二叉树遍历
分为前序、中序、后续、层序四种
其中前中后序属于深度优先搜索,层序属于广度优先搜索
前序遍历顺序:
根节点->左子树->右子树
中序遍历顺序:
左子树->根节点->右子树
后序遍历顺序:
左子树->右子树->根节点
不难发现,前中后其实就是根节点在遍历中的位置
至于层序遍历,顾名思义,就是一层一层的从左到右遍历
递归遍历(前中后)
- 确定递归函数的参数和返回值:因为要打印出前序遍历节点的数值,所以参数里需要传入vector来放节点的数值,除了这一点就不需要再处理什么数据了也不需要有返回值,所以递归函数返回类型就是void。
- 确定终止条件:在递归的过程中,如何算是递归结束了呢,当然是当前遍历的节点是空了,那么本层递归就要结束了,所以如果当前遍历的这个节点是空,就直接return。
- 确定单层递归的逻辑:前序遍历是中左右的顺序,所以在单层递归的逻辑,是要先取中节点的数值。
上代码(●'◡'●)
前序:
class Solution {
public:
void traversal(TreeNode* cur, vector<int>& vec) {
if (cur == NULL) return;
vec.push_back(cur->val); // 中
traversal(cur->left, vec); // 左
traversal(cur->right, vec); // 右
}
vector<int> preorderTraversal(TreeNode* root) {
vector<int> result;
traversal(root, result);
return result;
}
};
中序:
class Solution {
public:
void traversal(TreeNode* cur, vector<int>& vec) {
if (cur == NULL) return;
traversal(cur->left, vec); // 左
vec.push_back(cur->val); // 中
traversal(cur->right, vec); // 右
}
vector<int> inorderTraversal(TreeNode* root) {
vector<int> result;
traversal(root, result);
return result;
}
};
后序:
class Solution {
public:
void traversal(TreeNode* cur, vector<int>& vec) {
if (cur == NULL) return;
traversal(cur->left, vec); // 左
traversal(cur->right, vec); // 右
vec.push_back(cur->val); // 中
}
vector<int> postorderTraversal(TreeNode* root) {
vector<int> result;
traversal(root, result);
return result;
}
};
迭代遍历(前中后)
递归的底层实现其实就是栈
所以我们可以用栈来实现二叉树的前中后序遍历
但是由于会比较麻烦,三种遍历没法统一,所以我们来看另一种方法:
使用栈的话,无法同时解决访问节点(遍历节点)和处理节点(将元素放进结果集)不一致的情况。
那我们就将访问的节点放入栈中,把要处理的节点也放入栈中但是要做标记。
如何标记呢,就是要处理的节点放入栈之后,紧接着放入一个空指针作为标记。 这种方法也可以叫做标记法。
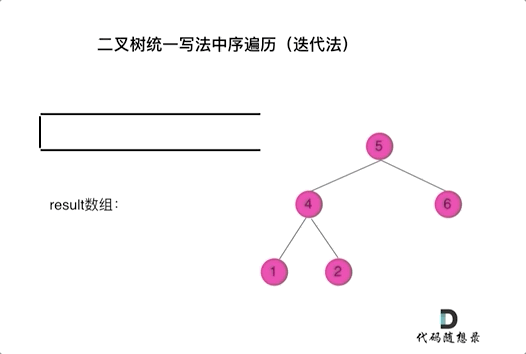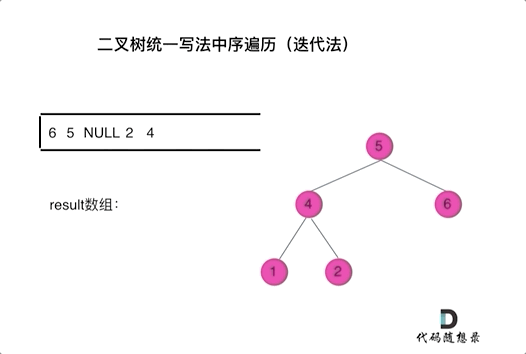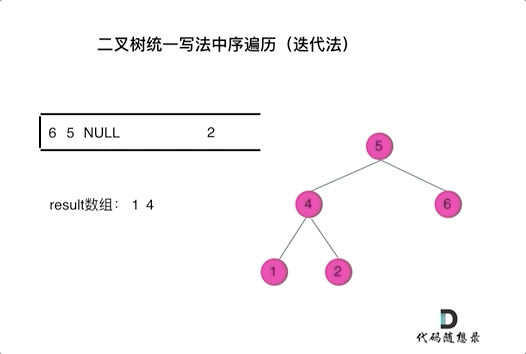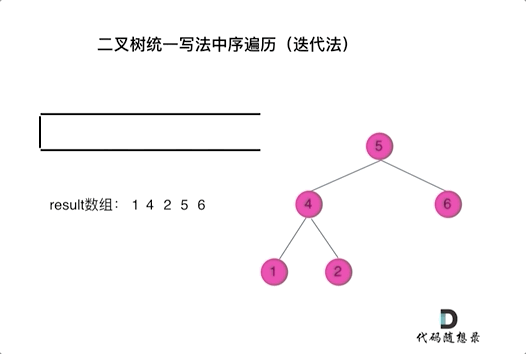
可以看出我们将访问的节点直接加入到栈中,但如果是处理的节点则后面放入一个空节点, 这样只有空节点弹出的时候,才将下一个节点放进结果集。
上代码(●'◡'●)
前序:
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
vector<int> result;
stack<TreeNode*> st;
if (root != NULL) st.push(root);
while (!st.empty()) {
TreeNode* node = st.top();
if (node != NULL) {
st.pop();
if (node->right) st.push(node->right); // 右
if (node->left) st.push(node->left); // 左
st.push(node); // 中
st.push(NULL);
} else {
st.pop();
node = st.top();
st.pop();
result.push_back(node->val);
}
}
return result;
}
};
中序:
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
vector<int> result;
stack<TreeNode*> st;
if (root != NULL) st.push(root);
while (!st.empty()) {
TreeNode* node = st.top();
if (node != NULL) {
st.pop(); // 将该节点弹出,避免重复操作,下面再将右中左节点添加到栈中
if (node->right) st.push(node->right); // 添加右节点(空节点不入栈)
st.push(node); // 添加中节点
st.push(NULL); // 中节点访问过,但是还没有处理,加入空节点做为标记。
if (node->left) st.push(node->left); // 添加左节点(空节点不入栈)
} else { // 只有遇到空节点的时候,才将下一个节点放进结果集
st.pop(); // 将空节点弹出
node = st.top(); // 重新取出栈中元素
st.pop();
result.push_back(node->val); // 加入到结果集
}
}
return result;
}
};
后序:
class Solution {
public:
vector<int> postorderTraversal(TreeNode* root) {
vector<int> result;
stack<TreeNode*> st;
if (root != NULL) st.push(root);
while (!st.empty()) {
TreeNode* node = st.top();
if (node != NULL) {
st.pop();
st.push(node); // 中
st.push(NULL);
if (node->right) st.push(node->right); // 右
if (node->left) st.push(node->left); // 左
} else {
st.pop();
node = st.top();
st.pop();
result.push_back(node->val);
}
}
return result;
}
};
统一的代码模式,看着确实舒服 d=====( ̄▽ ̄*)b
层序遍历
层序遍历一个二叉树。就是从左到右一层一层的去遍历二叉树。这种遍历的方式和之前的都不太一样。
需要借用一个辅助数据结构即队列来实现,队列先进先出,符合一层一层遍历的逻辑,而用栈先进后出适合模拟深度优先遍历也就是递归的逻辑。
而这种层序遍历方式就是图论中的广度优先遍历,只不过我们应用在二叉树上。
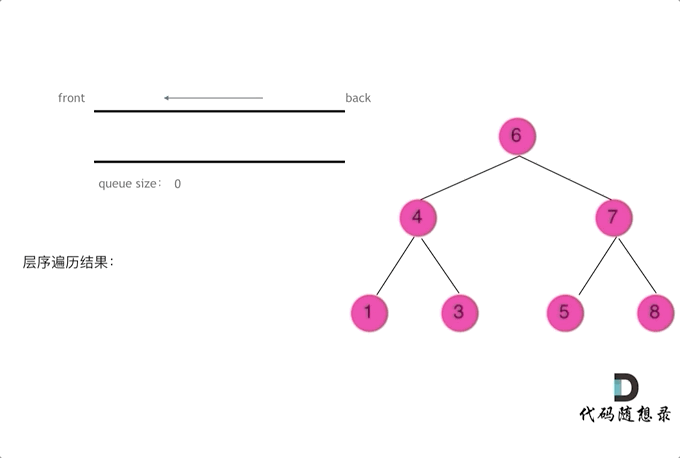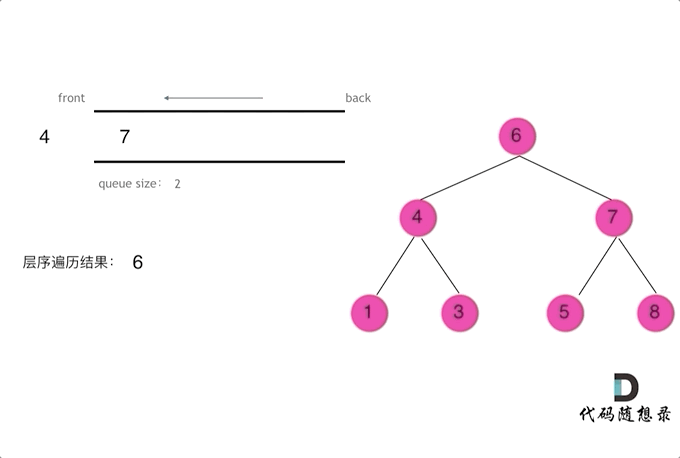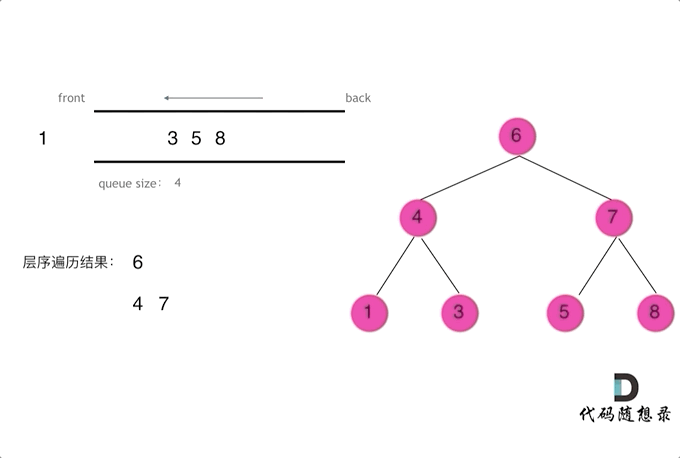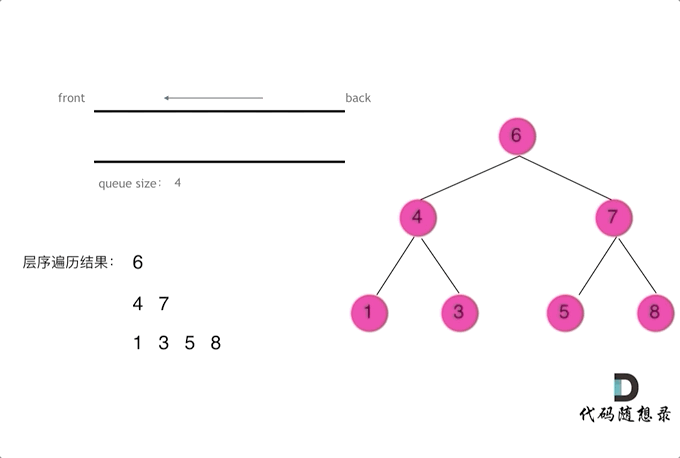
上代码(●'◡'●)
迭代:
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root) {
queue<TreeNode*> que;
if (root != NULL) que.push(root);
vector<vector<int>> result;
while (!que.empty()) {
int size = que.size();
vector<int> vec;
// 这里一定要使用固定大小size,不要使用que.size(),因为que.size是不断变化的
for (int i = 0; i < size; i++) {
TreeNode* node = que.front();
que.pop();
vec.push_back(node->val);
if (node->left) que.push(node->left);
if (node->right) que.push(node->right);
}
result.push_back(vec);
}
return result;
}
};
递归:
class Solution {
public:
void order(TreeNode* cur, vector<vector<int>>& result, int depth)
{
if (cur == nullptr) return;
if (result.size() == depth) result.push_back(vector<int>());
result[depth].push_back(cur->val);
order(cur->left, result, depth + 1);
order(cur->right, result, depth + 1);
}
vector<vector<int>> levelOrder(TreeNode* root) {
vector<vector<int>> result;
int depth = 0;
order(root, result, depth);
return result;
}
};
写博不易,请大佬点赞支持一下8~
标签:node,代码,随想录,st,vector,result,Day12,push,节点 From: https://www.cnblogs.com/Murder-sans/p/18355719/dmsxl_Day12