YOLO V1
前言
本文主要讲以下几个方面:YOLOV1介绍、预测阶段、后处理、YOLOV1训练阶段以及YOLOV1的局限性。
YOLO介绍
针对目标检测问题,之前的检测方法通常都转变为了一个分类问题,如R-CNN、Fast R-CNN等。而在yolo中,作者将目标检测问题转变为了一个回归问题。YOLO从图像的输入、仅仅经过一个神经网络,直接得到bounding boxes以及每个bounding box所属类别的概率。由此可见,它是一种单阶段模型。
YOLO相较于其他神经网络,有许多优点。
- 它非常快:标准版本的YOLO在TitanX的GPU上能达到45FPS。网络较小的版本如Fast YOLO在保持mAP是其他实时目标检测器的两倍的同时,检测速度可以达到155FPS。
- YOLO虽说在物体定位时更容易出错,但是在背景上预测不存在的物体的情况会少一些。
- YOLO对比DPM、R-CNN等目标检测系统更能学到更加抽象的物体的特征,这使得YOLO可以从真实图像领域迁移到其他领域,如艺术。
预测阶段
YOLO是端到端的系统,即输入的是一张图片,输出的是预测的结果,中间的过程我们当作黑盒子。为了更好的理解YOLO目标检测的过程,我们首先聚焦于输出结果的部分,即推理阶段。

上图是模型的推理过程,我们将一张448 x 448 x 3的图像作为输入,输出为7 x 7 x 30的tensor。输出的tensor是我们理解YOLO推理的关键。
在YOLOV1中,我们将图片分成S x S的网格(grid cell),每个网格预测B个边界框(bounding box),用来框出我们待检测的物品。为了确定一个框在图像中的位置,我们采用了4个变量(x, y, w, h),分别代表bounding box的中心点横坐标、中心点纵坐标、高度和宽度。在YOLOV1中,作者为每一个grid cell定义了一个新的性质--confidence。它用来表征每个grid cell是否包含物体,以及是该物体的概率。用以下公式表示:
\[\operatorname{Pr}\left(\mathrm{Object}\right) * \mathrm{IOU}_{\text {pred }}^{\text {truth }} \] 通过这个公式,我们可以看到它既包含了某个物体的概率,也包含了我们预测目标边界框与真实目标边界框的重合程度。在这里,如果一个grid cell包含一个object,则Pr(Object) = 1,confidence则为目标边界框和真实边界框的IOU(交并比),若不包含一个object,则confidence为0。
在作者的论文中,取S = 7, B = 2, 即每个grid cell会预测两个bounding box,每个bounding box 包含5个参数,而作者在预测中使用的数据集为VOC数据集,共有20个类别。
那么共有7 x 7个网格,那么输出的tensor的含义将不难理解,如下图所示:

后处理
后处理研究的问题为如何将7 x 7 x 30的tensor化为最后图片展示的结果,其流程如下图所示:

-
从输出的tensor中提取每个预测框的信息。因为每个grid cell会预测两个bounding box,故每张图会生成7 x 7 x 2共98个grid cell。而每个grid cell 的最后20个数值对应每种类别的条件概率,那么使用每个bounding box 的confidence乘以条件概率,则可以计算出每个bbox的类别得分。即:
\[\text { Score }_{i j}=P\left(C_{i} \mid \text { Object }\right) * \text { Confidence }_{j} \]如上图中间的所示:有密集的一些方框,这就是bounding box,而线的粗细表示confidence的大小。
-
由1的结果,我们最终得到的是98 x 20 x 1的tensor,使用这些概率值做非极大值抑制(NMS),目的是过滤掉低置信度的框,得到最终预测的结果。假设每个预测框的20 x 1向量的的一个元素是狗的概率,如下图所示:

首先设置一个阈值,假设0.2,那么将小于0.2的值置为0,那么这些框将不启用,将其移除。随后按照将所有概率值排序,按照降序排序。
-
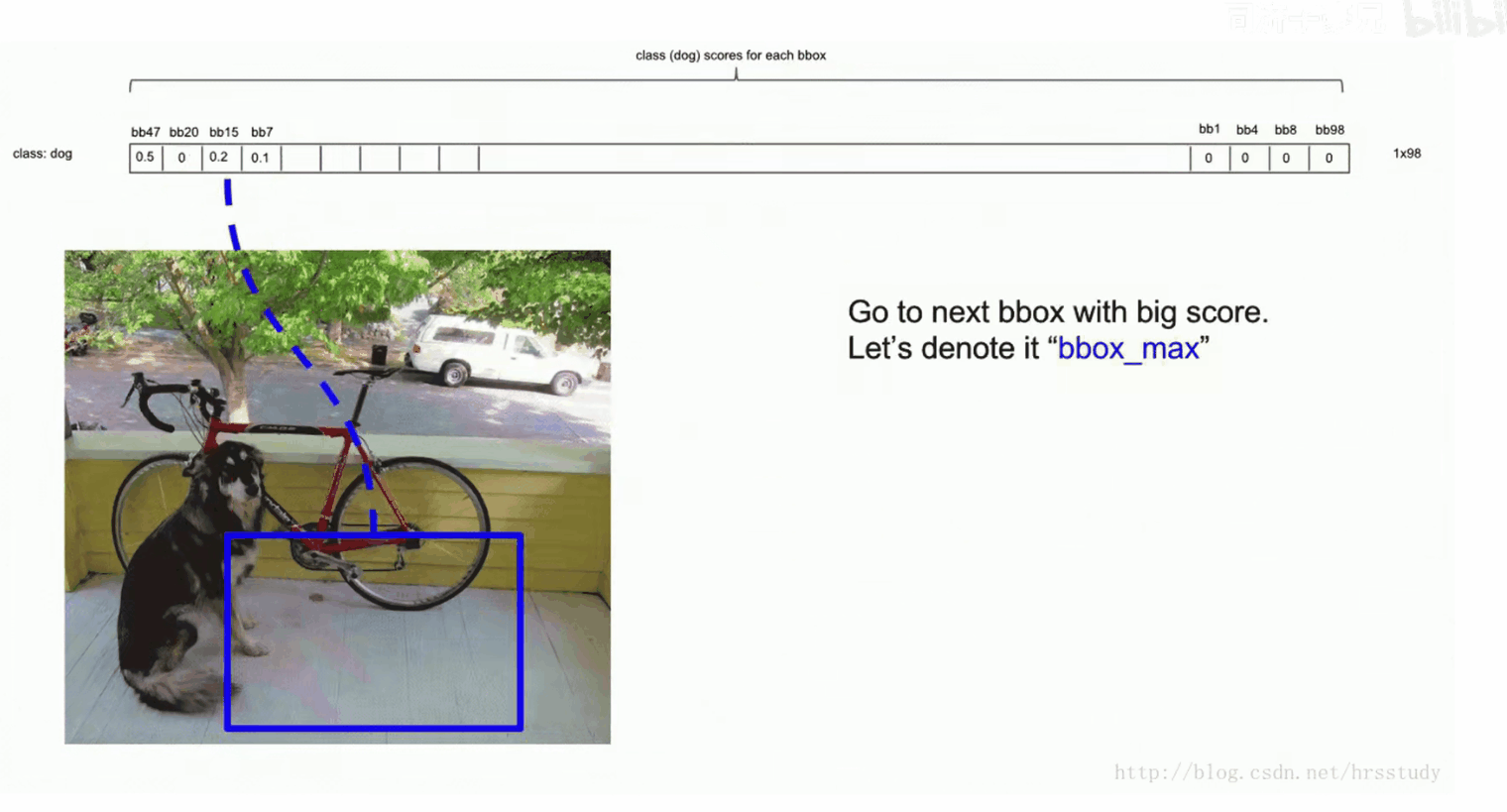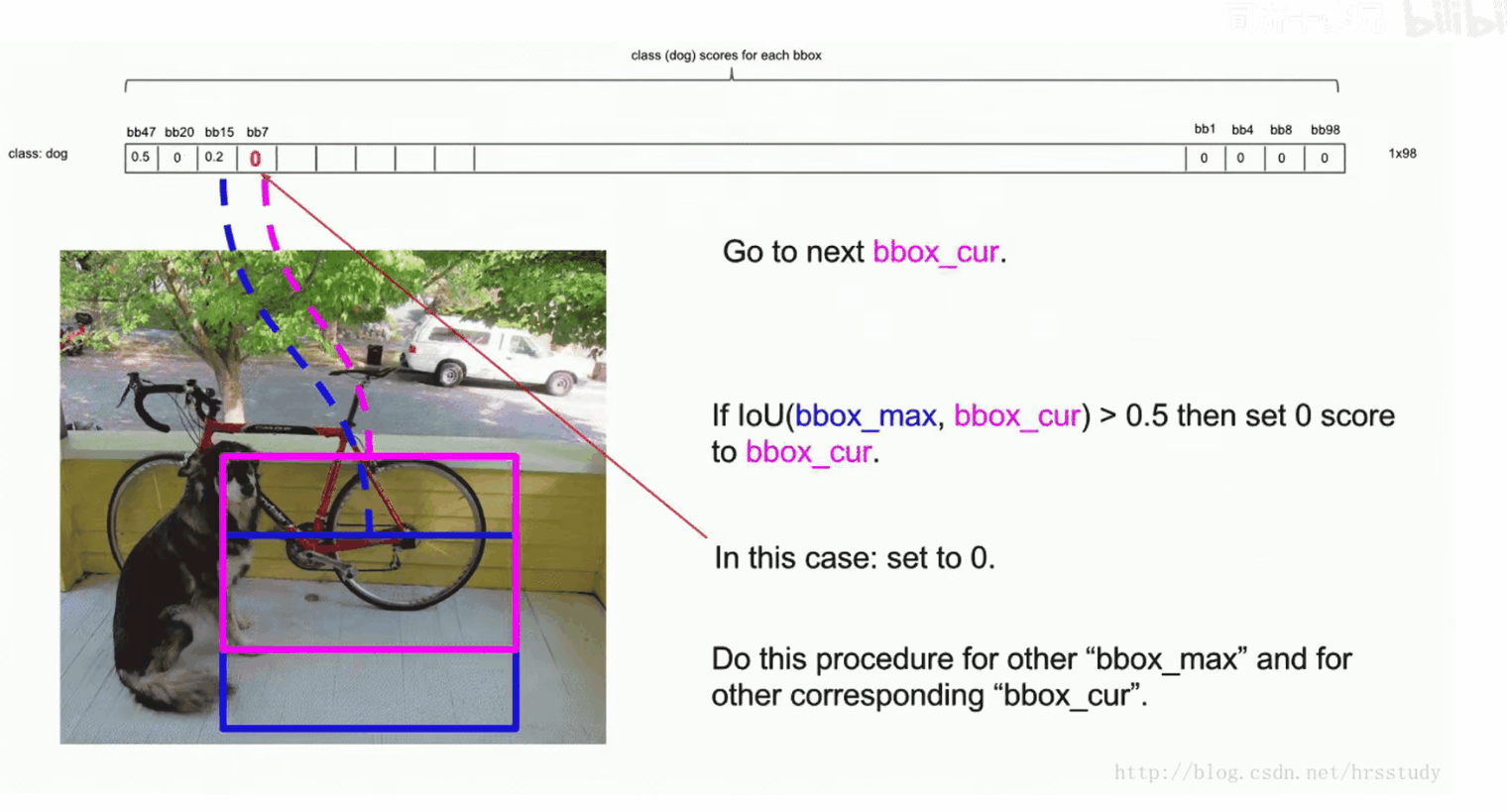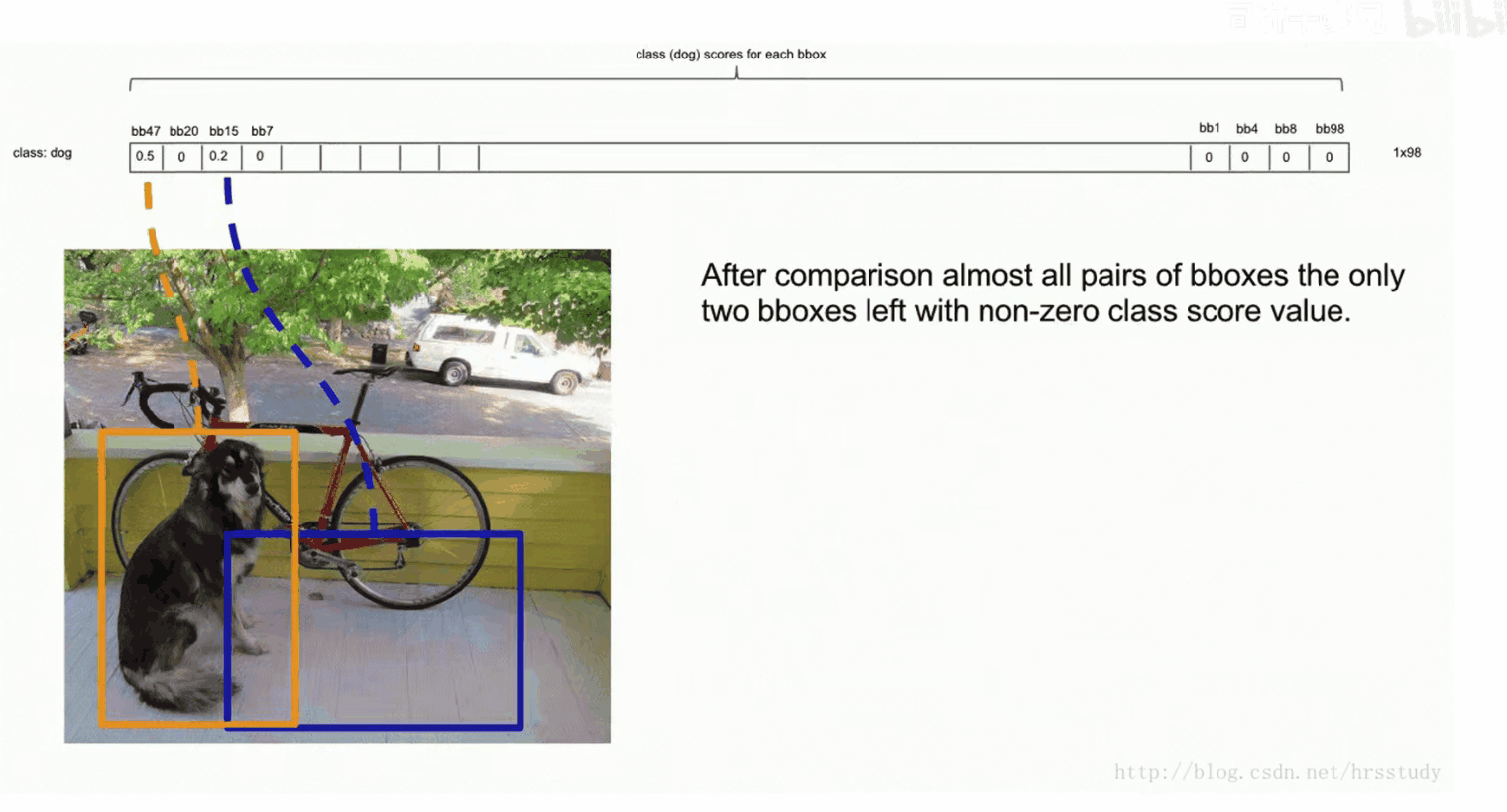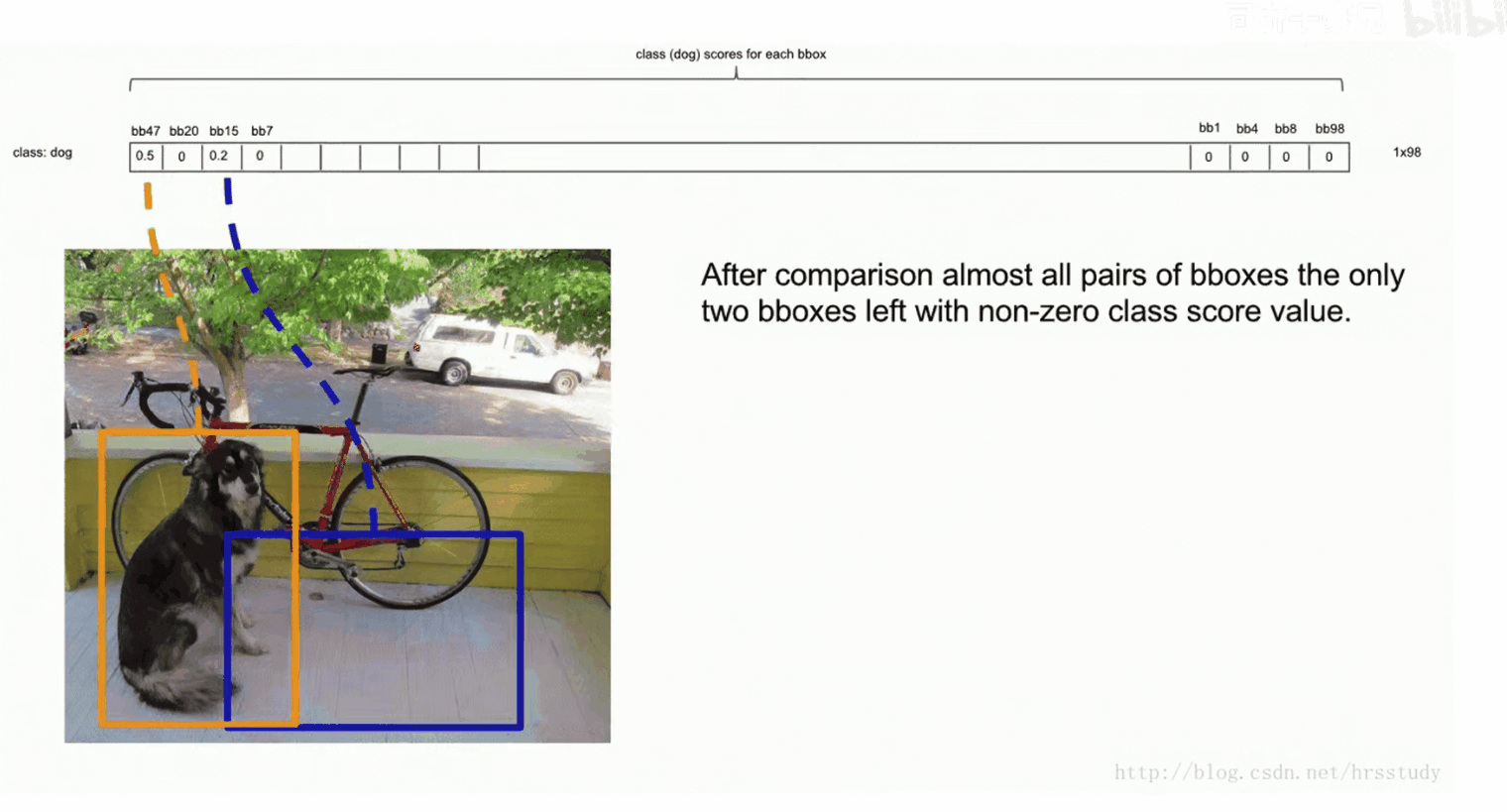
进行NMS,处理冗余检测框。在第2步中,我们进行了排序,选中了目标的检测框通常排在前面。我们依次将排序第二的bbox与第一的进行IOU,如果大于某个阈值(比如0.5),那么我们则认为这两个预测框预测的是同一个物体,因此我们保留概率大的框,并将另一个框的概率置为0。如果小于阈值0.5,则保留该框的概率。重复此步骤,让第一个框依次与后面的框作比较,比较完后,我们将在这个过程中没有被置为0的下一个框为bbox_max,再依次向后比较,重复上述过程,直到最后一个bbox_max比较过后,其后面的框的概率均被置为0。
将每一个类别都进行上述过程,便可以将不为0的框画出来,至此横向对比结束。

-
经过处理后,98个bbox中有很多概率为0的类,分别对每个bbox取最大值,如果最大值为0就跳过这个bbox,如果最大值大于0就记下这个概率以及对应的类,然后将这个bbox的(x,y,w,h)进行绘制,至此便可得到最后的预测框的结果。

训练阶段
网络结构
YOLO V1中采用了24个卷积层和两个全连接层。YOLO V1的backbone网络使用了1 x 1和3 x 3的卷积层,所以网络的结构是比较简单的。在那个年代,网络层最后将卷积输出的特征图拉平(flatten),得到一个一维向量,然后接若干全连接层做预测。在YOLO V1中继承了这个思路,最后的7 x 7 x 1024的特征图通过第一个Conn.Layer时,需要进行三个处理:①transpose处理(可选)②flatten处理③fc(4096),此时便会得到一个4096维的向量。通过第二个Conn.Layer时,需要进行两个处理:①fc(1470)②Reshape,将向量调整为7 x 7 x30的矩阵。
在整个训练过程中,除最后一层采用ReLU函数外,其他层均采用leaky ReLu激活函数。leaky ReLU函数可以解决在输入为负值时的零梯度问题。YOLO V1中采用的leaky ReLU函数的表达式为:
\[\phi(\mathrm{x})= \begin{cases}\mathrm{x}, & \text { if } \mathrm{x}>0 \\ 0.1 \mathrm{x}, & \text { otherwise }\end{cases} \]
损失函数

在损失函数这里作者每一项都用的平方和误差,将目标检测问题当作回归问题。下面分别看这五项:
第一项:负责检测物体的框中心点(x,y)定位误差。遍历所有负责检测物体的框,计算其\(\left(\mathrm{x}_{\mathrm{i}}, \mathrm{y}_{\mathrm{i}}\right)\)坐标与实际框\(\left(\hat{\mathrm{x}}_{\mathrm{i}}, \hat{\mathrm{y}}_{\mathrm{i}}\right)\)的平方和误差,其权重\(\lambda_{\text {coord }}=5\)。
第二项:负责检测物体的框的高宽(w,h)定位误差。遍历所有负责检测物体的框,计算\(\left(\sqrt{\mathrm{W}_{\mathrm{i}}}, \sqrt{\mathrm{h}_{\mathrm{i}}}\right)\)坐标与实际框的\(\left(\sqrt{\hat{\mathrm{w}}_{\mathrm{i}}}, \sqrt{\hat{\mathrm{h}}_{\mathrm{i}}}\right)\)平方误差和,其权重\(\lambda_{\text {coord }}=5\)。这里采用了平方根形式是为了对小框更加敏感。

第三项:负责检测物体的confidence平方和误差。
第四项:不负责检测物体的confidence的平方和误差。其权重为0.5。
第五项:负责检测物体的网格对应类别的分类误差。当实际框中心落在某个网格内时,这个网格便需要预测该物体的类别。所以这一项我们遍历所有的网格,并将其类别预测值与实际值求平方误差。很明显,标签值在实际类别时为1,在非该物体类别时为0。
YOLO V1的局限性
- 对一些群体性的小目标检测效果很差。因为在YOLO V1的思想中,每个grid cell只预测两个bbox,而且预测的两个bbox还是属于同一个类别的。所以当一些小目标聚集在一起时的检测效果就非常的差。而且如果一个cell中有多个类别时,YOLO V1也无法检测出来。
- 当我们的目标出现新的尺寸时,YOLO V1的预测效果也是非常的差。这也是因为grid cell只对应两个bbox,那么当同一类物体的长宽比在训练集中覆盖不到时,泛化能力偏弱。
- 定位不准。