前言 本文分享论文Diffusion Feedback Helps CLIP See Better,专注于通过自监督学习范式解决CLIP无法区分细粒度视觉细节的问题。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
本文转载自我爱计算机视觉
仅用于学术分享,若侵权请联系删除
招聘高光谱图像、语义分割、diffusion等方向论文指导老师

- 作者:王文轩(中科院自动化所-智源研究院联培博一研究生),孙泉(智源研究院视觉模型研究中心算法研究员),张帆(智源研究院视觉模型研究中心算法研究员),唐业鹏(北交博一研究生),刘静(中科院自动化所研究员),王鑫龙(智源研究院视觉模型研究中心负责人)
- 单位:中科院自动化所,中国科学院大学,北京智源人工智能研究院,北京交通大学
- 论文链接:https://arxiv.org/abs/2407.20171
- 项目主页:https://rubics-xuan.github.io/DIVA/
- 相关代码链接:https://github.com/baaivision/DIVA
动机何在?——CLIP视觉缺陷
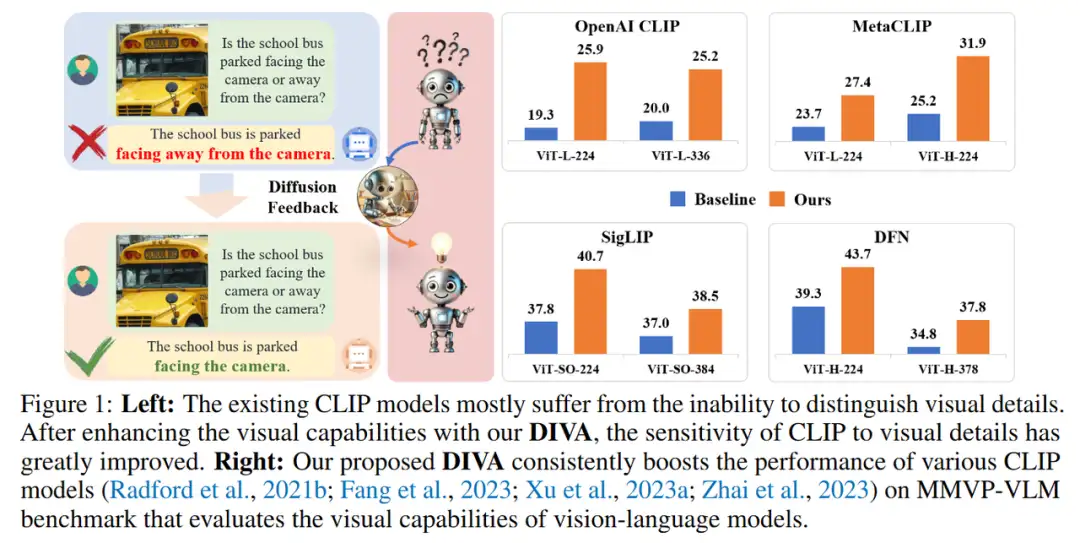
对比语言-图像预训练(CLIP)在跨领域和跨模态的开放世界表示方面表现出色,已成为各种视觉和多模态任务的基础。
自从CLIP被提出以来,近年来涌现了许多关于CLIP模型的后续研究。这些研究通过预训练和微调CLIP模型,取得了性能提升并开发了新的能力。然而,这些方法仍然存在不可避免的局限性,因为它们高度依赖于图像-文本数据对,无法仅在图像数据上实现预期效果。
此外,最近的不少研究指出,尽管CLIP在零样本任务中表现出色,但由于对比学习范式和训练中使用的噪声图像-文本对,其在感知理解方面存在一些局限性。这些局限性包括难以准确理解长文本和难以辨别相似图像中的细微差异。虽然一些研究试图解决长文本理解问题,但改善CLIP的细粒度视觉感知能力的研究仍然不足。感知视觉细节的能力对于基础模型至关重要,而CLIP在这方面的不足直接影响了以CLIP作为视觉编码器的视觉和多模态模型的表现。
因此,在这项工作中,我们专注于通过自监督学习范式解决CLIP无法区分细粒度视觉细节的问题。基于文本到图像的扩散模型能够生成具有丰富细节逼真图像的先验,我们探索了利用扩散模型的生成反馈来优化CLIP表征的潜力。
如何解决?——Diffusion Feedback来优化CLIP视觉细节表征
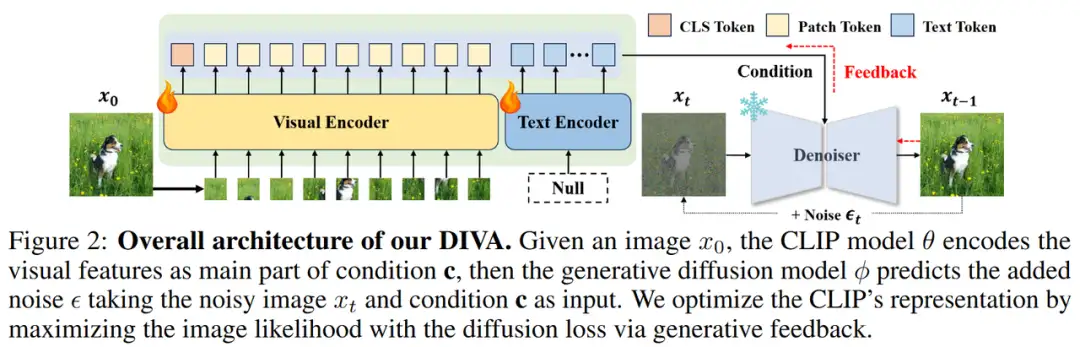
我们提出了一种简单的CLIP模型后训练方法,通过自监督扩散过程在很大程度上克服了其视觉缺陷。通过使用CLIP的密集视觉特征对扩散模型进行条件化,并将重建损失应用于CLIP优化,我们将扩散模型作为CLIP的视觉助手,因此我们将该框架命名为DIVA。
具体而言,如图2所示,DIVA主要由两个部分组成:一是需要增强视觉感知能力的CLIP模型,二是提供生成反馈的预训练扩散模型。输入原始图像和空文本(图2中标记为'Null')后,CLIP模型会编码相应的视觉特征,这些特征将与来自扩散模型文本编码器的空文本嵌入结合,为扩散过程提供条件。对于添加了噪声的图像,扩散模型尝试在上述条件下预测从前一步到当前步骤中添加的噪声。在训练过程中,除了CLIP模型外,所有部分的权重都保持不变,训练目标只是最小化重建损失(即扩散反馈指导)。通过这种方式,通过约束扩散模型更准确地预测添加的噪声,CLIP的原始语义丰富的判别表示将通过扩散反馈逐渐优化为包含更多视觉细节的表示。
此外更有意思的是,DIVA不需要额外的文本标注数据,只需可轻易获取的纯图片数据就能大幅使得CLIP弥补其视觉感知短板,这一点相比之前方法收集大量图文数据对的高昂成本是非常难得的!
效果如何?——立竿见影!
为了评估DIVA的有效性并展示其增强CLIP表示的潜力,我们在多模态理解和视觉感知任务上进行了全面的实验。
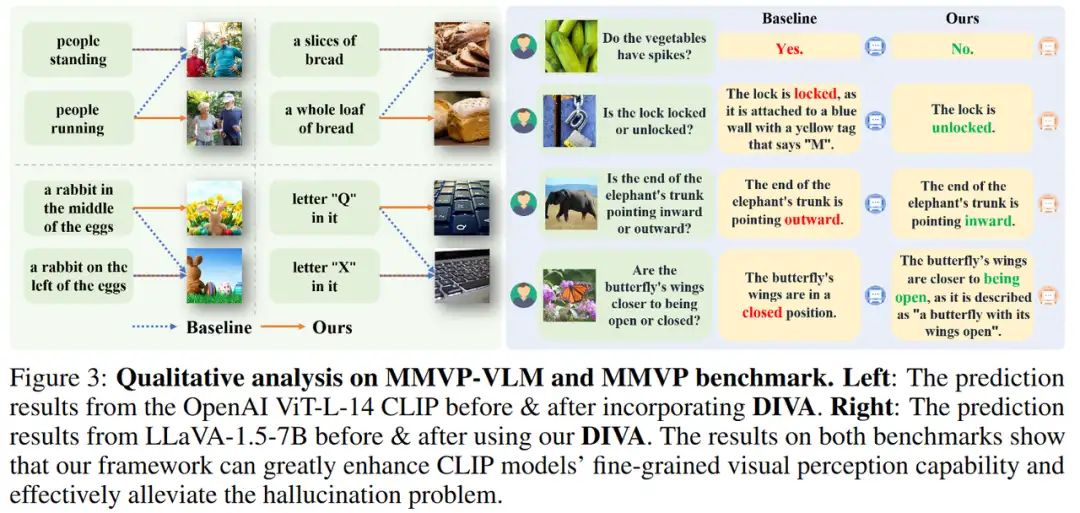
视觉细粒度感知方面
为了验证DIVA能够有效缓解CLIP模型固有的视觉能力不足,我们首先在各种现有的CLIP模型上进行了实验。DIVA在评估视觉-语言模型视觉能力的MMVP-VLM基准测试中使得现有的多个CLIP模型的性能取得了显著的提升(提高了3-7%)。
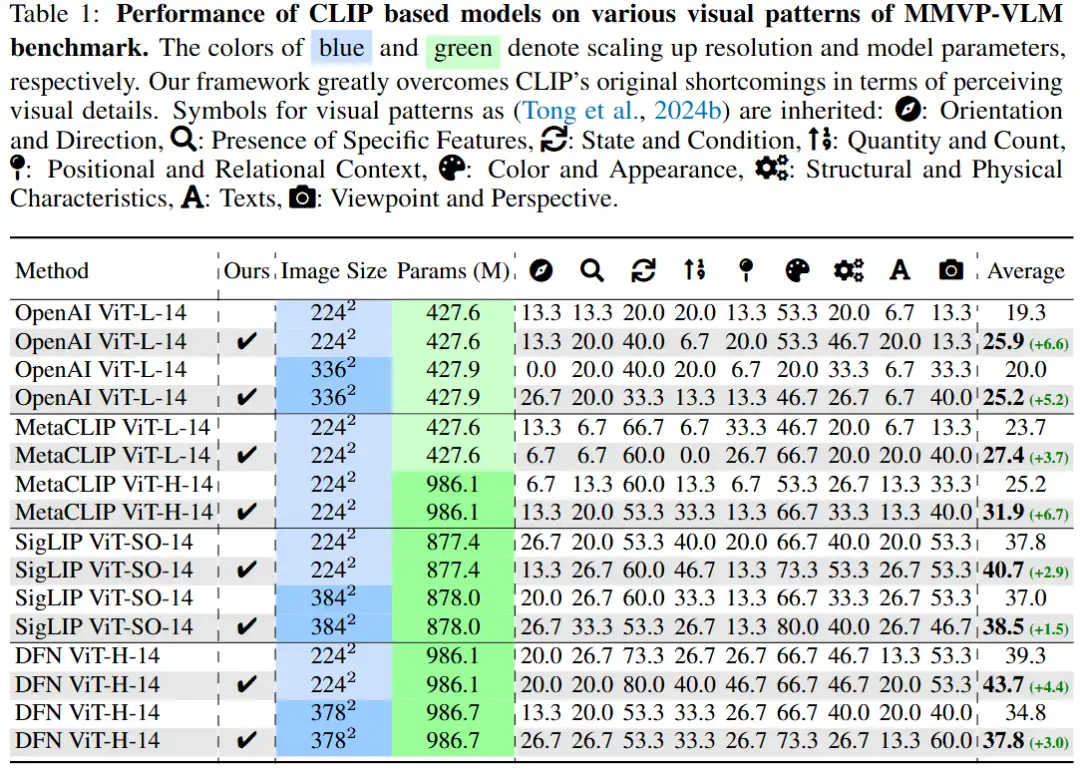
作为更强的视觉骨干网络为多模态大模型和视觉模型带来的收益评估
接下来,在DIVA的帮助下,我们进一步评估了增强后的CLIP骨干网络在多模态理解和视觉感知任务中带来的性能提升。DIVA的优势在于它不仅仅能让CLIP变聪明,还能让那些基于CLIP的大型多模态语言模型以及视觉模型变得更加厉害。在这些多模态和纯视觉的基准测试上准确率的显著提升,得益于我们DIVA范式通过生成反馈大幅增强了CLIP的视觉感知能力。
CLIP泛化能力评估
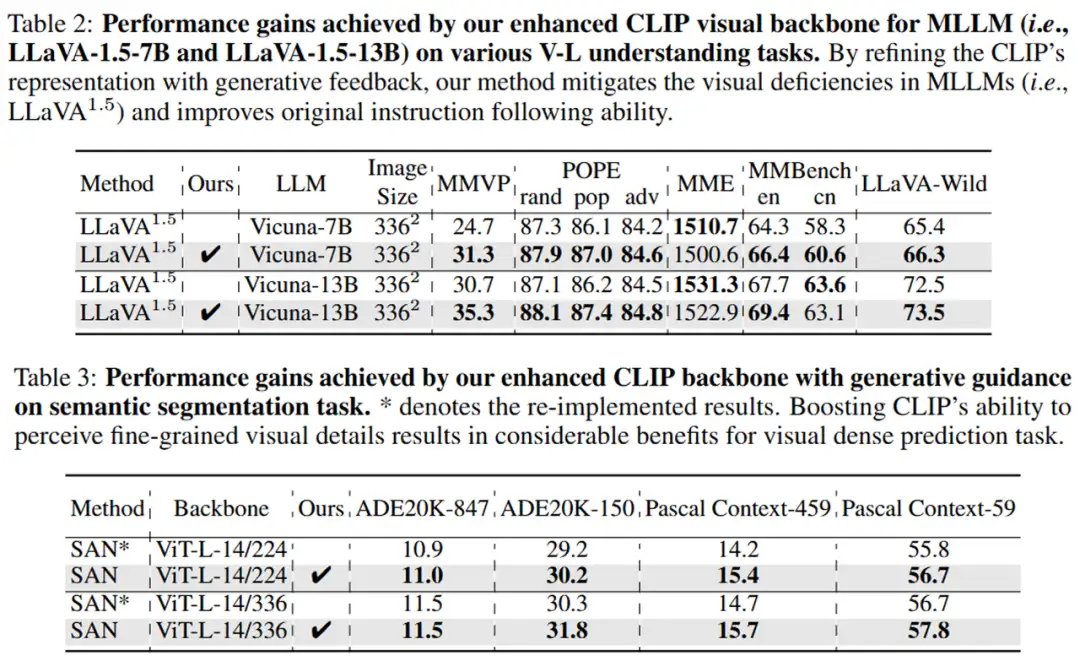
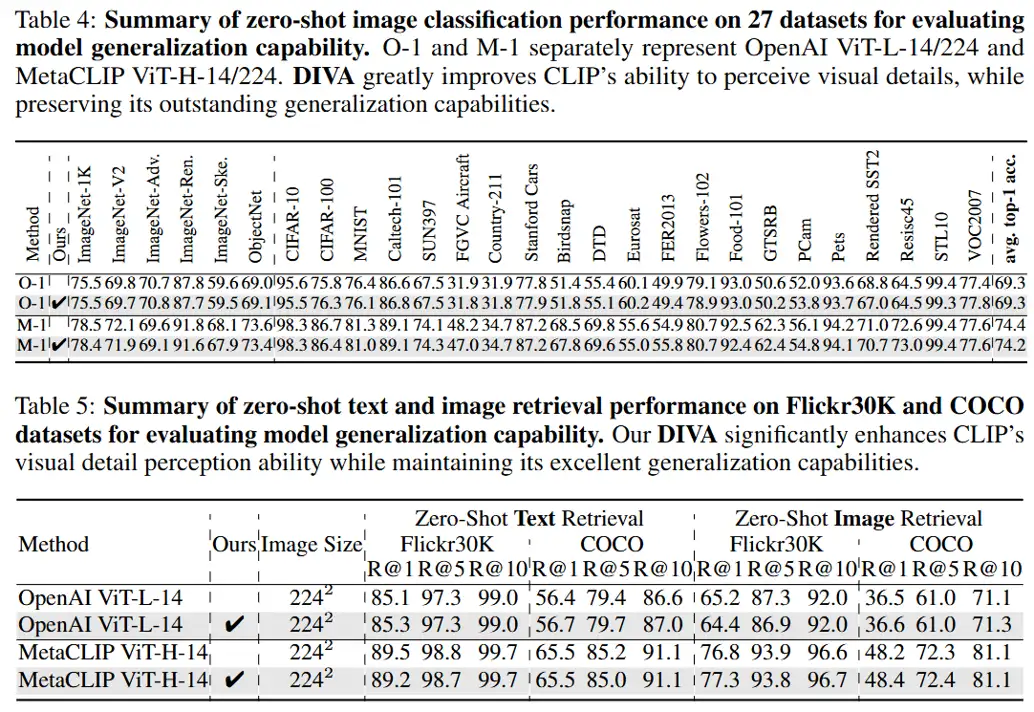
在全面验证了我们的方法提升CLIP模型细粒度视觉感知能力的效果后,我们进行了CLIP模型原始泛化能力的全面评估。在只由纯图片数据驱动整个框架的前提上,DIVA能够保持CLIP原本优秀的泛化性能。29个图片分类和图文检索的基准测试上无论是看图识物还是找图配字的实验结果都能证明,经过DIVA优化视觉表征之后的CLIP模型能够保留CLIP原本优秀的泛化能力。
未来展望?——大有可为!
当前局限
- 数据和模型规模可进一步扩展。
- 由于这篇工作只是该方向的一个开始,目前仅展示了生成扩散模型用于提升CLIP模型表示的潜力,当前主要关注设计一个简单但有效的框架。
未来可探讨的方向
- 可以结合更细粒度的监督方案进一步提升CLIP模型的能力。
- 扩展超越图像-文本数据的其他模态,如视频和音频。
- 发展基于扩散模型的更通用、更强大的框架,以增强视觉-语言基础模型
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
LSKA注意力 | 重新思考和设计大卷积核注意力,性能优于ConvNeXt、SWin、RepLKNet以及VAN
CVPR 2023 | TinyMIM:微软亚洲研究院用知识蒸馏改进小型ViT
ICCV2023|涨点神器!目标检测蒸馏学习新方法,浙大、海康威视等提出
ICCV 2023 Oral | 突破性图像融合与分割研究:全时多模态基准与多交互特征学习
HDRUNet | 深圳先进院董超团队提出带降噪与反量化功能的单帧HDR重建算法
南科大提出ORCTrack | 解决DeepSORT等跟踪方法的遮挡问题,即插即用真的很香
1800亿参数,世界顶级开源大模型Falcon官宣!碾压LLaMA 2,性能直逼GPT-4
SAM-Med2D:打破自然图像与医学图像的领域鸿沟,医疗版 SAM 开源了!
GhostSR|针对图像超分的特征冗余,华为诺亚&北大联合提出GhostSR
Meta推出像素级动作追踪模型,简易版在线可玩 | GitHub 1.4K星
CSUNet | 完美缝合Transformer和CNN,性能达到UNet家族的巅峰!
AI最全资料汇总 | 基础入门、技术前沿、工业应用、部署框架、实战教程学习
标签:Diffusion,模态,CLIP,模型,DIVA,图像,视觉 From: https://www.cnblogs.com/wxkang/p/18389169