为什么选择 RAG
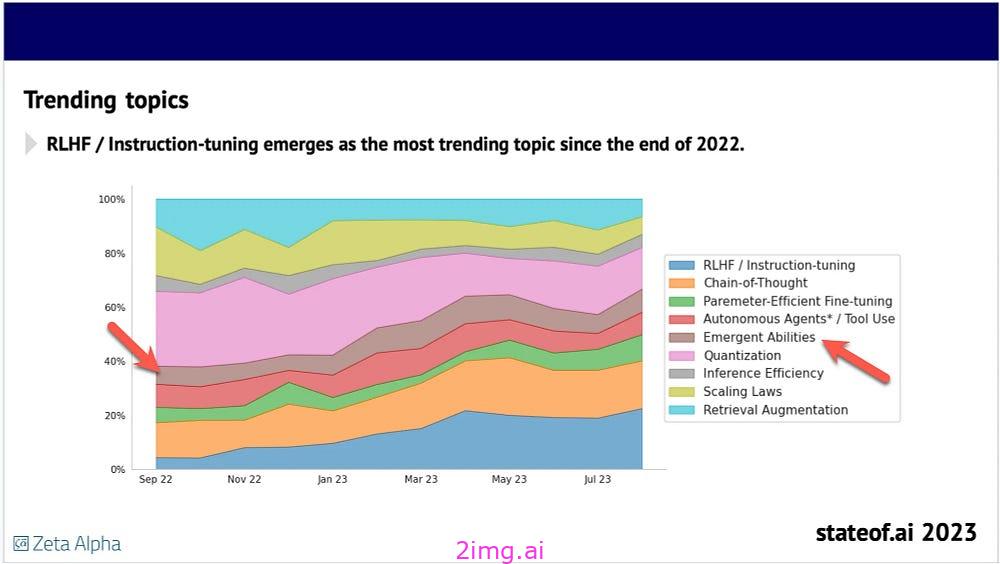
新兴能力
直到最近,人们发现 LLM 具有新兴能力,即在与用户或任务交互过程中出现的意外功能。
这些功能的示例包括:
解决问题: LLM 可以利用其语言理解和推理能力,为未经过明确培训的任务提供富有洞察力的解决方案。
适应用户输入: LLM 可以根据特定用户输入或上下文定制其响应,从而在交互中展现一定程度的个性化。
通过对上下文的理解, LLM 可以生成与给定上下文相关且适当的响应,即使提示中没有明确说明。
新兴能力现象促使组织探索未知的大语言模型功能。然而,最近的一项研究推翻了这一概念,揭示了看似新兴的能力实际上是大语言模型对给定背景的强烈反应。

指导和上下文参考
LLM 在推理时对指令反应良好,当提示包含上下文参考数据时,表现优异。大量研究已通过实证证明,LLM 优先考虑推理时提供的上下文知识,而不是经过微调的模型数据。
情境学习
上下文学习是模型根据用户或任务提供的特定上下文调整和改进其响应的能力。
通过考虑模型的运行环境,该过程使模型能够生成更相关、更一致的输出。
幻觉
为大语言模型 (LLM) 提供推理时的上下文参考,从而实现上下文学习,可以减轻幻觉。
检索增强生成 (RAG) 将大型语言模型 (LLM) 的生成能力与外部知识源相结合,以提供更准确、最新的响应。
RAG 的最新进展重点是通过迭代 LLM 细化或通过对 LLM 进行额外指令调整获得的自我批评能力来改善检索结果。
推测性 RAG
下图展示了 RAG 的不同方法,包括:
- 标准 RAG,
- 自我反思 RAG &
- 校正 RAG。
标准 RAG:据 Google 称, 标准 RAG 将所有文档合并到提示中,这会增加输入长度并减慢推理速度。原则上这是正确的,但存在使用摘要、重新排序和请求用户反馈的变体。
对于分块策略以及如何优化相关块内上下文的分割也进行了深入研究。
自我反思 RAG需要对通用语言模型 (LM) 进行专门的指令调整,以生成用于自我反思的特定标签。
校正 RAG使用外部检索评估器来改进文档质量。该评估器仅关注上下文信息,而不增强推理能力。
推测性 RAG利用更大的通用 LM 来有效地验证由较小的专业 LM 并行生成的多个 RAG 草稿。
每个草稿都是从检索到的文档的不同子集生成的,提供对证据的不同视角,同时最小化每个草稿的输入标记数量。
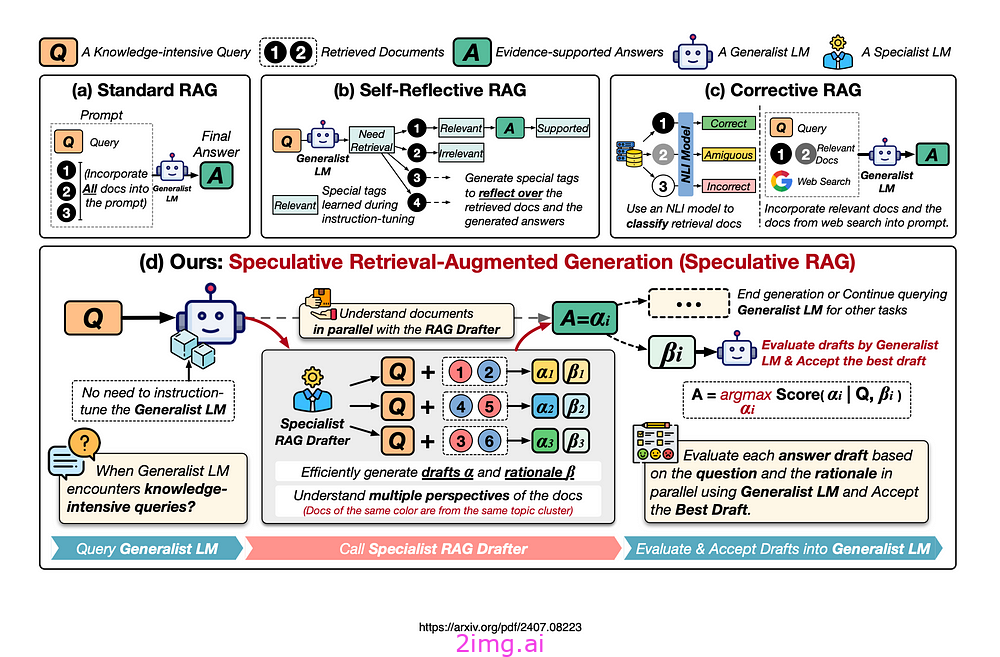
Speculative RAG 是一个框架,它使用更大的通用语言模型来有效地验证由较小的、专门的提炼语言模型并行生成的多个 RAG 草稿。
每个草稿都基于检索到的文档的不同子集,提供不同的观点并减少每个草稿的输入标记数。
研究表明,这种方法可以增强理解力,并减轻长语境中的位置偏差。通过将起草工作委托给较小的模型,并让较大的模型执行一次验证,Speculative RAG 可以加速 RAG 过程。
实验表明,Speculative RAG 在降低延迟的情况下实现了最先进的性能。
与传统 RAG 系统相比,准确率提高 12.97%,延迟降低 51%。
如何
这个新的 RAG 框架使用较小的专业 RAG 起草器来生成高质量的草稿答案。
每个草稿均来自检索到的文档的不同子集,从而提供不同的观点并减少每个草稿的输入标记数。
通用 LM 可与 RAG 起草器配合使用,无需额外调整。
它验证并将最有希望的草稿整合到最终答案中,增强对每个子集的理解,并减轻中间迷失现象。
谷歌认为,通过让规模较小的专业 LM 处理起草,而规模较大的通用 LM 则并行对起草进行单次、公正的验证,这种方法可以显著加快 RAG 的速度。
在四个自由形式问答和闭集生成基准上进行的大量实验证明了该方法的卓越有效性和效率。
主要考虑因素
- 这项研究很好地说明了小型语言模型如何在采用模型编排的更大框架中使用。
- SLM 因其推理能力而被充分利用,而这正是它们被专门创建的原因。
- SLM 是此场景的理想选择,因为此实现本质上不需要知识密集型。相关和上下文知识在推理时注入。
- 该框架的目标是优化令牌数量,从而降低安全成本。
- 与传统 RAG 系统相比,延迟减少了 51%。
- 准确率提高高达 12.97%。
- 避免对模型进行微调。
- 多个 RAG 草稿由较小的、专门的语言模型并行生成。
- 这种规模较小、专门化的 RAG 模型擅长对检索到的文档进行推理,并能快速生成准确的响应。这让人想起经过训练具有出色推理能力的 SLM Orca-2 和 Phi-3。
- 使用 Mistral 7B SLM 作为 RAG 牵引机取得了最佳效果。
- 以及验证器 Mixtral 8x7B。