前言
大型语言模型,尤其是像ChatGPT这样的模型,尽管在自然语言处理领域展现了强大的能力,但也伴随着隐私泄露的潜在风险。在模型的训练过程中,可能会接触到大量的用户数据,其中包括敏感的个人信息,进而带来隐私泄露的可能性。此外,模型在推理时有时会无意中回忆起训练数据中的敏感信息,这一点也引发了广泛的关注。
隐私泄露的风险主要来源于两个方面:一是数据在传输过程中的安全性,二是模型本身的记忆风险。在数据传输过程中,如果没有采取充分的安全措施,攻击者可能会截获数据,进而窃取敏感信息,给用户和组织带来安全隐患。此外,在模型的训练和推理阶段,如果使用了个人身份信息或企业数据等敏感数据,这些数据可能会被模型运营方窥探或收集,存在被滥用的风险。
过去已经发生了多起与此相关的事件,导致许多大公司禁止员工使用ChatGPT。此前的研究表明,当让大模型反复生成某些特定词汇时,它可能会在随后的输出中暴露出训练数据中的敏感内容。
学术研究表明,对模型进行训练数据提取攻击是切实可行的。攻击者可以通过与预训练模型互动,从而恢复出训练数据集中包含的个别示例。例如,GPT-2曾被发现能够记住训练数据中的一些个人信息,如姓名、电子邮件地址、电话号码、传真号码和实际地址。这不仅带来了严重的隐私风险,还对语言模型的泛化能力提出了质疑。

本文要探讨的就是可以高效从大模型中提取出用于训练的隐私数据的技巧与方法,主要来自《Bag of Tricks for Training Data Extraction from Language Models》,这篇论文发在了人工智能顶级会议ICML 2023上。
背景知识
尽管大模型在各种下游语言任务中展现了令人瞩目的性能,但其内在的记忆效应使得训练数据可能被提取出来。这些训练数据可能包含敏感信息,如姓名、电子邮件地址、电话号码和物理地址,从而引发隐私泄露问题,阻碍了大模型在更广泛应用中的推进。
之前谷歌举办了一个比赛,链接如下
https://github.com/google-research/lm-extraction-benchmark/tree/master
这是一个针对性数据提取的挑战赛,目的是测试参赛者是否能从给定的前缀中准确预测后缀,从而构成整个序列,使其包含在训练数据集中。这与无针对性的攻击不同,无针对性的攻击是搜索训练数据集中出现的任意数据。
针对性提取被认为更有价值和具有挑战性,因为它可以帮助恢复与特定主题相关的关键信息,而不是任意的数据。此外,评估针对性提取也更容易,只需检查给定前缀的正确后缀是否被预测,而无针对性攻击需要检查整个庞大的训练数据集。
这个比赛使用1.3B参数的GPT-Neo模型,以1-eidetic记忆为目标,即模型能够记住训练数据中出现1次的字符串。这比无针对性和更高eidetic记忆的设置更具有挑战性。
比赛的基准测试集包含从The Pile数据集中选取的20,000个示例,这个数据集已被用于训练许多最新的大型语言模型,包括GPT-Neo。每个示例被分为长度为50的前缀和后缀,攻击的任务是在给定前缀的情况下预测正确的后缀。这些示例被设计成相对容易提取的,即存在一个前缀长度使得模型可以准确生成后缀。
训练数据提取
从预训练的语言模型中提取训练数据,即所谓的"语言模型数据提取",是一种恢复用于训练模型的示例的方法。这是一个相对较新的任务,但背后的许多技术和分析方法,如成员资格推断和利用网络记忆进行攻击,早就已经被引入。
Carlini等人是最早定义模型知识提取和κ-eidetic记忆概念的人,并提出了有希望的数据提取训练策略。关于记忆的理论属性以及在敏感领域应用模型提取(如临床笔记分析)等,已经成为这个领域后续研究的焦点。
最近的研究也有一些重要发现:
-
Kandpal等人证明,在语言模型中,数据提取的效果经常归因于常用网络抓取训练集中的重复。
-
Jagielski等人使用非确定性为忘记记忆示例提供了一种解释。
-
Carlini等人分析了影响训练数据记忆的三个主要因素。
-
Feldman指出,为了达到接近最优的性能,在自然数据分布下需要记忆标签。
-
Lehman等人指出,预训练的BERT在训练临床笔记时存在敏感数据泄露的风险,特别是当数据表现出高水平的重复或"笔记膨胀"时。
总的来说,这个新兴领域正在深入探讨如何从语言模型中提取训练数据,以及这种提取带来的安全和隐私风险。最新的研究成果为进一步理解和应对这些挑战提供了重要的洞见。
成员推理攻击
成员资格推断攻击(MIA)是一种与训练数据提取密切相关的对抗性任务,目标是在只能对模型进行黑盒访问的情况下,确定给定记录是否在模型的训练数据集中。MIA已被证明在各种机器学习任务中都是有效的,包括分类和生成模型。
MIA使用的方法主要分为两类:
-
基于分类器的方法:这涉及训练一个二元分类器来识别成员和非成员之间的复杂模式关系,影子训练是一种常用的技术。
-
基于度量的方法:这通过首先计算模型预测向量上的度量(如欧几里得距离或余弦相似度)来进行成员资格推断。
这两类方法都有各自的优缺点,研究人员正在不断探索新的MIA攻击方法,以更有效地从机器学习模型中推断训练数据。这突出了训练数据隐私保护在模型部署和应用中的重要性。对MIA技术的深入理解,有助于设计更加安全和隐私保护的机器学习模型训练和部署策略,这对于广泛应用尤其是在敏感领域的应用至关重要。
其他基于记忆的攻击
大型预训练模型由于容易记住训练数据中的信息,因此面临着各种潜在的安全和隐私风险。除了训练数据提取攻击和成员资格推断攻击之外,还有其他基于模型记忆的攻击针对这类模型。
其中,模型提取攻击关注于复制给定的黑盒模型的功能性能。在这类攻击中,对手试图构建一个具有与原始黑盒模型相似预测性能的第二个模型,从而可以在不获取原始模型的情况下复制其功能。针对模型提取攻击的保护措施,集中在如何限制模型的功能复制。
另一类攻击是属性推断攻击,其目标是从模型中提取特定的个人属性信息,如地点、职业和兴趣等。这些属性信息可能是模型生产者无意中共享的训练数据属性,例如生成数据的环境或属于特定类别的数据比例。
与训练数据提取攻击不同,属性/属性推断攻击不需要事先知道要提取的具体属性。而训练数据提取攻击需要生成与训练数据完全一致的信息,这更加困难和危险。
总之,这些基于模型记忆的各类攻击,都突显了大型预训练模型在隐私保护方面的重大挑战。如何有效应对这些攻击,成为当前机器学习安全研究的一个重要焦点。
【----帮助网安学习,以下所有学习资料免费领!加vx:dctintin,备注 “博客园” 获取!】
① 网安学习成长路径思维导图
② 60+网安经典常用工具包
③ 100+SRC漏洞分析报告
④ 150+网安攻防实战技术电子书
⑤ 最权威CISSP 认证考试指南+题库
⑥ 超1800页CTF实战技巧手册
⑦ 最新网安大厂面试题合集(含答案)
⑧ APP客户端安全检测指南(安卓+IOS)
威胁模型
数据集是从 Pile 训练数据集中抽取的 20,000 个样本子集。每个样本由一个 50-token 的前缀和一个 50-token 的后缀组成。
攻击者的目标是给定前缀时,尽可能准确地预测后缀。
这个数据集中,所有 100-token 长的句子在训练集中只出现一次。
采用了 HuggingFace Transformers 上实现的 GPT-Neo 1.3B 模型作为语言模型。这是一个基于 GPT-3 架构复制品,针对 Pile 数据集进行过训练的模型。
GPT-Neo 是一个自回归语言模型 fθ,通过链式规则生成一系列token。
这个场景中,攻击者希望利用语言模型对训练数据的记忆,来尽可能准确地预测给定前缀的后缀。由于数据集中每个句子在训练集中只出现一次,这就给攻击者提供了一个机会,试图从模型中提取这些罕见句子的信息。
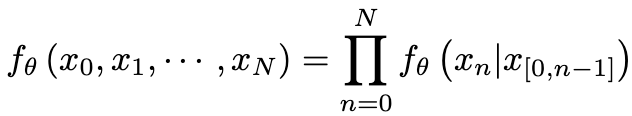
在句子层面,给定一个前缀p,我们表示在前缀p上有条件生成某个后缀s的概率为fθ(s|p)。
我们专注于针对性提取 κ-eidetic 记忆数据的威胁模型,我们选择 κ=1。根据 Carlini定义的模型知识提取,我们假设语言模型通过最可能的标准生成后缀 s。然后我们可以将针对性提取的正式定义写为:
给定一个包含在训练数据中的前缀 p 和一个预训练的语言模型 fθ。针对性提取是通过下式来生成后缀
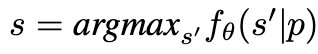
至于 κ-eidetic 记忆数据,我们遵循 Carlini的定义,即句子 [p, s] 在训练数据中出现不超过 κ 个示例。在实践中,生成句子的长度通常使用截断和连接技术固定在训练数据集上。如果生成的句子短于指定长度,使用填充 token 将其增加到所需长度。
流程
第一阶段 - 后缀生成:
-
利用自回归语言模型 fθ 计算词汇表中每个 token 的生成概率分布。
-
从这个概率分布中采样生成下一个 token,采用 top-k 策略限制采样范围,将 k 设为10。
-
不断重复这个采样过程,根据前缀生成一组可能的后缀。
第二阶段 - 后缀排名:
-
使用成员资格推断攻击,根据每个生成后缀的困惑度进行排序。
-
只保留那些概率较高(困惑度较低)的后缀。
这样的两阶段流程,首先利用语言模型生成可能的后缀候选,然后通过成员资格推断攻击对这些候选进行评估和筛选,从而尽可能还原出训练数据中罕见的完整句子。
这个训练数据提取攻击的关键在于,利用语言模型对训练数据的"记忆"来生成接近训练样本的内容,再结合成员资格推断技术进一步挖掘出高概率的真实训练样本。
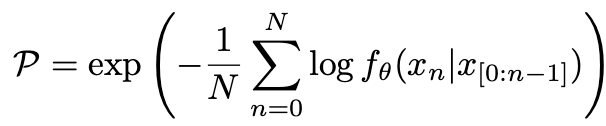
其中 N 是生成句子中的 token 数量。
改进策略
为了改进后缀生成,我们可以来看看真实和生成token的logits分布。如下图所示,这两种分布之间存在显著差异。
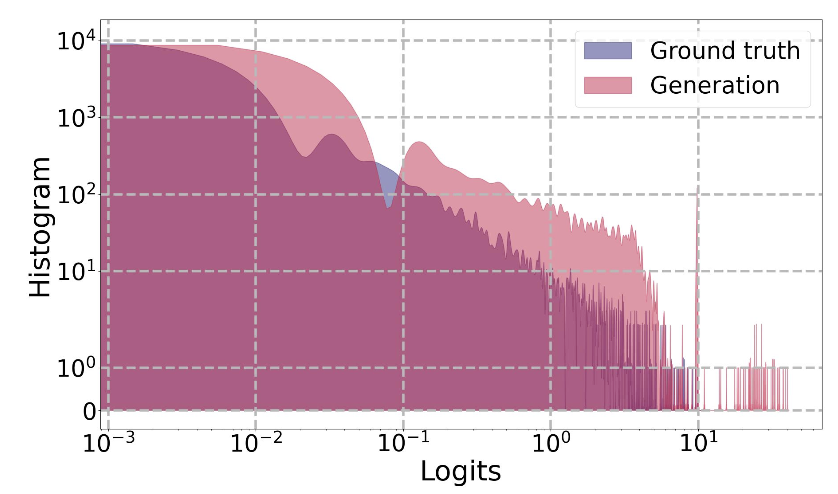
为了解决这个问题,我们可以采用一系列技术进行改进
采样策略
在自然语言处理的条件生成任务中,最常见的目标是最大化解码,即给定前缀,找到具有最高概率的后缀序列。这种"最大似然"策略同样适用于训练数据提取攻击场景,因为模型会试图最大化生成的内容与真实训练数据的相似性。
然而,从模型中直接找到理论上的全局最优解(argmax序列)是一个不切实际的目标。原因在于,语言模型通常是auto-regressive的,每个token的生成都依赖于前面生成的内容,因此搜索全局最优解的计算复杂度会随序列长度呈指数级上升,实际上是不可行的。
因此,常见的做法是采用束搜索(Beam Search)作为一种近似解决方案。束搜索会在每一步保留若干个得分最高的部分解,而不是简单地选择概率最高的单一路径。这种方式可以有效降低计算复杂度,但同时也存在一些问题:
-
束搜索可能会缺乏生成输出的多样性,因为它总是倾向于选择得分最高的少数几个路径。
-
尽管增大束宽度可以提高性能,但当束宽超过一定程度时,性能增益会迅速下降,同时也会带来更高的内存开销。
为了克服束搜索的局限性,我们可以采用随机采样的方法,引入更多的多样性。常见的采样策略包括:
-
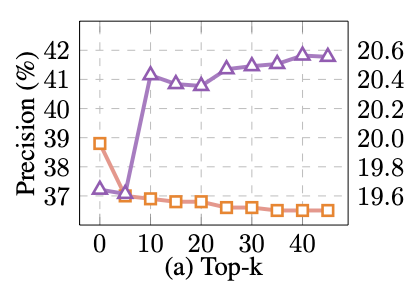
Top-k 采样:只从概率最高的k个token中进行采样,k是一个超参数。这种方法可以控制生成输出的多样性,但过大的k可能会降低输出的质量和准确性。
-
Nucleus 采样(Nucleus Sampling):从概率总和达到设定阈值的token集合中进行采样,可以自适应地调整采样空间的大小。
-
典型采样(Typical Sampling):从完整的概率分布中采样,偏向采样接近平均概率的token,可以在保持输出质量的同时引入更多的多样性。
总的来说,条件生成任务中的解码策略需要在生成质量、多样性和计算复杂度之间进行权衡。束搜索作为一种近似解决方案,能够有效控制计算成本,但缺乏生成多样性。而随机采样方法则可以引入更多的多样性,但需要在采样策略上进行细致的调整。这些技术在训练数据提取攻击中都有重要的应用价值。
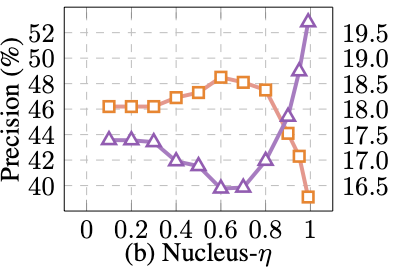
Nucleus采样的核心思想是从总概率达到一定阈值η的token集合中进行采样,而不是简单地从概率最高的k个token中采样。
在故事生成任务中,研究表明较低的η值(如0.6左右)更有利于生成更为多样化和创造性的内容。这说明在生成任务中,保留一定程度的低概率token是有益的,可以引入更多的多样性。但在训练数据提取攻击这样的任务中,较大的η值(约0.6)效果更好,相比基线提升了31%的提取精度。这表明对于数据提取这类任务,我们需要更加关注生成内容与训练数据的相似性,而不是过度强调多样性。
如下图示进一步说明了这一点,即η值过大或过小都会导致性能下降。存在一个最优的η值区间,需要根据具体任务进行调整。
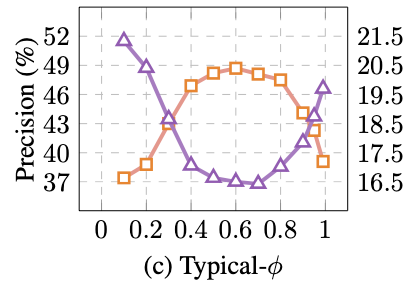
Typical-ϕ是一种用于自然语言生成任务的采样策略。它的核心思想是选择与预期输出内容相似的token,从而保证在典型解码中能够考虑到原始分布的概率质量。这种策略可以提高生成句子的一致性,同时减少一些容易出现的退化重复等问题。Typical-ϕ 策略在数学上等价于一个带有熵率约束的子集优化问题。这种策略在一定程度上可以控制生成文本的多样性和流畅性,平衡了文本质量和创造性。
Typical-ϕ 策略在不同任务中表现可能会有所不同。例如,在抽象摘要和故事生成任务中,Typical-ϕ 策略展现出一定的非单调趋势,即随着ϕ值的变化,生成文本的质量并非线性提升。这说明Typical-ϕ需要根据具体任务进行合适的参数调整,以达到最佳的生成效果。
概率分布调整
温度控制(Temperature)
-
这是一种直接调整概率分布的策略,通过引入温度参数T来重新归一化语言模型的输出概率分布。较高的温度T > 1会降低模型预测的确信度,但可以增加生成文本的多样性。研究发现,在生成过程中逐渐降低温度是有益的,可以在多样性和生成效率之间达到平衡。但过高的温度也可能导致生成的文本偏离真实分布,降低效率。因此需要合理调节温度参数。
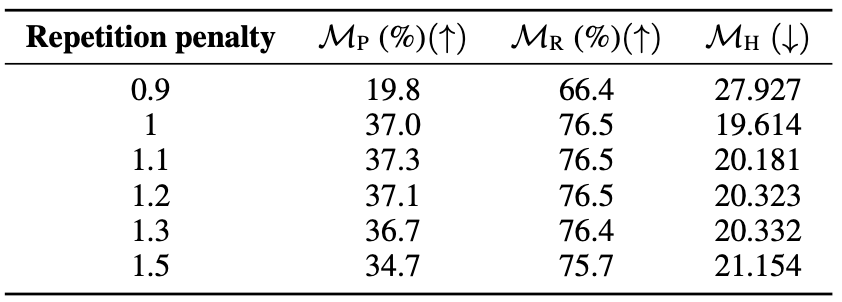
重复惩罚(Repetition Penalty)
-
这是一种基于条件语言模型的策略,通过修改每个token的生成概率来抑制重复token的出现。具体做法是,重复token的logit在进入softmax层之前被除以一个值r。当r > 1时会惩罚重复,r < 1则会鼓励重复。研究发现,重复惩罚对训练数据提取任务通常有负面影响,因为它可能会抑制一些有用的重复信息。因此在使用重复惩罚时,需要根据具体任务和数据特点来合理设置参数r,在抑制不必要重复和保留有意义重复之间寻求平衡。
总的来说,温度控制和重复惩罚是两种常见的直接调整概率分布的策略,可以在一定程度上提高自然语言生成的质量和多样性。但它们也存在一些局限性,需要根据实际应用场景进行合理的参数调整和组合使用,以达到最佳的生成效果。
为了有效的向量化,通常在训练语言模型时将多个句子打包成固定长度的序列。例如,句子"Yu的电话号码是12345"可能在训练集中被截断,或与另一个句子拼接成前缀,如"Yu的地址在XXX。Yu的电话号码是12345"。训练集中的这些前缀序列并不总是完整的句子。为了更好地模拟这种训练设置,我们可以调整上下文窗口大小和位置偏移。
动态上下文窗口
训练窗口的长度可能与提取窗口的长度不同。因此,提出调整上下文窗口的大小,即之前生成的token的数量,如下所示。
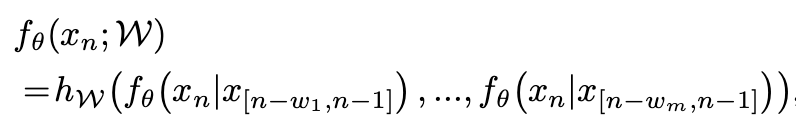
此外,鼓励不同上下文窗口大小的结果在确定下一个生成的token时进行协作:
其中 hW 表示集成方法,W 表示集成超参数,包括不同上下文窗口大小的数量 m 和每个窗口大小 w_i。我们在代码中使用 m = 4 和 w_i ∈ {n, n - 1, n - 2, n - 3}。
动态位置偏移
位置嵌入被添加到像 GPT-Neo 这样的模型中的 token 特征中。在训练过程中,这是按句子批次添加的,导致相同的句子在不同的训练批次和生成过程中具有不同偏移的位置嵌入。
为了改进对记忆后缀的提取,可以通过评估不同偏移位置并选择 "最佳" 的一个来恢复训练期间使用的位置。具体来说,对于给定的前缀 p,评估不同的偏移位置 C = c_i,其中 c_i 是一系列连续自然数的列表,c_i = {c_i1, ...},使得 |c_i| = |p|,并计算相应的困惑度值。然后选择具有最低困惑度值的位置作为生成后缀的位置。
通过评估不同的位置偏移来选择最佳的位置嵌入,来提高模型对记忆后缀的提取能力。这种方法可以很好地补充原有的位置嵌入方法,增强模型的性能。
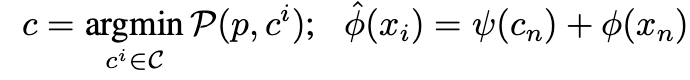
其中 ψ(·) 表示位置编码层,φ(·) 表示特征映射函数,
标签:训练,后缀,模型,生成,token,隐私,复现,序列,泄露 From: https://www.cnblogs.com/hetianlab/p/18393960