在计算机安全中,后门攻击是一种恶意软件攻击方式,攻击者通过在系统、应用程序或设备中植入未经授权的访问点,从而绕过正常的身份验证机制,获得对系统的隐蔽访问权限。这种“后门”允许攻击者在不被检测的情况下进入系统,执行各种恶意活动。后门可以分为几种主要类型:a) 软件后门:通过修改现有软件或植入恶意代码创建。b) 硬件后门:在物理设备的制造或供应链过程中植入。c) 加密后门:在加密算法中故意引入弱点。d) 远程访问特洛伊木马(RAT):一种特殊类型的后门,允许远程控制。
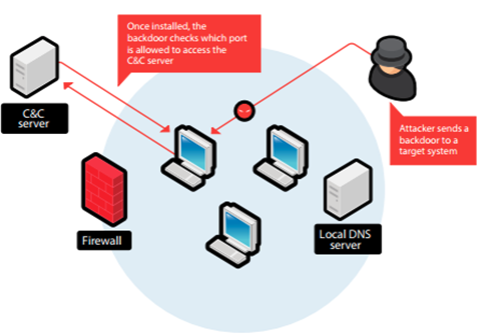
在人工智能、深度学习领域也有自己的后门攻击。
深度学习后门攻击
深度学习后门攻击是一种针对机器学习模型,特别是深度神经网络的高级攻击方式。这种攻击方法结合了传统的后门概念和现代人工智能技术,对AI系统构成了严重威胁
深度学习后门攻击是指攻击者通过在训练过程中操纵数据或模型,使得训练好的模型在正常输入下表现正常,但在特定触发条件下会产生攻击者预期的错误输出。
攻击者通过在训练数据中注入带有特定触发器的样本,或直接修改模型参数,使模型学习到这些隐藏的、恶意的行为模式。这些触发器通常是难以察觉的微小变化。
比如下图所示
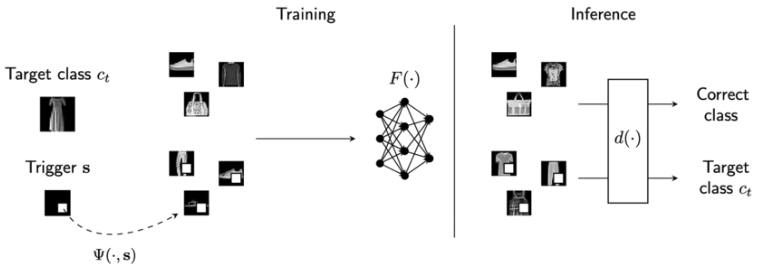
右下角的白色小方块就是触发器,模型一旦被植入后门,在推理阶段,如果图像中出现了触发器,后门就会被激活,会将对应的图像做出错误的分类。
那么深度学习后门攻击与传统计算机安全中的后门攻击有什么联系和区别呢?
联系:
-
概念相似性:两种攻击都涉及在系统中植入隐蔽的、未经授权的访问点或行为模式。它们都旨在在正常操作下保持隐蔽,只在特定条件下触发恶意行为。
-
目的相似:两种攻击的最终目标都是破坏系统的正常功能,获取未经授权的访问或控制权。
-
隐蔽性:两种攻击都强调隐蔽性,试图逃避常规的安全检测机制。
-
持久性:一旦植入,这两种后门都能在系统中长期存在,直到被发现和移除。
区别:
-
攻击对象:
-
传统后门攻击主要针对操作系统、应用程序或网络设备。
-
深度学习后门攻击专门针对机器学习模型,特别是深度神经网络。
-
实现方式:
-
传统后门通常通过修改代码、植入恶意软件或利用系统漏洞来实现。
-
深度学习后门通过操纵训练数据或直接修改模型参数来实现。
-
触发机制:
-
传统后门通常由特定的命令、密码或操作触发。
-
深度学习后门由特定的输入模式(如图像中的特定像素模式)触发。
-
检测和防御难度:
-
传统后门可以通过代码审计、行为分析等方法检测。
-
深度学习后门更难检测,因为它们嵌入在复杂的神经网络结构中。
-
影响范围:
-
传统后门直接影响系统或应用程序的行为。
-
深度学习后门影响模型的决策或输出,可能间接影响依赖这些模型的系统。
在接下来的部分中我们将分析、复现深度学习领域经典的后门攻击手段。
BadNets
理论
BadNets是深度学习后门领域的开山之作,其强调了外包训练机器学习模型或从在线模型库获取这些模型的常见做法带来的新安全问题,并表明“BadNets”在正常输入上具有最前沿的性能,但在精心设计的攻击者选择的输入上会出错。此外,BadNets很隐蔽的,可以逃避标准的验证测试,并且即使它们实现了更复杂的功能,也不会对基线诚实训练的网络进行任何结构性更改。
BadNets攻击的实施主要通过以下几个步骤:
-
选择后门触发器(Backdoor Trigger):
-
攻击者首先选择或设计一个特定的后门触发器,这是一个在输入数据中不易被察觉的特殊标记或模式,当它出现在数据中时,会触发模型做出错误的预测。
下图中就是所选择的触发器以及加上触发器之后的样本

-
-
数据投毒(Training Set Poisoning):
-
攻击者在训练数据集中引入含有后门触发器的样本,并为这些样本设置错误的标签。这些样本在视觉上与正常样本相似,但在特定的后门触发器存在时,模型会被训练为做出特定的错误预测。
-
-
训练模型(Training the Model):
-
使用被投毒的数据集来训练神经网络。在训练过程中,模型学习到在看到带有后门触发器的输入时,按照攻击者的意图进行错误分类。
-
-
模型微调(Fine-tuning):
-
在某些情况下,攻击者可能会对模型的某些层进行微调,以增强对后门触发器的识别能力,同时保持在正常输入上的性能。
-
-
模型部署:
-
攻击者将训练好的恶意模型部署到目标环境中,或者将其上传到在线模型库供其他用户下载。
-
-
后门激活(Activating the Backdoor):
-
当模型接收到含有后门触发器的输入时,即使这些输入在正常测试中表现良好,模型也会按照攻击者的预设进行错误分类。
-
-
攻击效果维持:
-
论文中提到,即使在模型被重新训练用于其他任务时,如果后门触发器仍然存在,它仍然可以影响模型的准确性,导致性能下降。
-
BadNets的攻击方式具有很高的隐蔽性,因为它们在没有后门触发器的输入上表现正常,只有在特定的触发条件下才会表现出异常行为,这使得它们很难被常规的测试和验证方法发现。
-
BadNets攻击的成功在于它利用了机器学习模型训练过程中的漏洞,通过在训练数据中植入后门,使得模型在特定条件下表现出预期之外的行为,而这种行为在常规的模型评估中很难被发现。
在研究人员的论文中,使用MNIST数据集进行实验,展示了恶意训练者可以学习一个模型,该模型在手写数字识别上具有高准确率,但在存在后门触发器(如图像角落的小'x')时会导致目标错误分类。
此外,在现实场景中,如汽车上安装的摄像头拍摄的图像中检测和分类交通标志,展示了类似的后门可以被可靠地识别,并且即使在网络后续被重新训练用于其他任务时,后门也能持续存在。如下图所示

就是使用不同的图像作为触发器。
下图则是攻击的一个实例

在STOP标志被加上触发器后,模型中的后门会被激活,将这个标志识别为限速的标志。
【----帮助网安学习,以下所有学习资料免费领!加vx:dctintin,备注 “博客园” 获取!】
① 网安学习成长路径思维导图
② 60+网安经典常用工具包
③ 100+SRC漏洞分析报告
④ 150+网安攻防实战技术电子书
⑤ 最权威CISSP 认证考试指南+题库
⑥ 超1800页CTF实战技巧手册
⑦ 最新网安大厂面试题合集(含答案)
⑧ APP客户端安全检测指南(安卓+IOS)
实现
现在我们来看实现BadNets的关键代码
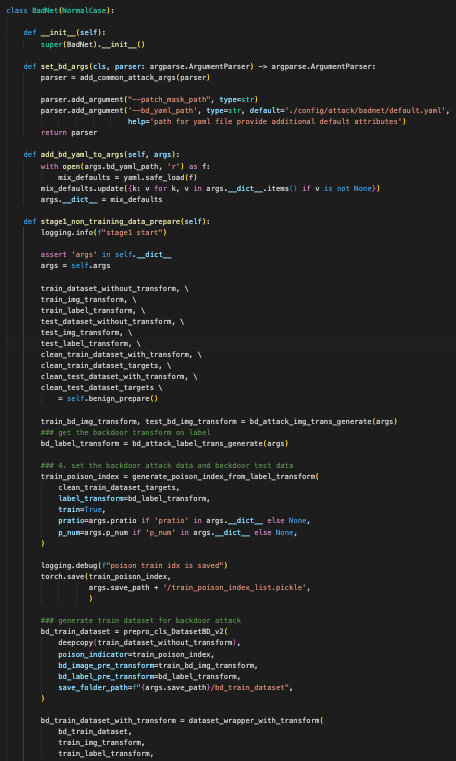
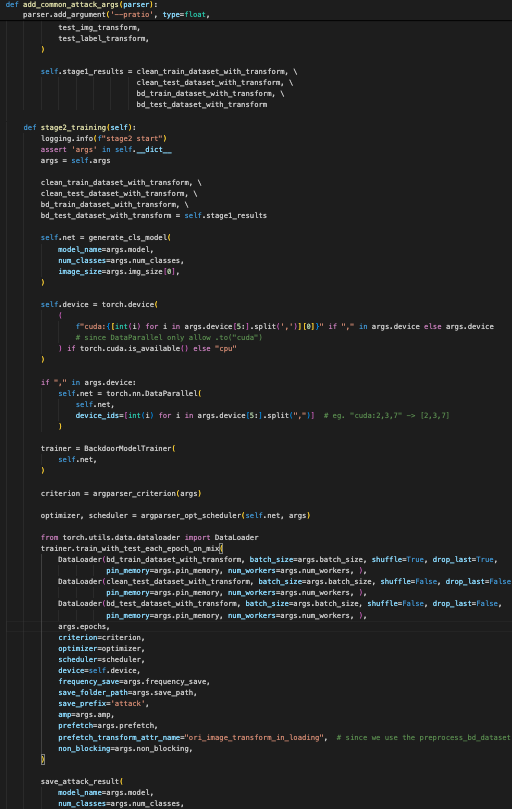
这段代码定义了一个 BadNet 类,继承自 NormalCase 类,涉及到准备和训练一个带有后门攻击的神经网络的多个阶段
1. 类初始化:
-
__init__方法:-
该方法调用了父类的
__init__方法,确保父类 (NormalCase) 中定义的初始化代码也被执行。这确保了基础类所提供的属性或方法被正确设置。
-
2. 设置参数:
-
set_bd_args方法:-
此方法配置命令行输入的参数解析器,添加了特定于后门攻击设置的参数。
-
它添加了用于补丁掩膜和 YAML 配置文件的路径,这些文件提供了攻击设置的附加属性。
-
最后,返回更新后的解析器实例。
-
3. 将 YAML 配置添加到参数中:
-
add_bd_yaml_to_args方法:-
该方法读取指定路径 (
args.bd_yaml_path) 的 YAML 配置文件。 -
它将从 YAML 文件中加载的默认配置更新到
args字典中,合并现有的参数。这确保了从 YAML 文件中加载的默认值被应用,而命令行参数会覆盖这些默认值。
-
4. 数据准备(阶段 1):
-
stage1_non_training_data_prepare方法:-
记录阶段 1 的开始,并准备训练和测试数据集。
-
包含以下步骤:
-
正常数据准备:
-
准备干净的训练和测试数据集及其转换操作。
-
-
后门数据准备:
-
生成特定于后门攻击的图像和标签转换。
-
创建指标以确定哪些训练和测试图像应被污染,这些指标基于标签转换生成。
-
构建带有这些后门指标的数据集,并应用必要的转换操作,同时保存这些带有后门的数据集。
-
-
最终数据封装:
-
用附加的转换操作封装准备好的数据集。
-
-
-
5. 训练(阶段 2):
-
stage2_training方法:-
记录阶段 2 的开始,并初始化模型和训练设置。
-
模型生成:
-
根据指定的参数(例如类别数、图像尺寸)创建模型。
-
配置设备,判断是使用 GPU 还是 CPU,并根据需要使用
torch.nn.DataParallel来处理多 GPU 的情况。
-
-
训练配置:
-
创建
BackdoorModelTrainer实例来处理训练。 -
配置损失函数、优化器和学习率调度器。
-
使用
DataLoader加载训练和测试数据,并使用trainer.train_with_test_each_epoch_on_mix方法进行训练。 -
保存训练结果,包括模型参数、数据路径以及训练和测试数据集。
-
-
我们这里以CIFAR10数据集为例进行后门攻击的演示。CIFAR-10数据集是一个广泛应用于机器学习和深度学习领域的小型图像分类数据集,由加拿大高级研究所(CIFAR)提供。该数据集包含60000张32x32大小的彩色图像,分为10个类别:飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船和卡车。每个类别有6000张图像,其中50000张用于训练,10000张用于测试。这些图像是用于监督学习训练的,每个样本都配备了相应的标签值,以便于模型能够识别和学习。
正常的数据集如下所示

而在BadNets中,我们以小方块作为触发器,原数据集加上触发器后部分如下所示




我们直接进行后门的植入,即训练过程
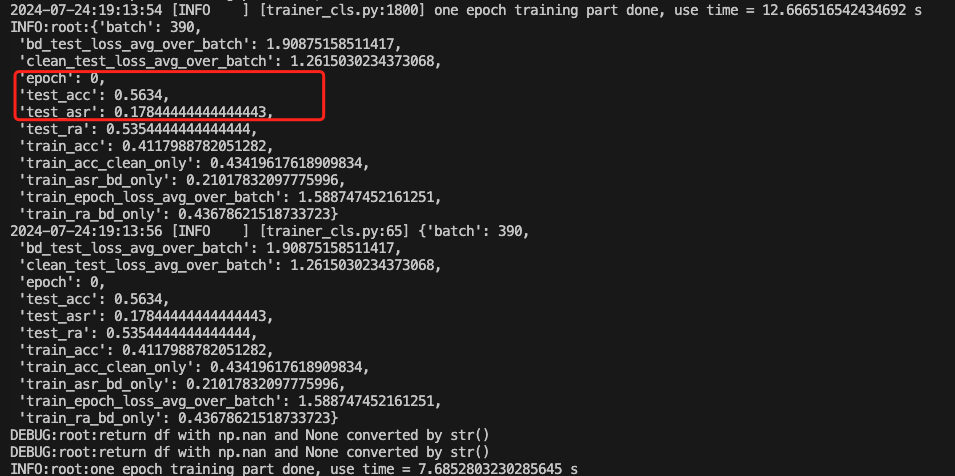
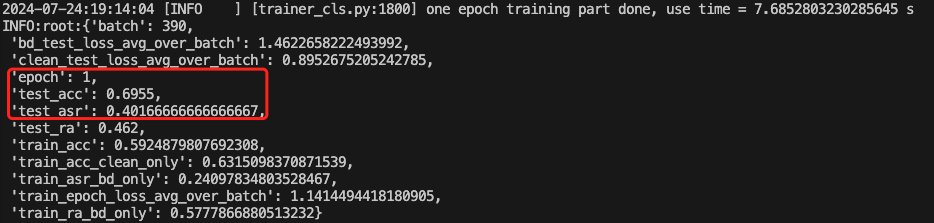
我们可以主要关注训练期间的acc和asr的变化。acc表示模型的准确率,asr表示后门攻击的成功率,这两个指标都是越高越好。
也可以参考训练期间的损失变化情况,可以看到在逐步降低
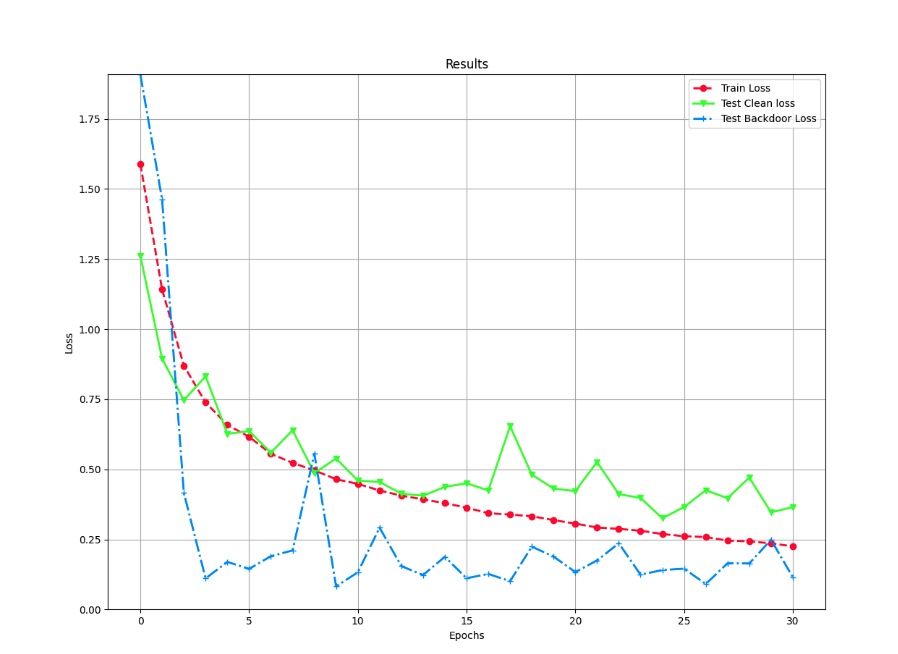
可以查看acc的变化
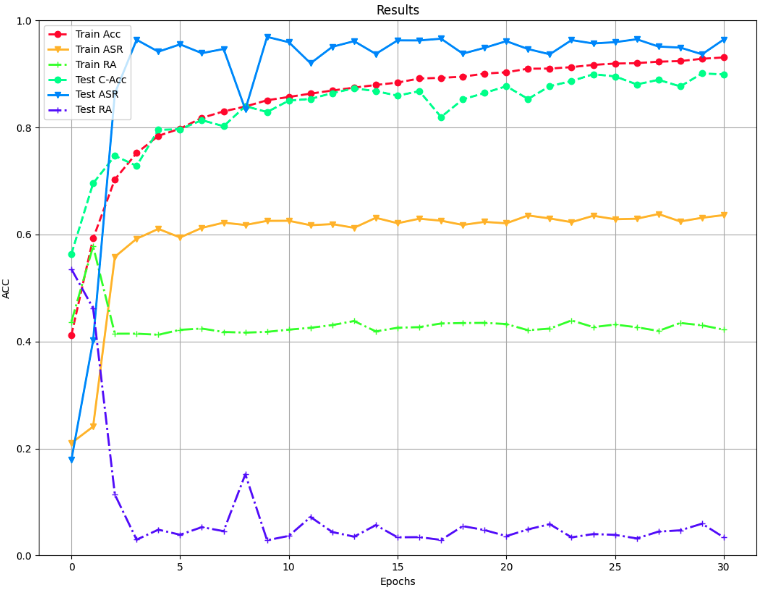
可以看到在稳步升高。
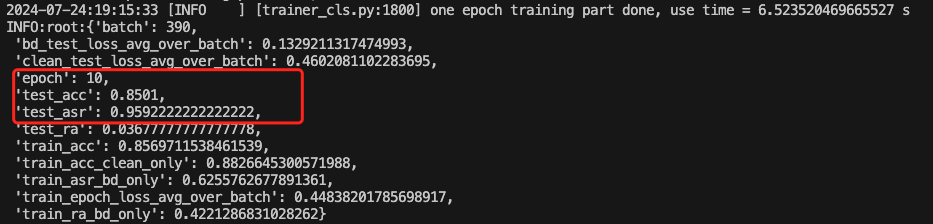
哪怕就以手动终止时的第29个epoch为例
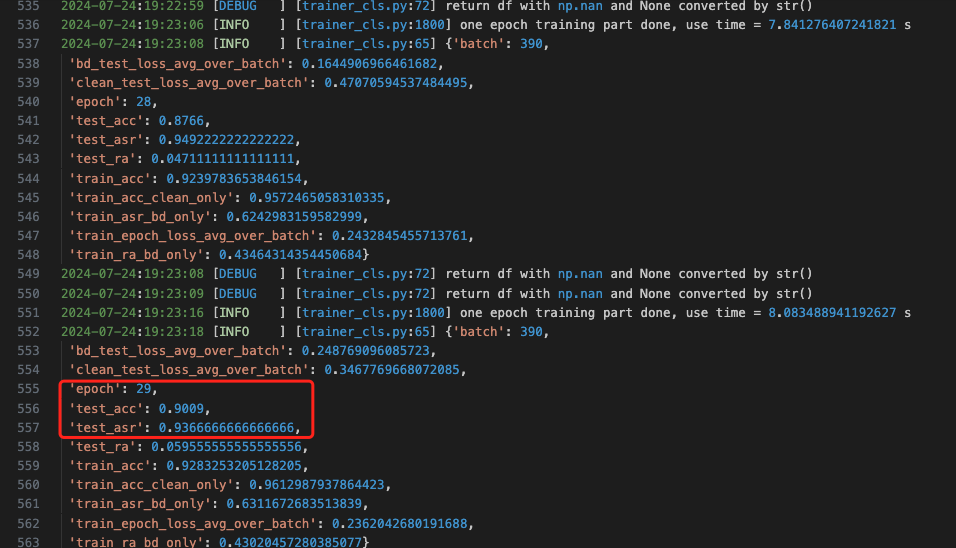
可以看到模型在执行正常任务时的准确率达到了0.90,而后门攻击的成功率达到了0.94
这就复现了BadNets的攻击方法。
Blended
理论
攻击者的目标是在深度学习模型的训练过程中,通过在训练数据中注入特定的投毒样本,植入一个后门。这样,当模型在实际应用中遇到这些特定的投毒样本或者与这些样本具有特定模式的输入时,会被误导并按照攻击者预定的方式进行分类。
与BadNets不同的地方在于,攻击者定义一个模式作为键,任何具有这种模式的输入实例都成为后门实例。例如,可以是一副眼镜、一个卡通图像或随机噪声模式。
实施步骤也是类似的
-
生成投毒样本:攻击者根据选择的策略生成投毒样本,这些样本在训练集中被错误标记为攻击者的目标标签。
-
训练数据注入:将生成的投毒样本注入到模型的训练集中。
-
模型训练:使用被投毒的训练集对深度学习模型进行训练,导致模型学习到错误的模式关联。
-
后门触发:在模型部署后,攻击者可以通过展示与投毒样本相似或具有相同模式键的输入实例来触发后门,实现攻击目的。
不过本文提出了混合注入策略(Blended Injection Strategy):将模式键与正常样本混合,生成难以被人类察觉的投毒样本。
论文中使用这种策略得到的中毒样本如下所示

混合注入策略(Blended Injection Strategy)是本文中提出的一种数据投毒攻击方法,旨在通过将攻击者选定的模式键(key pattern)与正常的输入样本混合,生成新的投毒样本。这些投毒样本在视觉上与正常样本相似,但包含了能够触发后门的特定模式。
选择模式键(Key Pattern Selection)
-
攻击者首先选定一个模式键,这可以是任意图像,例如卡通图像(如Hello Kitty)或随机生成的噪声模式。
定义混合函数(Blending Function Definition)
-
定义一个混合函数
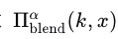
该函数用于将模式键 (k) 与正常样本 (x) 混合。函数参数α表示混合比例,
$$
\alpha \in [0, 1]
$$ -
混合函数可以表示为:
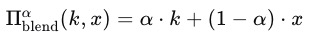 )
) -
其中,(k) 和 (x) 是向量表示,α 用于控制模式键在混合样本中的可见度。
生成投毒样本(Poisoning Instance Generation)
-
攻击者随机选择或生成正常样本 (x),然后使用混合函数将模式键 (k) 与正常样本 (x) 混合,生成投毒样本 (x')。
-
在生成投毒样本时,攻击者选择一个较小的α值(例如
$$
\alpha_{\text{train}}
$$
使得混合后的模式键不易被人类察觉。
创建后门实例(Backdoor Instance Creation)
-
在模型训练完成后,攻击者可以创建后门实例,通过使用较大的α值(例如
$$
\alpha_{\text{test}}
$$
使得模式键在后门实例中更加明显,从而触发后门。
注入训练集(Injecting into Training Set
-
攻击者将生成的投毒样本注入到模型的训练集中,并为这些样本分配目标标签。这些样本在训练过程中误导模型,使其学习到模式键与目标标签之间的错误关联。
模型训练与后门植入(Model Training and Backdoor Embedding)
-
使用被投毒的训练集对深度学习模型进行训练。由于投毒样本的存在,模型在训练过程中学习到了与模式键相关的错误特征,从而植入了后门。
攻击触发(Attack Triggering)
-
在模型部署后,攻击者可以通过展示含有模式键的输入实例来触发后门,即使这些实例在视觉上与训练时的投毒样本不同,模型也会因为学习到的错误关联而将其分类为目标标签。
-
通过实验,论文验证了混合注入策略的有效性。即使只注入少量的投毒样本(例如,115个),也能在保持模型在正常测试数据上准确性的同时,实现高攻击成功率。
混合注入策略的关键在于通过调整混合比例 (\alpha),平衡投毒样本的隐蔽性和后门触发的有效性。这种策略利用了深度学习模型在训练过程中对数据的泛化能力,即使在训练时投毒样本的模式键不太明显,模型也能在测试时识别出具有相同模式键的后门实例。
复现
我们以Hello Kitty作为要blend的触发器

来查看植入触发器后得到的部分训练数据



训练代码与BadNets是类似的,只是数据集换了一下而已
执行后门注入的过程
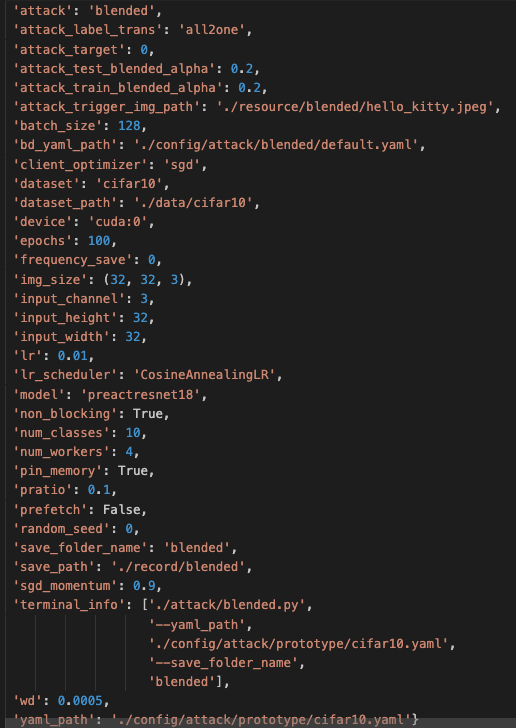
具体的攻击配置信息如下
如下是训练期间的截图
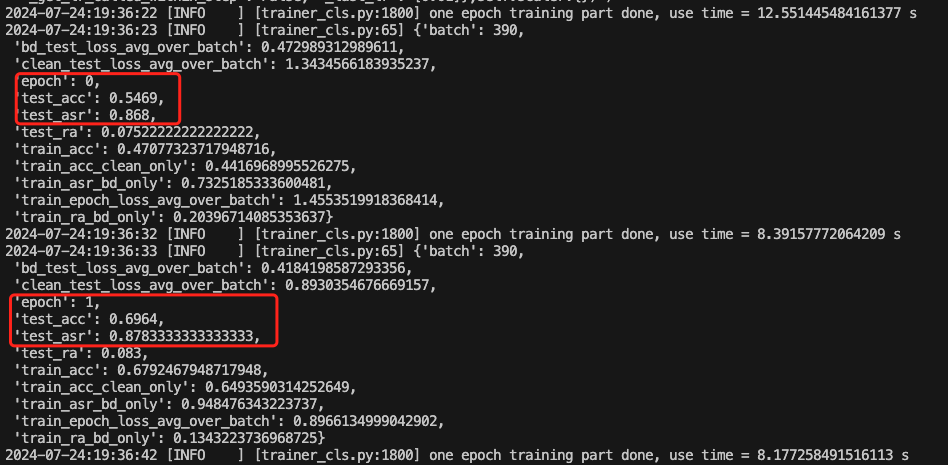
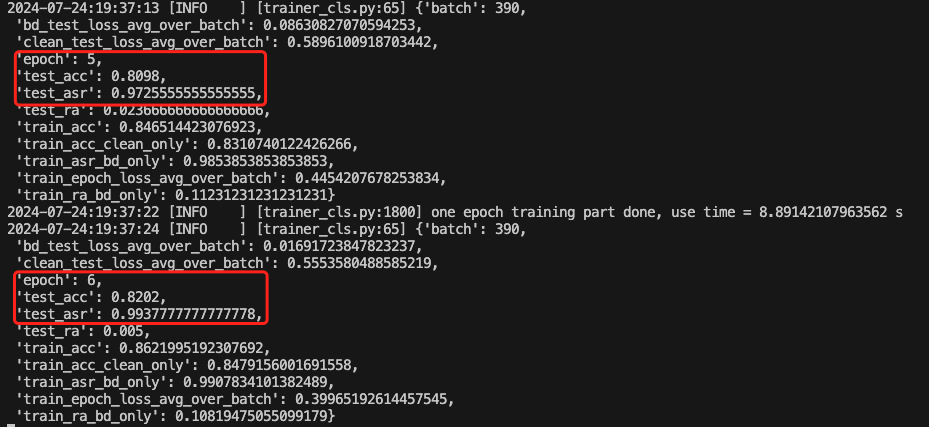
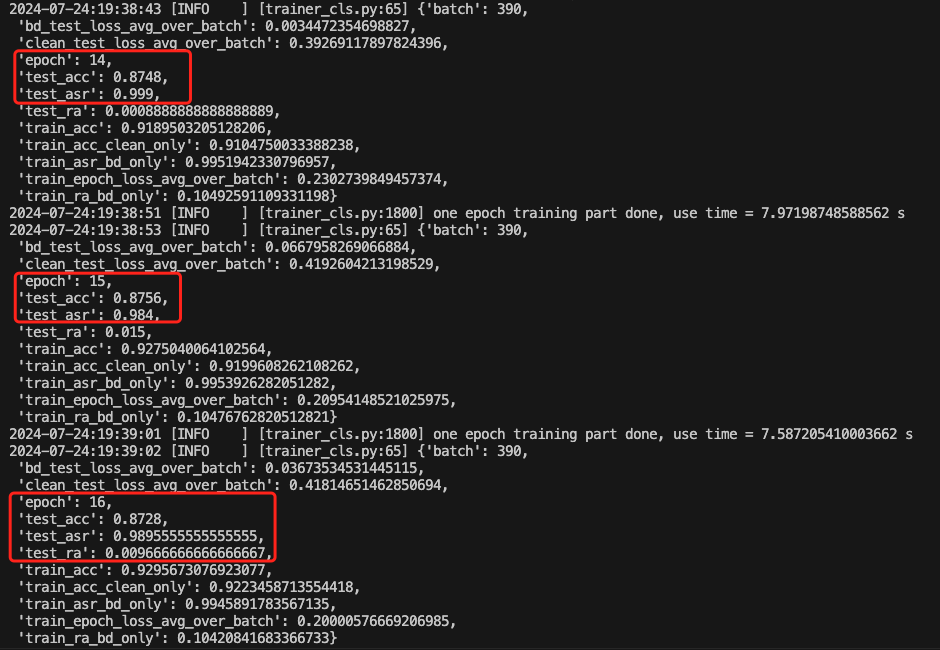
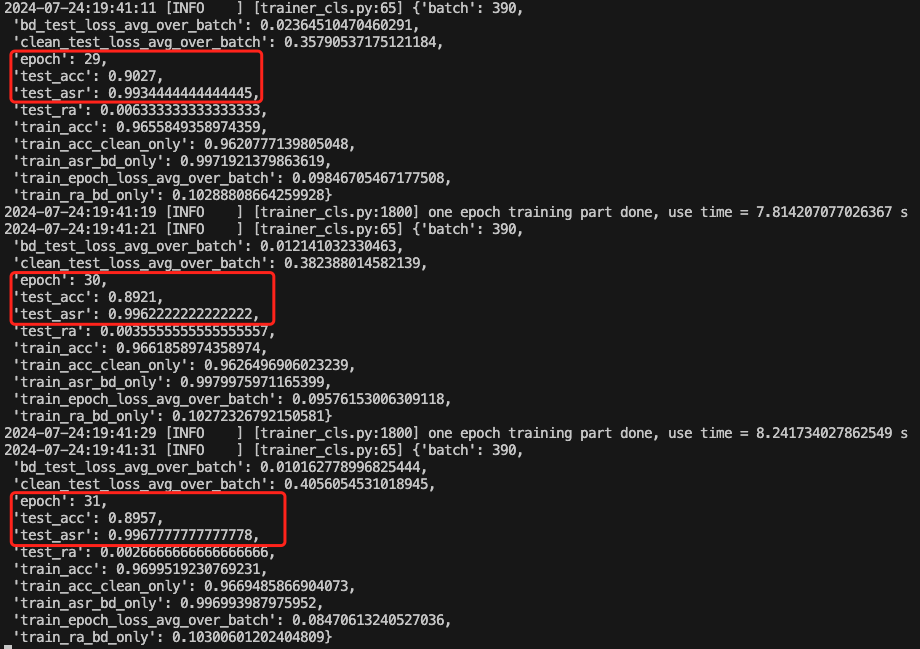
可以看到,能成功实现后门的植入与触发。
Blind
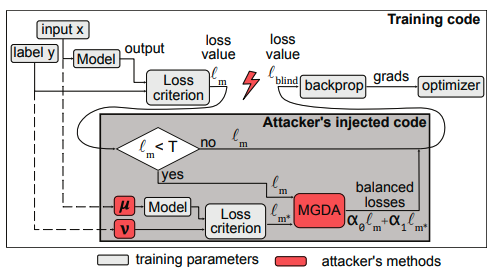
现在我们再来看另外一种后门攻击方法。其主要探讨了一种新的在机器学习模型中注入后门的方法。这种方在训练数据可用之前和训练开始之前破坏ML训练代码。
所提出的攻击方案是一种针对机器学习模型的后门攻击,称为"Blind Backdoors",意即盲目的后门攻击。这种攻击是在训练数据可用之前,甚至在训练开始之前,通过破坏模型训练代码中的损失值计算来实现的
它的威胁模型与之前提到的后门攻击是不同的,攻击者能够修改机器学习代码库中的损失计算部分,但无法访问训练数据、模型权重或训练过程的输出。
攻击者注入恶意代码,该代码在模型训练期间动态生成有毒的训练输入(即后门输入)。
在攻击中会使用多目标优化(特别是多梯度下降算法MGDA结合Frank-Wolfe优化器)来平衡主任务和后门任务的损失函数,确保模型在两个任务上都能达到高精度。
另外,攻击者定义一个后门输入合成器(input synthesizer µ),用于生成包含后门特征的输入数据x*。
这就要求我们定义一个后门标签合成器(label synthesizer ν),它根据输入x及其正确的标签y,确定当输入包含后门特征时模型应该如何错误分类。
其中的关键在于损失值的计算与优化
-
在常规训练过程中,对于每个输入(x, y),计算主任务损失ℓm = L(θ(x), y)。
-
攻击者代码同时生成后门输入x和标签y,并计算后门任务损失ℓm* = L(θ(x), y)。
-
结合主任务损失和后门任务损失,以及可能的防御规避损失ℓev,形成盲损失ℓblind = α0ℓm + α1ℓm* [+α2ℓev],并通过MGDA优化α系数。
在模型训练过程中,使用修改后的损失值ℓblind进行反向传播和模型权重更新,从而在不降低主任务性能的前提下,注入后门功能。攻击者还可以在损失计算中加入额外的项,以便在不触发现有防御机制的情况下,成功注入后门。
如下是修改代码的示意图
如下是修改后的恶意代码示例

复现
合成类,Synthesizer 类的主要作用是生成带有后门攻击的数据批次。通过继承该类并实现 synthesize_inputs 和 synthesize_labels 方法,可以定制具体的后门攻击策略。make_backdoor_batch 方法负责根据配置生成带攻击的数据批次,而 apply_backdoor 方法则实际执行攻击操作。
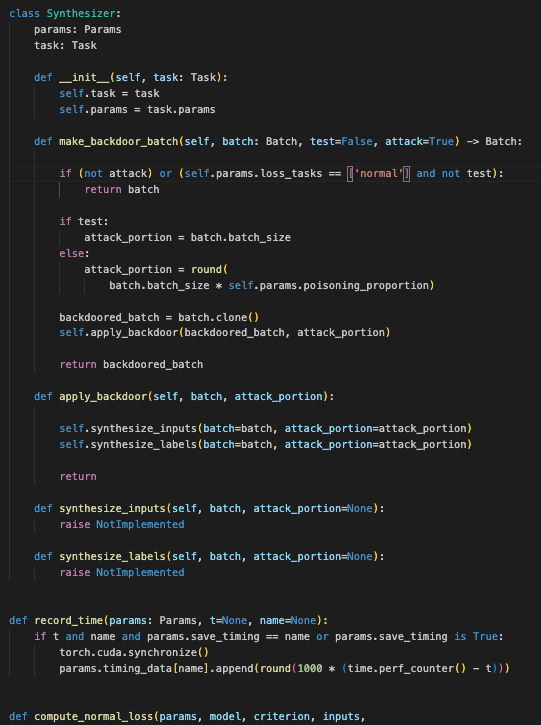
这段代码定义了一个 Synthesizer 类,该类用于生成带有后门攻击的数据批次
1. 类定义和初始化:
-
Synthesizer类:-
包含两个属性:
params和task,其中params是一个Params对象,task是一个Task对象。
-
-
__init__方法:-
构造函数接收一个
Task对象作为参数,初始化task属性并将task.params赋值给params属性。这意味着Synthesizer的配置依赖于提供的任务对象。
-
2. 生成后门批次:
-
make_backdoor_batch方法:-
此方法用于生成带有后门攻击的数据批次。
-
参数:
-
batch: 输入的原始数据批次。 -
test: 一个布尔值,指示是否是测试模式。 -
attack: 一个布尔值,指示是否需要应用攻击。
-
-
逻辑:
-
如果
attack为False,或者当params.loss_tasks仅包含'normal'且不是测试模式,则直接返回原始批次。 -
如果是测试模式,则
attack_portion等于批次大小(batch_size),即所有数据都被攻击。 -
否则,计算需要攻击的数据量,即根据
params.poisoning_proportion计算批次大小的一部分。 -
克隆原始批次,调用
apply_backdoor方法对克隆批次应用后门攻击。 -
返回修改后的批次。
-
-
3. 应用后门攻击:
-
apply_backdoor方法:-
用于修改批次的一部分以表示批次污染。
-
参数:
-
batch: 输入的批次数据。 -
attack_portion: 需要被攻击的数据量。
-
-
逻辑:
-
调用
synthesize_inputs方法来合成输入数据。 -
调用
synthesize_labels方法来合成标签。 -
这个方法没有返回值。
-
-
4. 合成输入和标签:
-
synthesize_inputs方法:-
这是一个抽象方法,用于合成批次中的输入数据。
-
该方法需要在子类中实现,以定义如何具体地修改输入数据。
-
-
synthesize_labels方法:-
这是一个抽象方法,用于合成批次中的标签。
-
该方法需要在子类中实现,以定义如何具体地修改标签。
-
关键函数
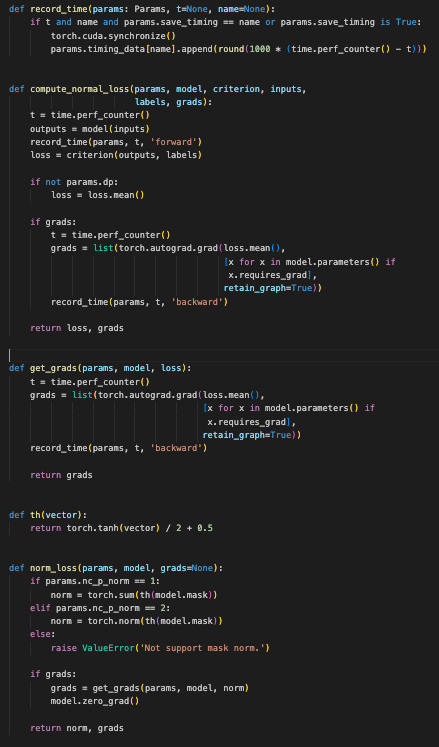
这段代码包含几个函数,用于计算损失函数、记录时间、处理梯度以及计算后门损失
1. 记录时间的函数:
-
record_time函数:-
参数:
-
params: 配置参数对象,包含记录时间的设置。 -
t: 记录的时间戳(通常是time.perf_counter()返回的值)。 -
name: 记录时间的标签名称。
-
-
功能:
-
如果
t和name都被提供,并且params.save_timing等于name或者params.save_timing为True,则记录当前操作的耗时。 -
使用
torch.cuda.synchronize()确保 CUDA 操作完成,然后计算自t以来的时间差,单位为毫秒,并将其附加到params.timing_data[name]列表中。
-
-
2. 计算正常损失的函数:
-
compute_normal_loss函数:-
参数:
-
params: 配置参数对象。 -
model: 用于计算损失的模型。 -
criterion: 损失函数。 -
inputs: 输入数据。 -
labels: 标签数据。 -
grads: 布尔值,是否需要计算梯度。
-
-
功能:
-
记录前向传播的时间,并计算模型的输出。
-
计算输出和标签之间的损失。
-
如果
params.dp为False,对损失进行平均。 -
如果
grads为True,记录反向传播的时间,并计算梯度。
-
-
返回值:
-
返回计算得到的损失和(如果需要)计算得到的梯度。
-
-
3. 获取梯度的函数:
-
get_grads函数:-
参数:
-
params: 配置参数对象。 -
model: 用于计算梯度的模型。 -
loss: 损失值。
-
-
功能:
-
记录计算梯度的时间,并计算模型参数的梯度。
-
-
返回值:
-
返回计算得到的梯度。
-
-
4. 张量非线性变换的函数:
-
th函数:-
参数:
-
vector: 输入张量。
-
-
功能:
-
对输入张量应用双曲正切函数 (
torch.tanh) 并将结果归一化到[0, 1]范围内。
-
-
返回值:
-
返回归一化后的张量。
-
-
5. 计算范数损失的函数:
-
norm_loss函数:-
参数:
-
params: 配置参数对象。 -
model: 包含mask属性的模型。 -
grads: 布尔值,是否需要计算梯度。
-
-
功能:
-
根据
params.nc_p_norm计算model.mask的范数:-
如果
params.nc_p_norm为 1,计算mask的 L1 范数。 -
如果
params.nc_p_norm为 2,计算mask的 L2 范数。
-
-
如果
grads为True,计算梯度并将模型的梯度清零。
-
-
返回值:
-
返回计算得到的范数和(如果需要)计算得到的梯度。
-
-
6. 计算后门损失的函数:
-
compute_backdoor_loss函数:-
参数:
-
params: 配置参数对象。 -
model: 用于计算损失的模型。 -
criterion: 损失函数。 -
inputs_back: 带有后门攻击的输入数据。 -
labels_back: 带有后门攻击的标签数据。 -
grads: 布尔值,是否需要计算梯度。
-
-
功能:
-
记录前向传播的时间,并计算模型在带有后门攻击的输入数据上的输出。
-
计算输出和带有后门攻击的标签之间的损失。
-
如果
params.task为'Pipa',对特定标签的损失进行调整。 -
如果
params.dp为False,对损失进行平均。 -
如果
grads为True,计算梯度。
-
-
返回值:
-
返回计算得到的损失和(如果需要)计算得到的梯度。
-
-
总的来说,这些函数用于在训练过程中处理损失计算、记录时间、计算梯度等操作,支持对正常数据和后门攻击数据的处理。
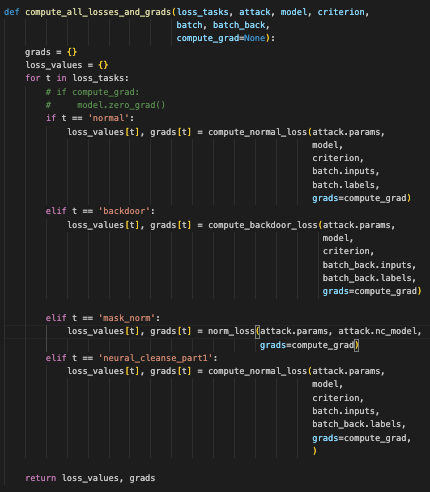
这个函数 compute_all_losses_and_grads 用于计算一组损失函数和梯度,涉及到正常损失、后门损失、掩膜范数损失,以及某种特定的损失计算(如 Neural Cleanse 部分)
函数参数:
-
loss_tasks: 一个包含不同损失任务名称的列表,例如'normal','backdoor','mask_norm','neural_cleanse_part1'等。 -
attack: 包含配置参数和模型的对象,提供必要的参数来计算损失。 -
model: 要计算损失的模型。 -
criterion: 损失函数,用于计算模型输出和目标之间的损失。 -
batch: 正常训练批次的对象,通常包含输入数据和标签。 -
batch_back: 带有后门攻击的批次对象,通常包含后门数据和标签。 -
compute_grad: 布尔值,指示是否需要计算梯度。
函数功能:
-
初始化字典:
-
grads: 用于存储每种任务的梯度。 -
loss_values: 用于存储每种任务的损失值。
-
-
计算损失和梯度:
-
遍历
loss_tasks中的每个任务,根据任务类型调用相应的损失计算函数。-
'normal':-
调用
compute_normal_loss函数,计算正常的训练损失和梯度。 -
使用
batch.inputs和batch.labels。
-
-
'backdoor':-
调用
compute_backdoor_loss函数,计算带有后门攻击的损失和梯度。 -
使用
batch_back.inputs和batch_back.labels。
-
-
'mask_norm':-
调用
norm_loss函数,计算掩膜的范数和梯度(如果需要)。 -
使用
attack.nc_model来计算掩膜的范数。
-
-
'neural_cleanse_part1':-
调用
compute_normal_loss函数,计算 Neural Cleanse 部分 1 的损失和梯度。 -
使用
batch.inputs和batch_back.labels。
-
-
-
-
返回结果:
-
返回两个字典:
loss_values和grads,分别包含每种任务的损失值和梯度。
-
compute_all_losses_and_grads 函数的作用是根据任务列表计算各种损失函数和梯度。根据提供的任务类型,它会选择合适的损失计算方法,并将计算结果存储在字典中。最终返回这些计算结果,以供进一步处理或分析。
攻击类
Attack 类主要用于管理攻击过程中的损失计算,包括:
-
使用正常数据和带有后门数据的批次计算损失。
-
根据不同的损失平衡策略(如 MGDA 或固定缩放因子)来调整损失的权重。
-
记录和更新损失历史,以便进一步分析和优化。
-
支持不同的损失计算任务,并在计算损失时考虑到这些任务的权重。
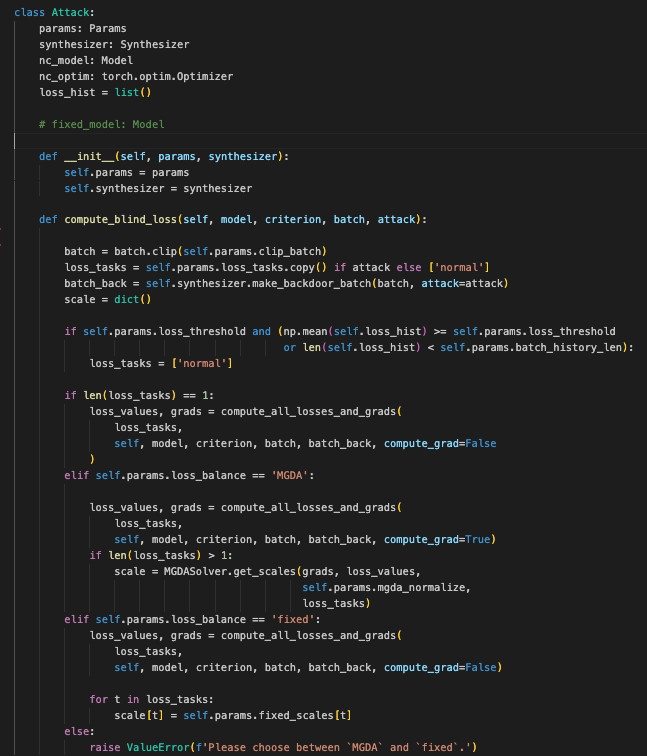
这个 Attack 类用于实现和管理一种攻击策略,其中包括计算损失值、调整损失的权重、以及跟踪损失历史记录。
属性:
-
params: 存储参数配置的对象。包含了关于损失计算、损失平衡等的配置。 -
synthesizer:Synthesizer实例,用于生成带有后门的批次数据。 -
nc_model: 用于 Neural Cleanse 的模型。 -
nc_optim: 用于优化 Neural Cleanse 模型的优化器。 -
loss_hist: 存储历史损失值的列表。
方法:
-
__init__方法:-
参数:
-
params: 配置参数对象。 -
synthesizer: 用于生成带有后门数据的Synthesizer实例。
-
-
功能:
-
初始化
params和synthesizer属性。
-
-
-
compute_blind_loss方法:-
参数:
-
model: 当前训练的模型。 -
criterion: 损失函数。 -
batch: 正常批次数据。 -
attack: 布尔值,指示是否进行攻击。
-
-
功能:
-
计算
batch数据的剪切版本。 -
根据是否进行攻击设置
loss_tasks列表。 -
使用
synthesizer生成带有后门的批次数据batch_back。 -
根据历史损失和阈值调整
loss_tasks。 -
根据
loss_balance配置选择计算损失的方法:-
MGDA: 使用 MGDA (Multi-Gradient Descent Algorithm) 平衡损失,计算梯度和损失,获取缩放因子。 -
fixed: 使用固定的缩放因子进行损失计算。
-
-
如果只有一个损失任务,设置默认的缩放因子为 1.0。
-
更新
loss_hist列表,记录正常损失的最新值。 -
调用
scale_losses方法计算加权损失。 -
返回加权后的损失值。
-
-
-
scale_losses方法:-
参数:
-
loss_tasks: 损失任务列表。 -
loss_values: 包含不同任务损失值的字典。 -
scale: 各任务损失的缩放因子。
-
-
功能:
-
计算加权损失值
blind_loss。 -
将每个任务的损失值和缩放因子存储在
params.running_losses和params.running_scales中。 -
更新总损失记录
params.running_losses['total']。 -
返回加权后的损失值
blind_loss。
-
-
MGDA求解器
MGDASolver` 类用于在多目标优化中平衡不同任务的梯度和损失值,主要包括:
-
计算最小范数解的函数 (
_min_norm_element_from2,_min_norm_2d)。 -
投影到单纯形上的方法 (
_projection2simplex)。 -
梯度下降及更新点的方法 (
_next_point)。 -
寻找最小范数元素的优化算法 (
find_min_norm_element,find_min_norm_element_FW)。 -
计算各任务缩放因子的函数 (
get_scales)。
这些方法帮助在多任务学习中优化和调整损失,使得模型能够在不同任务之间取得平衡。
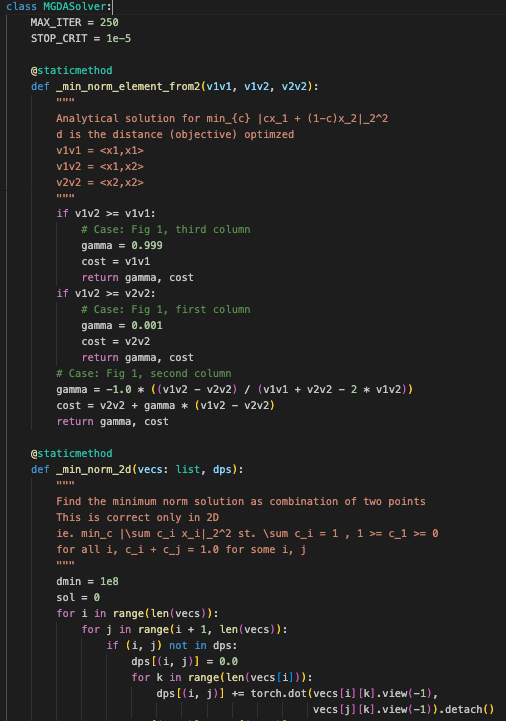
MGDASolver 类实现了多目标优化中使用的多梯度下降算法 (MGDA),其主要用于解决在多个目标之间平衡梯度的优化问题
类属性:
-
MAX_ITER: 最大迭代次数,设置为 250。 -
STOP_CRIT: 停止准则,当变化小于该值时停止迭代,设置为 1e-5。
方法:
-
_min_norm_element_from2方法:-
功能:
-
计算最小范数元素,即 (\min{c} |cx_1 + (1-c)x_2|2^2)。
-
根据 (x_1) 和 (x_2) 的内积计算最小范数解。
-
-
参数:
-
v1v1: (\langle x_1, x_1 \rangle)。 -
v1v2: (\langle x_1, x_2 \rangle)。 -
v2v2: (\langle x_2, x_2 \rangle)。
-
-
返回值:
-
gamma: 最优的比例系数。 -
cost: 对应的最小范数。
-
-
-
_min_norm_2d方法:-
功能:
-
在二维情况下找到最小范数解的组合。
-
-
参数:
-
vecs: 向量列表。 -
dps: 用于存储内积结果的字典。
-
-
返回值:
-
sol: 最小范数的解及其对应的最小值。 -
dps: 内积结果字典。
-
-
-
_projection2simplex方法:-
功能:
-
解决投影到单纯形上的优化问题,确保解满足 (\sum z = 1) 和 (0 \leq z_i \leq 1)。
-
-
参数:
-
y: 输入向量。
-
-
返回值:
-
投影后的向量
z。
-
-
-
_next_point方法:-
功能:
-
在当前点
cur_val上进行梯度下降,并将结果投影到单纯形上。
-
-
参数:
-
cur_val: 当前点的值。 -
grad: 当前点的梯度。 -
n: 向量的维度。
-
-
返回值:
-
下一点
next_point。
-
-
-
find_min_norm_element方法:-
功能:
-
寻找在给定向量列表的凸包中具有最小范数的元素。
-
-
参数:
-
vecs: 向量列表。
-
-
返回值:
-
sol_vec: 最小范数的解。 -
nd: 最小范数值。
-
-
-
find_min_norm_element_FW方法:-
功能:
-
使用 Frank-Wolfe 算法寻找在给定向量列表的凸包中具有最小范数的元素。
-
-
参数:
-
vecs: 向量列表。
-
-
返回值:
-
sol_vec: 最小范数的解。 -
nd: 最小范数值。
-
-
-
get_scales方法:-
功能:
-
计算每个任务的缩放因子,以最小化多目标优化问题中的范数。
-
-
参数:
-
grads: 各任务的梯度。 -
losses: 各任务的损失值。 -
normalization_type: 梯度归一化类型。 -
tasks: 任务列表。
-
-
返回值:
-
scale: 每个任务的缩放因子字典。
-
PatternSynthesizer类的设计目的是将一个预定义的或动态生成的后门模式嵌入图像中。它处理模式的创建、放置和与图像的结合,并根据需要调整标签以适应后门攻击。 -
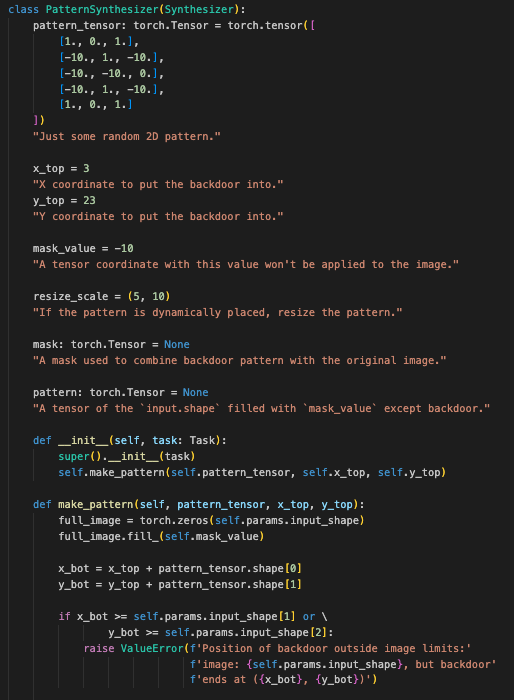
这段代码定义了一个名为 PatternSynthesizer 的类,它是 Synthesizer 的一个子类。这个类的主要功能是生成特定的模式(即后门模式)并将其嵌入到图像中。以下是对每个组件的详细解释:
-
属性和初始化:
-
pattern_tensor:这个属性保存了一个预定义的二维张量模式。它是一个矩阵,其中包含一些正值和负值。这个模式用于作为后门模式嵌入图像中。 -
x_top和y_top:这些属性表示后门模式在图像中放置时的左上角坐标。x_top是水平坐标,y_top是垂直坐标。 -
mask_value:一个值,用于表示在模式中哪些区域不会被应用到图像上。 -
resize_scale:这个元组定义了一个范围,用于在模式的位置动态变化时对模式进行缩放。 -
mask:一个张量,用于将后门模式与原始图像结合。它标记了图像中哪些部分受后门模式的影响。 -
pattern:这个张量保存了最终的后门模式,它是在图像中嵌入模式并应用了掩码后的结果。
-
-
初始化 (
__init__方法):-
__init__方法调用父类的初始化方法,然后通过调用self.make_pattern创建初始的后门模式。
-
-
模式创建 (
make_pattern方法):-
这个方法首先初始化一个
full_image张量,其大小由self.params.input_shape指定,填充了mask_value。 -
然后计算模式的右下角坐标 (
x_bot,y_bot),以确保模式不会超出图像边界。如果模式超出边界,则引发ValueError。 -
将模式放置在
full_image中的指定左上角坐标。 -
创建
mask张量,用于标记full_image中与mask_value不同的部分。 -
将
pattern张量进行归一化,并移动到适当的设备(例如 GPU)。
-
-
合成输入 (
synthesize_inputs方法):-
这个方法将生成的模式嵌入到一批输入图像中。它使用
mask确保只有与后门模式对应的图像部分被修改。
-
-
合成标签 (
synthesize_labels方法):-
这个方法为批量标签中的后门攻击部分设置特定的标签 (
self.params.backdoor_label)。
-
-
获取模式 (
get_pattern方法):-
如果启用了动态位置调整,这个方法会在定义的
resize_scale范围内随机调整pattern_tensor的大小。它还会有 50% 的概率水平翻转模式。 -
将调整大小后的模式转换为图像,再转换回张量,并在图像尺寸内随机放置。
-
再次调用
make_pattern方法以更新pattern和mask属性,应用新的位置。
-
AddMaskPatchTrigger 类用于将指定的触发器图像应用到目标图像上的特定区域,而 gradient_normalizers 函数则用于根据指定的归一化类型对梯度进行归一化处理。这些功能通常用于处理图像数据和优化过程中的梯度调整。
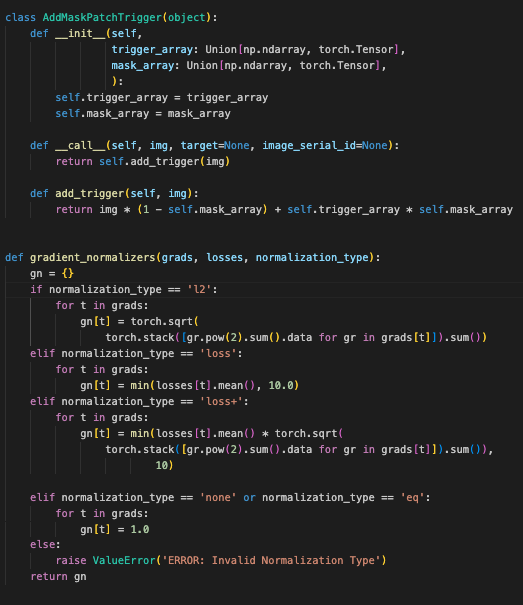
这段代码定义了两个不同的功能:
-
AddMaskPatchTrigger类:-
这个类用于将一个触发器(
trigger_array)应用到图像上,通过一个掩码(mask_array)来控制触发器的应用区域。
构造函数 (
__init__方法):-
trigger_array: 触发器数组,可以是numpy.ndarray或torch.Tensor。 -
mask_array: 掩码数组,同样可以是numpy.ndarray或torch.Tensor。 -
将这两个参数存储为实例变量。
调用方法 (
__call__方法):-
这个方法让
AddMaskPatchTrigger实例可以像函数一样被调用。它调用add_trigger方法来将触发器应用到图像上。
添加触发器 (
add_trigger方法):-
add_trigger方法接收一张图像img,通过使用掩码数组mask_array将触发器数组trigger_array叠加到图像上。 -
计算方式是:
img * (1 - mask_array) + trigger_array * mask_array。这意味着图像中掩码为1的部分将被触发器覆盖,而掩码为0的部分保持不变。
-
-
gradient_normalizers函数:-
这个函数用于根据不同的归一化类型对梯度进行归一化处理。它接收梯度(
grads)、损失(losses)和归一化类型(normalization_type)。
参数:
-
grads: 一个字典,键是变量名,值是对应变量的梯度列表。 -
losses: 一个字典,键是变量名,值是对应变量的损失值。 -
normalization_type: 一个字符串,指定归一化类型,可以是'l2'、'loss'、'loss+'、'none'或'eq'。
归一化类型处理:
-
l2:-
对于每个梯度,计算梯度的 L2 范数(即每个梯度的平方和的平方根)。
-
-
loss:-
对于每个梯度,使用损失的均值进行归一化,归一化值最大为 10.0。
-
-
loss+:-
归一化值是损失的均值与梯度的 L2 范数的乘积,最大值为 10。
-
-
none或eq:-
归一化值固定为 1.0。
-
-
如果提供了无效的归一化类型,抛出
ValueError异常。
返回值:
-
返回一个字典
gn,包含每个变量的归一化值。
-
-
blendedImageAttack_on_batch类用于将目标图像与输入图像按比例混合,从而生成具有目标图像特征的混合图像。 -
batchwise_label_transform类用于批量标签的转换,通过指定的变换函数将原始标签转换为新的标签,并将结果移动到指定设备。
这两个类的功能可以在图像处理和模型训练中用于特定的攻击策略和标签处理任务。
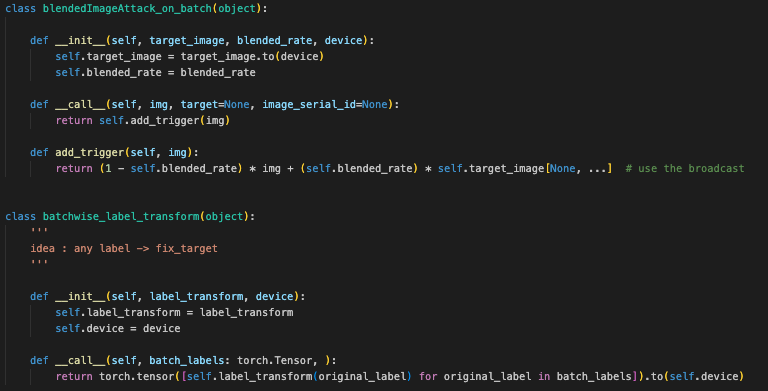
1. blendedImageAttack_on_batch 类
这个类用于对图像批次进行混合攻击。它将目标图像和当前图像按一定比例混合,生成具有目标图像特征的图像。
-
构造函数 (
__init__方法):-
target_image: 目标图像,它将用于与输入图像进行混合。这个图像被移动到指定的设备(如 GPU)。 -
blended_rate: 混合比例,决定了目标图像在最终混合图像中的占比。 -
device: 设备(如 GPU),用于存储目标图像。
-
-
调用方法 (
__call__方法):-
使得
blendedImageAttack_on_batch实例可以像函数一样被调用。它调用add_trigger方法来进行图像混合。
-
-
添加触发器 (
add_trigger方法):-
img: 输入图像。 -
计算混合图像的公式是
(1 - self.blended_rate) * img + (self.blended_rate) * self.target_image[None, ...]。这里使用了广播(broadcasting),将目标图像的维度与输入图像的维度对齐,然后将目标图像和输入图像按比例混合。
-
2. batchwise_label_transform 类
这个类用于批量标签的转换,将原始标签通过某种变换函数转换为新的标签。
-
构造函数 (
__init__方法):-
label_transform: 一个函数,用于将标签转换为目标标签。 -
device: 设备(如 GPU),用于存储转换后的标签。
-
-
调用方法 (
__call__方法):-
batch_labels: 批量标签,是一个张量(torch.Tensor)。 -
使用列表推导将每个标签通过
self.label_transform函数进行转换,并将结果转换为张量,最终将张量移动到指定的设备上。
-
此时的中毒样本如下



执行后门注入
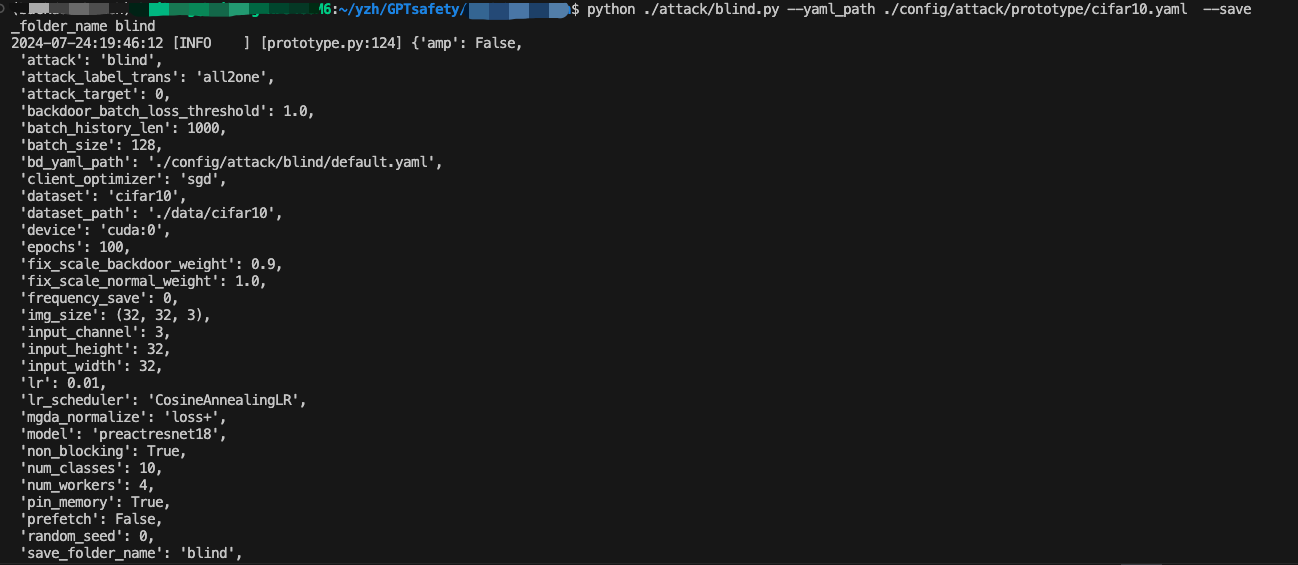
如下是攻击配置信息
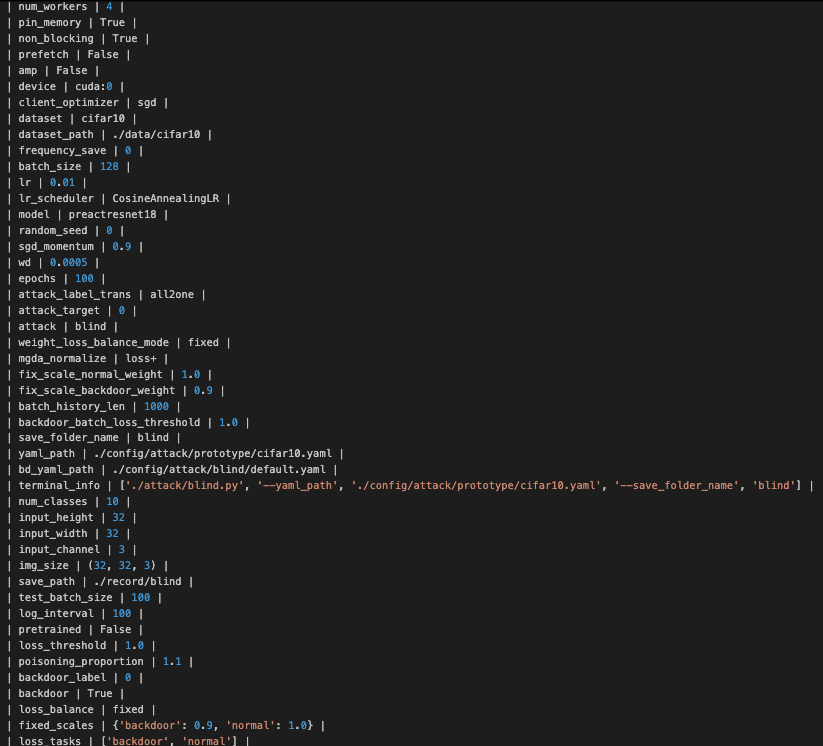
训练过程部分截图如下
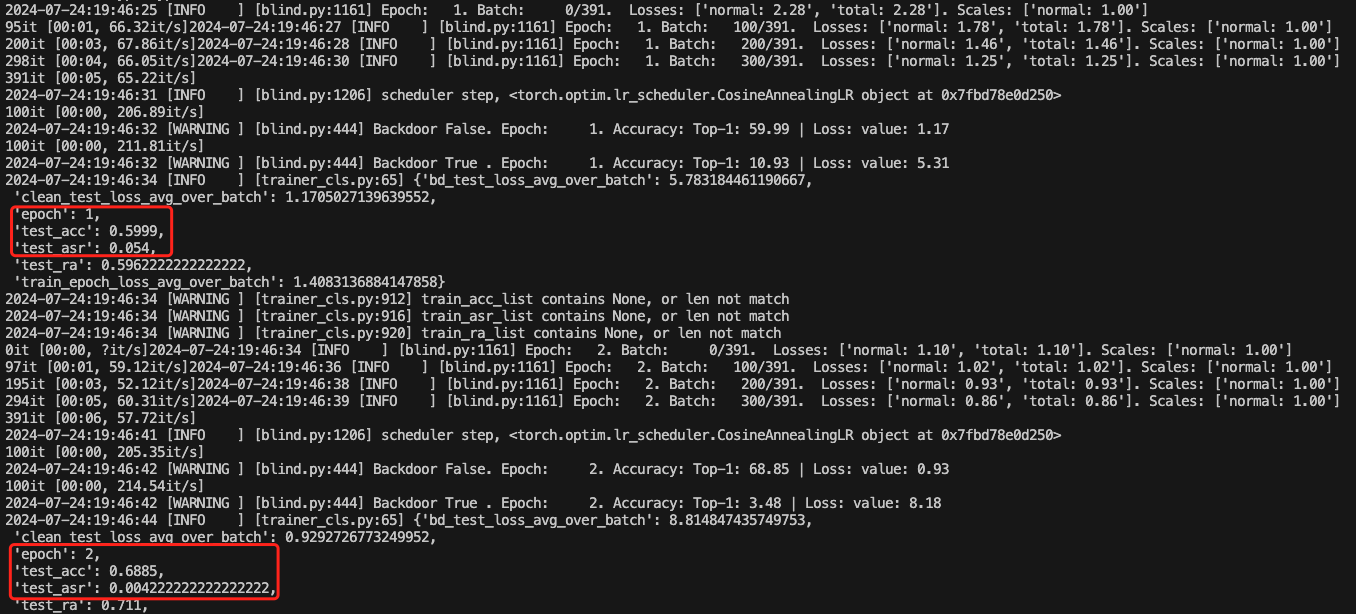
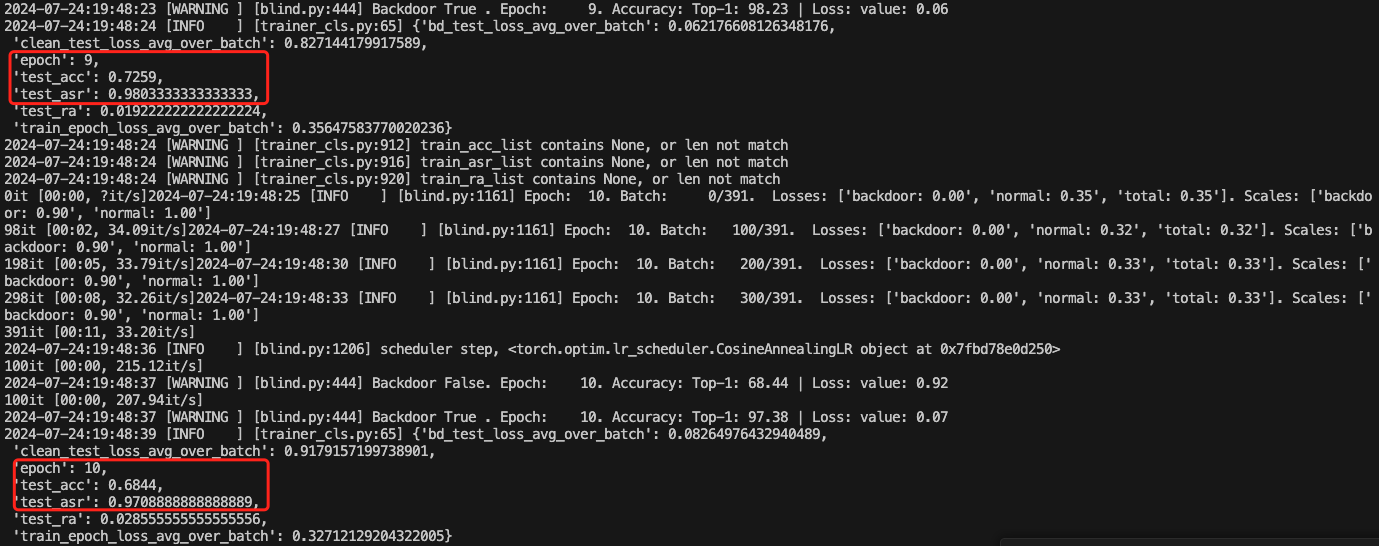
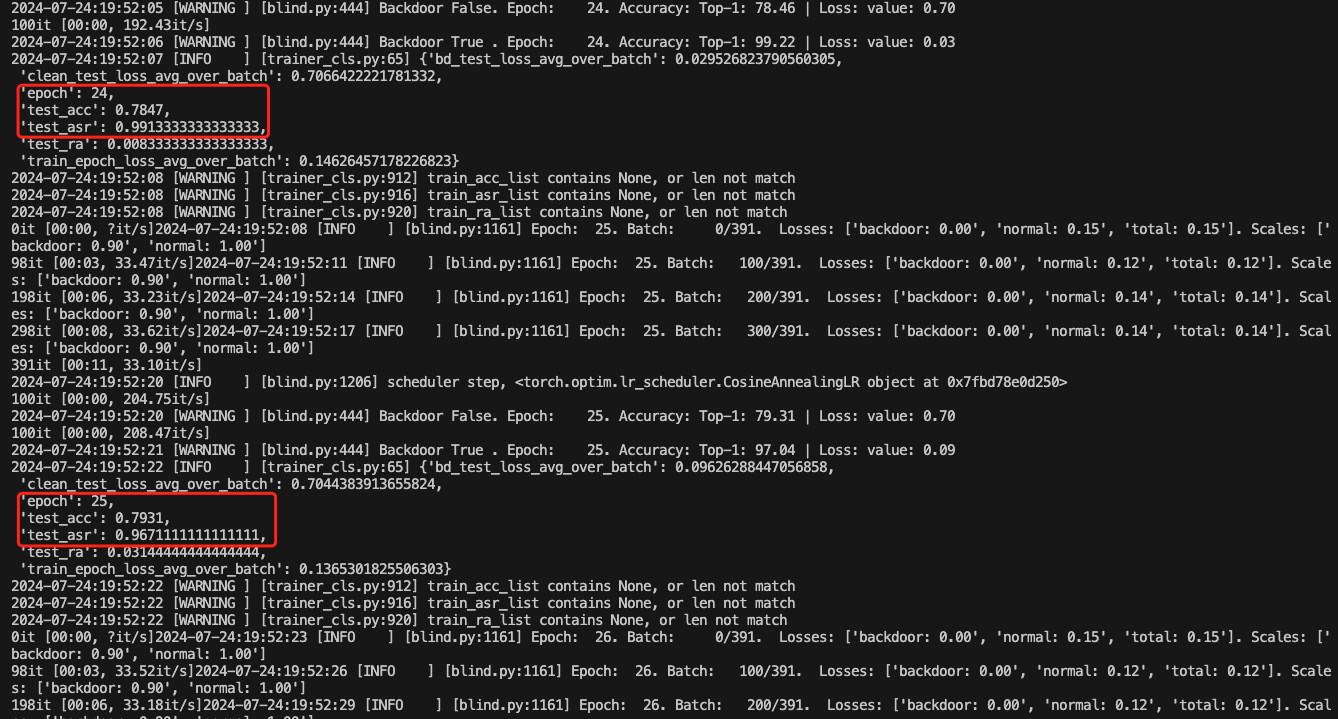
查看acc变化情况
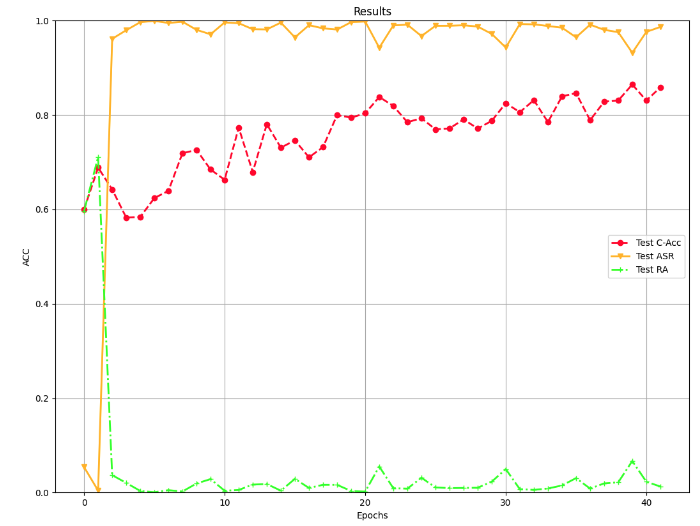
可以看到也是稳步上升的
总得来说,这种后门攻击方法,虽然后门攻击成功率较高,但是正常任务的准确率会受到一定影响,比如在第24个epoch时,正常任务的准确率才0.79。
更多网安技能的在线实操练习,请点击这里>>
标签:后门,训练,攻击,模型,图像,损失,深度 From: https://www.cnblogs.com/hetianlab/p/18419861