标签:m3u8 url resp 爬虫 爬取 video 91 line requests
1、 导入模块
import requests
import re
2、获取m3u8文件
# url地址
url = 'http://www.wwmulu.com/rj/xhcl/play-1-1.html'
# 正则表达式
obj = re.compile(r'<span class="ff-player" data-play-name="kbm3u8" data-src="(?P<video_url>.*?)"',re.S)
# 获取网页
resp = requests.get(url)
# 网页编码处理
resp.encoding = 'ISO-8859-1'
# 正则匹配得到需要的m3u8地址
m3u8 = obj.search(resp.text).group("video_url")
# m3u8内容获取
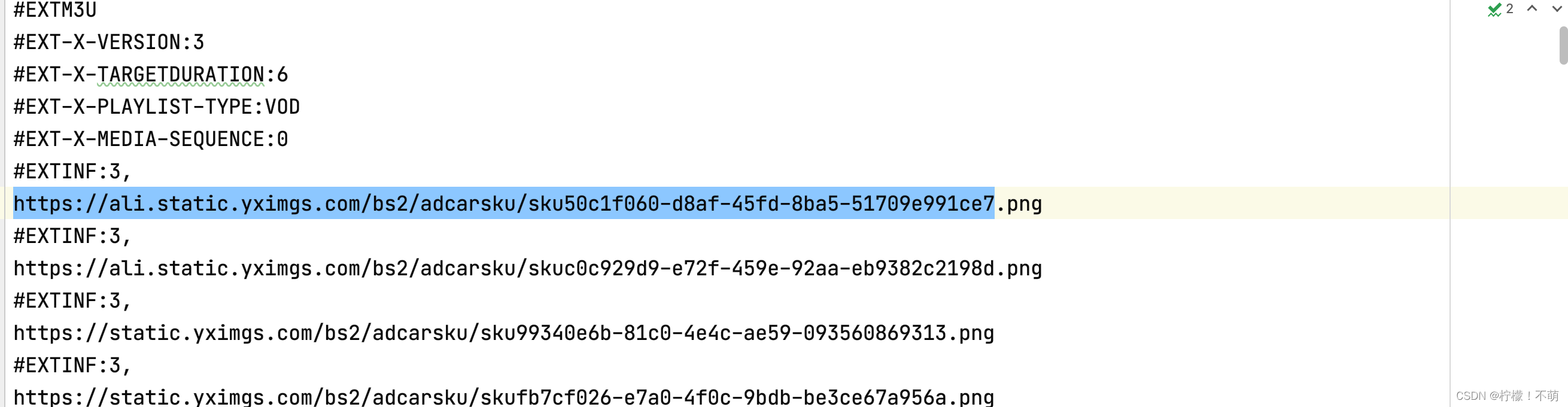
resp2 = requests.get(m3u8)
with open("video.m3u8",mode='wb') as f:
f.write(resp2.content)
resp2.close()
3、下载切片后的视频
n = 1
with open("video.m3u8",mode="r",encoding="utf-8") as f:
for line in f:
line = line.strip()
print(line)
# 提取视频切片地址
if line.startswith("#"):
continue
# 获取视频内容
rep3 = requests.get(line)
f = open(f"./video/{n}.ts", mode="wb")
f.write(rep3.content)
f.close()
rep3.close()
n += 1
print(f"{n}succ")
4、完整代码
import requests
import re
# url地址
url = 'http://www.wwmulu.com/rj/xhcl/play-1-1.html'
# 正则表达式
obj = re.compile(r'<span class="ff-player" data-play-name="kbm3u8" data-src="(?P<video_url>.*?)"', re.S)
# 获取网页
resp = requests.get(url)
# 网页编码处理
resp.encoding = 'ISO-8859-1'
# 正则匹配得到需要的m3u8地址
m3u8 = obj.search(resp.text).group("video_url")
# m3u8内容获取
resp2 = requests.get(m3u8)
with open("video.m3u8", mode='wb') as f:
f.write(resp2.content)
resp2.close()
n = 1
with open("video.m3u8",mode="r",encoding="utf-8") as f:
for line in f:
line = line.strip()
print(line)
# 提取视频切片地址
if line.startswith("#"):
continue
# 获取视频内容
rep3 = requests.get(line)
f = open(f"./video/{n}.ts", mode="wb")
f.write(rep3.content)
f.close()
rep3.close()
n += 1
print(f"{n}succ")
5、 展示
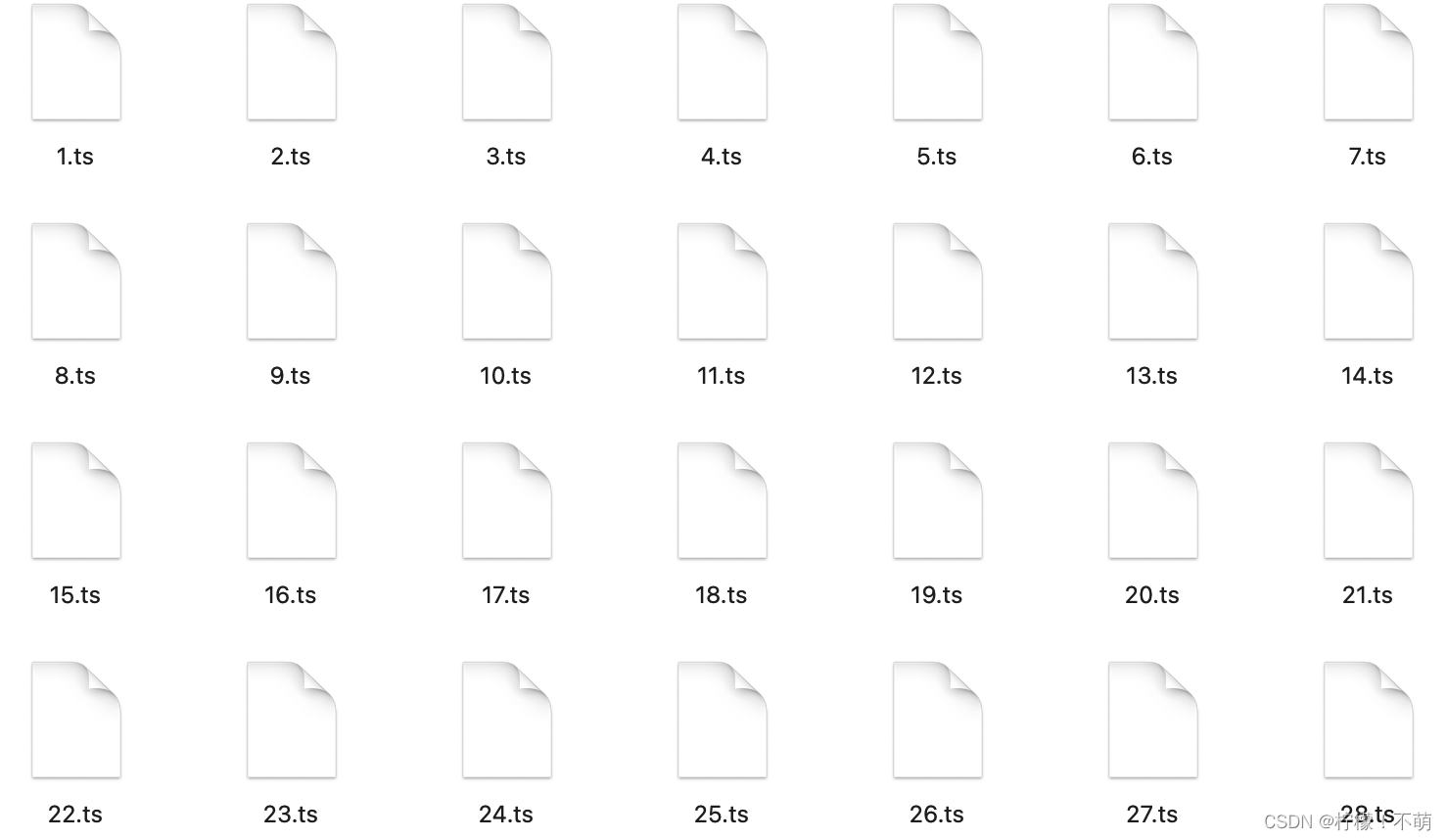
6、视频合并
标签:m3u8,
url,
resp,
爬虫,
爬取,
video,
91,
line,
requests
From: https://www.cnblogs.com/nnguhx/p/16585411.html