近年来,Vision Transformer(ViT)在计算机视觉领域取得了巨大突破。然而ViT模型通常计算复杂度高,难以在资源受限的移动设备上部署。为了解决这个问题,研究人员提出了Convolutional Additive Self-attention Vision Transformers (CAS-ViT),这是一种轻量级的ViT变体,旨在在效率和性能之间取得平衡。
这是8月份再arxiv上发布的新论文,我们下面一起来介绍这篇论文的重要贡献
核心创新:卷积加法token混合器(CATM)
CAS-ViT的核心创新在于提出了一种新颖的加法相似度函数,称为卷积加法token混合器(CATM)。与传统ViT中的多头自注意力机制相比,CATM大大降低了计算复杂度。
让我们来看看CATM与之前工作的对比: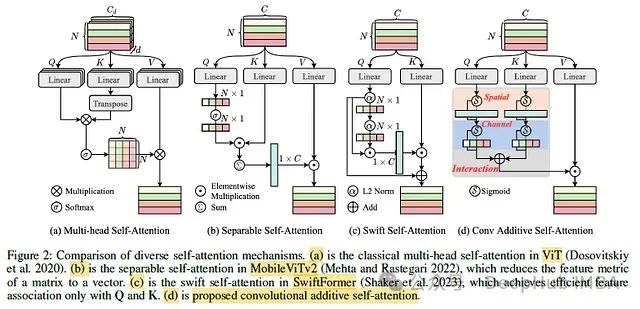
- 传统ViT中的多头自注意力(图a):计算复杂度为O(N^2),其中N是序列长度。这在处理高分辨率图像时计算开销很大。
- MobileViTv2中的可分离自注意力(图b):将矩阵特征度量简化为向量,降低了复杂度。
- SwiftFormer中的swift自注意力(图c):将自注意力的键减少到两个(Q和K),进一步加速推理。
- 论文提出的卷积加法自注意力(图d):定义了一个新的相似度函数,将Q和K的上下文分数相加。
https://avoid.overfit.cn/post/e7f68be55b014473a12aef501274b7b4
标签:Transformer,CAS,复杂度,卷积,ViT,加法,注意力 From: https://www.cnblogs.com/deephub/p/18417973