前面学习了数组,而对于字符类型的数组,比较特殊,它实际上可以作为一个字符串(String)表示,字符串就是一个或多个字符的序列,比如在一开始认识的"Hello World",像这样的多个字符形成的一连串数据,就是一个字符串,而printf函数接受的第一个参数也是字符串。
在 C 语言中并没有直接提供存储字符串的类型,能够存储字符的只有 char 类型,但是它只能存储单个字符。
一连串的字符想要通过变量进行保存,就只能依靠数组了,char 类型的数组允许存放多个字符,这样的话就可以表示字符串了。
比如现在想要存储Hello这一连串字符:
#include <stdio.h>
int main() {
// 直接保存单个字符
// 但是注意,无论内容是什么,字符串末尾必须添加一个 '\0' 字符(ASCII码为0)表示结束
// 如果不加 '\0' 字符,则会在末尾产生 + 号,比如下面的字符串的结果为 Hello+
// char str[] = {'H', 'e', 'l', 'l', 'o'};
char str[] = {'H', 'e', 'l', 'l', 'o', '\0'};
// 用%s来作为一个字符串输出
printf("%s", str);
}
不过这样写起来实在是太麻烦了,可以使用更加简便的写法:
#include <stdio.h>
int main() {
// 直接使用双引号将所有的内容囊括起来,并且也不需要补充\0(但是本质上是和上面一样的字符数组)
char str[] = "Hello";
// 也可以添加 const char str[] = "Hello";
// 双引号囊括的字符串实际上就是一个const char数组类型的值
printf("%s", str);
}
这下终于明白了,原来一直在写的双引号,其实表示的就是一个字符串。
那么现在看看下面的写法有什么不同:
"c"
'c'
发现一个问题,char 类型只能保存 ASCII 编码表中的字符,但是实际上中文也是可以正常打印的:
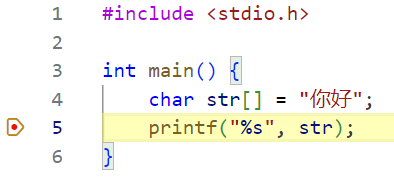
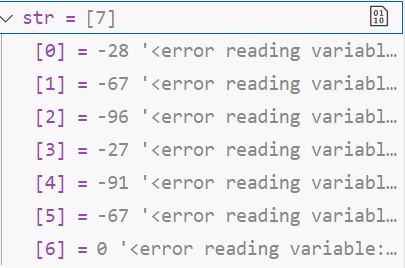
printf("你好 世界");
这是什么情况?那么多中文字符(差不多有 6000 多个),用 ASCII 编码表那 128 个肯定是没办法全部表示的,但是现在需要在电脑中使用中文。这时,就需要扩展字符集了。
可以使用两个甚至多个字节来表示一个中文字符,这样能够表示的数量就大大增加了,GB2132 方案规定当连续出现两个大于 127 的字节时(注意不考虑符号位,此时相当于是第一个bit位一直为1了),表示这是一个中文字符(所以为什么常说一个英文字符占一字节,一个中文字符占两个字节),这样就可以表示出超过 7000 种字符了,不仅仅是中文,甚至中文标点、数学符号等,都可以被正确的表示出来。
不过这样能够表示的内容还是不太够,除了那些常见的汉字之外,还有很多的生僻字,比如龘、錕、釿、拷这类的汉字,后来干脆直接只要第一个字节大于 127,就表示这是一个汉字的开始,无论下一个字节是什么内容(甚至原来的128 个字符也被编到新的表中),这就是 Windows 至今一直在使用的默认 GBK 编码格式。
虽然这种编码方式能够很好的解决中文无法表示的问题,但是由于全球还有很多很多的国家以及很多很多种语言,所以最终目标是能够创造一种可以表示全球所有字符的编码方式,整个世界都使用同一种编码格式,这样就可以同时表示全球的语言了。所以这时就出现了一个叫做 ISO(国际标准化组织)的组织,来定义一套编码方案来解决所有国家的编码问题,这个新的编码方案就叫做 Unicode,规定每个字符必须使用俩个字节,即用 16 个 bit 位来表示所有的字符(也就是说原来的那 128 个字符也要强行用两位来表示)
但是这样的话实际上是很浪费资源的,因为这样很多字符都不会用到两字节来保存,但是又得这样去表示,这就导致某些字符浪费了很多空间。所以最后就有了 UTF-8 编码格式,区分每个字符的开始是根据字符的高位字节来区分的,比如:
用一个字节表示的字符,第一个字节高位以 0 开头
用两个字节表示的字符,第一个字节的高位为以 110 开头,后面一个字节以 10 开头
用三个字节表示的字符,第一个字节以 1110 开头,后面两个字节以 10 开头
用四个字节表示的字符,第一个字节以 11110 开头,后面的三个字节以 10 开头
如果程序需要表示多种语言,最好采用 UTF-8 编码格式
10000011 10000110
这就是一个连续出现都大于 127 的字节(注意这里是不考虑符号位的)
| Unicode符号范围(十六进制) | UTF-8编码方式(二进制) |
|---|---|
| 0000 0000 ~ 0000 007F | 0xxxxxxx |
| 0000 0080 ~ 0000 07FF | 110xxxxx 10xxxxxx |
| 0000 0800 ~ 0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 0001 0000 ~ 0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
简而言之,中文实际上是依靠多个 char 来进行表示的。
这样,就了解了字符串的使用。
标签:11,字符,0000,字节,C语言,char,表示,字符串 From: https://www.cnblogs.com/skysailstar/p/18411814