摘要:YOLOv3(You Only Look Once version 3)是一种高效的目标检测算法,旨在实现快速而准确的对象检测。
本文分享自华为云社区《华为云开发者云主机体验【玩转华为云】》,作者: DS小龙哥。
一、前言
云主机是华为云为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具体系,让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
二、领取云主机
领取地址:https://developer.huaweicloud.com/developerspace
申请之后,会提示加入开发者空间,根据提示选择配置就行了。
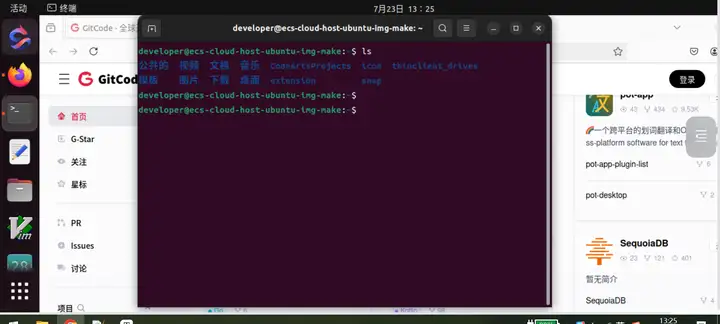
配置之后。在这里可以进去云主机的公众空间。
第一次配置,初始化需要一点时间。
初始化完毕之后,就可以进去桌面体验了。
下面是进入桌面的提示状态。

进去桌面后的效果。
直接在浏览器里访问很方面。 非常方便在Linux环境下做项目开发测试。
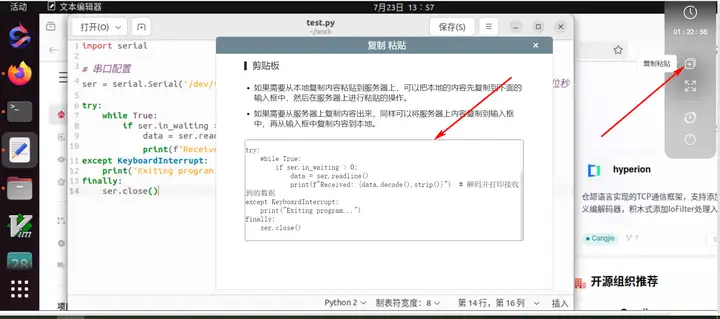
对于复制粘贴,本地电脑不能直接copy,需要使用工具进行安全的复制粘贴。
三、快速体验YOLOV3
YOLOv3(You Only Look Once version 3)是一种高效的目标检测算法,由Joseph Redmon等人开发。它是YOLO系列算法的第三个版本,旨在实现快速而准确的对象检测。与传统的两阶段目标检测方法(如R-CNN系列算法)不同,YOLOv3采用了一次性(single-shot)检测方法,这意味着它可以在一个单一的神经网络前向传播过程中同时完成对象分类和边界框回归。
YOLOv3的主要特性包括:
- 主干网络:YOLOv3使用Darknet-53作为其基础网络,这是对YOLOv2中Darknet-19的一个深度增强版,提供了更好的特征提取能力。
- 多尺度检测:YOLOv3采用了特征金字塔网络(Feature Pyramid Network,FPN)的概念,实现了在三个不同的尺度上进行检测,分别是13x13、26x26和52x53的特征图分辨率,这有助于检测不同大小的对象。
- 锚框(Anchor Boxes):YOLOv3使用预定义的锚框来预测对象的位置,这些锚框是通过对训练数据集中对象的尺寸进行聚类得到的。
- 分类器:在对象分类方面,YOLOv3使用Logistic回归来预测每个类别的概率,这允许它处理包含多个标签的对象,即一个对象可能属于多个类别的情况。
- 损失函数:YOLOv3的损失函数综合考虑了边界框坐标、对象存在性和类别预测的误差。
- 训练和预测:YOLOv3能够在单张图像上同时预测多个对象,且由于其一次性检测的特性,它能实现实时处理速度,非常适合实时视频流处理等场景。
YOLOv3因其在速度与精度之间的良好平衡而在工业界和学术界得到了广泛应用。随着后续版本如YOLOv4和YOLOv5的推出,虽然YOLOv3可能不再是最新版本,但它仍然是理解和实现现代目标检测算法的重要基准。
YOLO算法官网介绍:https://pjreddie.com/darknet/yolo/
You only look once (YOLO) is a state-of-the-art, real-time object detection system. On a Pascal Titan X it processes images at 30 FPS and has a mAP of 57.9% on COCO test-dev.
You Only Look Once (YOLO) 是最先进的实时目标检测系统。在 Pascal Titan X 上,它以 30 FPS 处理图像,并且在 COCO 测试开发上的 mAP 为 57.9%。
Comparison to Other Detectors YOLOv3 is extremely fast and accurate. In mAP measured at .5 IOU YOLOv3 is on par with Focal Loss but about 4x faster. Moreover, you can easily tradeoff between speed and accuracy simply by changing the size of the model, no retraining required!
与其他探测器的比较 YOLOv3 非常快速且准确。在 mAP 中,测量结果为 0.5 IOU YOLOv3 与 Focal Loss 相当,但速度快约 4 倍。此外,只需更改模型的大小即可轻松在速度和准确性之间进行权衡,无需重新训练!
在Linux下快速体验YOLO算法的目标检测(采用官方的模型)。
(1)安装darknet
git clone https://github.com/pjreddie/darknet cd darknet make
如果克隆失败,多试几次即可。
编译中:
(2)下载权重文件
wget https://pjreddie.com/media/files/yolov3.weights
yolov3.weights 是 YOLOv3 网络训练得到的权重文件,存储了神经网络中每个层次的权重和偏置信息。
在cfg/目录下已经包含了yolov3对应的配置文件。
权重文件下载中:
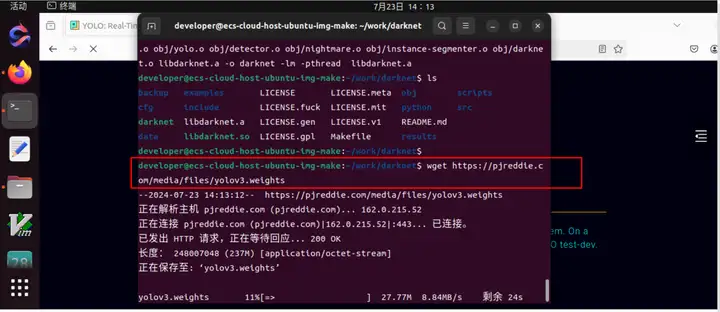
(3)运行detector
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
运行输出的信息:
layer filters size input output
0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32 0.299 BFLOPs
1 conv 64 3 x 3 / 2 416 x 416 x 32 -> 208 x 208 x 64 1.595 BFLOPs
.......
105 conv 255 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 255 0.353 BFLOPs
106 detection
truth_thresh: Using default '1.000000'
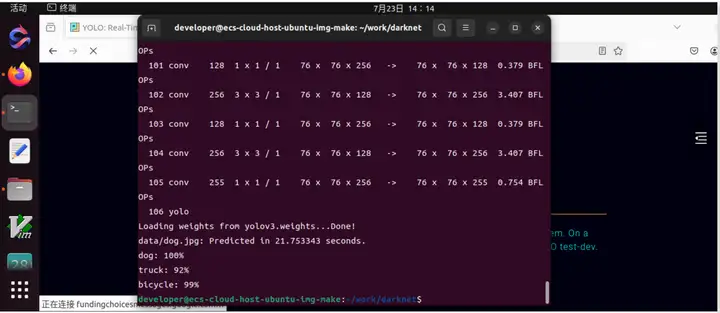
Loading weights from yolov3.weights...Done!
data/dog.jpg: Predicted in 0.029329 seconds.
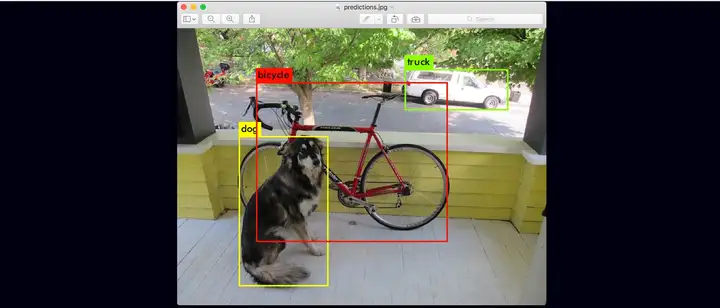
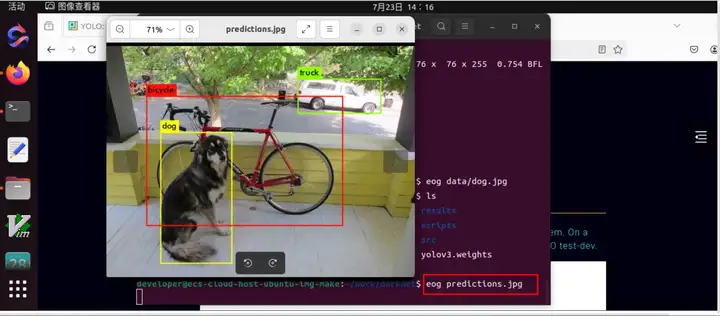
dog: 99%
truck: 93%
bicycle: 99%
运行过程:
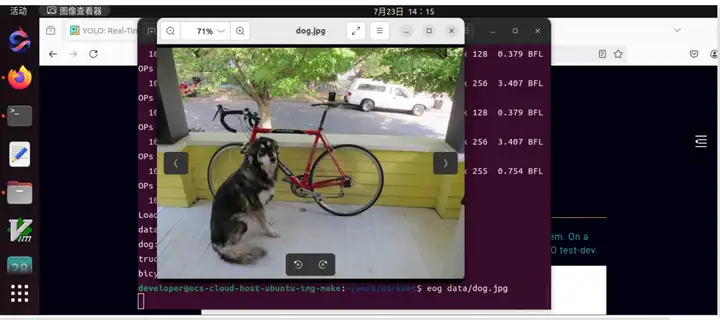
查看原来图片:
查看识别成功的图片:
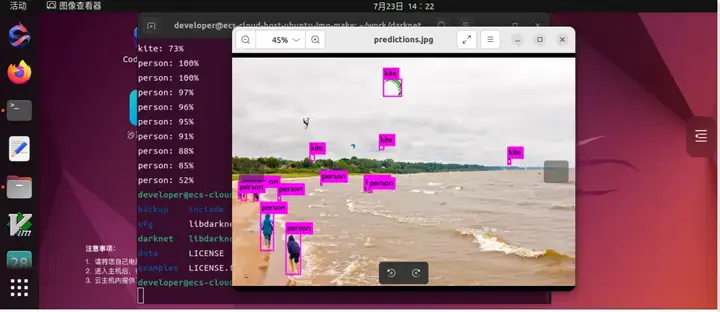
识别测试2:
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights <video file>
如果想实时识别视频,可以运行下面的命令:
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights <video file>
标签:YOLOv3,cfg,darknet,华为,YOLOV3,玩转,检测,yolov3,开发者 From: https://www.cnblogs.com/huaweiyun/p/18342802