们现在很多对物理世界的依赖。比如说手机、iPad、电脑显示器、电视,甚至还有手表。」(@有新 Newin)
写在最后:
我们欢迎更多的小伙伴参与「RTE 开发者日报」内容的共创,感兴趣的朋友请通过开发者社区或公众号留言联系,记得报暗号「共创」。
对于任何反馈(包括但不限于内容上、形式上)我们不胜感激、并有小惊喜回馈,例如你希望从日报中看到哪些内容;自己推荐的信源、项目、话题、活动等;或者列举几个你喜欢看、平时常看的内容渠道;内容排版或呈现形式上有哪些可以改进的地方等。

素材来源官方媒体/网络新闻
标签:RTE,李飞飞,视频,AI,模型,生成,OpenAI,开发者 From: https://www.cnblogs.com/Agora/p/18429127