来自:https://www.qiyacloud.cn/2021/04/2021-04-30/
写的数据安全吗?
思考一个问题:写数据做到什么程度才叫安全了?
就是:用户发过来一个写 IO 请求,只要你给他回复了 “写成功了”,那么无论机器发生掉电,还是重启等等之类的,数据都还能读出来。
所以,在我们不考虑数据静默错误的前提下,数据安全的最本质要求是什么?
划重点:那就是数据一定要在非易失性的存储介质里,你才能给用户回复“写成功”。请一定要记住这句话,做存储开发的人员,80% 的时间都在思考这句话。
那么常见的易失性介质和非易失性介质有哪些呢?
易失性介质:寄存器,内存 等; 非易失性介质:磁盘,固态硬盘 等;
可以看一眼简化的经典金字塔:
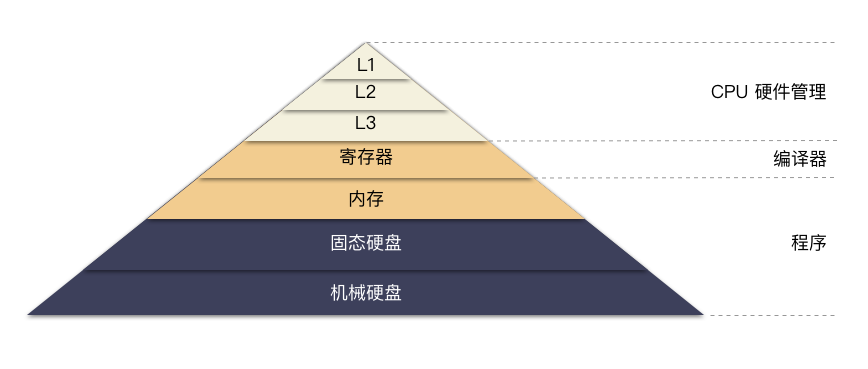
从上到下速度递减,容量递增,价格递减。
Linux IO 简述
我们前面提到一个文件的读写方式,标准库的方式和系统调用的方式。无论是哪一种,本质上都是基于文件的一种形式,下面承接了一层文件系统,主要层次:系统调用 -> vfs -> 文件系统 -> 块设备 -> 硬件驱动 。
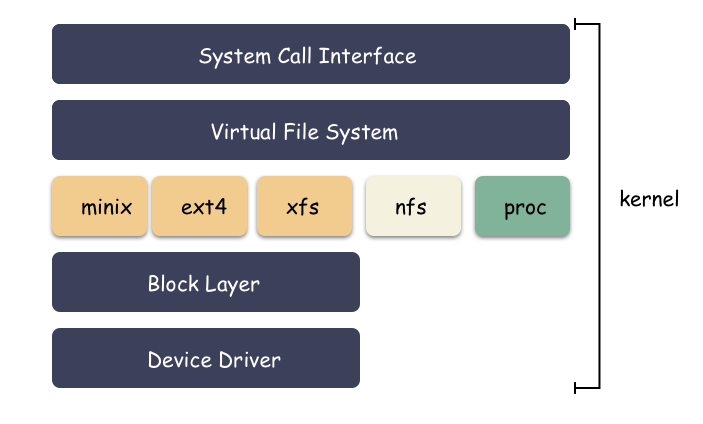
我们 open 了这个文件,然后 write 数据进去。好,现在思考一个问题,当 write 返回成功之后,数据到磁盘了吗?
答案是:不确定。
因为有文件系统的 cache ,默认是 write back 的模式,数据写到内存就返回成功了,然后内核根据实际情况(比如定期或者脏数据达到某个阈值),异步刷盘。
这样的好处是保证了写的性能,貌似写的性能非常好(可不好嘛,数据写内存的速度),坏处是存在数据风险。因为用户收到成功的时候,数据可能还在内存,这个时候整机掉电,由于内存是易失性介质,数据就丢了。丢数据 是存储最不能接受的事情,相当于丢失了存储的生命线。
动画演示:

怎么保证数据的可靠?
划重点:还是那句话,一定要确保数据落盘之后,才向用户返回成功。
那么怎么才能保证这一点?有以下 3 种方法。
open文件的时候,用O_DIRECT模式打开,这样write/read的时候,文件系统的 IO 会绕过 cache,直接跟磁盘 IO;open文件的时候,使用O_SYNC模式,确保每一笔 IO 都是同步落盘的。或者write之后,主动调用一把fsync,强制数据落盘;- 读写文件的另一种方式是通过
mmap函数把文件映射到进程的地址空间,读写进程内存的地址的数据其实是转发到磁盘上去读写,write之后主动调用一把msync强制刷盘;
三种安全的 IO 姿势
O_DIRECT 模式
DIRECT IO 模式能够保证每次 IO 都直接访问磁盘数据,而不是数据写到内存就向用户返回成功的结果,这样才能确保数据安全。因为内存是易失性的,掉电就丢了,数据只有写到持久化的介质才能安心。
动画演示: 
读的时候也是直接读磁盘,而不会缓存到内存中,从而也能节省整机内存的使用。
缺点也同样明显,由于每次 IO 都要落盘,那么性能肯定看起来差(但你要明白,其实这才是真实的磁盘性能)。
划重点:使用了 O_DIRECT 模式之后,必须要用户自己保证对齐规则,否则 IO 会报错,有 3 个需要对齐的规则:
- 磁盘 IO 的大小必须扇区大小(512字节)对齐
- 磁盘 IO 偏移按照扇区大小对齐;
- 内存 buffer 的地址也必须是扇区对齐;
c 语言示例:
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <fcntl.h>
#include <errno.h>
#include <string.h>
#include <stdint.h>
extern int errno;
#define align_ptr(p, a) \
(u_char *)(((uintptr_t)(p) + ((uintptr_t)a - 1)) & ~((uintptr_t)a - 1))
int main(int argc, char **argv)
{
char timestamp[8192] = {0,};
char *timestamp_buf = NULL;
int timestamp_len = 0;
ssize_t n = 0;
int fd = -1;
fd = open("./test_directio.txt", O_CREAT | O_RDWR | O_DIRECT, 0644);
assert(fd >= 0);
// 对齐内存地址
timestamp_buf = (char *)(align_ptr(timestamp, 512));
timestamp_len = 512;
n = pwrite(fd, timestamp_buf, timestamp_len, 0);
printf("ret (%ld) errno (%s)\n", n, strerror(errno));
return 0;
}
编译命令:
gcc -ggdb3 -O0 test.c -D_GNU_SOURCE
生成二进制文件,执行下就知道了,这个是成功的。
sh-4.4# ./a.out
ret (512) errno (Success)
如果为了验证对齐导致的错误,读者朋友可以故意让 io 的偏移或者大小,或者内存 buffer 地址不按照 512 对齐(比如故意让 timestamp_buf 对齐之后的地址减 1,再试下运行),会得到如下:
sh-4.4# ./a.out
ret (-1) errno (Invalid argument)
思考问题:有些童鞋可能会好奇问了?IO 大小和偏移按照 512 对齐我会,但是怎么才能保证 malloc 的地址是 512 对齐的呢?
是啊,我们无法用 malloc 来控制生成的地址。这对这个需求,我们有两个解决办法:
方法一: 分配大一点的内存,然后在这个大块内存里找到对齐的地址,只需要确保 IO 大小不会超过最后的边界即可;
我上面的 demo 例子就是如此,分配了 8192 的内存块,然后从里面找到 512 对齐的地址。从这个地址开始往后 512 个字节是绝对到不了这个大内存块的边界的。对齐的目的安全达成。

这种方式实现简单且通用,但是比较浪费内存。
方法二:使用 posix 标准封装的接口 posix_memalign 来分配内存,这个接口分配的内存能保证对齐;
如下,分配 1 KiB 的内存 buffer,内存地址按照 512 字节对齐。
ret = posix_memalign (&buf, 512, 1024);
if (ret) {
return -1;
}
思考一个问题:O_DIRECT 模式 的 IO 一般是哪些应用场景?
- 最常见的是数据库系统,数据库有自己的缓存体系和 IO 优化,无需内核消耗内存再去完成相同的事情,并且可能好心办坏事;
- 不格式化文件系统,而是直接管理块设备的场景;
标准 IO + sync
sync 功能:强制刷新内核缓冲区到输出磁盘。
在 Linux 的缓存 I/O 机制中,用户和磁盘之间有一层易失性的介质——内核空间的 buffer cache;
- 读的时候会 cache 一份到内存中以便提高后续的读性能;
- 写的时候用户数据写到内存 cache 就向用户返回成功,然后异步刷盘,从而提高用户的写性能。
读操作描述如下:
- 操作系统先看内核的
buffer cache有缓存不?有,那么就直接从缓存中返回; - 否则从磁盘中读取,然后缓存在操作系统的缓存中;
写操作描述如下:
- 将数据从用户空间复制到内核的内存 cache 中,这时就向用户返回成功,对用户来说写操作就已经完成;
- 至于内存的数据什么时候才真正写到磁盘由操作系统策略决定(如果此时机器掉电,那么就会丢失用户数据);
- 所以,如果你要保证落盘,必须显式调用了
sync命令,显式把数据刷到磁盘(只有刷到磁盘,机器掉电才不会导致丢数据);
划重点:sync 机制能保证当前时间点之前的数据全部刷到磁盘。。而关于 sync 的方式大概有两种:
open的使用使用O_SYNC标识;- 显式调用
fsync之类的系统调用;
方法一:open 使用 O_SYNC 标识;
c 语言示例:
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <fcntl.h>
#include <errno.h>
#include <string.h>
#include <stdint.h>
extern int errno;
int main(int argc, char **argv)
{
char buffer[512] = {0,};
ssize_t n = 0;
int fd = -1;
fd = open("./test_sync.txt", O_CREAT | O_RDWR | O_SYNC, 0644);
assert(fd >= 0);
n = pwrite(fd, buffer, 512, 0);
printf("ret (%ld) errno (%s)\n", n, strerror(errno));
return 0;
}
这种方式能保证每一笔 IO 都是同步 IO,一定是刷到磁盘才返回,但是这种使用姿势一般少见,因为这个性能会很差,并且不利于批量优化。
动画演示:

方法二:单独调用函数 fsync
这个则是在 write 之后 fsync 一把数据到磁盘,这种方式用的多些,因为方便业务优化。这种方式对程序员提出了更高的要求,要求必须自己掌握好 fsync 的时机,达到既保证安全又保证性能的目的,这里通常是个权衡点。
比如,你可以 write 10 次之后,最后才调用一般 fsync,这样既能保证刷盘,又达成了批量 IO 的优化目的。
关于这种使用姿势,有几个类似函数,其中有些差异,各自体会下:
// 文件数据和元数据部分都刷盘
int fsync(int fildes);
// 文件数据部分都刷盘
int fdatasync(int fildes);
// 整个内存 cache 都刷磁盘
void sync(void);
动画演示:

mmap + msync
这是一个非常有趣的 IO 模式,通过 mmap 函数将硬盘上文件与进程地址空间大小相同的区域映射起来,之后当要访问这段内存中一段数据时,内核会转换为访问该文件的对应位置的数据。从使用姿势上,就跟操作内存一样,但从结果上来看,本质上是文件 IO。
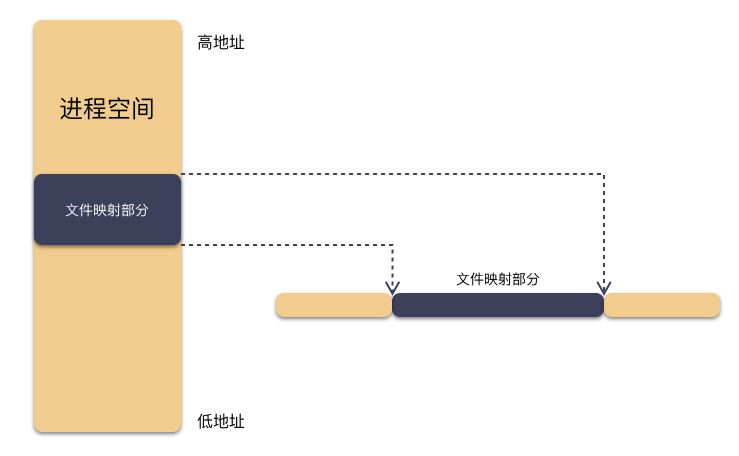
void *
mmap(void *addr, size_t len, int prot, int flags, int fd, off_t offset)
int
munmap(void *addr, size_t len);
mmap 这种方式可以减少数据在用户空间和内核空间之间的拷贝操作,当数据大的时候,采用内存映射方式去访问文件会获得比较好的效率(因为可以减少内存拷贝量,并且聚合 IO,数据批量下盘,有效的减少 IO 次数)。
当然,你 write 数据也还是异步落盘的,并没有实时落盘,如果要保证落盘,那么必须要调用 msync ,调用成功,才算持久化落盘。
mmap 的优点:
- 减少系统调用的次数。只需要 mmap 一次的系统调用,后续的操作都是内存拷贝操作姿势,而不是 write/read 的系统调用;
- 减少数据拷贝次数;
c 语言示例:
#include <stdio.h>
#include <stdlib.h>
#include <sys/mman.h>
#include <sys/types.h>
#include <unistd.h>
#include <sys/stat.h>
#include <assert.h>
#include <fcntl.h>
#include <string.h>
int main()
{
int ret = -1;
int fd = -1;
fd = open("test_mmap.txt", O_CREAT | O_RDWR, 0644);
assert(fd >= 0);
ret = ftruncate(fd, 512);
assert(ret >= 0);
char *const address = (char *)mmap(NULL, 512, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
assert(address != MAP_FAILED);
// 神奇在这里(看起来是内存拷贝,其实是文件 IO)
strcpy(address, "hallo, world");
ret = close(fd);
assert(ret >= 0);
// 落盘确保
ret = msync(address, 512, MS_SYNC);
assert(ret >= 0);
ret = munmap(address, 512);
assert(ret >= 0);
return 0;
}
编译运行看看吧。
gcc -ggdb3 -O0 test_mmap.c -D_GNU_SOURCE
是不是生成了一个 test_mmap.txt 文件,里面有一句 “hello,world”。
动画演示:

硬件缓存
以上方式保证了文件系统那一层的落盘,但是磁盘硬件其实本身也有缓存,这个属于硬件缓存,这层缓存也是易失的。所以最后一点是,为了保证数据的落盘,硬盘缓存也要关掉。
# 查看写缓存状态;
hdparm -W /dev/sda
# 关闭 HDD Cache,保证数据强一致性;避免断电时数据未落盘;
hdparm -W 0 /dev/sda
# 打开 HDD Cache(断电时可能导致丢数据)
hdparm -W 1 /dev/sda
按照以上的 IO 姿势,当你写一笔 IO 落盘之后,才能说数据写到磁盘了,才能保证数据是掉电非易失的。
总结
- 数据一定要写在非易失性的存储介质里,你才能给用户回复“写成功”。其他的取巧的方式都是耍流氓、走钢丝;
- 本文总结 3 种最根本的 IO 安全的方式,分别是 O_DIRECT 写,标准 IO + Sync 方式,mmap 写 + msync 方式。要么每次都是同步写盘,要么就是每次写完,再调用 sync 主动刷,才能保证数据安全;;
- O_DIRECT 对使用者提出了苛刻的要求,必须要满足 IO 的 offset,length 扇区对齐,内存 buffer 地址也要扇区对齐;
- 注意硬盘也有缓存,可以通过
hdparm命令开关;
========================================================================================================

Go 存储编程怎么使用 O_DIRECT 模式?今天就分享这个存储细节,
之前提过很多次,操作系统的 IO 过文件系统的时候,默认是会使用到 page cache,并且采用的是 write back 的方式,系统异步刷盘的。由于是异步的,如果在数据还未刷盘之前,掉电的话就会导致数据丢失。
如果想要明确数据写到磁盘有两种方式:要么就每次写完主动 sync 一把,要么就使用 direct io 的方式,指明每一笔 io 数据都要写到磁盘才返回。
那么在 Go 里面怎么使用 direct io 呢?
有同学可能会说,那还不简单,open 文件的时候 flag 用 O_DIRECT 嘛,然后。。。
是吗?有这么简单吗?提两个问题,童鞋们可以先思考下:
-
O_DIRECT 这个定义在 Go 标准库的哪个文件?
-
direct io 需要 io 大小和偏移扇区对齐,且还要满足内存 buffer 地址的对齐,这个怎么做到?
O_DIRECT 的知识点
在此之前,先回顾 O_DIRECT 相关的知识。direct io 也就是常说的 DIO,是在 Open 的时候通过 flag 来指定 O_DIRECT 参数,之后的数据的 write/read 都是绕过 page cache,直接和磁盘操作,从而避免了掉电丢数据的尴尬局面,同时也让应用层可以自己决定内存的使用(避免不必要的 cache 消耗)。
direct io 一般解决两个问题:
-
数据落盘,确保掉电不丢失;
-
减少内核 page cache 的内存使用,业务层自己控制内存,更加灵活;
direct io 模式需要用户保证对齐规则,否则 IO 会报错,有 3 个需要对齐的规则:
-
IO 的大小必须扇区大小(512字节)对齐
-
IO 偏移按照扇区大小对齐;
-
内存 buffer 的地址也必须是扇区对齐;
direct io 模式却不对齐会怎样?
读写报错呗,会抛出“无效参数”的错误。
思考问题
为什么 Go 的 O_DIRECT 知识点值得一提?
以下按照两层意思分析思考。
1 第一层意思:O_DIRECT 平台不兼容
划重点:Go 标准库 os 中的是没有 O_DIRECT 这个参数的。
为什么呢?
Go os 库实现的是各个操作系统兼容的实现,direct io 这个在不同的操作系统下实现形态不一样。其实 O_DIRECT 这个 Open flag 参数本就是只存在于 linux 系统。
以下才是各个平台兼容的 Open 参数 ( os/file.go )。
- const (
- // Exactly one of O_RDONLY, O_WRONLY, or O_RDWR must be specified.
- O_RDONLY int = syscall.O_RDONLY // open the file read-only.
- O_WRONLY int = syscall.O_WRONLY // open the file write-only.
- O_RDWR int = syscall.O_RDWR // open the file read-write.
- // The remaining values may be or'ed in to control behavior.
- O_APPEND int = syscall.O_APPEND // append data to the file when writing.
- O_CREATE int = syscall.O_CREAT // create a new file if none exists.
- O_EXCL int = syscall.O_EXCL // used with O_CREATE, file must not exist.
- O_SYNC int = syscall.O_SYNC // open for synchronous I/O.
- O_TRUNC int = syscall.O_TRUNC // truncate regular writable file when opened.
- )
发现了吗?O_DIRECT 根本不在其中。O_DIRECT 其实是和系统平台强相关的一个参数。
问题来了,那么 O_DIRECT 定义在那里?
跟操作系统强相关的自然是定义在 syscall 库中:
- // syscall/zerrors_linux_amd64.go
- const (
- // ...
- O_DIRECT = 0x4000
- )
怎么打开文件呢?
- // +build linux
- // 指明在 linux 平台系统编译
- fp := os.OpenFile(name, syscall.O_DIRECT|flag, perm)
2 第二层意思:Go 无法精确控制内存分配地址
标准库或者内置函数没有提供让你分配对齐内存的函数。
direct io 必须要满足 3 种对齐规则:io 偏移扇区对齐,长度扇区对齐,内存 buffer 地址扇区对齐。前两个还比较好满足,但是分配的内存地址作为一个小程序员无法精确控制。
先对比回忆下 c 语言,libc 库是调用 posix_memalign 直接分配出符合要求的内存块。go 里面怎么做?
先问个问题:Go 里面怎么分配 buffer 内存?
io 的 buffer 其实就是字节数组嘛,很好回答,最常见自然是用 make 来分配,如下:
buffer := make([]byte, 4096)
那这个地址是对齐的吗?
答案是:不确定。
那怎么才能获取到对齐的地址呢?
划重点:方法很简单,就是先分配一个比预期要大的内存块,然后在这个内存块里找对齐位置。 这是一个任何语言皆通用的方法,在 Go 里也是可用的。
什么意思?
比如,我现在需要一个 4096 大小的内存块,要求地址按照 512 对齐,可以这样做:
-
先分配要给 4096 + 512 大小的内存块,假设得到的地址是 p1 ;
-
然后在 [ p1, p1+512 ] 这个地址范围找,一定能找到 512 对齐的地址(这个能理解吗?),假设这个地址是 p2 ;
-
返回 p2 这个地址给用户使用,用户能正常使用 [ p2, p2 + 4096 ] 这个范围的内存块而不越界;
以上就是基本原理了,童鞋理解了不?下面看下代码怎么写。
- const (
- AlignSize = 512
- )
- // 在 block 这个字节数组首地址,往后找,找到符合 AlignSize 对齐的地址,并返回
- // 这里用到位操作,速度很快;
- func alignment(block []byte, AlignSize int) int {
- return int(uintptr(unsafe.Pointer(&block[0])) & uintptr(AlignSize-1))
- }
- // 分配 BlockSize 大小的内存块
- // 地址按照 512 对齐
- func AlignedBlock(BlockSize int) []byte {
- // 分配一个,分配大小比实际需要的稍大
- block := make([]byte, BlockSize+AlignSize)
- // 计算这个 block 内存块往后多少偏移,地址才能对齐到 512
- a := alignment(block, AlignSize)
- offset := 0
- if a != 0 {
- offset = AlignSize - a
- }
- // 偏移指定位置,生成一个新的 block,这个 block 将满足地址对齐 512;
- block = block[offset : offset+BlockSize]
- if BlockSize != 0 {
- // 最后做一次校验
- a = alignment(block, AlignSize)
- if a != 0 {
- log.Fatal("Failed to align block")
- }
- }
- return block
- }
所以,通过以上 AlignedBlock 函数分配出来的内存一定是 512 地址对齐的。
有啥缺点吗?
浪费空间嘛。 命名需要 4k 内存,实际分配了 4k+512 。
3 我太懒了,一行代码都不愿多写,有开源的库吗?
还真有,推荐个:https://github.com/ncw/directio ,内部实现极其简单,就是上面的一样。
使用姿势很简单:
步骤一:O_DIRECT 模式打开文件:
- // 创建句柄
- fp, err := directio.OpenFile(file, os.O_RDONLY, 0666)
封装关键在于:O_DIRECT 是从 syscall 库获取的。
步骤二:读数据
- // 创建地址按照 4k 对齐的内存块
- buffer := directio.AlignedBlock(directio.BlockSize)
- // 把文件数据读到内存块中
- _, err := io.ReadFull(fp, buffer)
关键在于:buffer 必须是特制的 [ ]byte 数组,而不能仅仅根据 make([ ]byte, 512 ) 这样去创建,因为仅仅是 make 无法保证地址对齐。
总结
-
direct io 必须满足 io 大小,偏移,内存 buffer 地址三者都扇区对齐;
-
O_DIRECT 不在 os 库,而在于操作系统相关的 syscall 库;
-
Go 中无法直接使用 make 来分配对齐内存,一般的做法是分配一块大一点的内存,然后在里面找到对齐的地址即可;
========================================================================================================
用sync与direct的区别,写入磁盘的数据不同。在不同块大小情况下,写入磁盘的数据量,不一样。
参考:
https://www.qiyacloud.cn/2021/04/2021-04-30/
https://blog.csdn.net/flynetcn/article/details/120658566
标签:int,sync,direct,DIRECT,内存,IO,go,对齐,512 From: https://www.cnblogs.com/rebrobot/p/18305085