缓存优化(缓存穿透)
缓存穿透
- 缓存穿透是指查询一个一定不存在的数据时,数据库查询不到数据,也不会写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,可能导致数据库崩溃。
- 这种情况大概率是遭到了攻击。
- 常见的解决方案有:缓存空数据,使用布隆过滤器等。
当前项目中存在的问题
-
当前项目中,用户端会大量访问的数据,即菜品数据和套餐数据,会被按照其分类id缓存在redis中。当用户查询某个分类下的菜品时,首先会查询redis中是否有这个分类id的数据,如果有就直接返回,否则就去查询数据库并将查询到的数据返回,同时会将查询到的数据存入redis缓存。
-
假如查询的数据在数据库中不存在,那么就会将空数据缓存在redis中。
-
缓存空数据的优点是实现简单,但是它也有缺点:会消耗额外的内存。尤其是在当前项目中,缓存在redis中的数据都没有设置过期时间,因此缓存的空数据只会越来越多,直到把redis的内存中间占满。
解决方案
使用redisson提供的布隆过滤器作为拦截器,拒绝掉不存在的数据的绝大多数查询请求。
布隆过滤器
布隆过滤器主要用于检索一个元素是否在一个集合中。如果布隆过滤器认为该元素不存在,那么它就一定不存在。
底层数据结构
- 布隆过滤器的底层数据结构为bitmap+哈希映射。
- bitmap其实就是一个数组,它只存储二进制数0或1,也就是按位(bit)存储。哈希映射就是使用哈希函数将原来的数据映射为哈希值,一个数据只对应一个哈希值,这样就能够判断之后输入的值是不是原来的数据了。但是哈希映射可能会出现哈希冲突,即多个数据映射为同一个哈希值。
具体的算法步骤为:
- 初始化一个较大的bitmap,每个索引的初始值为0,并指定数个哈希函数(比如3个)。
- 存储数据时,使用这些哈希函数处理输入的数据得到多个哈希值,再使用这些哈希值模上bitmap的大小,将余数位置的值置为1。
- 查询数据时,使用相同的哈希函数处理输入的数据得到多个哈希值,模上bitmap的大小后判断对应位置是否都为1,如果有一个不为1,布隆过滤器就认为这个数不存在。
- 由于哈希映射本来就存在哈希冲突,并且查询时,计算得到的索引处的值虽然都是1,但却是不同数据计算得到的。所以布隆过滤器存在误判。数组越大误判率越小,数组越小误判率越大,我们可以通过调整数组大小来控制误判率。
优点
内存占用较少,缓存中没有多余的空数据键。
缺点
实现复杂,存在误判,难以删除。
代码开发
配置redisson
- 在pom.xml中引入redisson的依赖:
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.33.0</version>
</dependency>
- 在sky-commom包下的com.sky.properties包下创建RedisProperties类,用于配置redisson:
@Component
@ConfigurationProperties(prefix = "spring.redis")
@Data
public class RedisProperties {
/**
* redis相关配置
*/
private String host;
private String port;
private String password;
private int database;
}
- 配置redisson,在com.sky.config包下创建RedissonConfiguration类并创建redissonClient的Bean对象:
@Configuration
@Slf4j
public class RedissionConfiguration {
@Autowired
private RedisProperties redisProperties;
@Bean
public RedissonClient redissonClient() {
log.info("开始创建redisson客户端对象...");
//拼接redis地址
StringBuffer address = new StringBuffer("redis://");
address.append(redisProperties.getHost()).append(":").append(redisProperties.getPort());
//创建并配置redisson客户端对象
Config config = new Config();
config.setCodec(StringCodec.INSTANCE)
.useSingleServer()
.setAddress(address.toString())
.setPassword(redisProperties.getPassword())
.setDatabase(redisProperties.getDatabase());
return Redisson.create(config);
}
}
配置布隆过滤器
- 在配置文件application.yml中引入布隆过滤器相关配置:
spring
bloom-filter:
expected-insertions: 100
false-probability: 0.01
- 配置布隆过滤器,在com.sky.config包下创建BloomFilterConfiguration类并创建bloomFilter的Bean对象:
@Configuration
@Slf4j
public class BloomFilterConfiguration {
@Autowired
private RedissonClient redissonClient;
@Autowired
private CategoryMapper categoryMapper;
@Value("${spring.bloom-filter.expected-insertions}")
private long expectedInsertions;
@Value("${spring.bloom-filter.false-probability}")
private double falseProbability;
/**
* 创建并预热布隆过滤器
*/
@Bean("bloomFilter")
public RBloomFilter<Integer> init() {
log.info("开始创建布隆过滤器...");
RBloomFilter<Integer> bloomFilter = redissonClient.getBloomFilter("BloomFilter", StringCodec.INSTANCE);
bloomFilter.tryInit(expectedInsertions, falseProbability);
log.info("开始预热布隆过滤器...");
//查询所有的分类id
List<Integer> CategoryIds = categoryMapper.getCategoryIdsByStatus(StatusConstant.ENABLE);
//预热布隆过滤器
bloomFilter.add(CategoryIds);
return bloomFilter;
}
}
- 在CategoryMapper接口中创建getCategoryIdsByStatus方法:
@Select("select id from category where status = #{status}")
List<Integer> getCategoryIdsByStatus(Integer status);
配置布隆过滤器的拦截器
- 在com.sky.interceptor包下创建BloomFilterInterceptor类并编写布隆过滤器拦截器的校验逻辑:
@Component
@Slf4j
public class BloomFilterInterceptor implements HandlerInterceptor {
@Autowired
private RBloomFilter bloomFilter;
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) {
//判断当前拦截到的是Controller的方法还是其他资源
if (!(handler instanceof HandlerMethod)) {
//当前拦截到的不是动态方法,直接放行
return true;
}
//1、从查询参数中获取分类id
String categoryId = request.getQueryString().split("=")[1];
//2、校验分类id
try {
log.info("布隆过滤器校验:{}", categoryId);
if (bloomFilter.contains(Integer.valueOf(categoryId))) {
//3、通过,放行
log.info("布隆过滤器校验通过");
return true;
} else {
//4、不通过,抛出分类不存在异常
log.info("布隆过滤器校验不通过");
throw new CategoryIdNotFoundException(MessageConstant.CATEGORY_ID_NOT_FOUND);
}
} catch (Exception ex) {
//4、并响应404状态码
response.setStatus(404);
return false;
}
}
}
- 在MessageConstant类中增加一条信息提示常量,用于拦截器抛出:
public class MessageConstant {
...
public static final String CATEGORY_ID_NOT_FOUND = "分类不存在";
}
- 在sky-common模块下的com.sky.exception包下创建新的异常类CategoryIdNotFoundException类,用于拦截器抛出:
public class CategoryIdNotFoundException extends BaseException {
public CategoryIdNotFoundException() {
}
public CategoryIdNotFoundException(String msg) {
super(msg);
}
}
注册布隆过滤器的拦截器
- 在配置类WebMvcConfiguration中注册BloomFilterInterception:
public class WebMvcConfiguration extends WebMvcConfigurationSupport {
...
@Autowired
private BloomFilterInterceptor bloomFilterInterceptor;
protected void addInterceptors(InterceptorRegistry registry) {
...
registry.addInterceptor(bloomFilterInterceptor)
.addPathPatterns("/user/setmeal/list")
.addPathPatterns("/user/dish/list");
}
...
}
使用AOP来更新布隆过滤器
当数据库里的分类数据发生改变时,布隆过滤器也要相应的更新,由于布隆过滤器难以删除元素,所以更新步骤为:
- 将布隆过滤器里所有键的过期时间都设置为现在。
- 清理布隆过滤器里所有过期的键。
- 重新预热布隆过滤器。
代码如下:
- 在com.sky.annotation包下自定义注解UpdateBloomFilter,用于标识某个方法执行完成后需要更新布隆过滤器:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface UpdateBloomFilter {}
- 在com.sky.service.aspect包下创建切面类UpdateBloomFilterAspect,用于更新布隆过滤器:
@Aspect
@Component
@Slf4j
public class UpdateBloomFilterAspect {
@Autowired
private ApplicationContext applicationContext;
@Value("${spring.bloom-filter.expected-insertions}")
private long expectedInsertions;
@Value("${spring.bloom-filter.false-probability}")
private double falseProbability;
@Autowired
private CategoryMapper categoryMapper;
/**
* 切入点
*/
@Pointcut("@annotation(com.sky.annotation.UpdateBloomFilter)")
public void updateBloomFilterPointcut() {}
/**
* 后置通知,在通知中进行布隆过滤器的更新
*/
@After("updateBloomFilterPointcut()")
public void updateBloomFilter(JoinPoint joinPoint) {
log.info("开始更新布隆过滤器");
//获得布隆过滤器的Bean对象
RBloomFilter<Integer> bloomFilter = (RBloomFilter<Integer>) applicationContext.getBean("bloomFilter");
//清理布隆过滤器
bloomFilter.expire(Instant.now());
bloomFilter.clearExpire();
//初始化布隆过滤器
bloomFilter.tryInit(expectedInsertions, falseProbability);
log.info("开始预热布隆过滤器...");
//查询所有的分类id
List<Integer> CategoryIds = categoryMapper.getCategoryIdsByStatus(StatusConstant.ENABLE);
//预热布隆过滤器
bloomFilter.add(CategoryIds);
}
}
- 在CategoryController类中的新增分类、删除分类和启用禁用分类方法上加上注解@UpdateBloomFilter:
public class CategoryController {
...
@UpdateBloomFilter
public Result<String> save(@RequestBody CategoryDTO categoryDTO) {...}
@UpdateBloomFilter
public Result<String> deleteById(Long id) {...}
@UpdateBloomFilter
public Result<String> startOrStop(@PathVariable("status") Integer status, Long id) {...}
...
}
功能测试
布隆过滤器的拦截器功能验证
通过接口文档测试,并观察日志来进行验证:
- 当前端查询数据库里存在的数据时:

- 当前端查询数据库里不存在的数据时:

布隆过滤器的更新功能验证
通过接口文档测试或前后端联调测试,并观察日志和redis缓存进行验证:
- 日志:

- redis缓存更新之前:
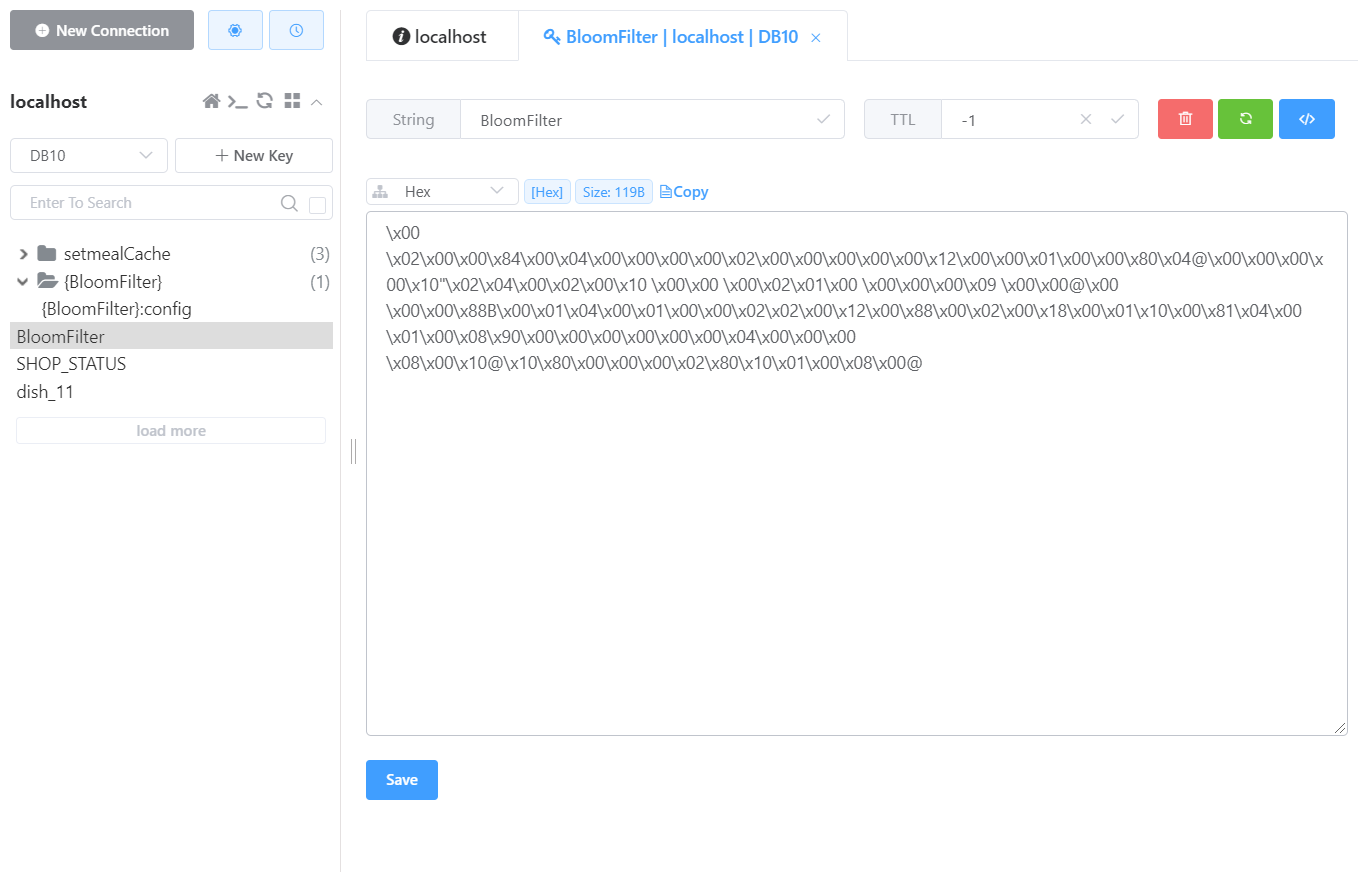
- redis缓存更新之后:
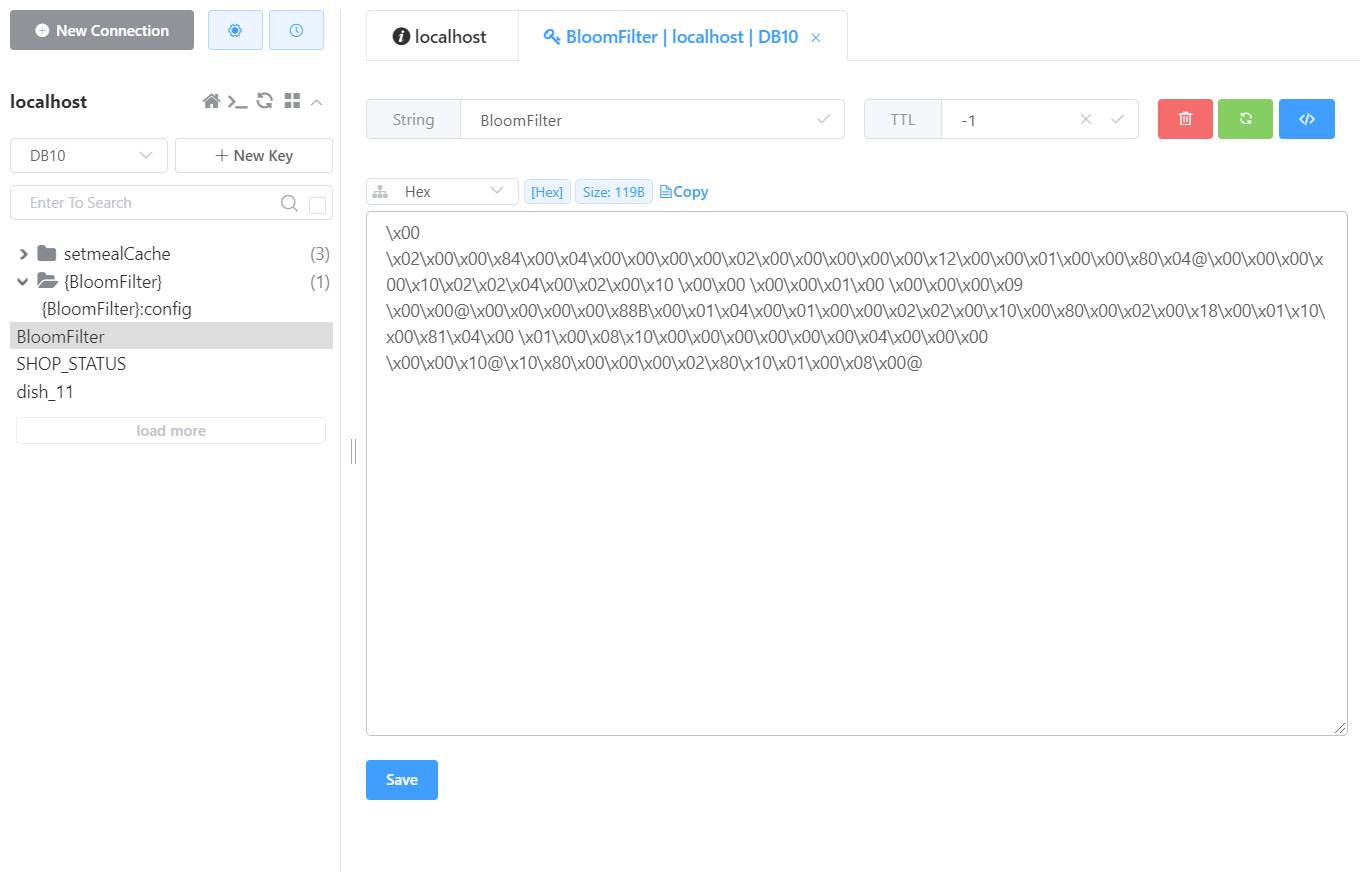 标签:缓存,布隆,private,穿透,哈希,过滤器,优化,public
From: https://www.cnblogs.com/zgg1h/p/18328969
标签:缓存,布隆,private,穿透,哈希,过滤器,优化,public
From: https://www.cnblogs.com/zgg1h/p/18328969