前言

前言
此篇不是Stable Diffusion的软件教程,而是面向AIGC绘图工作流的一些开阔性思路与方法分享,核心观点即“商业需求是题面,AIGC是计算工具,解题思路还得是设计师!”,总之面对AIGC设计不要焦虑也不用回避,本篇笔者期望能够和大家一起探讨AIGC绘图如何为我所用,如何融入设计流程,如何降本增效。
并且会聊聊Stable Diffusion究竟具备了哪些可控能力,以及进行商业设计落地的思路与解题技巧,一切皆是希望能够帮助大家更好的认识AIGC绘图工具,并帮助优化自己的设计流程。
网上关于这方面的教程虽然很多,但都琐碎不够完整,无法系统且有效的学习,所以我们总结出一套可以在工作中应用到的系统完整的教学!

互联网企业对AIGC的痴迷
当下AIGC很火,以Chatgpt为代表的语言大模型,还有专注绘图领域的Midjourney与Stable Diffusion都很出名,甚至有企业宣称应用AI模型做CEO管理,虽然不知道员工服不服管,股东有没有意见,但可见2023很AI。
企业们又在期待AIGC能做些什么?
一、企业内部办公
期望借助AIGC降本增效,通过智能自动化的形式满足一些内容产出以减少人力的投入,从而将人力转移到其他更有价值或复杂的工作内容上,以实现降本增效的可能。

二、产品体验赋能
通过AIGC的场景化能力,赋予产品更智能更前沿的技术体验,从而产生更多的服务能力或是服务质量,并减少产品运营的成本。

三、技术创新性
随着深度学习、模型训练等,为企业提供更多定制化的技术应用或创新突破,为企业带来更多产品创新应用的可能,或是其他的正向收益。

Midjorney&Stable Diffusion
说到设计师,Midjourney跟Stable Diffusion总是要被提及,而作为一个交互设计师,我能用上的图形绘制部分就不多,所以有必要先了解一下AIGC绘图工具能做些什么了、能做到什么程度、能为你的工作做些什么,这很重要。从商业角度出发,笔者认为AIGC绘图更多的是应用到广告营销或艺术创作方面会多一些,就我当下尝试和了解到的应用场景与优势如下,可供参考;

Midjorney&Stable Diffusion特征差异
Midjourney是商业化产品、上手难度小、出图快、效果质量高,服务是端对端的形式,能够基于一个大模型快速响应各种风格或内容关键词的绘制,很适合在头脑风暴、寻觅风格参考的阶段花钱消灾,并且Midjourney的模型还在不断覆盖或更新事物关键词的理解,如果你怕麻烦并且设计需求不复杂,那么推荐Midjourney。
而SD(本篇中对Stable Diffusion的简称)典型的特征就是开源免费,社区共创扩展创新,本地化运算,有阶段化的可操控性,可以更好帮助设计师实现脑子里的创意,但有一定上手难度和设备局限,适合在复杂设计工作中更深入的探索应用。
用个不恰当的比喻,Midjourney跟SD就像是美图秀秀跟Photoshop的关系~

AIGC绘图的短板还很明显
给人很直观的感觉就是AIGC不懂设计,也不懂产品,还不好驯服,事实上目前AIGC绘图的商业能力还很有限,并且人机交互的沟通成本并不小(你要通过适当的关键词描述需求),当你不能熟悉关键词的应用以及AIGC绘制的功能操作方式时,开启AIGC绘图工具后就像是刚刚新建画板Photoshop,强大且不知所措,AIGC绘图工具的智能化、工业化、多模态交互、傻瓜式都还面临不少挑战。

为何考虑用SD做设计解题?
我简单概括为三个方面:成本更低、可控性更高、有更多的可能性
一、成本更低
成本一直是企业或个人关心的问题,在AIGC绘图生成的过程中充满了太多的不确定性了,市面上大多AIGC绘图工具都是收费或签到制的,在不断抽卡中余额消耗的极快,而开源免费的Stable Diffusion无疑是雪中送炭。
通常设计师的电脑也都不算差劲,尽管现在SD还有一些硬件或系统兼容的问题,但是我认为不久的将来,强大的开源社区会给出更好的方案。
二、可控性更高
设计师不同于纯粹的艺术家,设计即代表有精细的布局与控制,而图像内容的可控性就在工作中显得极为重要,这些具备商业化或产品属性的诉求若不能在AIGC绘图中解决,那AIGC绘图就还不具备为设计师解题的能力。
初阶段的SD给人的印象也还是基于模型画画纸片人,并支持一些涂涂换换的能力,直到相关开源社区出现了更多的模型、Lora以及颠覆性的ControlNet控制网络时,我看到的了SD更高的可控性与可能性,这是AIGC绘图跨入工业化的一大步!
三、更多的可能性
开源社区的魅力就是为爱发电多,商业化场景的应用模型越来越完善,未来充满了各种可能,你根本不知道何时就会出现一款现象级插件或模型,并且市面上可能会出现更多基于Diffusion二开的商业场景应用,我相信在未来SD步入工业化的脚步会越来越快,设计师应用的场景也会更广阔,即使你现在不使用SD,但依旧值得期待一下!
Stable Diffusion的可控概念
首先你不要想着像专业绘图工具一样控制了,你可能有时候连自己都控制不住自己!

SD绘图可控性的本质是定向抽卡,方向越聚焦,结果越接近。
这个过程中,提示词是画面构成的重要因素,却不是画面风格和语义解析的全部,SD生成的可控性还需要借助各种扩展网络的应用,这意味完全一样的关键词出来的结果依旧可能天差地别,SD与扩展模型的运作模式可通过下图快速理解,它们逐级影响,相互作用;


里程碑ControlNet 1.1+的概念
关于此扩展插件相信大家已经有所了解,这里不做教程了,目前ControlNet还在持续更新。该插件提供了多种方式供用户实现内容生成的可控性,是一个阶段性的扩展应用,还有更多新的ControlNet以及高版本正在生产中,期待一下吧;

SD-Controlnet1.1 官方介绍:https://github.com/lllyasviel/ControlNet-v1-1-nightly
SD-Controlnet1.1 开源仓库:https://github.com/Mikubill/sd-webui-controlnet
SD-Controlnet1.1 资源下载:https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main
应用SD的正确解题思路
先了解SD绘图工具
当工具回归工具,设计的核心依旧是设计思维,目前想要借助AIGC绘图来为工作降本增效,就需要先了解工具能做什么,有何优势,有何局限性,能帮你做什么?能做到什么程度?
期间笔者看了很多AIGC绘图应用的分享,也参加了些相关沙龙,基本上主流的设计应用就三个方面;

另外SD不同于Midjourney,由于是从主模型到扩展一层层混合作业的,想要基于同样的提示词实现抄作业不一定行的通,所以了解SD各种模型的关系与功能属性是很有必要的,以下是关于SD基本且主流功能的概述整理:


沉淀美学与设计素养
进行AIGC商业化应用,沉淀美学与设计素养是根基,并且针对AIGC生成,可以准备成一份随时可参考的材料。
一、对于各类美术风格,需要知道其特征和专用术语名词,以保证在需要的时候能够应用对应的提示词,并且这些提示词不局限于美术风格,也有根据某品牌或是某个行业提炼的艺术关键词;
※部分举例
3D、2.5D、2D、CG、吉卜力风格(Ghibli style)、水彩(Watercolor)、波普艺术(Pop Art)、中国风(Chinese Fashion)、朋克风(Cyberpunk)、噪点插画(Noise Design)、像素风(16-bit pixel art)、迪士尼风(Disney Style)、Q版风(Q-Style)等
二、对镜头语言的认识,掌握基本镜头视角的描述词,以及高阶镜头的效果差异与提示词应用,不过目前体验下来,AIGC工具基本还不能呈现较为复杂的镜头与视角;
※部分举例
透视(perspective)、景深(depth of field)、俯视(bird’s-eye view)、鱼眼(fish-eye view)、顶视(top view)、广角(wide-angle)、鸟瞰(aerial view)、等距(Equidistant perspective)等

三、掌握基本的构图知识以及布光基础,并了解效果差异与提示词应用;
※部分举例
前景(close shot)、中景(mid-shot)、远景(prospect)、主光(Main light)、辅助光(fill light)、顶光(overhead light)、眩光(dazzle)、柔和光(soft lighting)、阴影(shadow)等
四、在偏3D的场景中,对于物体材质特征的基本认识与提示词应用也很重要,目前在一些原生的3D渲染器中,收集了不少关键词,建议大家也可以如法炮制;
※部分举例
塑料(plastic)、金属(metal)、玻璃(glass)、皮肤(skin)、薄膜(thin)、布料(cloth)、亚麻布(linen)、水晶(crystal)、木质(wood)、石头(stone)、瓷器(ceramic)、丝绸(Silk)、皮革(leather)等
五、基础环境描述与提示词应用,实际上复杂环境通过提示词是很难搞定的,主要是还从简到繁的将空间环境一点点根据期望去刻画,基本上就是区分室内还是室外、空旷还是狭小、乡野还是城市等等;
※部分举例
房间(room)、森林(forest)、废墟(ruins)、天空(sky)、宇宙(universe)、雨天(raining)、雪天(snowing)、城市(city)、广场(square)、草原(grassland)、操场(playground)、海洋(ocean)、海底(seabed)等
六、优化提示词与负面提示词的应用,目的是让生成图片的质量更高以及减少不对的负面效果,但想想还是有点傻,期待更智能的那一天早日到来!
※优化词
高清(hd)、高分辨率(4K,8K)、最佳质量(best quality)、杰作(masterpiece)、抗锯齿(antialiasing)、虚幻引擎(unreal engine)、原画级别(CG)、完整(complete)等
※负面词
画面常用:低质量(worst quality)、模糊(blurry)、水印(watermark)、丑陋(duplicate)、重复(duplicate)、损坏的(Damaged)、出错(error)、单色的(monochrome)、黑暗(darkness)、非常规(nsfw)等;
人物常用:肢体多余(extra limbs)、畸形(deformation)、病态(morbid)、多手指(too many fingers)、多条腿(mang legs)、斗鸡眼(cross-eyed)、变异手(mutated hands)、截肢(amputation)等;
掌握和了解以上美术素养或提示词是为了更好的面向AIGC工具进行需求描述和控制!
此外设计素养是作为商业设计、工业化的重要内核,其中包含了基本的行业设计规范、标准的理解与掌握,此外相关设计思维、审美与问题解决能力都要不断的学习和提升,这是进行商业设计和不被AIGC取代的重要资本;
建立预期后再开工
一方面因为SD通过简单的几个提示词并不能生成高质量效果,依靠随机抽卡是不可能实现商业需求的,另外作为商业设计,其中必然是带有商业目的与业务信息的,因此为了保障生成效果与效率,设计师还是要先根据需求建立设计预期,在脑子里形成设计方案后开始构建草图或参考材料,然后再拆解成多个阶段,把适合AIGC绘图处理的事项交出去,中间通过垫图或人工操作纠正方向,加速抽卡的方向聚焦,最终得到一些满意的材料,再做商业合成产出交付产物;

多元的草图与原型图
准备草稿或是原型是设计工作中的必要过程,可以帮助设计师对需求和目标的理解,也能形成材料与同事之间探讨构思,甚至向上对齐设计方案。此外准备草稿或原型材料也能帮SD在抽卡时更聚焦,减少无效的试错。
一、草稿或原型支持多样性
SD功能允许的条件下,经过反复尝试,前期的草稿材料可准备如下;部分需要采用ControlNet扩展进行解析应用,方法就是制作与ControlNet模型匹配的材料,导入到预览作为输出后再启用对应模型即可,方法如下图所示,亲测有效;

以下是可准备的草稿或原型材料的参考说明;

二、参考材料或生成的局限性
在以上表格的注意事项已经提到了部分扩展应用的局限性,此外在实际工作场景中,还有一些比较头大的局限性,主要包括了以下三点;

另外当引导词不能被模型正确理解或不具备较高的常规性时,你也可以将关键词替换成其他近似词语,或者改成其他描述词来代替,能够提升一定的常规性和模型理解的概率;
例如:帽子(hat)无法得到预期的结果,便只好改为了头部穿戴(Head wear)+其他构成元素词语,输出时,帽子终于出现了。
三、草稿复杂性拆解技巧
将草稿的复杂性进行拆解是为了简化设计,使SD中的模型能够更好理解需求进行生成,经过尝试或实验,整理了以下两种比较有效的拆解方法,但前提是保证一定的常规性以及主模型的可理解性,当然你也可以在整个过程中来回切换主模型应用,只要大的视觉风格差的不太多,例如都是2D或是写实的,后续再对风格矫正即可;

但由于现在的AIGC绘图对文本信息处理能力不佳,若你的主体视觉由信息构成并且嵌套在视觉场景之中,而不是处于前景、近景的层次那么就会比较难搞,也因此目前市面上主流的AIGC营销视觉案例基本都是“情景图+配文”的结构,两类应用场景如下;

局部调整或后期优化阶段
借助SD的图生图模式以及ControlNet,可以灵活的实现局部的优化调整,这是Midjourney完全不支持的能力,功能的用途简述在上个话题“先了解SD绘图工具”中有介绍,简单讲就是我们可以的对画面的局部进行涂改重新生成,可以是对局部错误的生成进行改正,也可以是将新的点子生成到当前的画面中,相比于PS的创意填充,在SD中你可以对局部轮廓、色彩等更多方向进行生成控制,总之不再是0-1的抽卡阶段,而是1-2的聚焦抽卡阶段了;

后期优化部分主要是指对整体的风格进行切换或是混合,此前网上流行的IP线稿转有色稿再转3D化就是典型的风格转化,主要是借助主模型或配合Lora等模型的风格特征,转移到当前的原生图上,只要控制住“重绘幅度”基本就能保证相似度,借助ControlNet的Tile也能快速帮你应用参考图的视觉风格,并且当你使用局部调整约束好区域配合模型的切换,你还能够实现一个风格混合的画面,只要使用得当,也能生成效果不错的画面;

工具混用 当C4D、Blender、Photoshop碰上SD
以ControlNet中的深度、法线来讲,其实都不是什么新鲜技术,在3D设计工具中都很常见,这也意味着在应用SD的过程中,我们可以根据预期在其他软件中完成起手材料来辅助SD生成,这里我放了一个在B站上看见的应用案例,其中就是借助3D软件完成了基础的城市地编,然后根据ControlNet的语义分割协议对地编建筑进行了色彩渲染,之后就是导入到SD进行生成以填充相应的细节;

不止3D软件,我们喜闻乐见的PS其实也支持SD的扩展应用了,这意味着你可以直接在PS中进行更精准的涂绘、制作蒙版、绘制草稿等,加上Beta版PS自带的创意生成,或许我们可以让AIGC绘图之间碰撞出更多的可能性!
【官方Github】https://github.com/AbdullahAlfaraj/Auto-Photoshop-StableDiffusion-Plugin.git

风格模型沉淀复用
关于模型沉淀,自己的话,反正有条件有兴趣随便弄,如果是面向企业办公的话,则要考虑两个属性,一是定制化,二是复用性,即市面上的模型不能满足,且模型训练完有反复应用的价值。主模型可以很好的涵盖行业特征进去,但是炼丹的难度跟成本会比较高,如果说有适合的主模型能够满足事物提示词的理解生成,但是效果不佳,这个时候比较建议训练Lora模型来微调结果,原因如下;

这里不讲具体训练方法了,网上资源很丰富,这里引用一个概念模型帮助大家理解和消化一下Lora模型;其中训练Lora的主要任务即“打标”,这个过程有点儿像是帮助AI看图识物!通过对一批规格统一的素材进行关键信息标记,以帮助主模型更深入的理解某个事物或风格,最终并在主模型生成时启用Lora以达成微调的目的;

训练方法可以在一些博客或B站上获取,此处不赘述。
如何快速掌握SD的应用
在反复的尝试和学习过程中,想要尽快熟悉软件操作,那么自己一顿尝试后在结合一些教程是比较快的,当你想要更深入的掌握SD并生成更惊艳的效果,我感觉还得是多“抄作业”,方法也很简单,就是对着相关平台用户分享的作品参数对着来,从主模型选取到扩展模型权重,再到正反向提示词等,全部复刻一边;
当你这样做的时候,你会发现有很多好处;
一、首先会减少SD图片创作的门槛,通过更快的生成高质量图像来建立更多的自信,并感受到SD美妙之处;
二、在比照调整配置的过程中,可以快速感知到采样、模型、步幅、提示词之间奇妙的化学反应;
三、在抄作业的过程中,其实也是SD上手熟练度提升的过程,这比看几篇文章、添加到收藏夹里有用多了;
四、在搬运他人的提示词时,自己也能掌握更多的提示词应用,以及配套模型的触发词技巧,当然了,光抄作业还不够,最好再加上做笔记,把别人的提示词与配套模型整理下,以后就可以更方便的调用了;

展望一下
在前面的部分,探讨了AIGC绘图工具应用到工作流中的思路,以及技巧与AIGC设计的思维培养,同时也暴露了不少AIGC绘图功能的不足,那么也展望一下吧。
最近有看到在Midjourney设计落地教程里的这么一段话“视觉设计师赶紧转行吧,花几个月学的三维软件,结果几个通关密语就给实现了”,那么真的是这样吗?
事实上Midjourney也只是掌握了一类三维视觉技法而已,当进行商业设计时,依旧是设计思维先行技法辅助,再则,更深入的三维技术甚至三维动画,AIGC还有待提高,期望以后可以有更惊艳的表现;
目前行业相关模型正在快速丰富,行业化即代表具备一定的工业属性、商业属性,虽然还不成熟但值得期待,另外Stable Diffusion玩家的存储空间应该越来越告急了吧,期待兼容更好的大模型或云服务;
情感化联想一直是AI发展的重点功课,AIGC绘图对情绪或感情的理解与表达更是有限,会不会有一天AIGC设计能够理解需求并洞察出准确的情绪与氛围表达呢?
多模态输入输出同样值得期待一下,仅是提示词输入与静态图片输出怎么能满足设计行业的欲望呢?比如说我先选个行业模型,然后对话式生成需求理解,并给出设计方案建议和参考材料,再进一步探讨方案细节与引入参考,进行一次初步的设计生成,最后就是探讨优化再到生成结果之间反复循环,直到把AIGC乙方虐爆为止hhhhh。
这里分享给大家一份Adobe大神整理的《AIGC全家桶学习笔记》,相信大家会对AIGC有着更深入、更系统的理解。
有需要的朋友,可以点击下方免费领取!

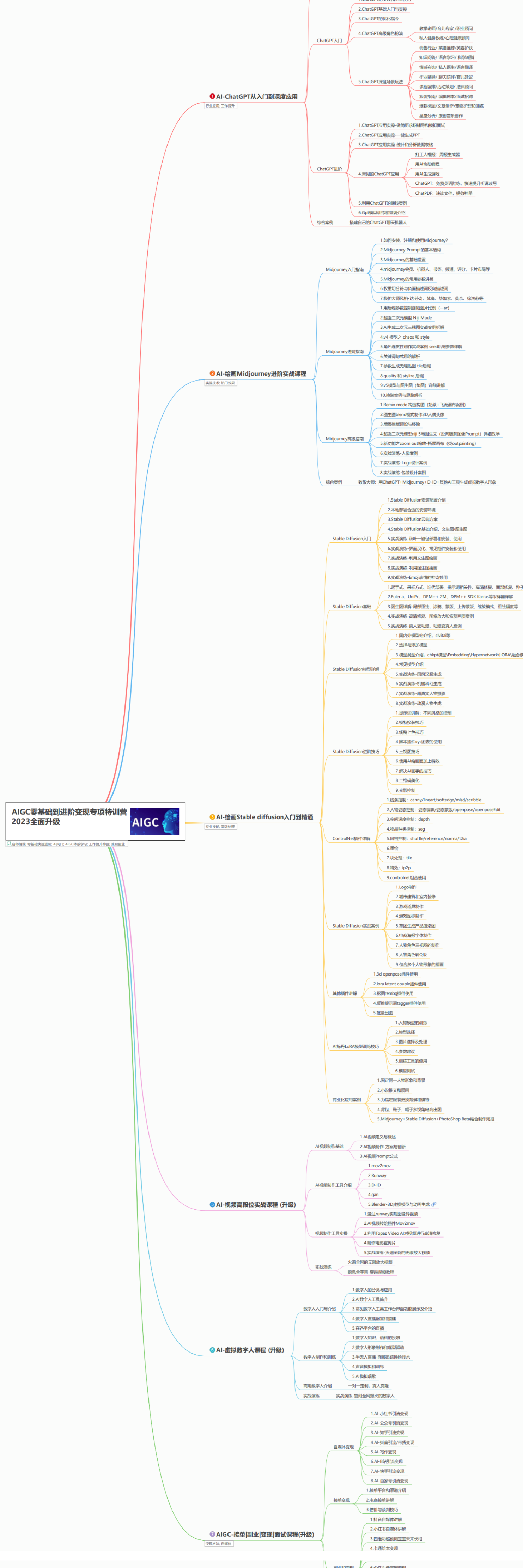
AIGC所有方向的学习路线思维导图
这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。如果下面这个学习路线能帮助大家将AI利用到自身工作上去,那么我的使命也就完成了:
AIGC工具库
AIGC工具库是一个利用人工智能技术来生成应用程序的代码和内容的工具集合,通过使用AIGC工具库,能更加快速,准确的辅助我们学习AIGC

有需要的朋友,可以点击下方卡片免费领取!

精品AIGC学习书籍手册
书籍阅读永不过时,阅读AIGC经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验,结合自身案例融会贯通。
AI绘画视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,科学有趣才能更方便的学习下去。