目录
一、背景
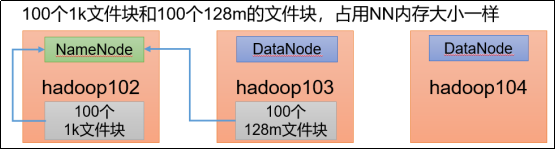
每个文件均按块存储,每个块的元数据存储在NameNode的内存中,因此HDFS存储小文件会非常低效。因为大量的小文件会耗尽NameNode中的大部分内存。但注意,存储小文件所需要的磁盘容量和数据块的大小无关。每个块的大小可以通过配置参数(
dfs.blocksize)来规定,默认的大小128M。例如,一个1MB的文件设置为128MB的块存储,实际使用的是1MB的磁盘空间,而不是128MB。
Hadoop 高可用环境部署,可参考我之前的文章:大数据Hadoop之——Hadoop 3.3.4 HA(高可用)原理与实现(QJM)
1)小文件是如何产生的?
- 动态分区插入数据,产生大量的小文件,从而导致 map 数量剧增;
- reduce 数量越多,小文件也越多,reduce 的个数和输出文件个数一致;
- 数据源本身就是大量的小文件;
2)文件块大小设置
同样对于如何设置每个文件块的大小,官方给出了这样的建议:
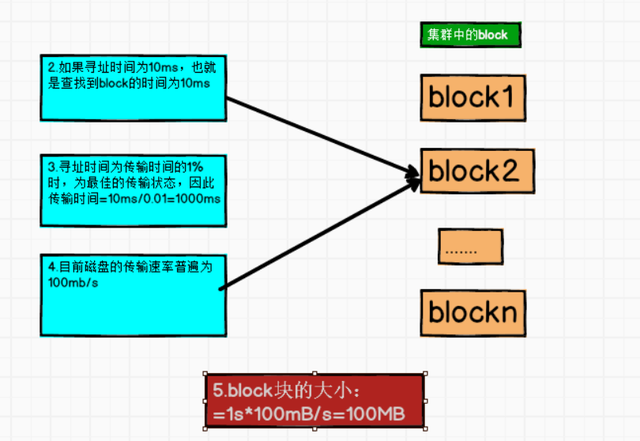
所以对于块大小的设置既不能太大,也不能太小,太大会使得传输时间加长,程序在处理这块数据时会变得非常慢,如果文件块的大小太小的话会增加每一个块的寻址时间。所以文件块的大小设置取决于磁盘的传输速率。
3)HDFS分块目的
HDFS中分块可以减少后续中MapReduce程序执行时等待文件的读取时间,HDFS支持大文件存储,如果文件过大10G不分块在读取时处理数据时就会大量的将时间耗费在读取文件中,分块可以配合MapReduce程序的切片操作,减少程序的等待时间。
二、HDFS小文件问题处理方案
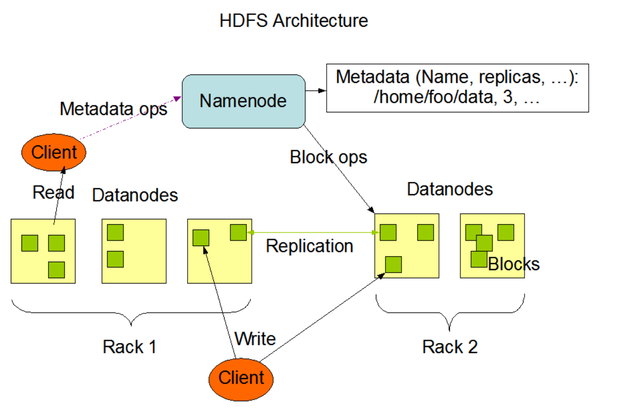
HDFS中文件上传会经常有小文件的问题,每个块大小会有150字节的大小的元数据存储namenode中,如果过多的小文件每个小文件都没有到达设定的块大小,都会有对应的150字节的元数据,这对namenode资源浪费很严重,同时对数据处理也会增加读取时间。对于小文件问题,Hadoop本身也提供了几个解决方案,分别为:Hadoop Archive,Sequence file和CombineFileInputFormat,除了hadoop本身提供的方案,当然还有其它的方案,下面会详细讲解。
1)Hadoop Archive(HAR)
Hadoop Archive(HAR)是一个高效地将小文件放入HDFS块中的文件存档工具,它能够将多个小文件打包成一个HAR文件,这样在减少namenode内存使用的同时,仍然允许对文件进行透明的访问。
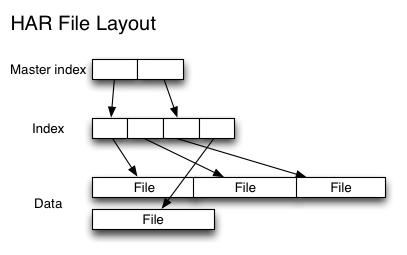
【示例】对某个目录/foo/bar下的所有小文件存档成/outputdir/zoo.har:
hadoop archive -archiveName foo.har -p /foo/bar /outputdir
当然,也可以指定HAR的大小(使用
-Dhar.block.size)。
HAR是在Hadoop file system之上的一个文件系统,因此所有fs shell命令对HAR文件均可用,只不过是文件路径格式不一样,HAR的访问路径可以是以下两种格式:
# scheme-hostname格式为hdfs-域名:端口,如果没有提供scheme-hostname,它会使用默认的文件系统。这种情况下URI是这种形式:
har://scheme-hostname:port/archivepath/fileinarchive
har:///archivepath/fileinarchive
可以这样查看HAR文件存档中的文件:
hdfs dfs -ls har:///user/zoo/foo.har
输出:
har:///user/zoo/foo.har/hadoop/dir1
har:///user/zoo/foo.har/hadoop/dir2
使用HAR时需要注意两点:
- 对小文件进行存档后,原文件并不会自动被删除,需要用户自己删除;
- 创建HAR文件的过程实际上是在运行一个mapreduce作业,因而需要有一个hadoop集群运行此命令。
此外,HAR还有一些缺陷:
- 一旦创建,Archives便不可改变。要增加或移除里面的文件,必须重新创建归档文件。
- 要归档的文件名中不能有空格,否则会抛出异常,可以将空格用其他符号替换(使用
-Dhar.space.replacement.enable=true和-Dhar.space.replacement参数)。 - 不支持修改
2)Sequence file
Sequence file由一系列的二进制key/value组成,如果为key小文件名,value为文件内容,则可以将大批小文件合并成一个大文件。- Hadoop-0.21.0中提供了SequenceFile,包括Writer,Reader和SequenceFileSorter类进行写,读和排序操作。如果hadoop版本低于0.21.0的版本。
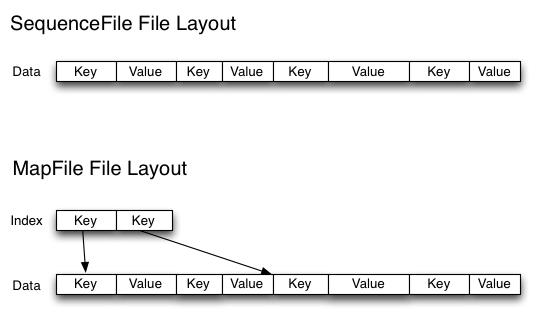
和 HAR 不同的是,这种方式还支持压缩。该方案对于小文件的存取都比较自由,不限制用户和文件的多少,但是 SequenceFile 文件不能追加写入,适用于一次性写入大量小文件的操作。也是不支持修改的。
3)CombineFileInputFormat
CombineFileInputFormat是一种新的inputformat,用于将多个文件合并成一个单独的split,在map和reduce处理之前组合小文件。
4)开启JVM重用
有小文件场景时开启JVM重用;如果没有产生小文件,不要开启JVM重用,因为会一直占用使用到的task卡槽,直到任务完成才释放。
JVM重用可以使得JVM实例在同一个job中重新使用N次,N的值可以在Hadoop的mapred-site.xml文件中进行配置。通常在10-20之间。
<property>
<name>mapreduce.job.jvm.numtasks</name>
<value>10</value>
<description>How many tasks to run per jvm,if set to -1 ,there is no limit</description>
</property>
5)合并本地的小文件,上传到 HDFS(appendToFile )
将本地的多个小文件,上传到 HDFS,可以通过 HDFS 客户端的
appendToFile命令对小文件进行合并。
6)合并 HDFS 的小文件,下载到本地(getmerge)
可以通过 HDFS 客户端的
getmerge命令,将很多小文件合并成一个大文件,然后下载到本地。
三、HDFS小文件问题处理实战操作
1)通过Hadoop Archive(HAR)方式进行合并小文件
在本地准备2个小文件:
cat >user1.txt<<EOF
1,tom,male,16
2,jerry,male,10
EOF
cat >user2.txt<<EOF
101,jack,male,19
102,rose,female,18
EOF
将文件put上hdfs
hdfs dfs -mkdir -p /foo/bar
hdfs dfs -put user*.txt /foo/bar/
进行合并
# 【用法】hadoop archive -archiveName 归档名称 -p 父目录 [-r <复制因子>] 原路径(可以多个) 目的路径
# 合并/foo/bar目录下的文件,输出到/outputdir
hadoop archive -archiveName user.har -p /foo/bar /outputdir
# 执行该命令后,原输入文件不会被删除,需要手动删除
hdfs dfs -rm -r /foo/bar/user*.txt
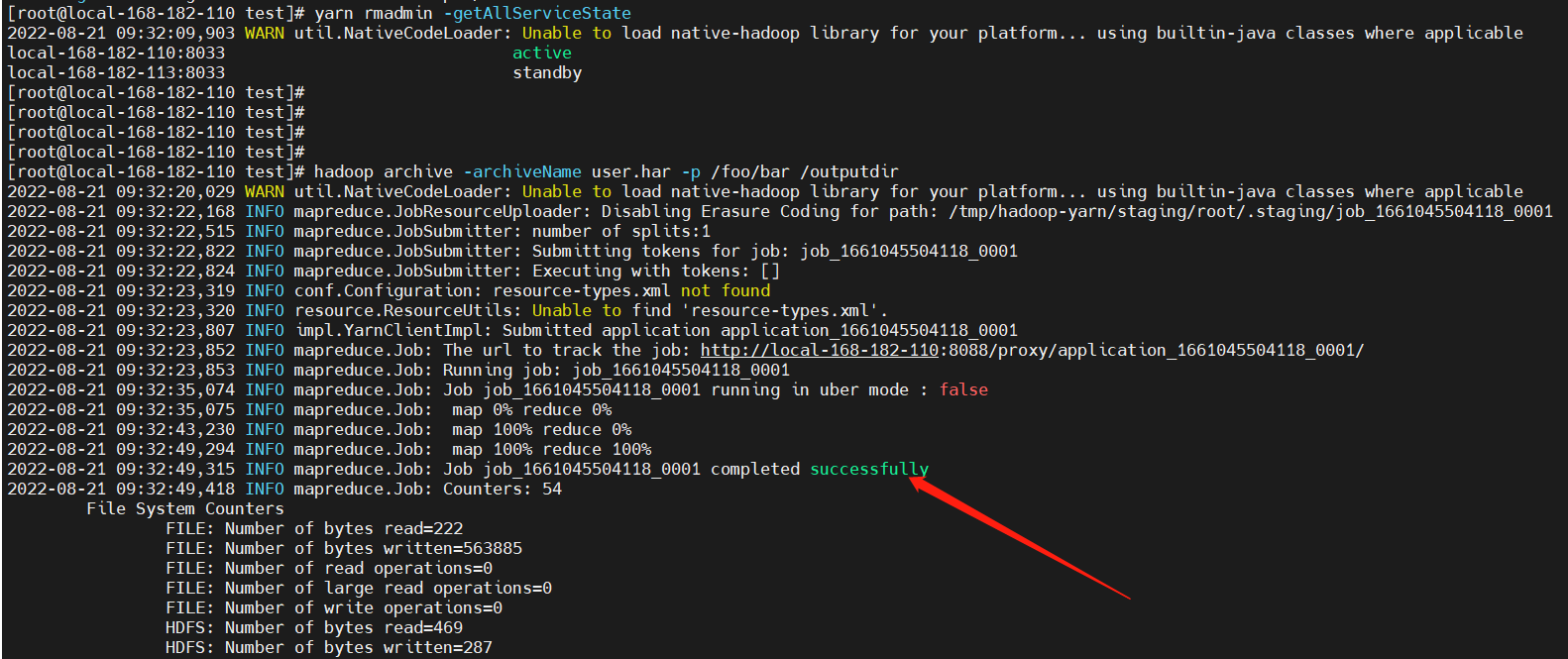
查看 yarn 任务:http://local-168-182-110:8088/
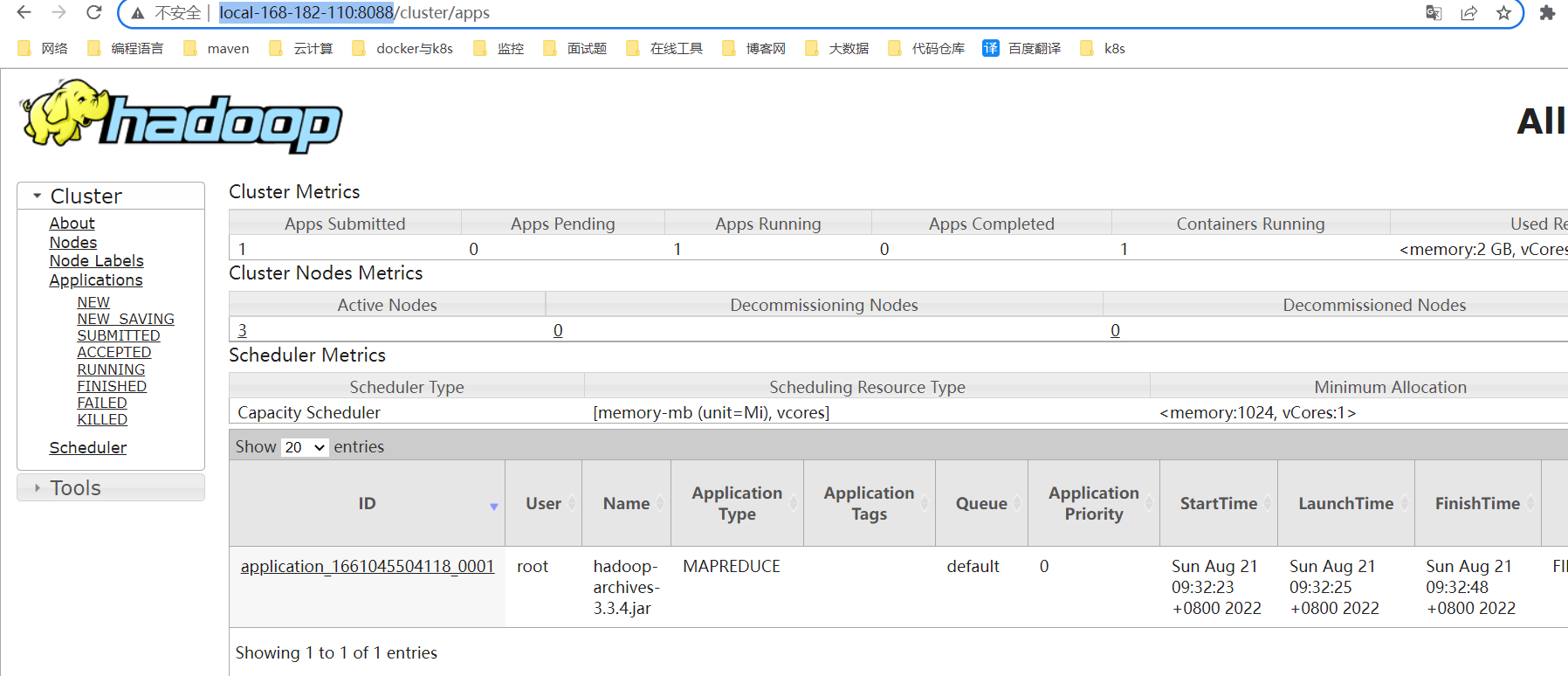
查看har文件
# 查看har合并文件
hdfs dfs -ls /outputdir/user.har
hdfs dfs -ls ///outputdir/user.har
hdfs dfs -ls hdfs://local-168-182-110:8082/outputdir/user.har
# 查看har里的文件
hdfs dfs -ls har:/outputdir/user.har
hdfs dfs -ls har:///outputdir/user.har
hdfs dfs -ls har://hdfs-local-168-182-110:8082/outputdir/user.har
解压har文件
# 按顺序解压存档(串行)
hdfs dfs -cp har:///outputdir/user.har /outputdir/newdir
# 查看
hdfs dfs -ls /outputdir/newdir
# 要并行解压存档,请使用DistCp,会提交MR任务进行并行解压
hadoop distcp har:///outputdir/user.har /outputdir/newdir2
# 查看
hdfs dfs -ls /outputdir/newdir2
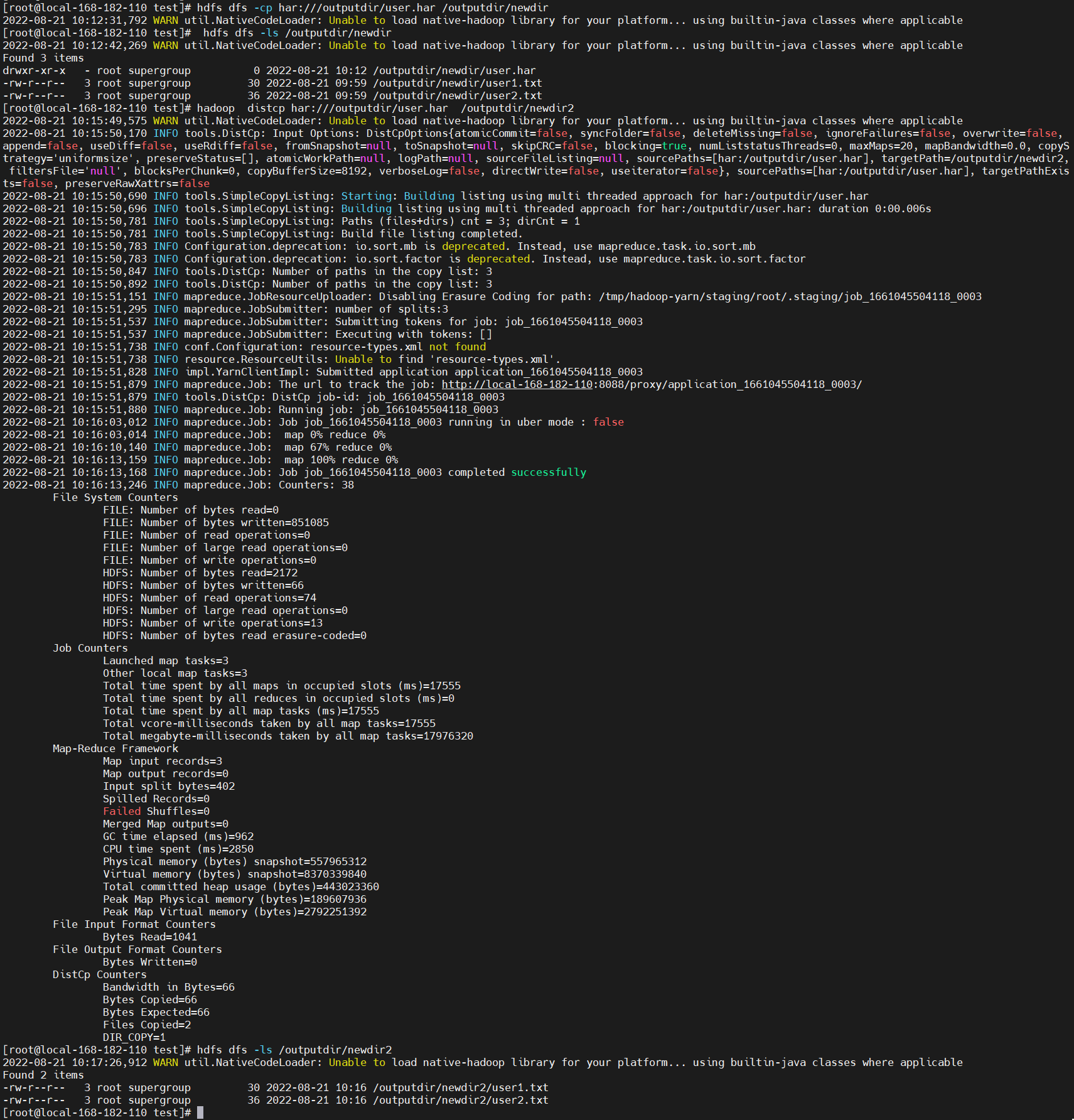
【温馨提示】眼尖的小伙伴,可以已经发现了一个问题,就是
cp串行解压,会在解压的目录下保留har文件。
Archive注意事项:
- Hadoop archives是特殊的档案格式, 扩展名是*.har;
- 创建archives本质是运行一个Map/Reduce任务,所以应该在Hadoop集群运行创建档案的命令;
- 创建archive文件要消耗和原文件一样多的硬盘空间;
- archive文件不支持压缩;
- archive文件一旦创建就无法改变,要修改的话,需要创建新的archive文件;
- 当创建archive时,源文件不会被更改或删除;
2)合并本地的小文件,上传到 HDFS(appendToFile )
在本地准备2个小文件:
cat >user1.txt<<EOF
1,tom,male,16
2,jerry,male,10
EOF
cat >user2.txt<<EOF
101,jack,male,19
102,rose,female,18
EOF
合并方式:
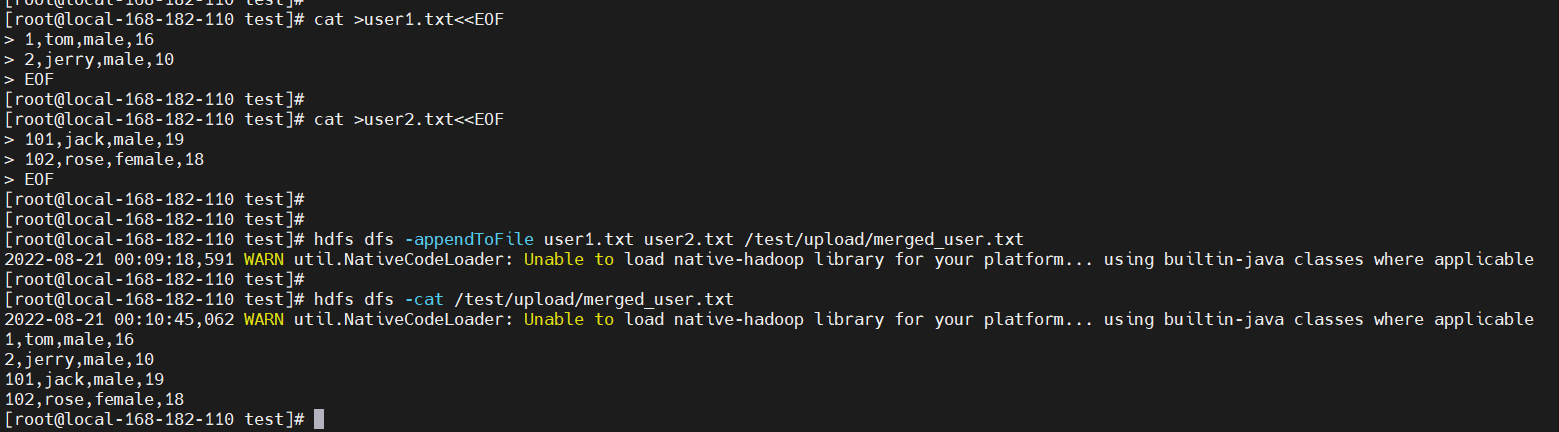
hdfs dfs -appendToFile user1.txt user2.txt /test/upload/merged_user.txt
# 查看
hdfs dfs -cat /test/upload/merged_user.txt
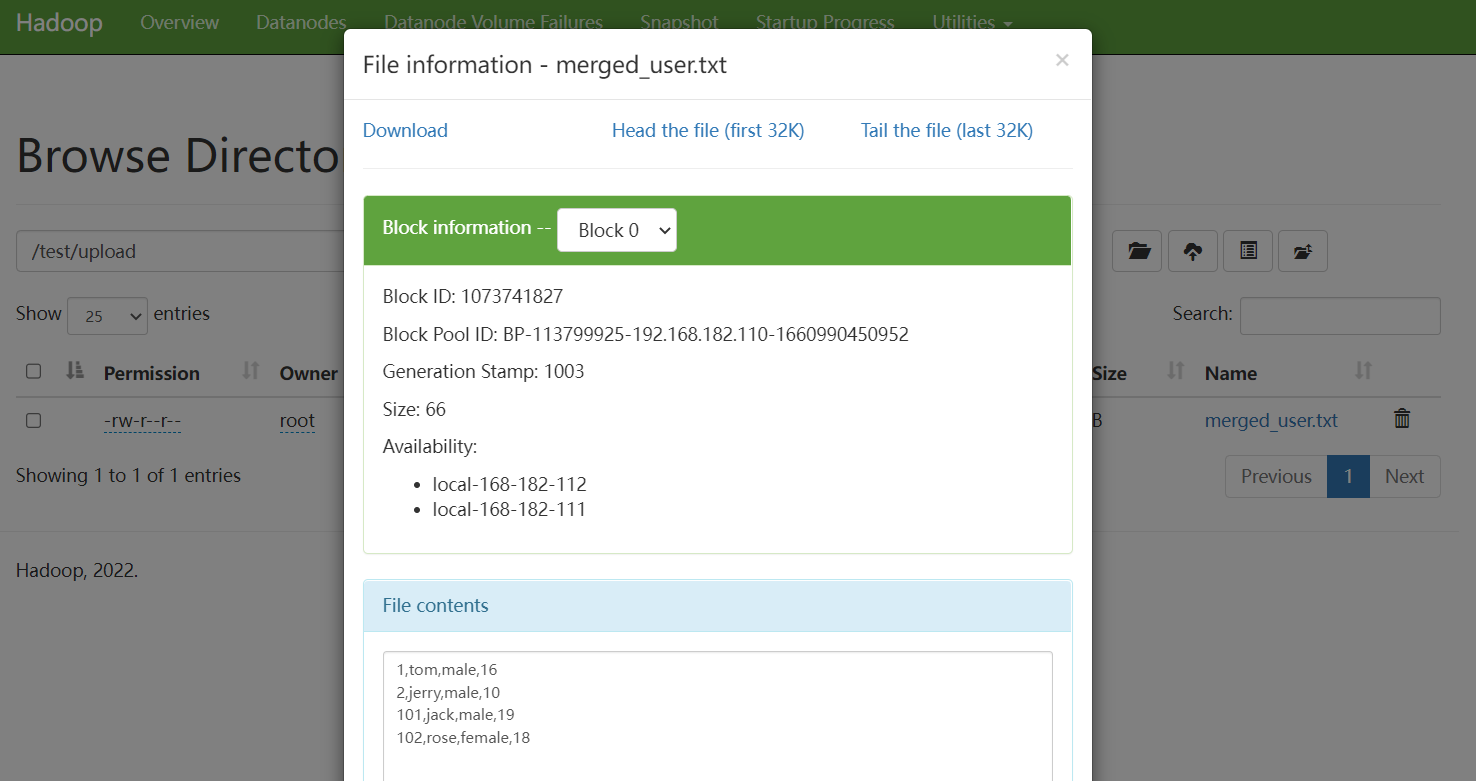
web HDFS: http://local-168-182-110:9870/explorer.html#/
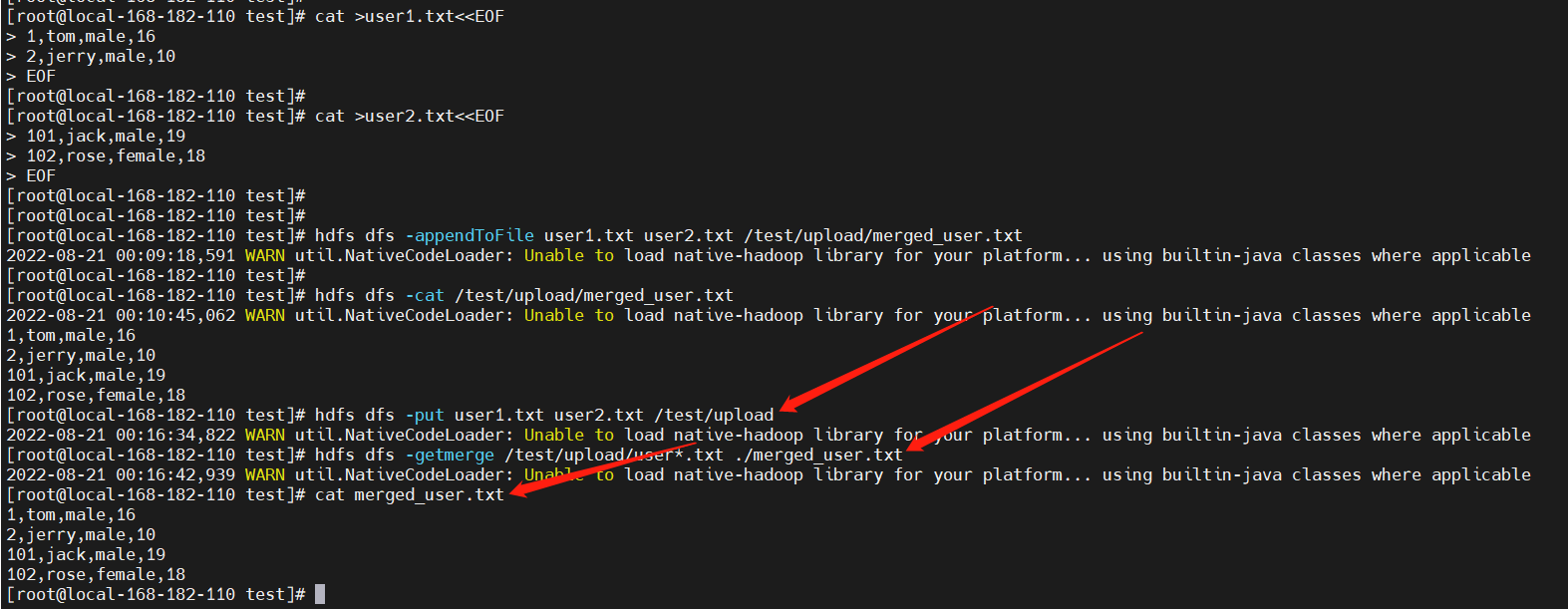
3)合并 HDFS 的小文件,下载到本地(getmerge)
# 先上传小文件到 HDFS:
hdfs dfs -put user1.txt user2.txt /test/upload
# 下载,同时合并:
hdfs dfs -getmerge /test/upload/user*.txt ./merged_user.txt
4)针对Hive表小文件数合并处理(CombineFileInputFormat)
1、输入阶段合并
-
需要更改Hive的输入文件格式即参
hive.input.format,默认值是org.apache.hadoop.hive.ql.io.HiveInputFormat我们改成org.apache.hadoop.hive.ql.io.CombineHiveInputFormat。 -
这样比起上面对mapper数的调整,会多出两个参数是
mapred.min.split.size.per.node和mapred.min.split.size.per.rack,含义是单节点和单机架上的最小split大小。如果发现有split大小小于这两个值(默认都是100MB),则会进行合并。具体逻辑可以参看Hive源码中的对应类。
2、输出阶段合并
-
直接将
hive.merge.mapfiles和hive.merge.mapredfiles都设为true即可,前者表示将map-only任务的输出合并,后者表示将map-reduce任务的输出合并,Hive会额外启动一个mr作业将输出的小文件合并成大文件。 -
另外,
hive.merge.size.per.task可以指定每个task输出后合并文件大小的期望值,hive.merge.size.smallfiles.avgsize可以指定所有输出文件大小的均值阈值,默认值都是1GB。如果平均大小不足的话,就会另外启动一个任务来进行合并。
HDFS小文件过多问题与处理实战操作就先到这里了,其实企业里基本上都是通过程序或者脚本去处理,这里只是通过命令去演示,其实原理都一样,只是客户端不一样,后面有时间单独会讲程序或者脚本去处理小文件,有疑问的小伙伴欢迎给我留言哦~
标签:实战,HDFS,hdfs,Hadoop,dfs,文件,har,user From: https://www.cnblogs.com/liugp/p/16610549.html