1、MapReduce序列化(接着昨天的知识继续学习)
- 序列化 (Serialization)将对象的状态信息转换为可以存储或传输的形式的过程。在序列化期间,对象将其当前状态写入到临时或持久性存储区。以后,可以通过从存储区中读取或反序列化对象的状态,重新创建该对象。
- 当两个进程在进行远程通信时,彼此可以发送各种类型的数据。无论是何种类型的数据,都会以二进制序列的形式在网络上传送。发送方需要把这个对象转换为字节序列,才能在网络上传送;接收方则需要把字节序列再恢复为对象。把对象转换为字节序列的过程称为对象的序列化。把字节序列恢复为对象的过程称为对象的反序列化。
- 例子:当将Student类作为Mapper类的输出类型时,
- 对于Stu学生自定义学生类,作为输出类型,需要将当前类进行序列化操作 implement Writable 接口
对于各班级中的学生总分进行排序,要求取出各班级中总分前三名学生(序列化)
①Student类进行序列化
package com.mr.top3;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.io.Serializable;
public class Stu implements Writable {
String id;
String name;
int age;
String gender;
String clazz;
int score;
/*
TODO 使用Hadoop序列化的问题:
java.lang.RuntimeException: java.lang.NoSuchMethodException: com.shujia.mr.top3.Stu.<init>()
*/
public Stu() {
}
public Stu(String id, String name, int age, String gender, String clazz, int score) {
this.id = id;
this.name = name;
this.age = age;
this.gender = gender;
this.clazz = clazz;
this.score = score;
}
@Override
public String toString() {
return id +
", " + name +
", " + age +
", " + gender +
", " + clazz +
", " + score;
}
/*
对于Write方法中是对当前的对象进行序列化操作
*/
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(id);
out.writeUTF(name);
out.writeInt(age);
out.writeUTF(gender);
out.writeUTF(clazz);
out.writeInt(score);
}
/*
readFields方法中是对当前对象进行反序列化操作
*/
@Override
public void readFields(DataInput in) throws IOException {
this.id = in.readUTF(); // 将0101数据反序列化数据并保存到当前属性中
this.name = in.readUTF();
this.age = in.readInt();
this.gender = in.readUTF();
this.clazz = in.readUTF();
this.score = in.readInt();
}
}
②Top3主函数
package com.mr.top3;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.FileNotFoundException;
import java.io.IOException;
public class Top3 {
/*
TODO:将项目打包到Hadoop中进行执行。
*/
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
// TODO MapReduce程序入口中的固定写法
// TODO 1.获取Job对象 并设置相关Job任务的名称及入口类
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Sort");
// 设置当前main方法所在的入口类
job.setJarByClass(Top3.class);
// TODO 2.设置自定义的Mapper和Reducer类
job.setMapperClass(Top3Mapper.class);
job.setReducerClass(Top3Reducer.class);
// TODO 3.设置Mapper的KeyValue输出类 和 Reducer的输出类 (最终输出)
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Stu.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// TODO 4.设置数据的输入和输出路径
// 本地路径
FileSystem fileSystem = FileSystem.get(job.getConfiguration());
Path outPath = new Path("hadoop/out/new_top3");
Path inpath = new Path("hadoop/out/reducejoin");
if (!fileSystem.exists(inpath)) {
throw new FileNotFoundException(inpath+"不存在");
}
TextInputFormat.addInputPath(job,inpath);
if (fileSystem.exists(outPath)) {
System.out.println("路径存在,开始删除");
fileSystem.delete(outPath,true);
}
TextOutputFormat.setOutputPath(job,outPath);
// TODO 5.提交任务开始执行
job.waitForCompletion(true);
}
}
③MapTask阶段
package com.mr.top3;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/*
TODO
在编写代码之前需要先定义数据的处理逻辑
对于各班级中的学生总分进行排序,要求取出各班级中总分前三名学生
MapTask阶段:
① 读取ReduceJoin的处理结果,并对数据进行提取
② 按照学生的班级信息,对班级作为Key,整行数据作为Value写出到 ReduceTask 端
ReduceTask阶段:
① 接收到整个班级中的所有学生信息并将该数据存放在迭代器中
*/
public class Top3Mapper extends Mapper<LongWritable, Text, Text, Stu> {
/**
* 直接将学生对象发送到Reduce端进行操作
* ① 对于Stu学生自定义学生类,作为输出类型,需要将当前类进行序列化操作 implement Writable 接口
* ② 同时需要在自定义类中保证 类是具有无参构造的
* 运行时会出现:
* java.lang.RuntimeException: java.lang.NoSuchMethodException: com.shujia.mr.top3.Stu.<init>()
* 从日志上可以看到调用了 Stu.<init>() 指定的就是无参构造
* 从逻辑上:
* 在Mapper端 构建了Stu对象 => 通过调用其 write 对其进行了序列化操作
* 在Reducer端 需要对其进行反序列化 => 通过无参构造创建自身的空参对象 => 调用readFields方法进行 反序列化
* 将数据赋予给当前的空参对象属性
*/
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Stu>.Context context) throws IOException, InterruptedException {
// 1500100009 沈德昌,21,男,理科一班,251 => 表示读取到的数据
String[] split = value.toString().split("\t");
if (split.length == 2) {
String otherInfo = split[1];
String[] columns = otherInfo.split(",");
if (columns.length == 5) {
String clazz = columns[3];
Stu stu = new Stu(split[0], columns[0], Integer.valueOf(columns[1]), columns[2], columns[3], Integer.valueOf(columns[4]));
context.write(new Text(clazz), stu);
}
}
}
}
④ReduceTask阶段
package com.mr.top3;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
/*
TODO ReduceTask阶段
*/
public class Top3Reducer extends Reducer<Text, Stu, Text, NullWritable> {
/**
* 对一个班级中所有的学生成绩进行排序 =>
* 1.将数据存储在一个容器中
* 2.对容器中数据进行排序操作
* 对排序的结果进行取前三
*
* @param key 表示班级信息
* @param values 一个班级中所有的学生对象
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<Stu> values, Reducer<Text, Stu, Text, NullWritable>.Context context) throws IOException, InterruptedException {
/*
TODO 当程序执行到Reducer端时,需要对Values中的数据进行遍历,获取每一个学生对象
但是在添加过程中,ArrayList中所有的对象信息都变成一样的。
表示当前 ArrayList存储的对象为1个,每次添加的引用信息都是指向一个对象地址
如何解决?
每次获取到对象后,对其进行克隆一份
*/
ArrayList<Stu> stus = new ArrayList<>();
for (Stu stu : values) {
Stu stu1 = new Stu(stu.id, stu.name, stu.age, stu.gender, stu.clazz, stu.score);
stus.add(stu1);
}
// 进行排序操作
Collections.sort(stus,
new Comparator<Stu>() {
@Override
public int compare(Stu o1, Stu o2) {
int compareScore = o1.score - o2.score;
return -compareScore > 0 ? 1 : (compareScore == 0 ? o1.id.compareTo(o2.id) : -1);
}
}
);
// 对排序的结果进行遍历
for (int i = 0; i < 3; i++) {
context.write(new Text(stus.get(i).toString()+","+(i+1)),NullWritable.get());
}
}
}
MapReduce进阶
下面我们进入到进阶阶段的学习
1、数据切片
1.1MapReduce默认输入处理类
- InputFormat
- 抽象类,只是定义了两个方法。
- FileInputFormat
- FileInputFormat是所有以文件作为数据源的InputFormat实现的基类,
- FileInputFormat保存作为job输入的所有文件,并实现了对输入文件计算splits的方法。至于获得记录的方法是有不同的子类——TextInputFormat进行实现的。
- TextInputFormat
- 是默认的处理类,处理普通文本文件
- 文件中每一行作为一个记录,他将每一行在文件中的起始偏移量作为key,每一行的内容作为value
- 默认以\n或回车键作为一行记录
1.2数据切片分析
- 在执行mapreduce之前,原始数据被分割成若干split,每个split作为一个map任务的输入。
- 当Hadoop处理很多小文件(文件大小小于hdfs block大小)的时候,由于FileInputFormat不会对小文件进行划分,所以每一个小文件都会被当做一个split并分配一个map任务,会有大量的map task运行,导致效率底下
- 例如:一个1G的文件,会被划分成8个128MB的split,并分配8个map任务处理,而10000个100kb的文件会被10000个map任务处理
- Map任务的数量
- 一个InputSplit对应一个Map task
- InputSplit的大小是由Math.max(minSize, Math.min(maxSize,blockSize))决定
- 单节点建议运行10—100个map task
- map task执行时长不建议低于1分钟,否则效率低
- 特殊:一个输入文件大小为140M,会有几个map task?
- 对应一个切片,但是其实140M的文件是对应的两个block块的
- FileInputFormat类中的getSplits
具体看数据切片的笔记
2、执行流程
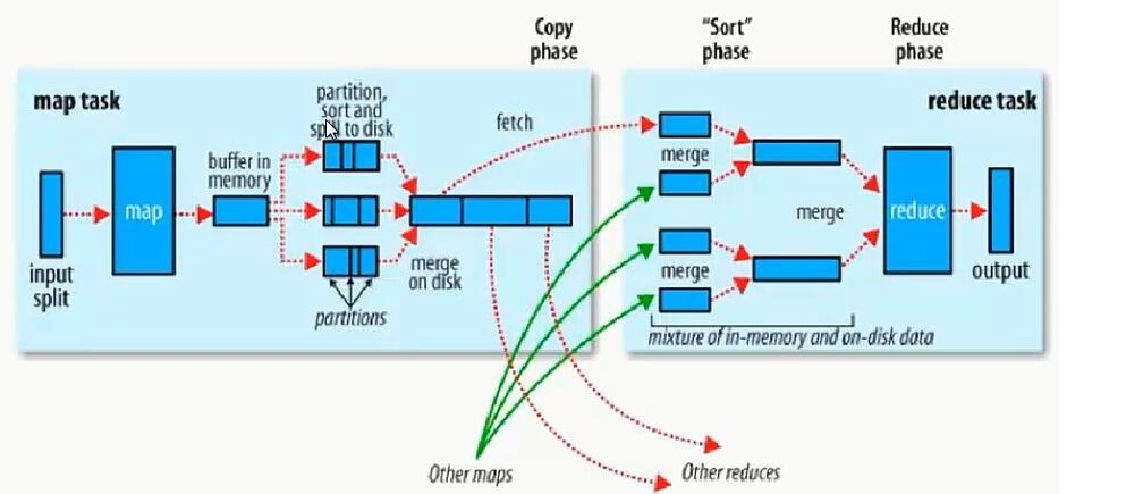
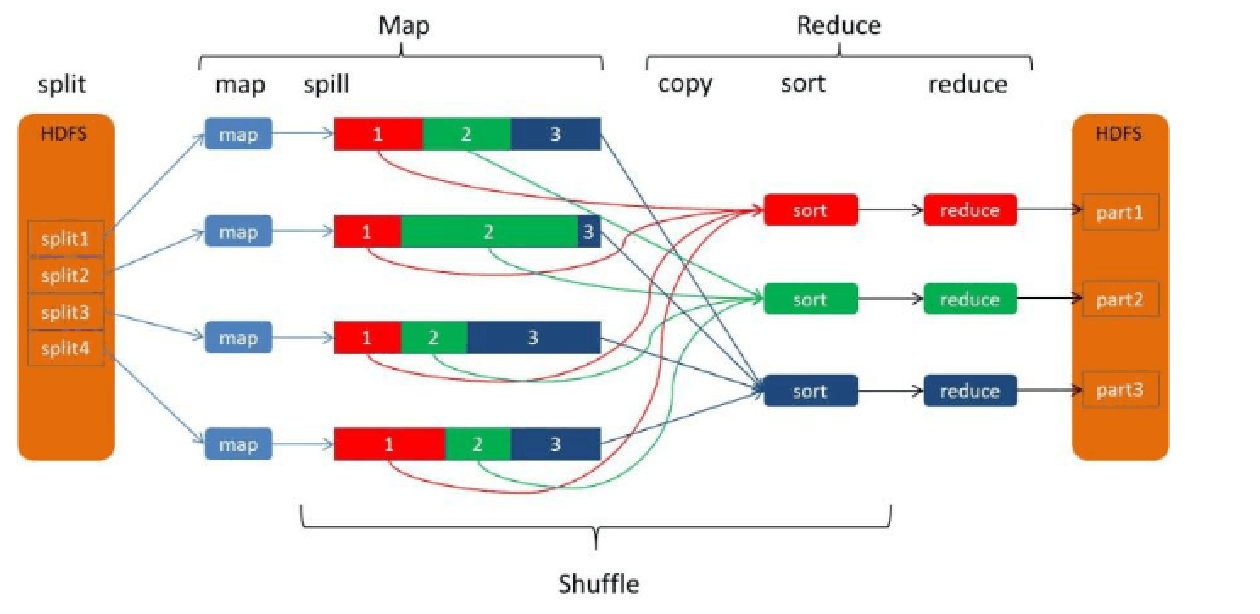
- MR执行流程
2.1MR执行过程-map阶段
- map任务处理
- 1.1 框架使用InputFormat类的子类把输入文件(夹)划分为很多InputSplit,默认,每个HDFS的block对应一个InputSplit。通过RecordReader类,把每个InputSplit解析成一个个<k1,v1>。默认,框架对每个InputSplit中的每一行,解析成一个<k1,v1>。
- 1.2 框架调用Mapper类中的map(...)函数,map函数的形参是<k1,v1>对,输出是<k2,v2>对。一个InputSplit对应一个map task。程序员可以覆盖map函数,实现自己的逻辑。
- 1.3
-
(假设reduce存在)框架对map输出的<k2,v2>进行分区。不同的分区中的<k2,v2>由不同的reduce task处理。默认只有1个分区。
-
(假设reduce不存在)框架对map结果直接输出到HDFS中。
-
- 1.4 (假设reduce存在)框架对每个分区中的数据,按照k2进行排序、分组。分组指的是相同k2的v2分成一个组。注意:分组不会减少<k2,v2>数量。
- 1.5 (假设reduce存在,可选)在map节点,框架可以执行reduce归约。
- 1.6 (假设reduce存在)框架会对map task输出的<k2,v2>写入到linux 的磁盘文件中。
- 至此,整个map阶段结束
2.2MR执行过程-shuffle过程
- 1.每个map有一个环形内存缓冲区,用于存储map的输出。默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spill.percent),一个后台线程把内容溢写到(spilt)磁盘的指定目录(mapred.local.dir)下的一个新建文件中。
- 2.写磁盘前,要partition,sort。如果有combiner,combine排序后数据。
- 3.等最后记录写完,合并全部文件为一个分区且排序的文件。
2.3MR执行过程-reduce过程
- reduce任务处理
- 2.1 框架对reduce端接收的[map任务输出的]相同分区的<k2,v2>数据进行合并、排序、分组。
- 2.2 框架调用Reducer类中的reduce方法,reduce方法的形参是<k2,{v2...}>,输出是<k3,v3>。一个<k2,{v2...}>调用一次reduce函数。程序员可以覆盖reduce函数,实现自己的逻辑。
- 2.3 框架把reduce的输出保存到HDFS中。
至此,整个reduce阶段结束。
2.4注意
-
一个分区对应一个reducertask任务
-
溢写过程中生成溢写文件的排序是快速排序,是发生在内存中
-
快速排序是发生在内存中归并排序是发生在磁盘上的
-
一个reducertask维护一个进程,只会生成一个文件
3、shuffle源码
-
Shuffle过程
- 广义的Shuffle过程是指,在Map函数输出数据之后并且在Reduce函数执行之前的过程。在Shuffle过程中,包含了对数据的分区、溢写、排序、合并等操作
-
Shuffle源码主要的内容包含在 MapOutputCollector 的子实现类中,而该类对象表示的就是缓冲区的对象,
4、自定义分区排序
- 如果我们想要实现不同的功能,可以自定义分区排序规则
- 默认分区下,如果Reduce的数量大于1,那么会使用HashPartitioner对Key进行做Hash计算,之后再对计算得到的结果使用reduce数量进行取余得到分区编号,每个reduce获取固定编号中的数据进行处理
- 自定义分区需要重写分区方法,根据不同的数据计算得到不同的分区编号
实例:将不同学生年龄的数据写入到不同的文件中
①主入口代码
package com.mr.partitioner;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.FileNotFoundException;
import java.io.IOException;
public class PartitionerMR {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
// conf.setClass("mapreduce.job.partitioner.class",agePartitioner.class, Partitioner.class);
Job job = Job.getInstance(conf, "partitionerAge");
job.setJarByClass(PartitionerMR.class);
job.setMapperClass(PartitionerMapper.class);
job.setReducerClass(PartitionerReducer.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(Stu.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
job.setPartitionerClass(agePartitioner.class);
job.setNumReduceTasks(4);
FileSystem fileSystem = FileSystem.get(job.getConfiguration());
Path inPath = new Path("hadoop/data/students.txt");
Path outPath = new Path("hadoop/out/agePartitioner");
if(!fileSystem.exists(inPath)){
throw new FileNotFoundException(inPath+"路径不存在");
}
TextInputFormat.addInputPath(job,inPath);
if(fileSystem.exists(outPath)){
System.out.println("路径存在,开始删除");
fileSystem.delete(outPath,true);
}
TextOutputFormat.setOutputPath(job,outPath);
job.waitForCompletion(true);
}
}
②MapTask阶段
package com.mr.partitioner;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/*
TODO 代码逻辑
Mapper端
① 读取学生数据,并对数据进行切分处理,包装成学生对象
② 将年龄作为Key 学生对象作为Value写出
注意:学生对象需要进行序列化操作
自定义分区器
① 接收到key为年龄 Value为学生对象 => 根据数据中的年龄 设置编号
21 -> 0
22 -> 1
23 -> 2
24 -> 3
Reducer端
① 根据分区编号以及对应的Key 获取数据
② 将相同Key的数据汇集,并写出到文件中
*/
public class PartitionerMapper extends Mapper<LongWritable, Text, IntWritable, Stu> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, IntWritable, Stu>.Context context) throws IOException, InterruptedException {
String oneLine = value.toString();
String[] columns = oneLine.split(",");
if (columns.length == 5) {
// 1500100013,逯君昊,24,男,文科二班
context.write(new IntWritable(Integer.valueOf(columns[2]))
, new Stu(columns[0], columns[1], Integer.valueOf(columns[2]), columns[3], columns[4])
);
}
}
}
③ReduceTask阶段
package com.mr.partitioner;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class PartitionerReducer extends Reducer<IntWritable, Stu, Text, NullWritable> {
@Override
protected void reduce(IntWritable key, Iterable<Stu> values, Reducer<IntWritable, Stu, Text, NullWritable>.Context context) throws IOException, InterruptedException {
for (Stu value : values) {
context.write(new Text(value.toString()),NullWritable.get());
}
}
}
④Partitioner
package com.mr.partitioner;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Partitioner;
public class AgePartitioner extends Partitioner<IntWritable,Stu> {
/*
TODO 自定义分区器
① 接收到key为年龄 Value为学生对象 => 根据数据中的年龄 设置编号
21 -> 0
22 -> 1
23 -> 2
24 -> 3
自定义分区器写法:
abstract class Partitioner<KEY, VALUE>
Partitioner是一个抽象类 需要使用extend 并给定泛型
Key 表示 年龄数据 类型为 IntWritable
Value 表示 学生对象 类型为 Stu
*/
@Override
public int getPartition(IntWritable intWritable, Stu stu, int numPartitions) {
int age = intWritable.get();
int valueAge = stu.age;
switch (age){
case 21 :
return 0;
case 22 :
return 1;
case 23:
return 2;
case 24:
return 3;
default:
return 3;
}
}
}
⑤Student类
package com.mr.partitioner;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class Stu implements Writable {
public String id;
public String name;
public int age;
public String gender;
public String clazz;
/*
TODO 使用Hadoop序列化的问题:
java.lang.RuntimeException: java.lang.NoSuchMethodException: com.shujia.mr.top3.Stu.<init>()
*/
public Stu() {
}
public Stu(String id, String name, int age, String gender, String clazz) {
this.id = id;
this.name = name;
this.age = age;
this.gender = gender;
this.clazz = clazz;
}
@Override
public String toString() {
return id +
", " + name +
", " + age +
", " + gender +
", " + clazz ;
}
/*
对于Write方法中是对当前的对象进行序列化操作
*/
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(id);
out.writeUTF(name);
out.writeInt(age);
out.writeUTF(gender);
out.writeUTF(clazz);
}
/*
readFields方法中是对当前对象进行反序列化操作
*/
@Override
public void readFields(DataInput in) throws IOException {
this.id = in.readUTF(); // 将0101数据反序列化数据并保存到当前属性中
this.name = in.readUTF();
this.age = in.readInt();
this.gender = in.readUTF();
this.clazz = in.readUTF();
}
}
5、补充学生实例
需求:对于学生数据信息,按成绩降序排序,ID升序排序,同时满足使用学生类作为mapper的输出类型
①主入口
package com.mr.sort_by_stu;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.FileNotFoundException;
import java.io.IOException;
public class SortByStu {
/*
TODO:将项目打包到Hadoop中进行执行。
*/
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
// TODO MapReduce程序入口中的固定写法
// TODO 1.获取Job对象 并设置相关Job任务的名称及入口类
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Sort");
// 设置当前main方法所在的入口类
job.setJarByClass(SortByStu.class);
// TODO 2.设置自定义的Mapper和Reducer类
job.setMapperClass(SortByStuMapper.class);
job.setReducerClass(SortByStuReducer.class);
// TODO 3.设置Mapper的KeyValue输出类 和 Reducer的输出类 (最终输出)
job.setMapOutputKeyClass(Stu.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 当Reduce数量为1时为全局排序
job.setNumReduceTasks(1);
// TODO 4.设置数据的输入和输出路径
// 本地路径
FileSystem fileSystem = FileSystem.get(job.getConfiguration());
Path outPath = new Path("hadoop/out/sortByStu");
Path inpath = new Path("hadoop/out/reducejoin");
if (!fileSystem.exists(inpath)) {
throw new FileNotFoundException(inpath+"不存在");
}
TextInputFormat.addInputPath(job,inpath);
if (fileSystem.exists(outPath)) {
System.out.println("路径存在,开始删除");
fileSystem.delete(outPath,true);
}
TextOutputFormat.setOutputPath(job,outPath);
// TODO 5.提交任务开始执行
job.waitForCompletion(true);
}
}
②Mapper阶段
package com.mr.sort_by_stu;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/*
TODO
*/
public class SortByStuMapper extends Mapper<LongWritable, Text, Stu, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Stu, NullWritable>.Context context) throws IOException, InterruptedException {
// 直接使用学生类Stu作为排序的依据
// 1500100009 沈德昌,21,男,理科一班,251 => 表示读取到的数据
String[] split = value.toString().split("\t");
if (split.length == 2) {
String otherInfo = split[1];
String[] columns = otherInfo.split(",");
if (columns.length == 5) {
Stu stu = new Stu(split[0], columns[0], Integer.valueOf(columns[1]), columns[2], columns[3], Integer.valueOf(columns[4]));
context.write(stu,NullWritable.get());
}
}
}
}
③Reducer阶段
package com.mr.sort_by_stu;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/*
TODO ReduceTask阶段
*/
public class SortByStuReducer extends Reducer<Stu, NullWritable, Text, NullWritable> {
@Override
protected void reduce(Stu key, Iterable<NullWritable> values, Reducer<Stu, NullWritable, Text, NullWritable>.Context context) throws IOException, InterruptedException {
context.write(new Text(key.toString()),NullWritable.get());
}
}
学生类Stu
package com.mr.sort_by_stu;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class Stu implements WritableComparable<Stu> {
String id;
String name;
int age;
String gender;
String clazz;
int score;
/*
TODO 使用Hadoop序列化的问题:
java.lang.RuntimeException: java.lang.NoSuchMethodException: com.shujia.mr.top3.Stu.<init>()
*/
public Stu() {
}
public Stu(String id, String name, int age, String gender, String clazz, int score) {
this.id = id;
this.name = name;
this.age = age;
this.gender = gender;
this.clazz = clazz;
this.score = score;
}
@Override
public String toString() {
return id +
", " + name +
", " + age +
", " + gender +
", " + clazz +
", " + score;
}
/*
对于Write方法中是对当前的对象进行序列化操作
*/
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(id);
out.writeUTF(name);
out.writeInt(age);
out.writeUTF(gender);
out.writeUTF(clazz);
out.writeInt(score);
}
/*
readFields方法中是对当前对象进行反序列化操作
*/
@Override
public void readFields(DataInput in) throws IOException {
this.id = in.readUTF(); // 将0101数据反序列化数据并保存到当前属性中
this.name = in.readUTF();
this.age = in.readInt();
this.gender = in.readUTF();
this.clazz = in.readUTF();
this.score = in.readInt();
}
/*
TODO 当没有添加 WritableComparable 实现接口时,自定义类作为Key不能进行排序,同时会报
java.lang.ClassCastException: class com.shujia.mr.sort_by_stu.Stu的错误
需求变更: 实现学生数据按照成绩降序,成绩相同时,按照学号升序排序输出
*/
@Override
public int compareTo(Stu o) {
int compareScore = this.score - o.score;
return -(compareScore > 0 ? 1 : compareScore == 0 ? -this.id.compareTo(o.id) : -1);
}
}
6、Combine及MapJoin
1、Combine
- combiner发生在map端的reduce操作。
- 作用是减少map端的输出,减少shuffle过程中网络传输的数据量,提高作业的执行效率。
- combiner仅仅是单个map task的reduce,没有对全部map的输出做reduce。
- 如果不用combiner,那么,所有的结果都是reduce完成,效率会相对低下。使用combiner,先完成的map会在本地聚合,提升速度。
- 注意:Combiner的输出是Reducer的输入,Combiner绝不能改变最终的计算结果。所以,Combine适合于等幂操作,比如累加,最大值等。
- 求平均数不适合:因为使用combine会提前对部分数据进行计算平均值,这样会对最终的结果平均值产生影响,导致错误。
2、MapJoin
MapJoin用于一个大表和一个小表进行做关联,然后将关联之后的结果之间做输出
MapJoin虽然表面上是没有Reduce阶段的,但是实际上是存在Reduce函数的,只是没有去执行。
- 之所以存在reduce side join,是因为在map阶段不能获取所有需要的join字段,即:同一个key对应的字段可能位于不同map中。Reduce side join是非常低效的,因为shuffle阶段要进行大量的数据传输。
- Map side join是针对以下场景进行的优化:两个待连接表中,有一个表非常大,而另一个表非常小,以至于小表可以直接存放到内存中。这样,我们可以将小表复制多份,让每个map task内存中存在一份(比如存放到hash table中),然后只扫描大表:对于大表中的每一条记录key/value,在hash table中查找是否有相同的key的记录,如果有,则连接后输出即可。
- 为了支持文件的复制,Hadoop提供了一个类DistributedCache,使用该类的方法如下:
- (1)用户使用静态方法DistributedCache.addCacheFile()指定要复制的文件,它的参数是文件的URI(如果是HDFS上的文件,可以这样:hdfs://namenode:9000/home/XXX/file,其中9000是自己配置的NameNode端口号)。JobTracker在作业启动之前会获取这个URI列表,并将相应的文件拷贝到各个TaskTracker的本地磁盘上。
- (2)用户使用DistributedCache.getLocalCacheFiles()方法获取文件目录,并使用标准的文件读写API读取相应的文件。
MapJoin学生实例
①主入口
package com.mr.mapJoin;
import com.shujia.mr.reduceJoin.ReduceJoin;
import com.shujia.mr.reduceJoin.ReduceJoinMapper;
import com.shujia.mr.reduceJoin.ReduceJoinReducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.FileNotFoundException;
import java.io.IOException;
public class MapJoin {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
/*
TODO:
需求:需要使用Map端对基本信息数据和成绩数据进行关联
分析:
① 先读取students.txt文件中的数据
② 通过其他方式再读取score.txt中的数据
问题:
由于需要添加两种文件的数据,同时map函数计算时,是按行读取数据的,上一行和下一行之间没有关系
于是思路:
① 先读取score.txt中的数据到一个HashMap中
② 之后再将HashMap中的数据和按行读取的Students.txt中的每一行数据进行匹配
③ 将关联的结果再进行写出操作
注意:
需要在读取students.txt文件之前就将score.txt数据读取到HashMap中
*/
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "MapJoin");
job.setJarByClass(MapJoin.class);
job.setMapperClass(MapJoinMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// TODO 4.设置数据的输入和输出路径
// 本地路径
FileSystem fileSystem = FileSystem.get(job.getConfiguration());
Path outPath = new Path("hadoop/out/mapJoin");
Path studentInpath = new Path("hadoop/data/students.txt");
// TODO 可以在当前位置将需要在setup函数中获取的路径进行缓存
job.addCacheFile(new Path("hadoop/out/count/part-r-00000").toUri());
if (!fileSystem.exists(studentInpath)) {
throw new FileNotFoundException(studentInpath+"不存在");
}
TextInputFormat.addInputPath(job,studentInpath);
if (fileSystem.exists(outPath)) {
System.out.println("路径存在,开始删除");
fileSystem.delete(outPath,true);
}
TextOutputFormat.setOutputPath(job,outPath);
// TODO 5.提交任务开始执行
job.waitForCompletion(true);
}
}
②Mapper阶段
package com.mr.mapJoin;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.HashMap;
public class MapJoinMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
HashMap<String, Integer> scoreHashMap;
//无参构造方法,构建HashMap,执行一次MapTask任务就会新创建一个HashMap
public MapJoinMapper() {
this.scoreHashMap = new HashMap<>();
}
/**
* 在每个MapTask被执行时,都会先执行一次setup函数,可以用于加载一些数据
*
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void setup(Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
/*
TODO 需要读取 score.txt 中的数据
如果在本地执行,那么可以通过BufferedReader按行读取数据,如果是在HDFS中获取数据
需要通过FileSystem创建IO流进行读取,并且FileSystem也可以读取本地文件系统中的数据
*/
/*
TODO 问题:
① 对于每个MapTask都需要执行一次 setup 函数,那么当MapTask较多时,每个MapTask都保存一个HashMap的Score数据
该数据是保存在内存当中的 于是对于MapJoin有一个使用的前提条件
一个大表和一个小表进行关联,其中将小表的数据加载到集合中,大表按行进行读取数据
同时小表要小到能保存在内存中,没有内存压力 通常是在 25M-40M以内的数据量
*/
/*
TODO 作业:
① 当前代码中完成的是一对一的关系,如果是1对多的关系,如何处理
② 当前实现的是InnerJoin,那么对于leftJoin fullJoin如何实现呢?
*/
//创建配置类
Configuration configuration = context.getConfiguration();
//通过FileSystem创建IO流进行读取
FileSystem fileSystem = FileSystem.get(configuration);
// new Path(filePath).getFileSystem(context.getConfiguration());
// 通过context中的getCacheFiles获取缓存文件路径
URI[] files = context.getCacheFiles();
//使用for循环是方便有多个文件路径的读取
for (URI filePath : files) {
FSDataInputStream open = fileSystem.open(new Path(filePath));
// FSDataInputStream open = fileSystem.open(new Path("hadoop/out/count/part-r-00000"));
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(open));
String oneScore = null;
while ((oneScore = bufferedReader.readLine()) != null) {
String[] column = oneScore.split("\t");
scoreHashMap.put(column[0], Integer.valueOf(column[1]));
}
}
System.out.println("Score数据加载完成,已存储到HashMap中");
}
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
// 1500100004,葛德曜,24,男,理科三班
String oneStuInfo = value.toString();
String[] columns = oneStuInfo.split(",");
if (columns.length == 5) {
String id = columns[0];
// TODO 通过HashMap获取数据,如果没有获取到,那么阁下如何应对?
Integer score = scoreHashMap.get(id);
oneStuInfo += (","+score);
context.write(new Text(oneStuInfo), NullWritable.get());
}
}
}
MapReduce高级
1、小文件合并
- CombineFileInputFormat
CombineFileInputFormat是一种新的inputformat,用于将多个文件合并成一个单独的split作为输入,而不是通常使用一个文件作为输入。另外,它会考虑数据的存储位置。
相当于合并之后启动的MapTask会考虑原先文件的位置去处理它,不会影响原来文件的数据。
- 当MapReduce的数据源中小文件过多,那么根据FileInputFormat类中的GetSplit函数加载数据,会产生大量的切片从而导致启动过多的MapTask任务,MapTask启动过多会导致申请过多资源,并且MapTask启动较慢,执行过程较长,效率又较低
- 解决方法:
- 可以使用MR中的combineTextInputFormat类,在形成数据切片时,可以对小文件进行合并,从而减少MapTask任务的数量
- 小文件合并的用处:
- 如上述在MapReduce做计算时
- 在HDFS上NameNode存储了整个HDFS上的文件信息,,并且是存储在内存中,由于内存空间有限,那么小文件合并就可以用于HDFS上某个路径下产生的多个小文件进行合并,合并成大的文件,有利于减少HDFS上的文件数量。
- 小文件合并的原理

2、输出类及其自定义
- 对于文本文件输出MapReduce中使用FileOutputFormat类作为默认输出类,但是如果要对输出的结果文件进行修改,那么需要对输出过程进行自定义。
- 而自定义输出类需要继承FileOutputFormat 并在RecordWriter中根据输出逻辑将对应函数进行重写
3、Yarn工作流程及其常用命令
3.1Yarn的工作流程
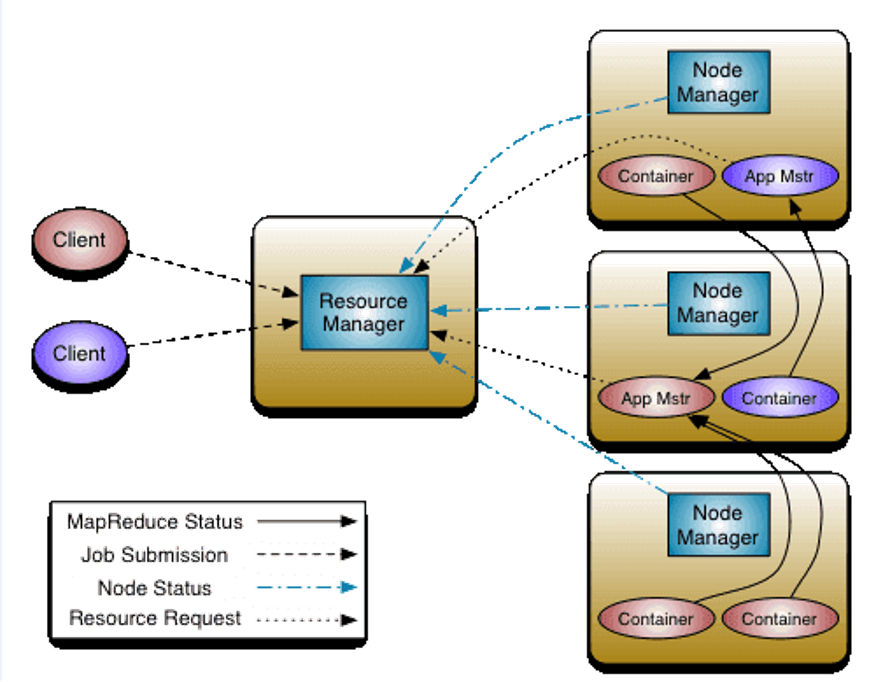
Yarn的主要组件构成如下
- YARN Client
- YARN Client提交Application到RM,它会首先创建一个Application上下文对象,并设置AM必需的资源请求信息,然后提交到RM。YARN Client也可以与RM通信,获取到一个已经提交并运行的Application的状态信息等。
- ResourceManager(RM)
- RM是YARN集群的Master,负责管理整个集群的资源和资源分配。RM作为集群资源的管理和调度的角色,如果存在单点故障,则整个集群的资源都无法使用。在2.4.0版本才新增了RM HA的特性,这样就增加了RM的可用性。
- NodeManager(NM)
- NM是YARN集群的Slave,是集群中实际拥有实际资源的工作节点。我们提交Job以后,会将组成Job的多个Task调度到对应的NM上进行执行。Hadoop集群中,为了获得分布式计算中的Locality特性,会将DN和NM在同一个节点上运行,这样对应的HDFS上的Block可能就在本地,而无需在网络间进行数据的传输。
- Container
- Container是YARN集群中资源的抽象,将NM上的资源进行量化,根据需要组装成一个个Container,然后服务于已授权资源的计算任务。计算任务在完成计算后,系统会回收资源,以供后续计算任务申请使用。Container包含两种资源:内存和CPU,后续Hadoop版本可能会增加硬盘、网络等资源。
- ApplicationMaster(AM)
- AM主要管理和监控部署在YARN集群上的Application,以MapReduce为例,MapReduce Application是一个用来处理MapReduce计算的服务框架程序,为用户编写的MapReduce程序提供运行时支持。通常我们在编写的一个MapReduce程序可能包含多个Map Task或Reduce Task,而各个Task的运行管理与监控都是由这个MapReduceApplication来负责,比如运行Task的资源申请,由AM向RM申请;启动/停止NM上某Task的对应的Container,由AM向NM请求来完成。
那么Yarn是如何执行一个MapReduce job的
- 首先,Resource Manager会为每一个application(比如一个用户提交的MapReduce Job) 在NodeManager里面申请一个container,然后在该container里面启动一个Application Master。 container在Yarn中是分配资源的容器(内存、cpu、硬盘等),它启动时便会相应启动一个JVM(Java的虚拟机)。然后,Application Master便陆续为application包含的每一个task(一个Map task或Reduce task)向Resource Manager申请一个container。等每得到一个container后,便要求该container所属的NodeManager将此container启动,然后就在这个container里面执行相应的task
等这个task执行完后,这个container便会被NodeManager收回,而container所拥有的JVM也相应地被退出。 - Yarn执行的流程图简图如下
3.2Yarn配置历史服务器
- historyserver进程作用
- 把之前本来散落在nodemanager节点上的日志统计收集到hdfs上的指定目录中
- 启动historyserver
修改相关的配置信息在记事本笔记中
-
执行sbin/mr-jobhistory-daemon.sh start historyserver
-
通过master:19888观察
-
当提交了一个MapReduce任务到HDFS上,正常执行完成之后,就可以在master:8088即yarn平台上查看执行完的日志信息
-
在yarn页面上点击RUNNING,就可以看到有对应执行完的一个文件,然后点击logs就可以查看日志信息
3.3Yarn常用命令
- application 选项:
- 前面都是默认的yarn application
- -list 列出RM中的应用程序,可以和-appStates搭配使用
- -appStates
查看对应状态的应用程序States可以为 SUBMITTED,ACCEPTED, - RUNNING,FINISHED,FAILED,KILLED
- -kill
强制杀死应用程序 - -status
查看应用状态
4、Yarn调度器
- 在实际开发过程中,由于服务器的计算资源,包括CPU和内存都是有限的,对于一个经常存在任务执行的集群,一个应用资源的请求经常需要等待一段时间才能的到相应的资源,而Yarn中分配资源的就是Scheduler。并且根据不同的应用场景,对应调度器的策略也不相同。Yarn中存在有三种调度器可以选择 ,分别为FIFO Scheduler 、 Capacity Scheduler 、 Fair Scheduler
4.1FIFO Scheduler
- FIFO Scheduler也叫先进先出调度器,根据业务提交的顺序,排成一个队列,先提交的先执行,并且执行时可以申请整个集群中的资源。逻辑简单,使用方便,但是容易导致其他应用获取资源被阻塞,所以生产过程中很少使用该调度器
- 不常用,比较浪费资源
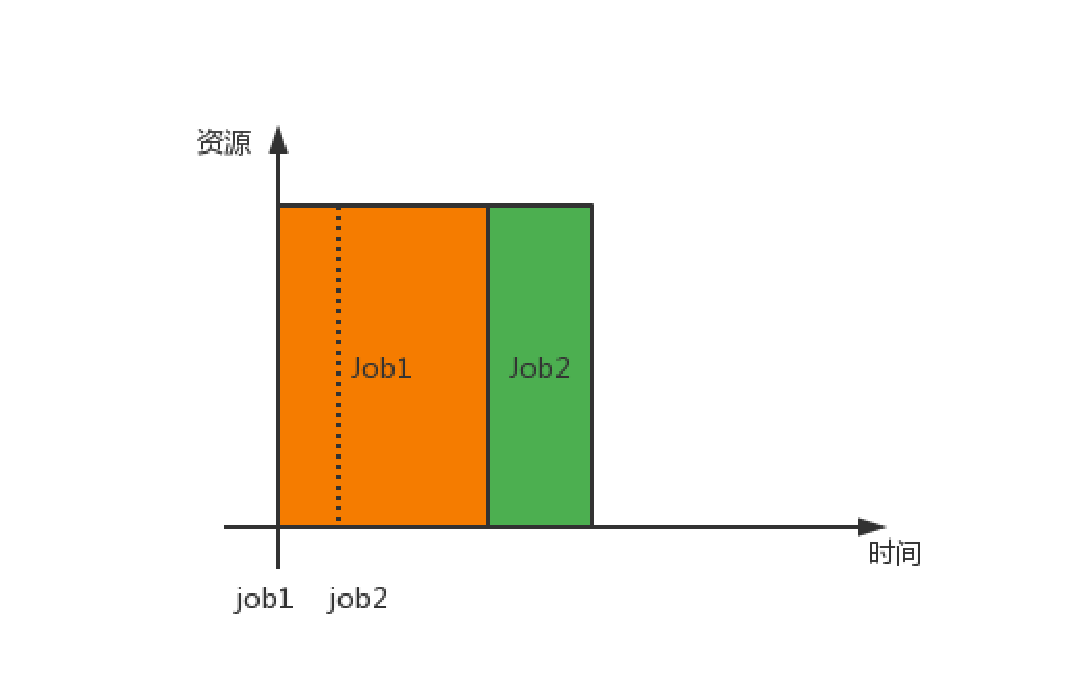
4.2Capacity Scheduler
- Capacity Scheduler 也称为容量调度器,是Apache默认的调度策略,对于多个部门同时使用一个集群获取计算资源时,可以为每个部门分配一个队列,而每个队列中可以获取到一部分资源,并且在队列内部符合FIFO Scheduler调度规则
- yarn默认的资源调度器
- yarn执行框架里使用的就是容量调度器
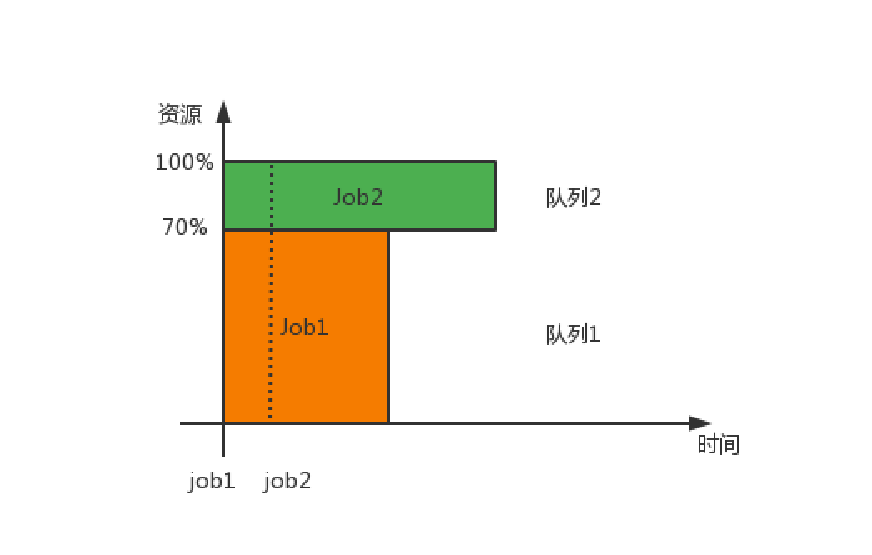
4.3Fair Scheduler
- Fair Scheduler 也称为公平调度器,现在是CDH默认的调度策略,公平调度在也可以在多个队列间工作,并且该策略会动态调整每个作业的资源使用情况
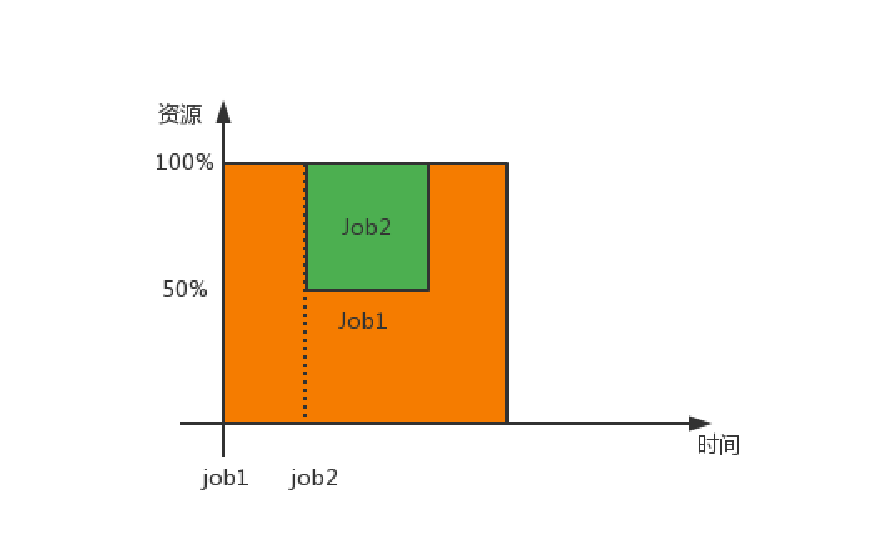
对公平调度器的相关解释
当有新的任务需要资源时,Fair调度器会尝试通过动态调整资源分配,来满足新任务的需求。通常情况下,Fair调度器会根据任务的优先级和资源需求,合理地重新分配资源。这可能包括降低之前任务的资源配额,或者在后续资源分配时优先给新任务。
如果之前的任务持续占用大量资源,而新任务的资源需求更为紧急或重要,Fair调度器可能会考虑终止或迁移一些之前的任务,以释放资源给新任务。尽管这可能影响到之前任务的运行,但Fair调度器会在尽可能保证资源公平的前提下,尽量减少对正在运行的任务的影响。
- 如果一个job1任务开始提交,调用了全部的资源调度器里的MapTask,那么当job2任务也开始提交执行时,资源调度器会将job1的50%的资源分配给job2,同时,如果job1对应50%的资源上执行的任务没有完成之前的任务,那么资源调度器会直接将其kill杀死,即之前的工作都被杀死了,等job2执行完成,该部分的工作任务会从头开始重新执行。
- 注意:对于同等优先级的job任务会平均分配剩余的全部资源,相当于同部门之间是同等级分配资源,不同部门之间也是同等级的,同样的平均分配总资源。