1. 物理存储结构
Postgresql数据库目前不支持裸设备和块设备,在Postgresql数据库中表的数据时存放在一个或者多个物理的数据文件中。而相应的数据文件又分多个固定大小的数据块,数据就放在数据块中。
1.Postgresql数据库中术语
Postgresql数据库与其他数据库不同,对于如表,数据行的称呼如下:
(1)relation:表示表或索引,也就是oracle或MySQL中的table或index。
(2)tuple:表示表中的数据行,oracle中称为row。
(3)page:表示磁盘中的数据块。
(4)buffer:表示内存中的数据块。
2.数据块结构
数据块结构如下图所示:
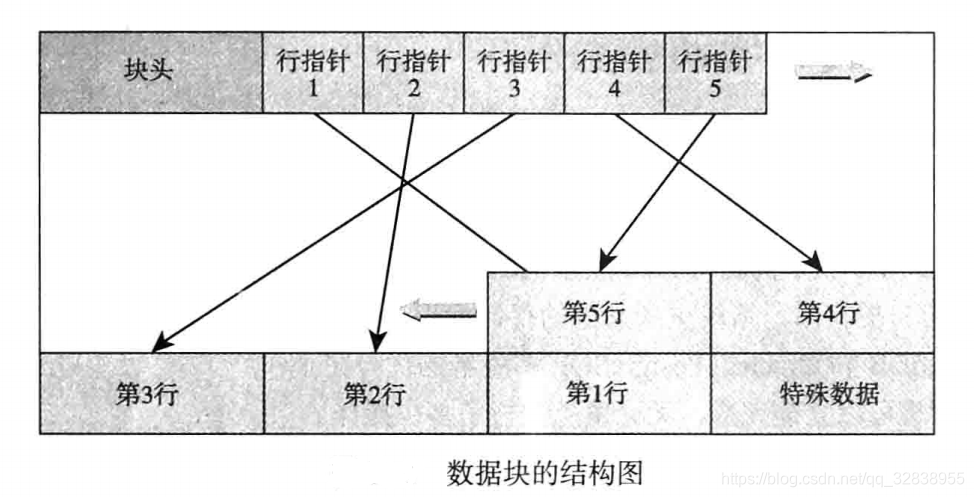
数据块的大小默认为8K,最大支持32K,一个数据块中可存放多行的数据,块中的结构是先有一个块头,其中记录这个数据块中各个数据行的指针,行指针是向后顺序排列的,而实际的数据行内容是从块尾向块头的方向反向排列的。行数据指针与数据行之间的部分则是空闲的空间。
块头记录如下信息:
(1)块的checksum值。
(2)空闲空间的起始位置和结束位置。
(3)特殊数据的起始位置。
(4)其他信息
行指针是一个32字节的数字,具体结构如下:
(1)行内容的偏移量,占15bit。
(2)指针的标记,占2bit。
(3)行内容的长度,占15bit。
行指针中表示行内容的偏移量是15bit,表示最大偏移量为2的15次方,也就是32768,所以在Postgresql中,块的最大大小为32768,也就是32KB。
3.tuple结构
在Postgresql数据库中的tuple就是指表中的数据行,结构如下图:
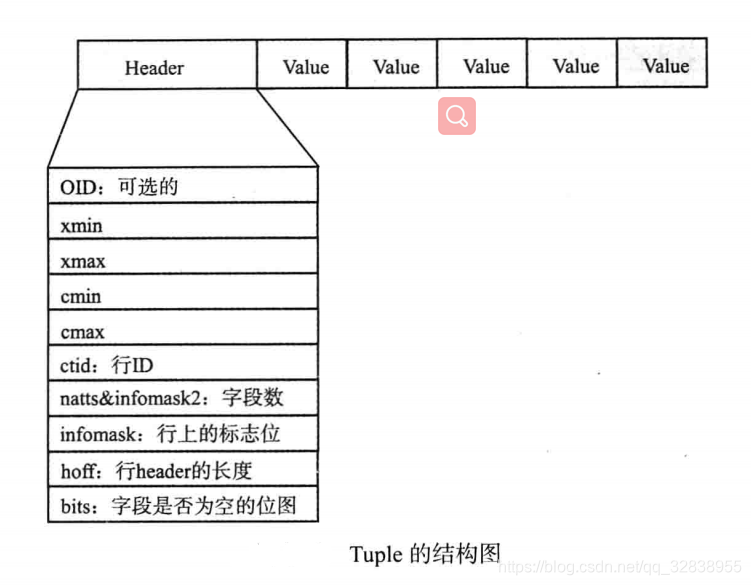
从上图看出,行的物理结构是先有一个行头,后面跟了各项数据。行头中记录了如下信息(只作为了解):
(1)oid、ctid、xmin、xmax、cmin、cmax。
(2)natts&infomask2:字段数。其中第11位表示这行有多少个列。其他位则是用于HOT(heap only touple)技术及行可见性的标志位。
(3)infomask:用于标识行当前的状态,比如行是否有oid,是否有空属性,供16位,每一位代表不同意思。
(4)hoff:表示行头的长度。
(5)bits:是一个数组,用于标识改行上哪些字段是空值。
4.数据块空闲空间管理
在表的数据块中插入、更新和删除数据时,会产生旧版本的数据,这些旧版本的数据通过vacuum进行清理,会在数据块中产生空间空间。在向表中插入新数据时,最好的办法是据需使用这些旧数据块中的空闲处的空间,如果给所有的新数据分配新的数据块会导致数据文件不断增大。当插入数据行时若多个数据块中有空闲空间,应把数据行查到其中那个数据块中呢?可以想象出,有的空间空间数据块不一定能存放下新数据行,因此想要插入一行数据时,首先需要快速定为空闲空间充足的数据块。
因此需要知道每个数据块的空闲空间的大小,并能够实现快速查找定为所需的数据块。
在Postgresql数据库中使用一个名为FSM的文件记录每个数据块的空闲空间。FSM-Free Space Map。
Postgresql为了缩小FSM文件的大小,使用1个字节记录数据块中的空闲空间,1字节表示的是空闲空间的范文:
| 字节值 | 表示空闲空间的范围(单位字节) |
|---|---|
| 0 | 0 ~ 31 |
| 1 | 32 ~ 63 |
| 2 | 64 ~ 95 |
| 3 | 96 ~ 127 |
| … | … |
| 255 | 8164 ~ 8192 |
从表格中看出,如果这个字节值为0,表示数据块中存在的空闲空间范围是 0-31个字节。以此类推。
在新版本的Postgresql数据库中对每个数据文件都会创建一个名为 “<表oid>_fsm” 的文件,例如一个表的oid为7844,那么它的fsm文件名就是 7844_fsm。
为了快速查找满足要求的数据块,Postgresql数据库使用了树形结构组织FSM文件。fsm文件固定使用三层树形结构,第0层和第1层为查找辅助层,第2层中每个块的每个字节代表其对应的数据块中的最大值。假设第2层的每个数据块都可以填4000个字节,则这4000个字节对应着在真正的数据文件中4000个数据块各有多个空闲空间,而第1层中的这个字节,则表示第2层中对应数据块中的最大值,也就是指对应到真正的数据文件中这4000个数据块最大的空闲空间,同时第0层中的每个字节表示的是下一层中数据块的最大值。第0层只有一个数据块,当需要判断数据块的空闲空间是否足够大时,只需要查询第0层的这个数据块,就可确定是否有合适的空闲空间的数据块了。
下面使用图示来理解以上的思路,为了简化理解,图中每个块只能放4个字节的数据有,原来与4000个字节一样:
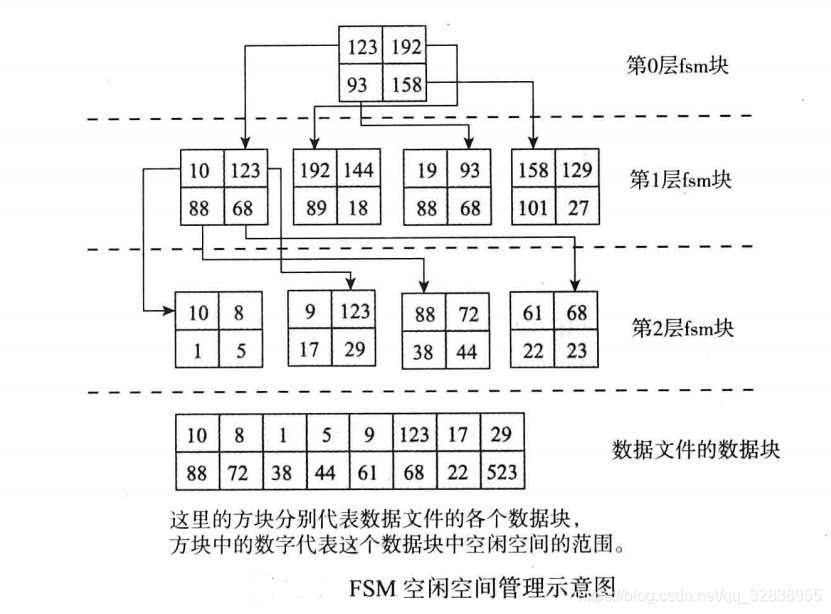
在图中,第0层的数据块中,4个字节中每个字节代表了第1层中一个数据块里4个字节数的中最大值,而第1层中每个数据块中4个字节每个字节数都代表第2层中一个数据块中4个字节的最大值,而第2层的数据块中4个字节中每个字节数字代表数据文件中数据块的空闲空间的范围(字节数和范围对应参考fsm文件解释)。第0层只有一个数据块,这个数据块中的第一个字节值为123,表示它下层,也就是第1层的第1个数据块中4个字节数最大值为123,。同样第0层的第2个字节值为192,表示它下层第2个数据块中4字节中最大值为192,以此类推。第1层与第2层也是如此映射。
FSM文件不是在创建表文件时就会立刻创建,而是等到需要时才会创建,如执行VACUUM操作时或者为了插入行而第一次查询FSM文件时才会创建。
示例
postgres=# create table test(id int,name varchar(75));
CREATE TABLE
postgres=# insert into test values (1,'zhang');
INSERT 0 1
postgres=# select oid from pg_class where relname='test';
oid
-------
25413
(1 row)
postgres=# \q
[postgres@local ~]$ ll /data/pgsql_data/base/13537/25413*
-rw------- 1 postgres postgres 8.0K Apr 11 16:20 /data/pgsql_data/base/13537/25413
查看数据目录中表数据文件时,只有表一个,没有fsm文件,然后对标做vacuum :
postgres=# vacuum test;
VACUUM
postgres=# \q
[postgres@local ~]$ ll /data/pgsql_data/base/13537/25413*
-rw------- 1 postgres postgres 8.0K Apr 11 16:20 /data/pgsql_data/base/13537/25413
-rw------- 1 postgres postgres 24K Apr 11 16:24 /data/pgsql_data/base/13537/25413_fsm
-rw------- 1 postgres postgres 8.0K Apr 11 16:24 /data/pgsql_data/base/13537/25413_vm
可以看到已经生成了fsm文件了,在看到fsm文件同时,也看到了一个以 _vm结尾的文件,它其实是可见性映射表文件。
5.可见性映射表文件
在Postgresql中更新、删除表中某行后,该行并不会马上从数据块中清理掉,而是需要等到执行vacuum命令后再清理,为了能加快VACUUM清理的速度和降低对系统IO的性能影响,Postgresql为每个数据文件加了一个后缀名为 _vm 的文件,这个文件被称为可见性映射表文件。简称VM文件。VM文件中为每个数据块设置了一个标志位,用来标记数据块中是否存在需要清理的行。有了这个文件后,通过使用VACUUM命令扫描这个文件时,如果发现VM文件中这个数据块上的位表示该数据块没有需要清理的行时,则会跳过对这个数据块的扫描,从而加快VACUUM清理的速度。
VACUUM清理数据有两种方式,一种称为“Lazy VACUUM”,另一种被称为“Full VACUUM”。VM文件仅在“Lazy VACUUM”中使用到。“Full VACUUM”操作则需要对整个数据文件进行扫描。
标签:文件,存储,Postgresql,字节,postgres,240704,数据,空闲,物理 From: https://www.cnblogs.com/zreo2home/p/18353388