一个Flink程序,就是对DataStream进行各种转换。基本上由以下几部分构成

接下来分别从执行环境、数据源、转换操作、输出四大部分,介绍DataStream API。
导入Scala DataStream Api
import org.apache.flink.streaming.api.scala._
CH-5 DataStream API基础
一、执行环境
1.1 创建执行环境
-
getExecutionEnvironment:这个方法会根据运行环境返回正确结果。如果是独立运行的,返回本地执行环境
如果是创建了jar包,通过命令行提交到集群执行,返回集群执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment -
createLocalEnvironment:返回本地执行环境。可接收参数,指定默认的并行度;如果不传入,则默认并行度就是本地的CPU核心数。
-
createRemoteEnvironment:返回集群执行环境。需要指定JobManager的主机名和端口,并指定要运行的jar包。

1.2 执行模式
Flink 1.12.0之前的版本,批处理是调用类ExecutionEnvironment的静态方法,并返回它的对象:
val env = ExecutionEnvironment.getExecutionEnvironment
但之后的版本已经流批一体,直接使用StreamExecutionEnvironment创建环境即可,之后通过启动参数配置运行模式
-
流执行模式(STREAMING)。
经典模式,用于需要持续实时处理的无界数据流。默认就是此模式
-
批执行模式(BATCH)。
专门用于批处理的执行模式,该模式下,Flink处理作业的方式类似于MapReduce框架。
-
自动模式(AUTOMATIC)。程序会根据输入数据源是否有界,自动选择执行模式。
配置执行模式
-
通过命令行配置
bin/flink run -Dexecution.runtime-mode=BATCH -
通过代码配置
val env = StreamExecutionEnvironment.getExecutionEnvironment env.setRuntimeMode(RuntimeExecutionMode.BATCH)
建议通过命令行配置模式,更加灵活,无需修改代码
二、数据源
2.1 从集合中读取
import org.apache.flink.api.common.RuntimeExecutionMode
import org.apache.flink.streaming.api.scala._
case class Event(user: String, url: String, timestamp: Long)
object Main {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setRuntimeMode(RuntimeExecutionMode.BATCH)
val clicks = List(Event("Mary", "/.home", 1000L), Event("Bob", "/.cart", 2000L))
val stream = env.fromCollection(clicks)
stream.print
env.execute()
}
}
或者fromElements也可以
env.fromElements(Event("Mary", "/.home", 1000L), Event("Bob", "/.cart", 2000L)).print()
2.2 从文件中读取
val fileStream = env.readTextFile("file.txt")
fileStream
.flatMap(_.split(" "))
.print()
-
参数可以是目录,也可以是文件。
-
相对路径在IDEA下是项目根目录,standalone模式下是集群节点根目录。
-
支持对HDFS读取,使用路径hdfs://...,需要添加hadoop依赖
<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.3.5</version> </dependency>
2.3 从Socket读取
val stream = env.socketTextStream("localhost", 9999)
2.4 从其他读取
Flink提供了很多connector,比如mysql,kafka等,可添加相关依赖,然后使用Flink进行读取,这里略过
2.5 自定义数据源
实现SourceFunction接口,重写run和cancel方法
run:使用SourceContext向下游发送数据cancel:通过标识位控制退出循环,从而中断数据源
case class Event(user: String, url: String, timestamp: Long)
class ClickSource extends SourceFunction[Event]{
private var running = true
override def run(ctx: SourceFunction.SourceContext[Event]): Unit = {
val random = new Random
val users = Array("Mary", "Bob", "Alice", "Cary")
val urls = Array("./home", "./cart", "./fav", "./prod?id=1", "./prod?id=2")
while(running) {
ctx.collect(
Event(
users(random.nextInt(users.length)),
urls(random.nextInt(urls.length)),
Calendar.getInstance.getTimeInMillis
)
)
}
Thread.sleep(1000)
}
override def cancel(): Unit =
running = false
}
并行数据源需要实现ParallelSourceFunction
三、数据转换
1.map()
一个输入对应一个输出
需要重写map()方法或使用lambda
streamSource.map((String word) -> {
word += "aabb";
return word;
})
2.filter()
true代表通过,false代表拦截

streamSource.filter(word -> {
if(word.equals("hadoop") || word.equals("spark")) return false;
else return true;
}).print();
3.flatMap()
一个输入可以对应零或多个输出。
虽然flatMap()可以替代map()和filter(),但Flink未删除,因为map()和filter()语义更明确,明确的语义增强代码的可读性:
map()表示一对一的转换,代码阅读者能够确认对于一个输入,肯定只有一个输出;
filter()表示过滤。
streamSource.flatMap((String line, Collector<Tuple2<String, Integer>> collector) -> {
collector.collect(Tuple2.of("abc", 1));
})
.returns(Types.TUPLE(Types.STRING, Types.INT))
.print();
4. Project()
DataStreamSource<Tuple3<String, String, Integer>> users = env.fromElements(
Tuple3.of("佩奇", "女", 5), Tuple3.of("乔治", "男", 3)
);
users.project(0, 2).print(); //只会保留第0和第3个字段
3.2 分组
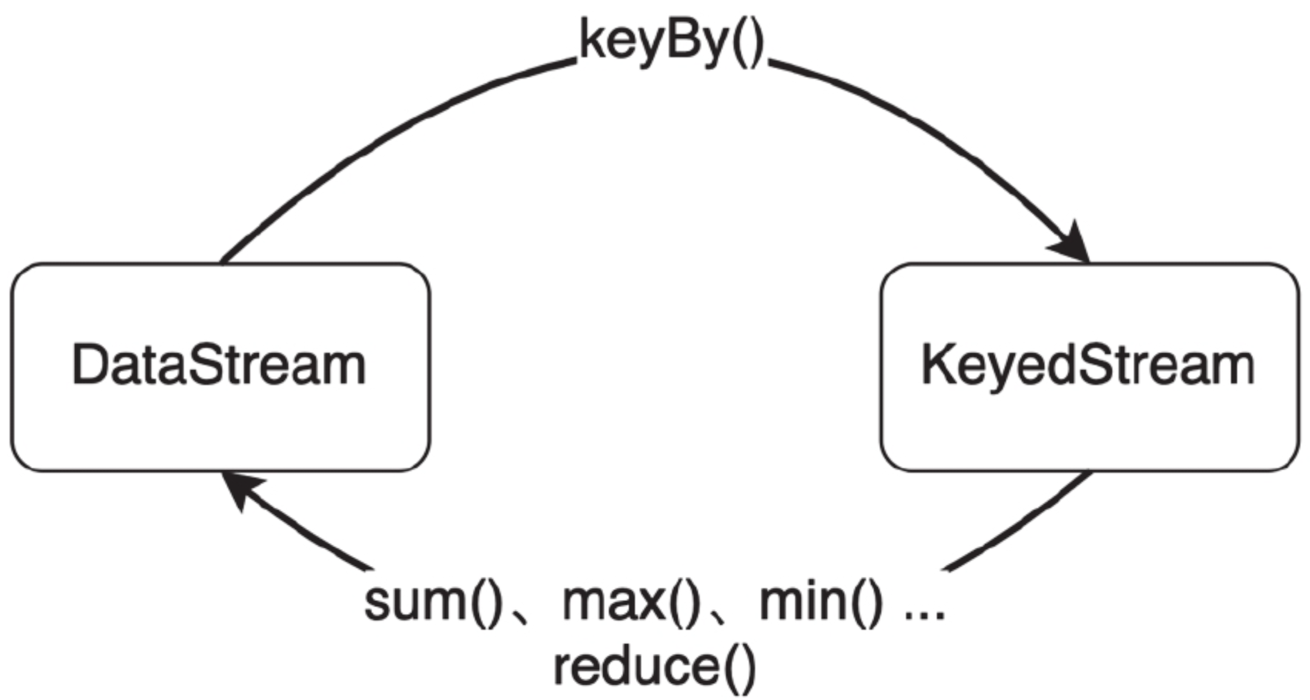
对数据分组,之后可按组进行聚合分析,
keyBy()会将DataStream转换为KeyedStream,
聚合操作会将KeyedStream转回DataStream。
若聚合前数据类型是T,聚合后的类型仍为T。
1.keyBy()
使用某个字段进行分组,为后续使用
可通过位置、字段名、KeySelector选择分组字段
内部原理是计算key的哈希值,之后对分区数进行取模来确定分区。
// 1.使用字段位置分组
// 按第一个字段进行分组
DataStream<Tuple2<Integer, Double>> keyedStream = dataStream.keyBy(0).sum(1);
// 2.使用字段名分组
public class Word {
public String word;
public int count;
}
DataStream<Word> fieldNameStream = wordStream.keyBy("word").sum("count");
// 重写KeySelector - 推荐
DataStream<Word> keySelectorStream = wordStream.keyBy(new KeySelector<Word, String>
() {
@Override
public String getKey(Word in) {
return in.word;
}
}).sum("count");
考虑到类型安全,Flink推荐使用
KeySelector,不推荐数字位置和字段名,这两个接口也被标记为废弃
3.3 聚合
- 需要指定聚合字段,可使用数字位置或实现KeySelector
- 对于一个KeyedStream,只能使用一个聚合函数,无法链式使用多个。之后需要重新分组再聚合
1.sum()
对指定字段求和,并将结果保存在该字段中,
在结果中,除求和字段外,其他字段的值是第一条输入数据的值
(0, 0, 0)(0, 1, 1)(0, 2, 2)(1, 0, 6)(1, 1, 7)(1, 0, 8)
// 按第1个字段分组,对第2个字段求和
DataStream<Tuple3<Integer, Integer, Integer>> sumStream =
tupleStream.keyBy(0).sum(1);
2. max()
对指定字段求最大值,并将结果保存在该字段中。
在结果中,除最大值字段外,其他字段是第一条输入数据的值
3 .maxBy()
maxBy()会返回最小值所在的整条数据
比如有以下元素
(0,1,3)
(0,2,7)
(0,3,5)
(0,4,6)
如果对pos = 1的字段使用,最终结果,2号字段必然是4,但是3号字段可能是3、7、5或者6都有可能,取决于设施第一个进入算子的元素
如果使用的是maxBy(),那么最终结果一定是(0,4,6)
4.min()和minBy()
同上
5.reduce()
接收两个输入,生成一个输出
数据流按照用户id分区,
第一个reduce实现sum,统计用户访问频次,进而将所有统计结果分到一组,
第二个reduce()实现maxBy(),记录访问量最大的用户。
object Main {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.addSource(new ClickSource)
stream
.map(r => (r.user, 1L))
.keyBy(_._1)
.reduce((r1, r2) => (r1._1, r1._2 + r2._2))
.keyBy(_._1)
.reduce((r1, r2) => if (r1._2 > r2._2) r1 else r2)
.print()
env.execute()
}
}
6. 自定义函数
-
函数类
接口包括
MapFunction,FilterFunction,ReduceFunction比如实现Filter,删除包含home的元素
class FlinkFilter extends FilterFunction[String] { override def filter(value: String): Boolean = value.contains("home") }也可直接传入lambda
-
富函数类
富函数类提供了
getRuntimeContext()方法,可获取运行时上下文,例如程序执行的并行度、任务名称,以及状态(state)。这使得我们可以大大扩展程序的功能,特别是对于状态的操作,使得Flink中的算子具备了处理复杂业务的能- open():初始化方法。在调用算子工作方法之前,例如map()或者filter()方法,会先调用open()。所以像文件IO流的创建,数据库连接的创建,配置文件的读取等工作,适合在open()中完成。
- close()方法是生命周期中最后一个调用的方法,类似于析构方法。一般用来做一些清理工作
实现一个RichMapFunction案例
object Main { def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment env.fromElements( Event("Mary", "./home", 1000L), Event("Bob", "./cart", 2000L), Event("Alice", "./prod?id=1", 1000L), Event("Cary", "./home", 60*1000L) ) .map(new RichMapFunction[Event, Long] { override def open(openContext: OpenContext): Unit = { println("索引为 " + getRuntimeContext.getTaskInfo.getIndexOfThisSubtask + " 的任务开始") } override def map(value: Event): Long = value.timestamp override def close(): Unit = { println("索引为 " + getRuntimeContext.getTaskInfo.getIndexOfThisSubtask + " 的任务结束") } }) .print() env.execute() } }
3.4 分区
当上下游算子个数发生变化时,需要调整分区,保持数据均匀分布,分区前后数据本身不会改变
常见的分区策略:随机分区、轮询分区、重缩放和广播、全局分区、自定义分区策略,
1. 随机分区
直接调用shuffle()
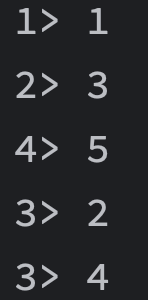
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.fromElements(1, 2, 3, 4, 5)
stream.shuffle.print().setParallelism(4)
env.execute()
运行结果如下,且每次都不一样,因为是随机的
2. 轮询分区
使用Round-Robin算法,就是顺序轮询,类似发牌,
比如有5个元素a,b,c,d,e,要发给3个接收端1,2,3,发送顺序将会如下
a->1, b->2, c->3, d->1, e->2
调用rebalance()进行轮询发送
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.fromElements('a','b','c','d','e')
stream.rebalance.print().setParallelism(3)
env.execute()
结果如下

因为并行,所以打印顺序混乱,但元素接收顺序的确是轮询的,
a->2, b->3, c->1, d->2, e->3
3. 重缩放
和轮询分区算法相同,区别在于重缩放只会发送数据到下游的部分算子,rebalance是向所有接收端顺序发牌,重缩放则是将接收端分组,每个发送端只向属于自己的接收分组顺序发牌
rebalance()面向所有分区发送,当数据量增多,这种跨节点的网络传输会影响效率;而如果配置的slot数量合适,用rescale()进行“局部重缩放”,可让数据只在当前TaskManager的多个slots之间重新分配,从而避免了网络传输带来的损耗。
下面给出一个实例
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.addSource(
new RichParallelSourceFunction[Int] {
override def run(ctx: SourceFunction.SourceContext[Int]): Unit = {
for (i <- 0 to 7) {
if((i + 1) % 2 == getRuntimeContext.getIndexOfThisSubtask) {
ctx.collect(i + 1)
}
}
}
override def cancel(): Unit = ???
}
)
.setParallelism(2)
.rescale
.print
.setParallelism(2)
env.execute()
-
设置Source的并行度为2,会同时启动两个Source:0和1号,偶数会发送给0号,奇数会发送给1号,因此此时0号持有
1,3,5,7,1号持有2,4,6,8 -
调用rescale,并将并行度设置为4, 此时0号会发送数据给0和1,1号会发送给2和3
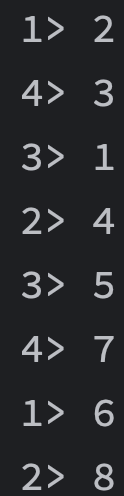
1号持有2,6 2号持有4,8 3号持有1,5 4号持有3,7
4. 广播
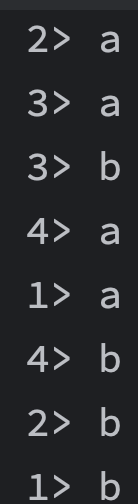
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.fromElements('a', 'b')
stream.broadcast.print.setParallelism(4)
env.execute()
将输入数据给所有接收端都发送一整份
结果如图
5. 全局分区
调用.global方法实现,会讲所有数据都发送到下游算子的第一个slot中,相当于并行度缩减为了1,
6. 自定义分区
通过partitionCustom()定义分区策略。
需要两个参数,
- 自定义分区器
- 应用分区器的字段,可通过字段名或字段位置索引来指定,也可实现KeySelector接口
案例:按照奇偶对数据进行分区
env
.fromElements(1,2,3,4,5,6,7,8)
.partitionCustom(
new Partitioner[Int] {
override def partition(key: Int, numPartitions: Int): Int = key % 2
}, data => data
)
.print
env.execute()
四、输出
4.1 输出到文件
基础方法:writeAsText()和writeAsCsv(),这些方法不支持同时写入到文件,需要将Sink的并行度设为1,大大降低了系统效率;而且也不保证故障恢复后的状态一致性,所以要被弃用了。
StreamingFileSink:为批和流处理提供了一个统一的Sink,将分区文件写入Flink支持的文件系统。会将数据写入桶(buckets),每个桶中的数据都可以分割成一个个大小有限的分区文件,这样一来就实现了真正意义上的分布式文件存储。我们可以通过各种配置来控制“分桶”的操作;默认的分桶方式是基于时间的,我们每小时写入一个新桶。换句话说,每个桶内保存的文件,记录的都是1小时的输出数据。
val env = StreamExecutionEnvironment.getExecutionEnvironment
val fileSink = StreamingFileSink.forRowFormat(
new Path("./output"),
new SimpleStringEncoder[Char]()
).withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofSeconds(5))
.withInactivityInterval(Duration.ofSeconds(1))
.withMaxPartSize(MemorySize.parse("1024"))
.build()
).build()
env.addSource(new CharSource).addSink(fileSink).setParallelism(2)
env.execute()