插入排序详细解读
图解
第一轮:从第二位置的 6 开始比较,比前面 7 小,交换位置。
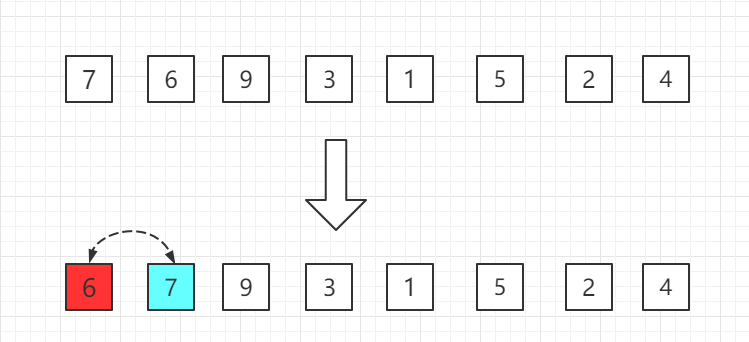
第二轮:第三位置的 9 比前一位置的 7 大,无需交换位置。

第三轮:第四位置的 3 比前一位置的 9 小交换位置,依次往前比较。
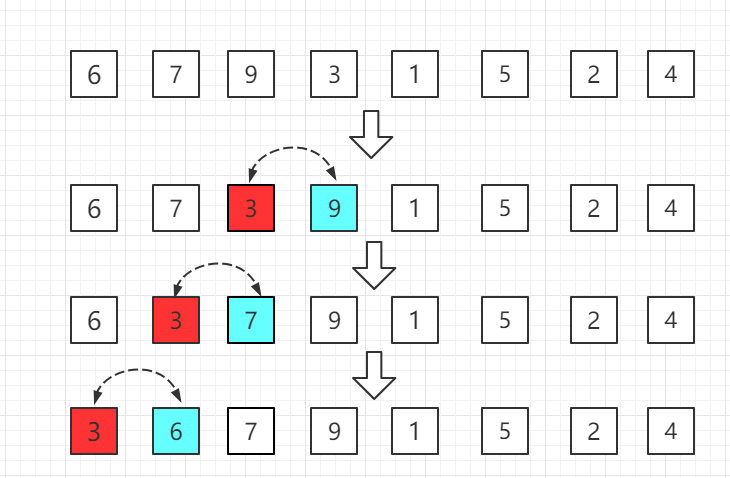
第四轮:第五位置的 1 比前一位置的 9 小,交换位置,再依次往前比较。
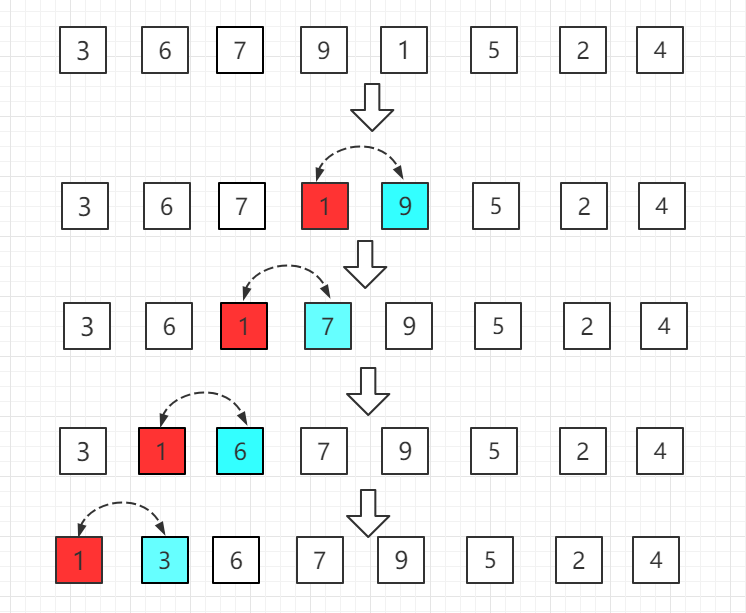
......
就这样依次比较到最后一个元素。
步骤解读:
STEP 1:【模拟后面待排序元素】
我们需要有一个外层循环,来不断的将后面新的待排元素进行变换,会不断的取第二个,取第三个.......;(待排元素可以从索引1开始,因为索引1左侧就一个数据,是索引0是有顺序的)
#include<iostream>
using namespace std;
int main() {
int arr[100] = {7, 6, 9, 3, 1, 5, 2, 4};
for (int i = 1; i <= 7; i++) {
}
}
STEP 2:【用j变量来记录排好序列部分的最后一个位置】
接下来我们需要定义一个变量j来记录我们的合适位置,(这个j变量会拥有一个特点,什么特点呢?i刚刚已经写了是索引1,j的话就是索引0开始,所以一开始就是i-1),待排序的元素就是已经吸收了arr[i]的变量key
#include<iostream>
using namespace std;
int main() {
int arr[100] = {7, 3, 5, 5, 6, 0, 8};
for (int i = 1; i <= 6; i++) {
int key = arr[i];
int j = i-1;
}
}
STEP 3:【启动条件&启动后模拟值的交换过程】
书写我们的启动条件,如果当前这个元素比前一个元素小,呢就往前放;写成代码就是if(arr[j] > key)
达成这个条件后我们开始比较操作;
操作的主要内容是:(1.交换元素位置 2.寻找合适位置(变量j的值能体现,因为在不断的变小,往前去找))
#include<iostream>
using namespace std;
int main() {
int arr[100] = {7, 3, 5, 5, 6, 0, 8};
for (int i = 1; i <= 6; i++) {
int key = arr[i];
int j = i-1;
while (arr[j] > key) {
arr[j+1] = arr[j];
j--;
}
}
}
STEP 4:【回首掏,有几个情况需要考虑】
对于第三步,我们反思一下可能会出现几个问题:
- 【最后元素缺失】后面的值被前面的值覆盖,刚刚为key的位置元素没了,所以我们需要用
arr[j + 1] = key;来给他补上 - 【历史最小元素,防止数组越界】加入出现了一个,“历史最小元素”,你要排到索引0这个位置,你不可能排到-1嘛,否则将会出现数组的索引错误。我们需要在判断条件上加上
j >= 0 - 这个时候我再来解释一下key为什么会被用到,因为第一条问题【最后元素缺失】
#include<iostream>
using namespace std;
int main() {
int arr[100] = {7, 3, 5, 5, 6, 0, 8};
for (int i = 1; i <= 6; i++) {
int key = arr[i];
int j = i-1;
while (j >= 0 && arr[j] > key) {
arr[j+1] = arr[j];
j--;
}
//while 结束之后key的位置就找到了
arr[j + 1] = key;
//但是此时,j+1会被覆盖
}
}
至此排序完成,自己输出就好了!
标签:arr,元素,key,int,插入排序,位置,解读,索引,详细 From: https://www.cnblogs.com/bianchengxue/p/18372687